机器学习笔记之生成模型综述(一)生成模型介绍
机器学习笔记之生成模型综述——生成模型介绍
- 引言
-
- 生成模型介绍
引言
从本节开始,将介绍生成模型的相关概念。
生成模型介绍
生成模型,单从名字角度,可以将其认识为:生成样本的模型。从流程的角度,它可以理解为:
- 给定一个数据集合,基于该数据集合进行建模,并通过数据集合学习出模型的参数信息;
- 根据已学习出的参数信息,使用模型构建出新的数据。
但生成新的数据仅是生成模型的一个任务/目标,通过生成新数据的模型对生成模型进行判别可能是很片面的。
例如之前介绍的高斯混合模型( Gaussain Mixture Model,GMM \text{Gaussain Mixture Model,GMM} Gaussain Mixture Model,GMM),它的概率图结构可表示为:
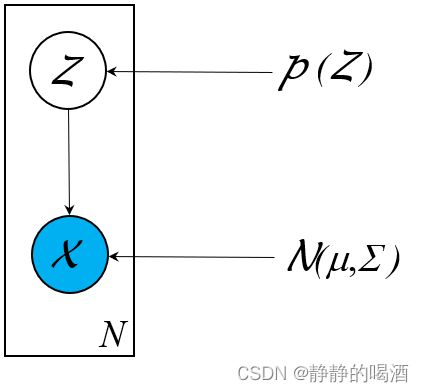
其中 Z \mathcal Z Z是一个一维、离散型随机变量,对应的 X ∣ Z \mathcal X \mid \mathcal Z X∣Z服从高斯分布:
Z ∼ Discrete Distribution ( 1 , 2 , ⋯ , K ) X ∣ Z ∼ N ( μ k , Σ k ) k ∈ { 1 , 2 , ⋯ , K } \begin{aligned} \mathcal Z & \sim \text{Discrete Distribution}(1,2,\cdots,\mathcal K) \\ \mathcal X \mid \mathcal Z & \sim \mathcal N(\mu_{k},\Sigma_k) \quad k \in \{1,2,\cdots,\mathcal K\} \end{aligned} ZX∣Z∼Discrete Distribution(1,2,⋯,K)∼N(μk,Σk)k∈{1,2,⋯,K}
只要能够确定隐变量 Z \mathcal Z Z的概率分布 P Z \mathcal P_{\mathcal Z} PZ,以及高斯分布参数 ( μ Z , Σ Z ) (\mu_{\mathcal Z},\Sigma_{\mathcal Z}) (μZ,ΣZ),就可以从概率模型中源源不断生成出样本:
这里 μ Z , Σ Z , P Z \mu_{\mathcal Z},\Sigma_{\mathcal Z},\mathcal P_{\mathcal Z} μZ,ΣZ,PZ均表示模型参数。
{ ∀ z ( i ) ∈ Z z ( i ) ∼ P z ( i ) x ( i ) ∣ z ( i ) ∼ N ( μ z ( i ) , Σ z ( i ) ) \begin{cases} \forall z^{(i)} \in \mathcal Z \\ z^{(i)} \sim \mathcal P_{z^{(i)}}\\ x^{(i)} \mid z^{(i)} \sim \mathcal N(\mu_{z^{(i)}},\Sigma_{z^{(i)}}) \end{cases} ⎩ ⎨ ⎧∀z(i)∈Zz(i)∼Pz(i)x(i)∣z(i)∼N(μz(i),Σz(i))
不可否认的是,高斯混合模型就是一个生成模型。它所处理的任务主要是无监督的聚类任务。
相反,监督学习中,是否也存在生成模型呢?例如:朴素贝叶斯分类器(Naive Bayes Classifier),它的概率图结构表示如下:
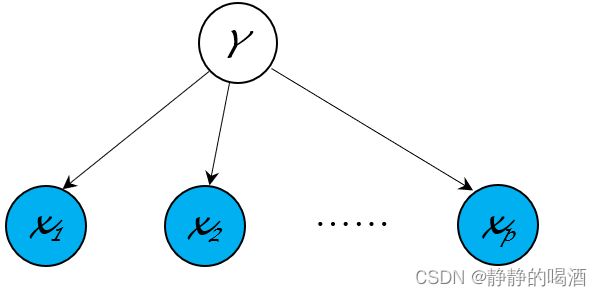
这是一个基于朴素贝叶斯假设的分类模型:
文字描述是:在标签 Y \mathcal Y Y确定的条件下,随机变量集合 X \mathcal X X内各随机变量相互独立。 p p p表示 X \mathcal X X内随机变量的数量; k k k表示随机变量 Y \mathcal Y Y划分类的数量。
x i ⊥ x j ∣ Y = l { i , j ∈ { 1 , 2 , ⋯ , p } i ≠ j l ∈ { 1 , 2 , ⋯ , k } x_i \perp x_j \mid \mathcal Y=l \quad \begin{cases} i,j \in \{1,2,\cdots,p\} \\ i \neq j \\ l \in \{1,2,\cdots,k\} \end{cases} xi⊥xj∣Y=l⎩ ⎨ ⎧i,j∈{1,2,⋯,p}i=jl∈{1,2,⋯,k}
关于 P ( X ∣ Y ) \mathcal P(\mathcal X \mid \mathcal Y) P(X∣Y)可表示为:
P ( X ∣ Y ) = ∏ i = 1 p P ( x i ∣ Y ) \mathcal P(\mathcal X \mid \mathcal Y) = \prod_{i=1}^p \mathcal P(x_i \mid \mathcal Y) P(X∣Y)=i=1∏pP(xi∣Y)
在分类过程中,通过软分类对 Y \mathcal Y Y的后验概率进行判别,并进行分类:
将后验概率 P ( Y ∣ X ) \mathcal P(\mathcal Y \mid \mathcal X) P(Y∣X)通过贝叶斯定理转化为似然 P ( X ∣ Y ) \mathcal P(\mathcal X \mid \mathcal Y) P(X∣Y) × 先验概率 P ( Y ) \mathcal P(\mathcal Y) P(Y)的形式。
P ( Y = m ∣ X ) ⇔ ? P ( Y = n ∣ X ) ∝ P ( X ∣ Y = m ) ⋅ P ( Y = m ) ⇔ ? P ( X ∣ Y = n ) ⋅ P ( Y = n ) \begin{aligned} \mathcal P(\mathcal Y = m \mid \mathcal X) & \overset{\text{?}}{\Leftrightarrow} \mathcal P(\mathcal Y = n \mid \mathcal X) \\ \propto \mathcal P(\mathcal X \mid \mathcal Y = m) \cdot \mathcal P(\mathcal Y = m) & \overset{\text{?}}{\Leftrightarrow} \mathcal P(\mathcal X \mid \mathcal Y = n) \cdot \mathcal P(\mathcal Y = n) \end{aligned} P(Y=m∣X)∝P(X∣Y=m)⋅P(Y=m)⇔?P(Y=n∣X)⇔?P(X∣Y=n)⋅P(Y=n)
显然,我们也无法从监督/无监督的角度对生成模型进行定义。再举一个例子:逻辑回归(Logistic Regression),虽然它和朴素贝叶斯分类器一样,也是软分类的经典算法,但它不是生成模型。因为它的核心是 通过 Sigmoid,Softmax \text{Sigmoid,Softmax} Sigmoid,Softmax函数直接对标签 Y \mathcal Y Y的后验概率进行比较:
这里以二分类为例,对应的是 Sigmoid \text{Sigmoid} Sigmoid函数。
{ P ( Y = 1 ∣ X ) = Sigmoid ( W T X + b ) P ( Y = 0 ∣ X ) = 1 − Sigmoid ( W T X + b ) P ( Y = 1 ∣ X ) ⇔ ? P ( Y = 0 ∣ X ) \begin{aligned} & \begin{cases} \mathcal P(\mathcal Y = 1 \mid \mathcal X) = \text{Sigmoid}(\mathcal W^T\mathcal X + b) \\ \mathcal P(\mathcal Y = 0 \mid \mathcal X) = 1 - \text{Sigmoid}(\mathcal W^T \mathcal X + b) \end{cases} \\ & \mathcal P(\mathcal Y = 1 \mid \mathcal X) \overset{\text{?}}{\Leftrightarrow} \mathcal P(\mathcal Y = 0 \mid \mathcal X) \end{aligned} {P(Y=1∣X)=Sigmoid(WTX+b)P(Y=0∣X)=1−Sigmoid(WTX+b)P(Y=1∣X)⇔?P(Y=0∣X)
从这里可以看出朴素贝叶斯分类器与逻辑回归的差别:
- 关于逻辑回归,直接对条件概率 P ( Y ∣ X ) \mathcal P(\mathcal Y \mid \mathcal X) P(Y∣X)进行建模,也就是说,逻辑回归中只关注 Sigmoid \text{Sigmoid} Sigmoid函数的返回结果,对 X \mathcal X X的特征并不关心;
- 相反,朴素贝叶斯分类器不仅没有直接比较 P ( Y ∣ X ) \mathcal P(\mathcal Y \mid \mathcal X) P(Y∣X),而是通过贝叶斯定理转化成 P ( X ∣ Y ) ⋅ P ( Y ) \mathcal P(\mathcal X \mid \mathcal Y) \cdot \mathcal P(\mathcal Y) P(X∣Y)⋅P(Y)进行比较。并且它对 X \mathcal X X的特征提出了严苛的条件独立性假设。
综上,生成模型的关注点均在样本分布本身,并根据样本分布的特点进行建模。和具体的任务之间没有具体关联关系:
-
如果是包含标签信息 Y \mathcal Y Y的监督学习任务,如朴素贝叶斯分类器。直接对 P ( X , Y ) \mathcal P(\mathcal X,\mathcal Y) P(X,Y)进行建模:
P ( Y ∣ X ) = P ( X , Y ) P ( X ) ∝ P ( X , Y ) = P ( X ∣ Y ) ⋅ P ( Y ) P ( X ∣ Y = m ) ⋅ P ( Y = m ) ⇔ ? P ( X ∣ Y = n ) ⋅ P ( Y = n ) \begin{aligned} \mathcal P(\mathcal Y \mid \mathcal X) = \frac{\mathcal P(\mathcal X,\mathcal Y)}{\mathcal P(\mathcal X)} \propto \mathcal P(\mathcal X,\mathcal Y) & = \mathcal P(\mathcal X \mid \mathcal Y) \cdot \mathcal P(\mathcal Y) \\ \mathcal P(\mathcal X \mid \mathcal Y = m) \cdot \mathcal P(\mathcal Y = m) & \overset{\text{?}}{\Leftrightarrow} \mathcal P(\mathcal X \mid \mathcal Y = n) \cdot \mathcal P(\mathcal Y = n) \end{aligned} P(Y∣X)=P(X)P(X,Y)∝P(X,Y)P(X∣Y=m)⋅P(Y=m)=P(X∣Y)⋅P(Y)⇔?P(X∣Y=n)⋅P(Y=n) -
如果是无监督学习任务,如隐变量模型( Latent Variable Model,LVM \text{Latent Variable Model,LVM} Latent Variable Model,LVM),可以通过构造隐变量 Z \mathcal Z Z,通过对 P ( X , Z ) \mathcal P(\mathcal X,\mathcal Z) P(X,Z)进行建模。
在无监督模型中,这种思想更加深刻。由于至始至终仅有样本特征是我们能够观测到的已知信息。无论是隐变量,还是模型,都是基于样本特征的性质构建的合理假设。当然,针对无监督学习任务,不是仅有隐变量模型一种选择。如‘自回归模型’(AutoRegressive,AR),它就是一种直接对P ( X ) \mathcal P(\mathcal X) P(X)建模的方法。
如:玻尔兹曼机系列的能量模型:
其中v v v表示观测变量;h h h表示隐变量。
P ( v , h ) = 1 Z exp { − E [ v , h ] } \begin{aligned} \mathcal P(v,h) = \frac{1}{\mathcal Z} \exp \{-\mathbb E[v,h]\} \end{aligned} P(v,h)=Z1exp{−E[v,h]}
如高斯混合模型:
P ( X ) = ∑ Z P ( X , Z ) = ∑ Z P ( X ∣ Z ) ⋅ P ( Z ) = ∑ k = 1 K p k ⋅ N ( μ k , Σ k ) ∑ k = 1 K p k = 1 \begin{aligned} \mathcal P(\mathcal X) & = \sum_{\mathcal Z}\mathcal P(\mathcal X,\mathcal Z) \\ & = \sum_{\mathcal Z} \mathcal P(\mathcal X \mid \mathcal Z) \cdot \mathcal P(\mathcal Z) \\ & = \sum_{k=1}^{\mathcal K} p_k \cdot \mathcal N(\mu_k,\Sigma_k) \quad \sum_{k=1}^{\mathcal K} p_k = 1 \end{aligned} P(X)=Z∑P(X,Z)=Z∑P(X∣Z)⋅P(Z)=k=1∑Kpk⋅N(μk,Σk)k=1∑Kpk=1
通常也称生成模型为概率生成模型。
生成对抗网络中的样本生成过程表示为 x = G ( Z ; θ g e n e ) x = \mathcal G(\mathcal Z;\theta_{gene}) x=G(Z;θgene),其中 Z \mathcal Z Z是一个简单分布。虽然这里 G ( Z ; θ g e n e ) \mathcal G(\mathcal Z;\theta_{gene}) G(Z;θgene)是一个由前馈神经网络构成的计算图,但它依然描述的是样本自身的概率模型/概率分布。因此,生成对抗网络是一个概率生成模型。
下一节将从监督与无监督的角度介绍现阶段经典的概率模型。
相关参考:
生成模型1-定义