整体流程
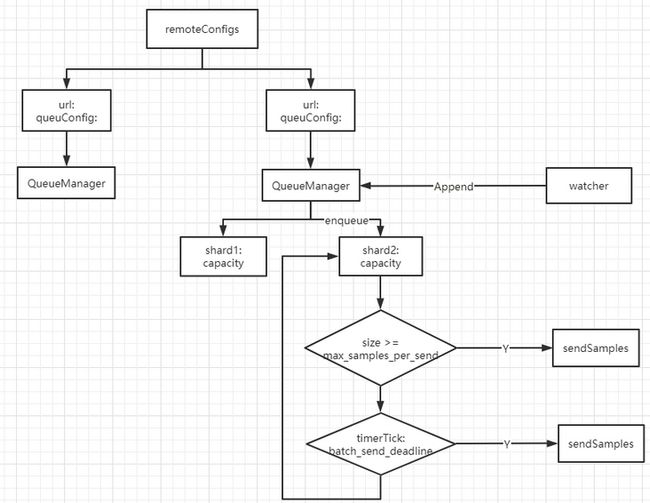
- remoteConfigs支持配置多个remoteStorage,每个remoteStorage使用1个QueueManager;
- watcher将sample发送给QueueManager;
- 1个QueueManager中管理多个shard,每个shard的容量为capactiy;
- 每个shard会定时(batch_send_deadline)定量(max_samples_per_send)的向remote endpoint发送数据;
代码入口
入口:storage/remote/write.go
主要工作是初始化QueueManager,然后调用start()让其干活。
// 根据配置初始化QueueManager,然后让QueueManager干活
func (rws *WriteStorage) ApplyConfig(conf *config.Config) error {
.....
newQueues := make(map[string]*QueueManager)
newHashes := []string{}
for _, rwConf := range conf.RemoteWriteConfigs {
hash, err := toHash(rwConf)
if err != nil {
return err
}
// Don't allow duplicate remote write configs.
if _, ok := newQueues[hash]; ok {
return fmt.Errorf("duplicate remote write configs are not allowed, found duplicate for URL: %s", rwConf.URL)
}
// Set the queue name to the config hash if the user has not set
// a name in their remote write config so we can still differentiate
// between queues that have the same remote write endpoint.
name := hash[:6]
if rwConf.Name != "" {
name = rwConf.Name
}
c, err := NewWriteClient(name, &ClientConfig{
URL: rwConf.URL,
Timeout: rwConf.RemoteTimeout,
HTTPClientConfig: rwConf.HTTPClientConfig,
})
if err != nil {
return err
}
queue, ok := rws.queues[hash]
......
endpoint := rwConf.URL.String()
newQueues[hash] = NewQueueManager( ##初始化QueueManager
newQueueManagerMetrics(rws.reg, name, endpoint),
rws.watcherMetrics,
rws.liveReaderMetrics,
rws.logger,
rws.walDir, ##这里是/prometheus,在walwatcher中会被初始化为/prometheus/wal
rws.samplesIn,
rwConf.QueueConfig,
conf.GlobalConfig.ExternalLabels,
rwConf.WriteRelabelConfigs,
c,
rws.flushDeadline,
)
// Keep track of which queues are new so we know which to start.
newHashes = append(newHashes, hash)
}
// Anything remaining in rws.queues is a queue who's config has
// changed or was removed from the overall remote write config.
for _, q := range rws.queues {
q.Stop()
}
for _, hash := range newHashes { ##QueueManager干活
newQueues[hash].Start()
}
rws.queues = newQueues
return nil
}具体看一下QueueManager做的事情:
- shards.Start():为每个shard启动1个Goroutine干活;
- watcher.Start(): 监听watcher的变化,将wal新增数据写入shards;
- updateShardsLoop(): 定期根据sample in / sample out计算新的shard;
- reshardLoop(): 更新shard;
func (t *QueueManager) Start() {
// 注册prometheus的监控参数
t.metrics.register()
t.metrics.shardCapacity.Set(float64(t.cfg.Capacity))
t.metrics.maxNumShards.Set(float64(t.cfg.MaxShards))
t.metrics.minNumShards.Set(float64(t.cfg.MinShards))
t.metrics.desiredNumShards.Set(float64(t.cfg.MinShards))
t.shards.start(t.numShards) ##shard默认=cfg.MinShard,也就是1;这里面会对每个shard进行初始化、赋值、发送
t.watcher.Start() ##walwatcher监控变化
t.wg.Add(2)
go t.updateShardsLoop() ##定期根据sample in / sample out计算新的shard
go t.reshardLoop() ##更新shard为新值
}shards.Start()解析
为每个shard启动1个Goroutine,让shard干活;
// 每个shard有一个queue,shards包含N个shard
// queue有capacity大小(默认cfg.Capacity=500)
// start the shards; must be called before any call to enqueue.
func (s *shards) start(n int) {
s.mtx.Lock()
defer s.mtx.Unlock()
s.qm.metrics.pendingSamples.Set(0)
s.qm.metrics.numShards.Set(float64(n))
newQueues := make([]chan sample, n) //N个shard,初始只有1个
for i := 0; i < n; i++ {
newQueues[i] = make(chan sample, s.qm.cfg.Capacity) //每个shard最大有capacity个元素,初始=500
}
s.queues = newQueues
var hardShutdownCtx context.Context
hardShutdownCtx, s.hardShutdown = context.WithCancel(context.Background())
s.softShutdown = make(chan struct{})
s.running = int32(n)
s.done = make(chan struct{})
atomic.StoreUint32(&s.droppedOnHardShutdown, 0)
for i := 0; i < n; i++ {
go s.runShard(hardShutdownCtx, i, newQueues[i]) ##这里进行实际的发送
}
}shard Goroutine干了发送的活:
- queueManager中有一个samples数组,接收发送给queue的数据;
- runShard()接收watcher发送的数据,保存到samples数组中;
发送给remote的时机:
- 定时:定时器事件到,cfg.BatchSendDeadLine(默认=5s);
- 定量:samples数组大小达到cfg.MaxSamplesPerSend(默认=100);
func (s *shards) runShard(ctx context.Context, shardID int, queue chan sample) {
defer func() {
if atomic.AddInt32(&s.running, -1) == 0 {
close(s.done)
}
}()
shardNum := strconv.Itoa(shardID)
// Send batches of at most MaxSamplesPerSend samples to the remote storage.
// If we have fewer samples than that, flush them out after a deadline
// anyways.
var (
max = s.qm.cfg.MaxSamplesPerSend
nPending = 0
pendingSamples = allocateTimeSeries(max)
buf []byte
)
timer := time.NewTimer(time.Duration(s.qm.cfg.BatchSendDeadline))
stop := func() {
if !timer.Stop() {
select {
case <-timer.C:
default:
}
}
}
defer stop()
for {
select {
case <-ctx.Done():
// In this case we drop all samples in the buffer and the queue.
// Remove them from pending and mark them as failed.
droppedSamples := nPending + len(queue)
s.qm.metrics.pendingSamples.Sub(float64(droppedSamples))
s.qm.metrics.failedSamplesTotal.Add(float64(droppedSamples))
atomic.AddUint32(&s.droppedOnHardShutdown, uint32(droppedSamples))
return
//接收数据,保存到pendingSamples
case sample, ok := <-queue:
if !ok {
if nPending > 0 {
level.Debug(s.qm.logger).Log("msg", "Flushing samples to remote storage...", "count", nPending)
s.sendSamples(ctx, pendingSamples[:nPending], &buf)
s.qm.metrics.pendingSamples.Sub(float64(nPending))
level.Debug(s.qm.logger).Log("msg", "Done flushing.")
}
return
}
// Number of pending samples is limited by the fact that sendSamples (via sendSamplesWithBackoff)
// retries endlessly, so once we reach max samples, if we can never send to the endpoint we'll
// stop reading from the queue. This makes it safe to reference pendingSamples by index.
pendingSamples[nPending].Labels = labelsToLabelsProto(sample.labels, pendingSamples[nPending].Labels)
pendingSamples[nPending].Samples[0].Timestamp = sample.t
pendingSamples[nPending].Samples[0].Value = sample.v
nPending++
//达到cfg.MaxSamplesPerSend,则发送
if nPending >= max {
s.sendSamples(ctx, pendingSamples, &buf)
nPending = 0
s.qm.metrics.pendingSamples.Sub(float64(max))
stop()
timer.Reset(time.Duration(s.qm.cfg.BatchSendDeadline))
}
//定时器事件到:cfg.BatchSendDeadLine
case <-timer.C:
if nPending > 0 {
level.Debug(s.qm.logger).Log("msg", "runShard timer ticked, sending samples", "samples", nPending, "shard", shardNum)
s.sendSamples(ctx, pendingSamples[:nPending], &buf)
s.qm.metrics.pendingSamples.Sub(float64(nPending))
nPending = 0
}
timer.Reset(time.Duration(s.qm.cfg.BatchSendDeadline))
}
}
}接收sampels数据
watcher监控指标的变化,调用QueueManager.Append()写入samples;
QueueManager.Append():
- 调用shards.enqueue将sample入队;
- 入队过程中使用2倍回退算法:入队失败,2倍时间回退,直到最大回退值;
// Append queues a sample to be sent to the remote storage. Blocks until all samples are
// enqueued on their shards or a shutdown signal is received.
func (t *QueueManager) Append(samples []record.RefSample) bool {
outer:
for _, s := range samples {
t.seriesMtx.Lock()
lbls, ok := t.seriesLabels[s.Ref]
if !ok {
t.metrics.droppedSamplesTotal.Inc()
t.samplesDropped.incr(1)
if _, ok := t.droppedSeries[s.Ref]; !ok {
level.Info(t.logger).Log("msg", "Dropped sample for series that was not explicitly dropped via relabelling", "ref", s.Ref)
}
t.seriesMtx.Unlock()
continue
}
t.seriesMtx.Unlock()
// This will only loop if the queues are being resharded.
backoff := t.cfg.MinBackoff
for {
select {
case <-t.quit:
return false
default:
}
if t.shards.enqueue(s.Ref, sample{
labels: lbls,
t: s.T,
v: s.V,
}) {
continue outer
}
t.metrics.enqueueRetriesTotal.Inc()
time.Sleep(time.Duration(backoff))
backoff = backoff * 2
if backoff > t.cfg.MaxBackoff {
backoff = t.cfg.MaxBackoff
}
}
}
return true
}shards入队的流程:
- sample的ref % shards:入队哪个shard;
- 入队用channel,直接<- sample;
// enqueue a sample. If we are currently in the process of shutting down or resharding,
// will return false; in this case, you should back off and retry.
func (s *shards) enqueue(ref uint64, sample sample) bool {
s.mtx.RLock()
defer s.mtx.RUnlock()
select {
case <-s.softShutdown:
return false
default:
}
shard := uint64(ref) % uint64(len(s.queues))
select {
case <-s.softShutdown:
return false
case s.queues[shard] <- sample:
s.qm.metrics.pendingSamples.Inc()
return true
}
}发送时min_backoff与max_backoff
发送在s.sendSamples完成,sendsamples调用sendsamplesWithBackoff:
- 若发送失败,进行backoff,初始backoff=minBackoff=30ms;
- 若继续发送失败,进行2倍backoff,直到maxBackoff=100ms;
- backoff的方式:time.Sleep(backoff);
func (s *shards) sendSamples(ctx context.Context, samples []prompb.TimeSeries, buf *[]byte) {
begin := time.Now()
err := s.sendSamplesWithBackoff(ctx, samples, buf) //具体干活
if err != nil {
level.Error(s.qm.logger).Log("msg", "non-recoverable error", "count", len(samples), "err", err)
s.qm.metrics.failedSamplesTotal.Add(float64(len(samples)))
}
// These counters are used to calculate the dynamic sharding, and as such
// should be maintained irrespective of success or failure.
s.qm.samplesOut.incr(int64(len(samples)))
s.qm.samplesOutDuration.incr(int64(time.Since(begin)))
atomic.StoreInt64(&s.qm.lastSendTimestamp, time.Now().Unix())
}具体发送动作:s.sendSamplesWithBackOff():
// sendSamples to the remote storage with backoff for recoverable errors.
func (s *shards) sendSamplesWithBackoff(ctx context.Context, samples []prompb.TimeSeries, buf *[]byte) error {
req, highest, err := buildWriteRequest(samples, *buf)
if err != nil {
// Failing to build the write request is non-recoverable, since it will
// only error if marshaling the proto to bytes fails.
return err
}
backoff := s.qm.cfg.MinBackoff
reqSize := len(*buf)
sampleCount := len(samples)
*buf = req
try := 0
// An anonymous function allows us to defer the completion of our per-try spans
// without causing a memory leak, and it has the nice effect of not propagating any
// parameters for sendSamplesWithBackoff/3.
attemptStore := func() error {
span, ctx := opentracing.StartSpanFromContext(ctx, "Remote Send Batch")
defer span.Finish()
span.SetTag("samples", sampleCount)
span.SetTag("request_size", reqSize)
span.SetTag("try", try)
span.SetTag("remote_name", s.qm.storeClient.Name())
span.SetTag("remote_url", s.qm.storeClient.Endpoint())
begin := time.Now()
err := s.qm.client().Store(ctx, *buf) ##HTTP将数据发送出去
s.qm.metrics.sentBatchDuration.Observe(time.Since(begin).Seconds())
if err != nil {
span.LogKV("error", err)
ext.Error.Set(span, true)
return err
}
return nil
}
for {
select {
case <-ctx.Done():
return ctx.Err()
default:
}
err = attemptStore()
//若发送失败
if err != nil {
// If the error is unrecoverable, we should not retry.
if _, ok := err.(recoverableError); !ok {
return err
}
// If we make it this far, we've encountered a recoverable error and will retry.
s.qm.metrics.retriedSamplesTotal.Add(float64(sampleCount))
level.Warn(s.qm.logger).Log("msg", "Failed to send batch, retrying", "err", err)
time.Sleep(time.Duration(backoff)) //通过sleep进行backoff
backoff = backoff * 2 //进行2倍回退
if backoff > s.qm.cfg.MaxBackoff { //backoff最大=cfg.MaxBackoff
backoff = s.qm.cfg.MaxBackoff
}
try++
continue
}
// Since we retry forever on recoverable errors, this needs to stay inside the loop.
s.qm.metrics.succeededSamplesTotal.Add(float64(sampleCount))
s.qm.metrics.bytesSent.Add(float64(reqSize))
s.qm.metrics.highestSentTimestamp.Set(float64(highest / 1000))
return nil
}
}