【面试宝典】软件测试工程师2021烫手精华版(第八章Python基础篇)
![]()
第八章 Python 基础
![]()
斐波那契数列求 N?

字符串反序输出?
print(a_str[::-1])
判断回文?
astr[::-1] == a_str
统计python 源代码文件中代码行数,去除注释,空行,进行输出?
python 调用cmd 并返回结果?
python 的 OS 模块。
• OS 模块调用CMD 命令有两种方式:os.popen(),os.system(). 都是用当前进程来调用。
• os.system 是无法获取返回值的。 当运行结束后接着往下面执行程序。 用法如: OS.system(“ipconfig”).
• OS.popen 带返回值的,如何获取返回值。如
• p=os.popen(cmd)
• print p.read().得到的是个字符串。
• 这两个都是用当前进程来调用,也就是说它们都是阻塞式的。管道 subprocess 模块。
• 运行原理会在当前进程下面产生子进程。
• sub=subprocess.Popen(cmd,shell=True,stdout=subprocess.PIPE)
• sub.wait()
• print sub.read()
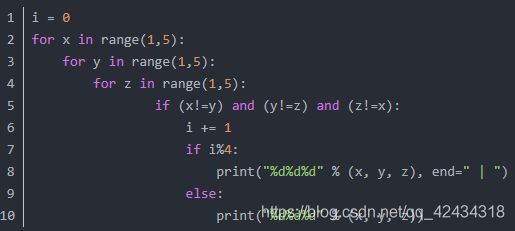
冒泡排序

1,2,3,4 这 4 个数字,能组成多少个互不相同的且无重复的三位数,都是多少?
给定一个整数 N,和一个 0-9 的数 K,要求返回 0-N 中数字 K 出现的次数
def digitCounts(self, k, n): count = 0
for i in range(n+1):
if i == 0 and i == k: count += 1
while( i // 10 >= 0 and i != 0):
j = i % 10 if j == k:
count += 1 i = i //10
return count![]()
请用 python 打印出 10000 以内的对称数(对称数特点:数字左右对称,如:1,2,11,121,1221 等)
网上找到的,不过他第一种方法跟俺的差不多,嘿嘿!!!
//方法一
2 function isSymmetryNum(start,end){
3 var flag;
4 for(var i=start;i<end+1;i++){
5 flag=true;
6 var iStr=i.toString();
7 for(var j=0,len=iStr.length;j<len/2;j++){
8 if(iStr.charAt(j)!==iStr.charAt(len-1-j)||i<10){
9 flag=false;
10 break;
11 }
12 }
13 if(flag==true){
14 console.log(i);
15 }
16
17 }
18 }
19 //方法二(更好)
20 function isSymmetryNum(start,end){
21 for(var i=start;i<end+1;i++){
22 var iInversionNumber=+(i.toString().split("").reverse().join(""));
23
24 if(iInversionNumber===i&&i>10){
25 console.log(i);
26 }
27
28 }
29 }
30 isSymmetryNum(1,10000);
![]()
判断 101-200 之间有多少个素数,并输出所有的素数
一个输入三角形的函数,输入后输出是否能组成三角形,三角形类型,请用等价类划分法设计测试用例
a,b,c=map(int ,input().split())
if a<+c and b<a+c and c<a+b: if a==b==c:
print('等边三角形') elif a==b or a==c or b==c:
if a*a+b*b==c*c or a*a+c*c==b*b or b*b+c*c==a*a:
print('等腰直角三角形') else:
print('等腰三角形')
elif a*a+b*b==c*c or a*a+c*c==b*b or b*b+c*c==a*a: print('直角三角形')
else:
print('普通三角形') else:
print('无法构成三角形')
![]()
如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们
,群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
编程题
请编写一个完整出程序,实现如下功能:从键盘输入数字 n,程序自动计算 n!,并输出。(注:n!=123……n,注 2:请使用递归实现)(可以使用任何开发语言)
- 如果现在有一台刚安装了WinXP 的计算机,请简单说明如何能够让以上程序得以运行。
- 写代码将如下数据从小到大排序,语言不限。(不可以直接使用 sort()等排序方法) 234,82,5,10,86,90
- 如何使用Python 发送一封邮件?
- Linux 下如何查看ip 地址,如何用Python 或 TCL 删除当前文件夹下所有文件以及目录?
- 给 x 变量赋值为 abccaefs,并统计 x 变量中单词出现的次数(java 或Python 任选一种语言编写)

一、 输入与输出
代码中要修改不可变数据会出现什么问题? 抛出什么异常?
代码不会正常运行,抛出 TypeError 异常。
代码中要修改不可变数据会出现什么问题? 抛出什么异常?
代码不会正常运行,抛出 TypeError 异常。
print 调用 Python 中底层的什么方法?
print 方法默认调用 sys.stdout.write 方法,即往控制台打印字符串。
简述你对 input()函数的理解?
在 Python3 中,input()获取用户输入,不论用户输入的是什么,获取到的都是字符串类型的。在 Python2 中有 raw_input()和 input(), raw_input()和 Python3 中的 input()作用是一样的, input()输入的是什么数据类型的,获取到的就是什么数据类型的。
python 两层列表怎么提取第二层的元素
aa = [[(55736,)], [(55739,)], [(55740,), (55801,)], [(55748,)], [(55783,), (55786,), (55787,), (55788,
)], [(55817,), (55821,)], [(55818,)]]
def getelement(aa): for elem in aa:
if type(elem)==type([]):
for element in getelement(elem): yield element
else:yield elem
for elem in getelement(aa):print(elem)(55736,) (55739,)
(55740,)
(55801,)
(55748,)
(55783,)
(55786,)
(55787,)
(55788,)
(55817,)
(55821,)
(55818,)
二、 条件与循环
阅读下面的代码,写出 A0,A1 至 An 的最终值?

![]()
range 和 xrange 的区别?
两者用法相同,不同的是 range 返回的结果是一个列表,而 xrange 的结果是一个生成器,前者是直接开辟一块内存空间来保存列表,后者是边循环边使用,只有使用时才会开辟内存空间,所以当列表
很长时,使用 xrange 性能要比 range 好。
考虑以下 Python 代码,如果运行结束,命令行中的运行结果是什么?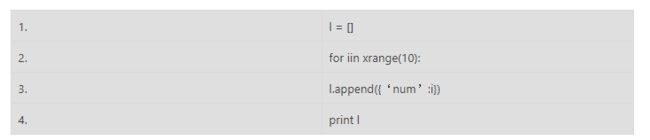
在考虑以下代码,运行结束后的结果是什么?
三、 字典
dict:字典,字典是一组键(key)和值(value)的组合,通过键(key)进行查找,没有顺序, 使用大括号”{}”;
应用场景:
dict,使用键和值进行关联的数据;
现有字典 d={‘a’:24,‘g’:52,‘i’:12,‘k’:33}请按字典中的 value 值进行排序?
sorted(d.items(),key = lambda x:x[1]) 。
说一下字典和 json 的区别?
字典是一种数据结构,json 是一种数据的表现形式,字典的 key 值只要是能 hash 的就行,json 的必须是字符串。
什么是可变、不可变类型?
可变不可变指的是内存中的值是否可以被改变,不可变类型指的是对象所在内存块里面的值不可以改变,有数值、字符串、元组;可变类型则是可以改变,主要有列表、字典。
存入字典里的数据有没有先后排序?
存入的数据不会自动排序,可以使用 sort 函数对字典进行排序。
字典推导式?
d = {key: value for (key, value) in iterable}
现有字典 d={‘a’:24,’g’:52,’l’:12,’k’:33}请按字 典中的 value 值进行排序?
sorted(d.items(),key = lambda x:x[1])
四、 字符串
str:字符串是 Python 中最常用的数据类型。我们可以使用引号('或")来创建字符串。
如何理解 Python 中字符串中的\字符?
有三种不同的含义:
1、转义字符
2、路径名中用来连接路径名
3、编写太长代码手动软换行。
请反转字符串“aStr”?
print(‘aStr’[::-1])
请按 alist 中元素的 age 由大到小排序
alist [{‘name’:‘a’,‘age’:20},{‘name’:‘b’,‘age’:30},{‘name’:‘c’,‘age’:25}] def sort_by_age(list1):
return sorted(alist,key=lambda x:x[‘age’],reverse=True)![]()
五、 列表
list:是 Python 中使用最频繁的数据类型,在其他语言中通常叫做数组,通过索引进行查找,使用方括号”[]”,列表是有序的集合。应用场景:定义列表使用 [ ] 定义,数据之间使用 “,”分割。
列表的索引从 0 开始:索引就是数据在列表中的位置编号,索引又可以被称为下标。
【注意】: 从列表中取值时,如果超出索引范围,程序会产生异常。IndexError: list index out of range
列表增加
列表名.insert(index, 数据):在指定位置插入数据(位置前有空元素会补位)。 # 往列表 name_list 下标为 0 的地方插入数据
In [3]: name_list.insert(0, “Sasuke”) In [4]: name_list
Out[4]: [‘Sasuke’, ‘zhangsan’, ‘lisi’, ‘wangwu’, ‘zhaoliu’]
现有的列表下标是 0-4,如果我们要在下标是 6 的地方插入数据,那个会自动插入到下标为 5 的地方, 也就是# 插入到最后
In [5]: name_list.insert(6, “Tom”) In [6]: name_list
Out[6]: [‘Sasuke’, ‘zhangsan’, ‘lisi’, ‘wangwu’, ‘zhaoliu’, ‘Tom’]
列表名.append(数据):在列表的末尾追加数据(最常用的方法)。
In [7]: name_list.append(“Python”)
In [8]: name_list
Out[8]: [‘Sasuke’, ‘zhangsan’, ‘lisi’, ‘wangwu’, ‘zhaoliu’, ‘Tom’, ‘Python’]列表.extend(Iterable):将可迭代对象中的元素追加到列表。
有两个列表 a 和 b a.extend(b) 会将 b 的元素追加到列表In [10]: a = [11, 22, 33]
In [11]: b = [44, 55, 66]
In [12]: a.extend(b)
In [13]: a
Out[13]: [11, 22, 33, 44, 55, 66]# 有列表 c 和 字符串 c In [14]: c = [‘j’, ‘a’, ‘v’, ‘a’]
In [15]: d = “python” In [16]: c.extend(d)
In [17]: c
Out[17]: [‘j’, ‘a’, ‘v’, ‘a’, ‘p’, ‘y’, ‘t’, ‘h’, ‘o’, ‘n’]
取值和修改取值:列表名[index] :根据下标来取值。
In [19]: name_list = [“zhangsan”, “lisi”, “wangwu”, “zhaoliu”] In [20]: name_list[0]
Out[20]: ‘zhangsan’ In [21]: name_list[3] Out[21]: ‘zhaoliu’
修改:列表名[index] = 数据:修改指定索引的数据。
In [22]: name_list[0] = “Sasuke” In [23]: name_list
Out[23]: [‘Sasuke’, ‘lisi’, ‘wangwu’, ‘zhaoliu’]
删除 del 列表名[index]:删除指定索引的数据。
In [25]: name_list = [“zhangsan”, “lisi”, “wangwu”, “zhaoliu”]# 删除索引是 1 的数据 In [26]: del name_list[1]
In [27]: name_list
Out[27]: [‘zhangsan’, ‘wangwu’, ‘zhaoliu’]
列表名.remove(数据):删除第一个出现的指定数据。
In [30]: name_list = [“zhangsan”, “lisi”, “wangwu”, “zhaoliu”, “lisi”]# 删除 第一次出现的 lisi 的数据 In [31]: name_list.remove(“lisi”)
In [32]: name_list
Out[32]: [‘zhangsan’, ‘wangwu’, ‘zhaoliu’, ‘lisi’]
列表名.pop():删除末尾的数据,返回值: 返回被删除的元素。
In [33]: name_list = [“zhangsan”, “lisi”, “wangwu”, “zhaoliu”]# 删除最后一个元素 In [34]: name_list.pop()
Out[34]: ‘zhaoliu’ In [35]: name_list
Out[35]: [‘zhangsan’, ‘lisi’, ‘wangwu’]
列表名.pop(index):删除指定索引的数据,返回被删除的元素。
In [36]: name_list = [“zhangsan”, “lisi”, “wangwu”, “zhaoliu”]# 删除索引为 1 的数据 lisi In [37]: name_list.pop(1)
Out[37]: ‘lisi’
In [38]: name_list
Out[38]: [‘zhangsan’, ‘wangwu’, ‘zhaoliu’]
列表名.clear():清空整个列表的元素。
In [40]: name_list = [“zhangsan”, “lisi”, “wangwu”, “zhaoliu”] In [41]: name_list.clear()
In [42]: name_list Out[42]: []![]()
排序列表名.sort():升序排序 从小到大。
In [43]: a = [33, 44, 22, 66, 11]
In [44]: a.sort()
In [45]: a
Out[45]: [11, 22, 33, 44, 66]
列表名.sort(reverse=True):降序排序 从大到小。
In [46]: a = [33, 44, 22, 66, 11]
In [47]: a.sort(reverse=True)
In [48]: a
Out[48]: [66, 44, 33, 22, 11]
列表名.reverse():列表逆序、反转。
In [50]: a = [11, 22, 33, 44, 55]
In [51]: a.reverse()
In [52]: a
Out[52]: [55, 44, 33, 22, 11]
len(列表名):得到列表的长度。
In [53]: a = [11, 22, 33, 44, 55]
In [54]: len(a)
Out[54]: 5
列表名.count(数据):数据在列表中出现的次数。
In [56]: a = [11, 22, 11, 33, 11]
In [57]: a.count(11)
Out[57]: 3
列表名.index(数据):数据在列表中首次出现时的索引,没有查到会报错。
In [59]: a = [11, 22, 33, 44, 22]
In [60]: a.index(22)
Out[60]: 1
if 数据 in 列表: 判断列表中是否包含某元素。
a = [11, 22, 33, 44 ,55]
if 33 in a:
print("找到了 ")
![]()
循环遍历
使用 while 循环:
a = [11, 22, 33, 44, 55]
i = 0
while i < len(a): print(a[i])
i += 1
使用 for 循环:
a = [11, 22, 33, 44, 55]
for i in a:
print(i)
写一个列表生成式,产生一个公差为 11 的等差数列
print([x*11 for x in range(10)])
给定两个列表,怎么找出他们相同的元素和不同的元素?
list1 = [1,2,3]
.
list2 = [3,4,5]
.
set1 = set(list1)
.
set2 = set(list2)
.
print(set1&set2)
.
print(set1^set2)
.
请写出一段 Python 代码实现删除一个 list 里面的重复元素?
比较容易记忆的是用内置的 set:
1
l1 = ['b','c','d','b','c','a','a']
.
2
l2 = list(set(l1))
.
3
print l2
.
如果想要保持他们原来的排序:用 list 类的 sort 方法:
1
l1 = ['b','c','d','b','c','a','a']
.
2
l2 = list(set(l1))
.
3
l2.sort(key=l1.index)
.
4
print l2
.
也可以这样写:
1
l1 = ['b','c','d','b','c','a','a']
.
2
l2 = sorted(set(l1),key=l1.index)
.
3
print l2
.
也可以用遍历:
1
l1 = ['b', 'c', 'd', 'b', 'c', 'a', 'a']
.
2
l2 = []
.
3
for i in l1:
.
4
if not i in l2:
.
5
l2.append(i)
.
6
print l2
.
给定两个 list A ,B,请用找出 A ,B 中相同的元素,A ,B 中不同的元素
A、B 中相同元素:print(set(A)&set(B)) A、B 中不同元素:print(set(A)^set(B))
新的默认列表只在函数被定义的那一刻创建一次。当 extendList 被没有指定特定参数 list 调用时,这组 list 的值
随后将被使用。这是因为带有默认参数的表达式在函数被定义的时候被计算,不是在调用的时候被计算。![]()
六、 元组
tuple:元组,元组将多样的对象集合到一起,不能修改,通过索引进行查找,使用括号”()”; 应用场景:把一些数据当做一个整体去使用,不能修改
七、 集合
set:set 集合,在 Python 中的书写方式的{},集合与之前列表、元组类似,可以存储多个数据,但是这些数
据是不重复的。集合对象还支持 union(联合), intersection(交), difference(差)和 ysmmetric_difference(对称差集)等数学运算.
快速去除列表中的重复元素
In [4]: a = [11,22,33,33,44,22,55]
In [5]: set(a)
Out[5]: {11, 22, 33, 44, 55}
交集:共有的部分
In [7]: a = {11,22,33,44,55}
In [8]: b = {22,44,55,66,77}
In [9]: a&b
Out[9]: {22, 44, 55}
并集:总共的部分
In [11]: a = {11,22,33,44,55}
In [12]: b = {22,44,55,66,77}
In [13]: a | b
Out[13]: {11, 22, 33, 44, 55, 66, 77}
差集:另一个集合中没有的部分
In [15]: a = {11,22,33,44,55}
In [16]: b = {22,44,55,66,77} In [17]: b - a
Out[17]: {66, 77}
对称差集(在 a 或 b 中,但不会同时出现在二者中)
In [19]: a = {11,22,33,44,55}
In [20]: b = {22,44,55,66,77}
In [21]: a ^ b
Out[21]: {11, 33, 66, 77}
![]()
八、 文件操作
4G 内存怎么读取一个 5G 的数据?(2018-3-30-lxy)
方法一:
可以通过生成器,分多次读取,每次读取数量相对少的数据(比如 500MB)进行处理,处理结束后在读取后面的 500MB 的数据。
方法二:
可以通过 linux 命令 split 切割成小文件,然后再对数据进行处理,此方法效率比较高。可以按照行数切割,可以按照文件大小切割。
现在要处理一个大小为 10G 的文件,但是内存只有 4G,如果在只修改 get_lines 函数而其他代码保持不变的情况下,应该如何实现?需要考虑的问题都有哪些?
要考虑到的问题有:内存只有 4G 无法一次性读入 10G 的文件,需要分批读入。分批读入数据要记录每次读入数据的位置。分批每次读入数据的大小,太小就会在读取操作上花费过多时间。
read、readline 和 readlines 的区别?
read:读取整个文件。 readline:读取下一行,使用生成器方法。 readlines:读取整个文件到一个迭代器以供我们遍历。![]()
九、 函数
Python 函数调用的时候参数的传递方式是值传递还是引用传递?
Python 的参数传递有:位置参数、默认参数、可变参数、关键字参数。函数的传值到底是值传递还是引用传递,要分情况:
不可变参数用值传递:像整数和字符串这样的不可变对象,是通过拷贝进行传递的,因为你无论如何都不可能在原处改变
不可变对象
可变参数是引用传递的:
比如像列表,字典这样的对象是通过引用传递、和 C 语言里面的用指针传递数组很相似,可变对象能在函数内部改变。
对缺省参数的理解 ?
缺省参数指在调用函数的时候没有传入参数的情况下,调用默认的参数,在调用函数的同时赋值时,所传入的参数会替代默认参数。
*args 是不定长参数,他可以表示输入参数是不确定的,可以是任意多个。
**kwargs 是关键字参数,赋值的时候是以键 = 值的方式,参数是可以任意多对在定义函数的时候不确定会有多少参数会传入时,就可以使用两个参数。
为什么函数名字可以当做参数用?
Python 中一切皆对象,函数名是函数在内存中的空间,也是一个对象。
Python 中 pass 语句的作用是什么?
在编写代码时只写框架思路,具体实现还未编写就可以用 pass 进行占位,使程序不报错,不会进行任何操作。![]()
十、 内建函数
map 函数和 reduce 函数?
①从参数方面来讲:
map()包含两个参数,第一个参数是一个函数,第二个是序列(列表 或元组)。其中,函数(即 map 的第一个参数位置的函数)可以接收一个或多个参数。
reduce()第一个参数是函数,第二个是序列(列表或元组)。但是,其函数必须接收两个参数。
②从对传进去的数值作用来讲:
map()是将传入的函数依次作用到序列的每个元素,每个元素都是独自被函数“作用”一次 。reduce()是将传人的函数作用在序列的第一个元素得到结果后,把这个结果继续与下一个元素作用
(累积计算)。
递归函数停止的条件?
递归的终止条件一般定义在递归函数内部,在递归调用前要做一个条件判断,根据判断的结果选择是继续调用自身,还是 return;返回终止递归。
终止的条件:
判断递归的次数是否达到某一限定值
判断运算的结果是否达到某个范围等,根据设计的目的来选择
回调函数,如何通信的?
回调函数是把函数的指针(地址)作为参数传递给另一个函数,将整个函数当作一个对象,赋值给调 用的函数。
Python 主要的内置数据类型都有哪些? print dir( ‘a ’) 的输出?
内建类型:布尔类型、数字、字符串、列表、元组、字典、集合;输出字符串‘a’的内建方法;
print(list(map(lambda x: x * x, [y for y in range(3)])))的输出?
[0, 1, 4]![]()
十一、 Lambda
什么是 lambda 函数? 有什么好处?
lambda 函数是一个可以接收任意多个参数(包括可选参数)并且返回单个表达式值的函数
lambda 函数比较轻便,即用即仍,很适合需要完成一项功能,但是此功能只在此一处使用,连名字都很随意的情况下;
匿名函数,一般用来给 filter, map 这样的函数式编程服务;作为回调函数,传递给某些应用,比如消息处理
什么是 lambda 函数?它有什么好处?写一个匿名函数求两个数的和?
lambda 函数是匿名函数;使用 lambda 函数能创建小型匿名函数。这种函数得名于省略了用 def 声明函数的标准步骤;
1
f = lambda x,y:x+y
2
print(f(2017,2018))
.
![]()
十二、 面向对象
Python 中的可变对象和不可变对象?
不可变对象,该对象所指向的内存中的值不能被改变。当改变某个变量时候,由于其所指的值不能被改变, 相当于把原来的值复制一份后再改变,这会开辟一个新的地址,变量再指向这个新的地址。
可变对象,该对象所指向的内存中的值可以被改变。变量(准确的说是引用)改变后,实际上是其所指的值直接发生改变,并没有发生复制行为,也没有开辟新的出地址,通俗点说就是原地改变。
Python 中,数值类型(int 和 float)、字符串 str、元组 tuple 都是不可变类型。而列表 list、字典 dict、集合 set 是可变类型。
Python 中is 和==的区别?
is 判断的是 a 对象是否就是 b 对象,是通过 id 来判断的。
==判断的是 a 对象的值是否和 b 对象的值相等,是通过 value 来判断的。
Python 的魔法方法?
魔法方法就是可以给你的类增加魔力的特殊方法,如果你的对象实现 (重载)了这些方法中的某一个,那么这个
方法就会在特殊的情况下被 Python 所调用,你可以定义自己想要的行为,而这一切都是自动发生的。 它们经常是两个下划线包围来命名的(比如 init , lt ),Python 的魔法方法是非常强大的,所以了解其使用方法也变得尤为重要! init 构造器,当一个实例被创建的时候初始化的方法。但是它并 不是实例化调用的第一个方法。
new 才是实例化对象调用的第一个方法,它只取下 cls 参数,并把 其他参数传给 init 。 new 很少使用,但是也有它适合的场景,尤其 是当类继承自一个像元组或者字符串这样不经常改变的类型的时候。
call 允许一个类的实例像函数一样被调用 。
getitem 定义获取容器中指定元素的行为,相当于 self[key] 。
getattr 定义当用户试图访问一个不存在属性的时候的行为 。
setattr 定义当一个属性被设置的时候的行为 。
getattribute 定义当一个属性被访问的时候的行为 。
面向对象中怎么实现只读属性?
1、将对象私有化,通过共有方法提供一个读取数据的接口。class person:
def init (self,x): self. age = 10;
def age(self):
return self. age; t = person(22)
t. age = 100 print(t.age())
2、最好的方法class MyCls(object):
weight = 50
@property #以访问属性的方式来访问 weight 方法 def weight(self):
return self. weight if name == ’ main ':
obj = MyCls() print(obj.weight) obj.weight = 12
Traceback (most recent call last):
50
File “C:/PythonTest/test.py”, line 11, in obj.weight = 12
AttributeError: can’t set attribute
谈谈你对面向对象的理解?
面向对象是相对于面向过程而言的。面向过程语言是一种基于功能分析的、以算法为中心的程序设计方法;而面向对象是一种基于结构分析的、以数据为中心的程序设计思想。在面向对象语言中有一个有很重要东西,叫做类。面向对象有三大特性:封装、继承、多态。![]()
十三、 正则表达式
Python 里 match 与 search 的 区 别 ?
match()函数只检测 RE 是不是在 string 的开始位置匹配, search()会扫描整个 string 查找匹配;也就是说 match()只有在 0 位置匹配成功的话才有返回,如果不是开始位置匹配成功的话,match()就返回 none。
Python 字符串查找和替换?
re.findall(r’目的字符串’,’原有字符串’) #查询 re.findall(r’cast’,‘itcast.cn’)[0]
re.sub(r‘要替换原字符’,’要替换新字符’,’原始字符串’) re.sub(r’cast’,‘heima’,‘itcast.cn’)
用 Python 匹配 HTML g tag 的时候,<.> 和 <.?> 有什么区别?
<.>是贪婪匹配,会从第一个“<”开始匹配,直到最后一个“>”中间所有的字符都会匹配到,中间可能会包含“<>”。
<.?>是非贪婪匹配,从第一个“<”开始往后,遇到第一个“>”结束匹配,这中间的字符串都会匹配到,但是不会有“<>”。
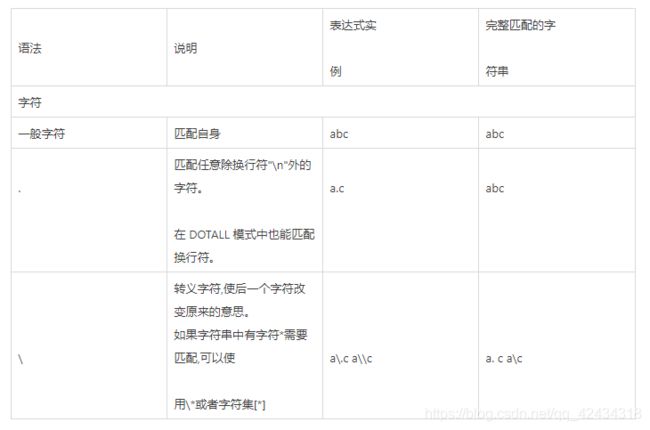
请写出下列正则关键字的含义?
如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们
,群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!

![]()
十四、 异常
在 except 中 return 后还会不会执行 finally 中的代码?怎么抛出自定义异常?
会继续处理 finally 中的代码;用 raise 方法可以抛出自定义异常。
介绍一下 except 的作用和用法?
except: #捕获所有异常 except: <异常名>: #捕获指定异常except:<异常名 1, 异常名 2> : 捕获异常 1 或者异常 2 except:<异常名>,<数据>:捕获指定异常及其附加的数据
except:<异常名 1,异常名 2>:<数据>:捕获异常名 1 或者异常名 2,及附加的数据![]()
十五、 模块与包
常用的 Python 标准库都有哪些?
os 操作系统,time 时间,random 随机,pymysql 连接数据库,threading 线程,multiprocessing进程,queue 队列。第三方库:
django 和 flask 也是第三方库,requests,virtualenv,selenium,scrapy,xadmin,celery, re,hashlib,md5。常用的科学计算库(如 Numpy,Scipy,Pandas)。
赋值、浅拷贝和深拷贝的区别?
一、 赋值在 Python 中,对象的赋值就是简单的对象引用,这点和 C++不同,如下所示: a = [1,2,“hello”,[‘python’, ‘C++’]]
b = a
在上述情况下,a 和 b 是一样的,他们指向同一片内存,b 不过是 a 的别名,是引用。
我们可以使用 b is a 去判断,返回 True,表明他们地址相同,内容相同,也可以使用 id()函数来查看两个列表的地址是否相同。
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了对象的引用。也就是
说除了 b 这个名字之外,没有其他的内存开销。修改了 a,也就影响了 b,同理,修改了 b,也就影响了 a。
二、 浅拷贝(shallow copy)
浅拷贝会创建新对象,其内容非原对象本身的引用,而是原对象内第一层对象的引用。浅拷贝有三种形式:切片操作、工厂函数、copy 模块中的 copy 函数。
比如上述的列表 a;
切片操作:b = a[:] 或者 b = [x for x in a];工厂函数:b = list(a); copy 函数:b = copy.copy(a);
浅拷贝产生的列表 b 不再是列表 a 了,使用 is 判断可以发现他们不是同一个对象,使用 id 查看,他们也不指向同一片内存空间。但是当我们使用 id(x) for x in a 和 id(x) for x in b 来查看 a 和 b 中元素的地址时,可以看到二者包含的元素的地址是相同的。
在这种情况下,列表 a 和 b 是不同的对象,修改列表 b 理论上不会影响到列表 a。
但是要注意的是,浅拷贝之所以称之为浅拷贝,是它仅仅只拷贝了一层,在列表 a 中有一个嵌套的 list,如果我们修改了它,情况就不一样了。
比如:a[3].append(‘java’)。查看列表 b,会发现列表 b 也发生了变化,这是因为,我们修改了嵌套的 list,
修改外层元素,会修改它的引用,让它们指向别的位置,修改嵌套列表中的元素,列表的地址并未发生变化,指向的都是用一个位置。
三、 深拷贝(deep copy)
深拷贝只有一种形式,copy 模块中的 deepcopy()函数。
深拷贝和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因此,它的时间和空间开销要高。
同样的对列表 a,如果使用 b = copy.deepcopy(a),再修改列表 b 将不会影响到列表 a,即使嵌
套的列表具有更深的层次,也不会产生任何影响,因为深拷贝拷贝出来的对象根本就是一个全新的对象,不再与原来的对象有任何的关联。
四、 拷贝的注意点?
对于非容器类型,如数字、字符,以及其他的“原子”类型,没有拷贝一说,产生的都是原对象的引用。 如果元组变量值包含原子类型对象,即使采用了深拷贝,也只能得到浅拷贝。![]()
init 和 new 的区别?
init 在对象创建后,对对象进行初始化。
new 是在对象创建之前创建一个对象,并将该对象返回给 init。
Python 里面如何生成随机数?
在 Python 中用于生成随机数的模块是 random,在使用前需要 import. 如下例子可以酌情列举: random.random():生成一个 0-1 之间的随机浮点数; random.uniform(a, b):生成[a,b]之间的浮点数;
random.randint(a, b):生成[a,b]之间的整数;
random.randrange(a, b, step) :在指定的集合 [a,b) 中,以 step 为基数随机取一个数; random.choice(sequence):从特定序列中随机取一个元素,这里的序列可以是字符串,列表,元组等。
输入某年某月某日, 判断这一天是这一年的第几天?( 可以用Python 标准库)
import datetime def dayofyear():
year = input(“请输入年份:”) month = input(“请输入月份:”) day = input(“请输入天:”)
date1 = datetime.date(year=int(year),month=int(month),day=int(day)) date2 = datetime.date(year=int(year),month=1,day=1)
return (date1 - date2 + 1).days
打乱一个排好序的 list 对象 alist?
import random random.shuffle(alist)
说明一下 os.path 和 sys.path 分别代表什么?
os.path 主要是用于对系统路径文件的操作。 sys.path 主要是对 Python 解释器的系统环境参数的操作
(动态的改变 Python 解释器搜索路径)。
Python 中的 os 模块常见方法?
• os.remove()删除文件
• os.rename()重命名文件
• os.walk()生成目录树下的所有文件名
• os.chdir()改变目录
• os.mkdir/makedirs 创建目录/多层目录
• os.rmdir/removedirs 删除目录/多层目录
• os.listdir()列出指定目录的文件
• os.getcwd()取得当前工作目录
• os.chmod()改变目录权限
• os.path.basename()去掉目录路径,返回文件名
• os.path.dirname()去掉文件名,返回目录路径
• os.path.join()将分离的各部分组合成一个路径名
• os.path.split()返回(dirname(),basename())元组
• os.path.splitext()(返回 filename,extension)元组
• os.path.getatime\ctime\mtime 分别返回最近访问、创建、修改时间
• os.path.getsize()返回文件大小 os.path.exists()是否存在
• os.path.isabs()是否为绝对路径
• os.path.isdir()是否为目录
• os.path.isfile()是否为文件![]()
Python 的 sys 模块常用方法?
• sys.argv 命令行参数 List,第一个元素是程序本身路径
• sys.modules.keys() 返回所有已经导入的模块列表
• sys.exc_info() 获取当前正在处理的异常类,exc_type、exc_value、exc_traceback 当前处理的
• 异常详细信息
• sys.exit(n) 退出程序,正常退出时 exit(0)
• sys.hexversion 获取 Python 解释程序的版本值,16 进制格式如:0x020403F0
• sys.version 获取 Python 解释程序的版本信息
• sys.maxint 最大的 Int 值
• sys.maxunicode 最大的 Unicode 值
• sys.modules 返回系统导入的模块字段,key 是模块名,value 是模块
• sys.path 返回模块的搜索路径,初始化时使用 PYTHONPATH 环境变量的值
• sys.platform 返回操作系统平台名称
• sys.stdout 标准输出
• sys.stdin 标准输入
• sys.stderr 错误输出
• sys.exc_clear() 用来清除当前线程所出现的当前的或最近的错误信息
• sys.exec_prefix 返回平台独立的 python 文件安装的位置
• sys.byteorder 本地字节规则的指示器,big-endian 平台的值是’big’,little-endian 平台的值是
• ‘little’
• sys.copyright 记录 python 版权相关的东西
• sys.api_version 解释器的 C 的 API 版本
• sys.version_info 元组则提供一个更简单的方法来使你的程序具备 Python 版本要求功能
模块和包是什么
在 Python 中,模块是搭建程序的一种方式。每一个 Python 代码文件都是一个模块,并可以引用其他的模块,比如对象和属性。
一个包含许多 Python 代码的文件夹是一个包。一个包可以包含模块和子文件夹。![]()
十六、 Python 特 性
Python 是强语言类型还是弱语言类型?
Python 是强类型的动态脚本语言。强类型:不允许不同类型相加。
动态:不使用显示数据类型声明,且确定一个变量的类型是在第一次给它赋值的时候。脚本语言:一般也是解释型语言,运行代码只需要一个解释器,不需要编译。
谈一下什么是解释性语言,什么是编译性语言?
计算机不能直接理解高级语言,只能直接理解机器语言,所以必须要把高级语言翻译成机器语言,计算机才能执行高级语言编写的程序。
解释性语言在运行程序的时候才会进行翻译。
编译型语言写的程序在执行之前,需要一个专门的编译过程,把程序编译成机器语言(可执行文件)。
Python 中有日志吗?怎么使用?
有日志。
Python 自带 logging 模块,调用 logging.basicConfig()方法,配置需要的日志等级和相应的参数,
Python 解释器会按照配置的参数生成相应的日志。
Python 是如何进行类型转换的?
内建函数封装了各种转换函数,可以使用目标类型关键字强制类型转换,进制之间的转换可以用int(‘str’,base=’n’)将特定进制的字符串转换为十进制,再用相应的进制转换函数将十进制转换 为目标进制。
可以使用内置函数直接转换的有: list---->tuple tuple(list)
tuple---->list list(tuple)
工具安装问题
windows 环境
Python2 无法安装 mysqlclient。Python3 无法安装 MySQL-python、 flup、functools32、
Gooey、Pywin32、 webencodings。 matplotlib 在 python3 环境中安装报错:The following required packages can not be
built:freetype, png。需要手动下载安装源码包安装解决。
scipy 在 Python3 环境中安装报错,numpy.distutils.system_info.NotFoundError,需要自己手
工下载对应的安装包,依赖 numpy,pandas 必须严格根据 python 版本、操作系统、64 位与否。运行matplotlib 后发现基础包 numpy+mkl 安装失败,需要自己下载,国内暂无下载源
centos 环境下
Python2 无法安装 mysql-python 和 mysqlclient 包,报错:EnvironmentError: mysql_config not found,解决方案是安装 mysql-devel 包解决。使用 matplotlib 报错:no module named _tkinter,
安装 Tkinter、tk-devel、tc-devel 解决。 pywin32 也无法在 centos 环境下安装。
关于 Python 程序的运行方面,有什么手段能提升性能?
使用多进程,充分利用机器的多核性能
对于性能影响较大的部分代码,可以使用 C 或 C++编写
对于 IO 阻塞造成的性能影响,可以使用 IO 多路复用来解决尽量使用 Python 的内建函数
尽量使用局部变量
Python 中的作用域?
Python 中,一个变量的作用域总是由在代码中被赋值的地方所决定。当 Python 遇到一个变量的话它会按照这的顺序进行搜索:
本地作用域(Local)—>当前作用域被嵌入的本地作用域(Enclosing locals)—>全局/模块作用域 (Global)—>内置作用域(Built-in)。
什么是 Python?
• Python 是一种编程语言,它有对象、模块、线程、异常处理和自动内存管理,可以加入其他语言的对比。
• Python 是一种解释型语言,Python 在代码运行之前不需要解释。
• Python 是动态类型语言,在声明变量时,不需要说明变量的类型。
• Python 适合面向对象的编程,因为它支持通过组合与继承的方式定义类。
• 在 Python 语言中,函数是第一类对象。
• Python 代码编写快,但是运行速度比编译型语言通常要慢。
• Python 用途广泛,常被用走"胶水语言",可帮助其他语言和组件改善运行状况。
• 使用 Python,程序员可以专注于算法和数据结构的设计,而不用处理底层的细节。
什么是 Python 的命名空间?
在 Python 中,所有的名字都存在于一个空间中,它们在该空间中存在和被操作——这就是命名空间。它就好像一个盒子,每一个变量名字都对应装着一个对象。当查询变量的时候,会从该盒子里面寻找相应的对象。
你所遵循的代码规范是什么?请举例说明其要求?
PEP8 规范。
- 变量
常量:大写加下划线 USER_CONSTANT。
私有变量 : 小写和一个前导下划线 _private_value。
Python 中不存在私有变量一说,若是遇到需要保护的变量,使用小写和一个前导下划线。但这只是程序员之间的一个约定,用于警告说明这是一个私有变量,外部类不要去访问它。但实际上,外部类还是可以访问到这个变量。
内置变量 : 小写,两个前导下划线和两个后置下划线 class 两个前导下划线会导致变量在解释期间被更名。这是为了避免内置变量和其他变量产生冲突。用户定义的变量要严格避免这种风格。以免导致混乱。 - 函数和方法
总体而言应该使用,小写和下划线。但有些比较老的库使用的是混合大小写,即首单词小写,之后每个
单词第一个字母大写,其余小写。但现在,小写和下划线已成为规范。私有方法 :小写和一个前导下划线
这里和私有变量一样,并不是真正的私有访问权限。同时也应该注意一般函数不要使用两个前导下划线 (当遇到两个前导下划线时,Python 的名称改编特性将发挥作用)。
特殊方法 :小写和两个前导下划线,两个后置下划线这种风格只应用于特殊函数,比如操作符重载等。函数参数 : 小写和下划线,缺省值等号两边无空格 - 类
类总是使用驼峰格式命名,即所有单词首字母大写其余字母小写。类名应该简明,精确,并足以从中理解类所完成的工作。常见的一个方法是使用表示其类型或者特性的后缀,例如:
SQLEngine,MimeTypes 对于基类而言,可以使用一个 Base 或者 Abstract 前缀 BaseCookie, AbstractGroup - 模块和包
除特殊模块 init 之外,模块名称都使用不带下划线的小写字母。若是它们实现一个协议,那么通常使用 lib 为后缀,例如:
import smtplib import os import sys - 关于参数
不要用断言来实现静态类型检测。断言可以用于检查参数,但不应仅仅是进行静态类型检测。
Python 是动态类型语言,静态类型检测违背了其设计思想。断言应该用于避免函数不被毫无意义的调用。
不要滥用 *args 和 **kwargs。*args 和 **kwargs 参数可能会破坏函数的健壮性。它们使签名变得模糊,而且代码常常开始在不应该的地方构建小的参数解析器。 - 其他
使用 has 或 is 前缀命名布尔元素 is_connect = True has_member = False
用复数形式命名序列 members = [‘user_1’, ‘user_2’] 用显式名称命名字典
person_address = {‘user_1’:‘10 road WD’, ‘user_2’ : ‘20 street huafu’}避免通用名称
诸如 list, dict, sequence 或者 element 这样的名称应该避免。避免现有名称诸如 os, sys 这种系统已经存在的名称应该避免。 - 一些数字
一行列数 : PEP 8 规定为 79 列。根据自己的情况,比如不要超过满屏时编辑器的显示列数。
一个函数 : 不要超过 30 行代码, 即可显示在一个屏幕类,可以不使用垂直游标即可看到整个函数。一个类 : 不要超过 200 行代码,不要有超过 10 个方法。一个模块 不要超过 500 行。 - 验证脚本可以安装一个 pep8 脚本用于验证你的代码风格是否符合 PEP8。
![]()
十七、 Python2 与 Python3 的 区 别
如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们
,群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
核心类差异
a. Python3 对 Unicode 字符的原生支持。
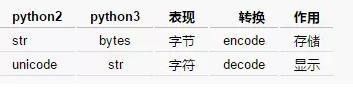
Python2 中使用 ASCII 码作为默认编码方式导致 string 有两种类型 str 和 unicode,Python3 只支持 unicode 的 string。Python2 和 Python3 字节和字符对应关系为:
a. Python3 采用的是绝对路径的方式进行 import。
Python2 中相对路径的 import 会导致标准库导入变得困难(想象一下,同一目录下有 file.py,如何同时导入这个文件和标准库 file)。Python3 中这一点将被修改,如果还需要导入同一目录的文件必须使用绝对路径,否则只能使用相关导入的方式来进行导入。
a. Python2 中存在老式类和新式类的区别,Python3 统一采用新式类。新式类声明要求继承 object,
必须用新式类应用多重继承。
a. 缩进严格程度
Python3 使用更加严格的缩进。Python2 的缩进机制中,1 个 tab 和 8 个 space 是等价的,所以在缩进中可以同时允许 tab 和 space 在代码中共存。这种等价机制会导致部分 IDE 使用存在问题。
Python3 中 1 个 tab 只能找另外一个 tab 替代,因此 tab 和 space 共存会导致报错:TabError: inconsistent use of tabs and spaces in indentation.
废弃类差异
- print 语句被 Python3 废弃,统一使用 print 函数
- exec 语句被 python3 废弃,统一使用 exec 函数
- execfile 语句被 Python3 废弃,推荐使用 exec(open("./filename").read())
- 不相等操作符"<>“被 Python3 废弃,统一使用”!="
- long 整数类型被 Python3 废弃,统一使用 int
- xrange 函数被 Python3 废弃,统一使用 range,Python3 中 range 的机制也进行修改并提高了大数据集生成效率
- Python3 中这些方法再不再返回 list 对象:dictionary 关联的 keys()、values()、items(),zip(),map(), filter(),但是可以通过 list 强行转换:
- mydict={“a”:1,“b”:2,“c”:3}
- mydict.keys() #
- list(mydict.keys()) #[‘a’, ‘c’, ‘b’]
- 迭代器 iterator 的 next()函数被 Python3 废弃,统一使用 next(iterator)
- raw_input 函数被 Python3 废弃,统一使用 input 函数
- 字典变量的 has_key 函数被 Python 废弃,统一使用 in 关键词
- file 函数被 Python3 废弃,统一使用 open 来处理文件,可以通过 io.IOBase 检查文件类型
- apply 函数被 Python3 废弃
- 异常 StandardError 被 Python3 废弃,统一使用 Exception
修改类差异
- 浮点数除法操作符“/”和“//”的区别
“ / ”:
Python2:若为两个整形数进行运算,结果为整形,但若两个数中有一个为浮点数,则结果为浮点数; Python3:为真除法,运算结果不再根据参加运算的数的类型。
“//”:
Python2:返回小于除法运算结果的最大整数;从类型上讲,与"/"运算符返回类型逻辑一致。Python3:和 Python2 运算结果一样。 - 异常抛出和捕捉机制区别
Python2
raise IOError, “file error” #抛出异常 except NameError, err: #捕捉异常 Python3
raise IOError(“file error”) #抛出异常 except NameError as err: #捕捉异常 - for 循环中变量值区别
Python2,for 循环会修改外部相同名称变量的值 i = 1
print ('comprehension: ', [i for i in range(5)]) print (‘after: i =’, i ) #i=4
Python3
, for 循环不会修改外部相
同名称变量的值
i = 1
print ('comprehension: ', [i for i in range(5)]) print (‘after: i =’, i ) #i=1 - round 函数返回值区别 Python2,round 函数返回 float 类型值
isinstance(round(15.5),int) #True Python3,round 函数返回 int 类型值 isinstance(round(15.5),float) #True - 比较操作符区别
Python2 中任意两个对象都可以比较
11 < ‘test’ #True
Python3 中只有同一数据类型的对象可以比较
11 < ‘test’ # TypeError: unorderable types: int() < str()
![]()
第三方工具包差异
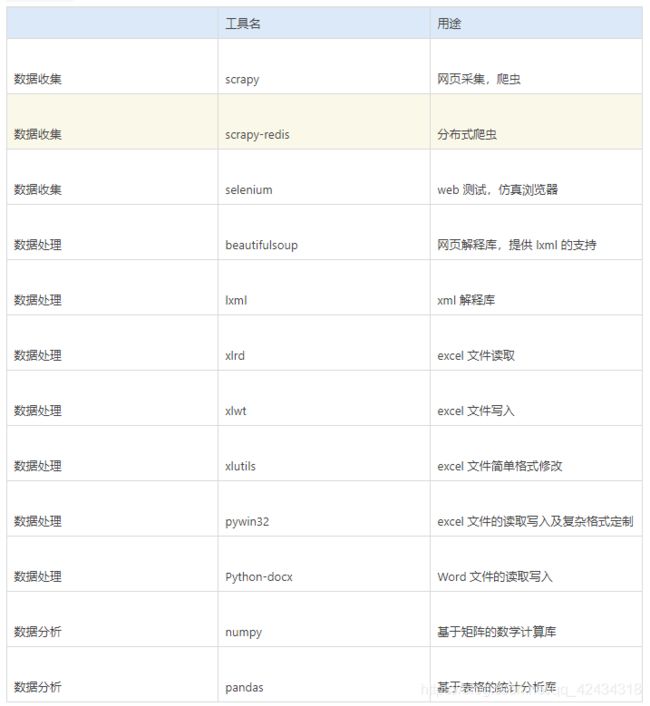
我们在 pip 官方下载源 pypi 搜索 Python2.7 和 Python3.5 的第三方工具包数可以发现,Python2.7
版本对应的第三方工具类目数量是 28523,Python3.5 版本的数量是 12457,这两个版本在第三方工具包支持数量差距相当大。
我们从数据分析的应用角度列举了常见实用的第三方工具包(如下表),并分析这些工具包在Python2.7 和 Python3.5 的支持情况:

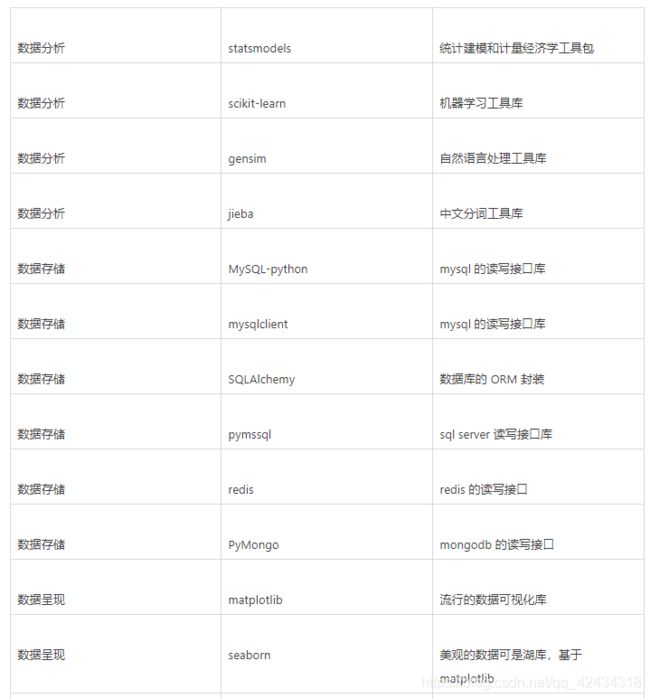
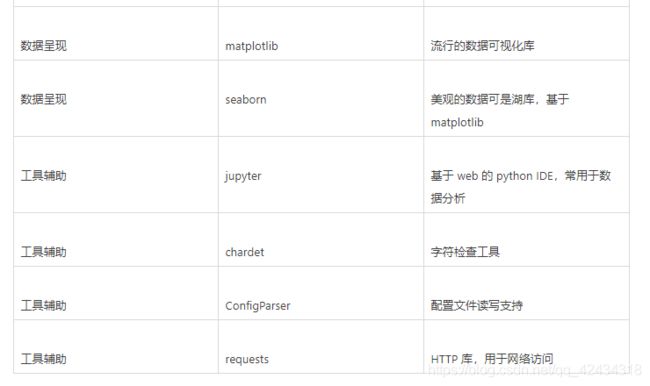
![]()
如果对软件测试有兴趣,想了解更多的测试知识,解决测试问题,以及入门指导,帮你解决测试中遇到的困惑,我们这里有技术高手。如果你正在找工作或者刚刚学校出来,又或者已经工作但是经常觉得难点很多,觉得自己测试方面学的不够精想要继续学习的,想转行怕学不会的, 都可以加入我们
,群内可领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!
测试新手
如果你立志成为一名测试工程师,但却没有任何的知识储备。这时候,你应该抓紧时间学习计算机基础知识,同时,还需要了解编程体验、产品设计、用户体验和研发流程等知识。
测试工程师
从知识体系上看,你需要有更全面的计算机基础知识,还需要了解互联网的基础架构、安全攻击、软件性能、用户体验和常见缺陷等知识。从测试技术上看,你需要能够使用常见的测试框架或者工具,需要具有一定的自动化测试脚本的开发能力,
高级测试工程师
合格的测试工程师关注的是纯粹的测试,而优秀的测试工程师关注更多的是软件整体的质量,需要根据业务风险以及影响来制定测试策略。另外,优秀的测试工程师不仅可以娴熟地运用各类测试工具,还非常清楚这些测试工具背后的实现原理。
测试架构
测试架构师不仅仅应该有技术的深度,还应该有全局观。比如,面对大量测试用例的执行,无论是 GUI 还是 API,都需要一套高效的能够支持高并发的测试执行基础架构;再比如,面对测试过程中的大量差异性数据要求,需要统一的测试数据准备平台。同时,测试架构师还必须对一些前沿的测试方法和技术有自己的理解。