论文阅读笔记:Traffic Accident Risk Prediction via Multi-ViewMulti-Task Spatio-Temporal Networks
文章来源:Traffic Accident Risk Prediction via Multi-View Multi-Task Spatio-Temporal Networks | IEEE Journals & Magazine | IEEE Xplore
[1] Senzhang Wang, Jiaqiang Zhang, Jiyue Li, et al. Traffic Accident Risk Prediction via Multi-View Multi-Task Spatio-Temporal Networks. [J]IEEE Transactions on Knowledge and Data Engineering. 2022
Abstract:随着许多国家的快速城市化进程,交通事故等非正常交通事件已经成为一个重要的健康和发展威胁。因此,准确预测一个城市中不同区域的交通事故风险至关重要,这在城市计算的研究领域引起了越来越多的研究兴趣。准确的交通风险预测所面临的挑战有三个方面。首先,城市中某些地区的交通事故数据是稀疏的,特别是对于细粒度的预测来说,这可能会导致模型训练过程中出现零膨胀问题。第二,不同地区发生的交通事故的时空相关性相当复杂,而且是非线性的,现有的回归等浅层模型难以把握。第三,交通事故的发生会受到各种环境特征的显著影响,包括天气、POI和路网特征。为了建立一个准确的预测模型,捕捉不同环境特征与交通事故风险之间的复杂联系是不容易的。为了解决上述问题,本文提出了一个多视图多任务时空网络(MVMT-STN)模型来同时预测一个城市的细粒度和粗粒度交通事故风险。具体来说,为了解决细粒度预测中的数据稀少问题,我们采用多任务学习框架,通过考虑空间关联来联合预测细粒度和粗粒度的交通事故风险。对于每个粒度的预测,我们设计了通道式CNN和多视角的GCN,分别捕捉局部的地理依赖性和全局的语义依赖性。为了获得上下文特征对交通事故的不同影响,我们还引入了一个融合学习模块,该模块整合了从不同类型的外部因素中学习到的通道和多视图特征。我们在两个大型真实交通事故数据集上进行了广泛的实验。结果表明,MVMT-STN与现有的最先进的方法相比,在细粒度和粗粒度的交通事故风险预测方面的性能都有很大的提高。
一、introduction
传统方式是基于统计和线性回归的方法,如SVM和ARIMA[3]被广泛用于预测交通事故,将一个地区或路段的交通事故数量视为时间序列数据。这类方法的主要局限性在于不能有效地捕捉到不同地区之间复杂的交通事故的时空相关性。随着近年来深度学习技术的发展,各种深度学习模型,如LSTM[4]、CNN[5]和自动编码器(AE)[6]被应用于预测全市的交通事故。
目前仍然存在许多挑战:首先,一个城市的某些地区的交通事故数据可能非常稀少,特别是在需要进行细粒度预测的情况下(如预测小区域的交通事故)。作为典型的非正常交通事故,交通事故更有可能只发生在城市中某些特定时间段的少数地区,而对于大多数其他地区来说,根本就没有交通事故。其次,交通事故数据的时空关联性是复杂的、非线性的,现有的方法难以捕捉。第三,对外部环境特征对交通事故的不同影响进行建模并不简单的。
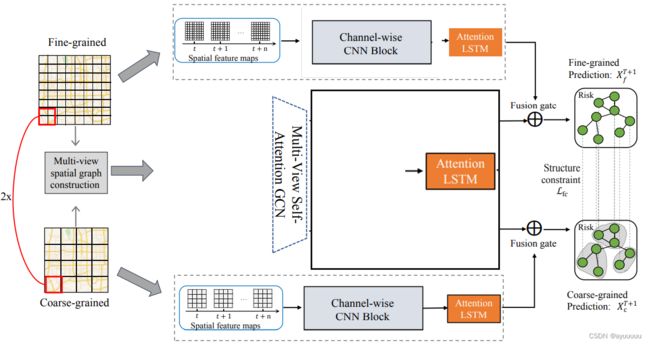
为了应对上述挑战,本文提出了一个多视图多任务时空网络(MVMT STN)模型,以同时预测一个城市的细粒度和粗粒度交通事故风险。具体来说,我们根据经纬度将城市划分为不同颗粒度的单元区域。对于每个颗粒度,我们首先在交通事故风险空间图上提出了一个channel-wise CNN,以学习本地的空间特征再现,然后根据各单元区域之间的上下文特征(即POI、道路特征、事故风险)的相似性建立多视图图。我们提出了一个multi-view self-attention GCN来学习多视图图上的全局语义特征表示。这两类特征表征接下来被设计的特征融合门所整合。同时,为了模拟不同外部因素的不同影响,在channel-wise CNN中,我们提出使用全局平均池来学习不同特征通道的影响权重,包括天气、POI、人员流动和交通事故。为了捕捉交通事故的非线性时间依赖性,我们还采用了attention LSTM进行时间特征学习。最后,我们采用多任务学习框架,通过考虑空间关联和解决数据稀疏问题,联合预测细粒度和粗粒度的交通事故风险。
二、preliminaries and problem definition
1.cell region. 我们根据经纬度将所研究的城市R划分为一个大小为H×W的网格图。我们将网格图的所有单元区域表示为R,R的一个粗粒度分区包含H×W k个网格单元,其中k∈N+是粗化系数。
2.Human mobility tensor. 考虑到一个城市的人口流动数据(如出租车轨迹),我们将所有单元区域在时间段t内的人口流动情况表示为张量St。
每个单元区域内POI的分布和密度表明了该区域的土地功能[13],因此有助于预测交通事故风险。同时,道路特征(如道路的长度和宽度,道路类型等)也与小区区域的交通状况高度相关[17]。因此,我们也考虑土地特征,定义如下:
3.Land features. 我们收集每个单元区域的土地特征,包括POI和道路特征,并将所有单元区域的POI和道路特征表示为P和F。
4.External features. 交通异常事件也与外部特征高度相关,包括天气、假期和一天中的时间。我们将小区区域R的外部特征表示为E。
5.Traffic accidengt risk map.交通事故风险图。按照文献[18],交通事故风险可分为以下三种类型:轻微事故风险、伤害事故风险和死亡事故风险。这三种类型的风险分别被赋予风险值1、2和3。一个时间段t的风险图可以表示为矩阵Xt,所有T个时间段的交通事故风险图形成一个风险张量X.
6.Multi-view spatial graph.为了充分捕捉外部环境特征对全局语义依赖的影响,我们将一个具有单元区域R的城市建模为一个多视图空间图G(V, E)。特别是,G包含三个视图,即POI相似性图视图Gp(V,Ep)、道路特征相似性图视图Gf(V,Ef)和交通事故风险相似性图视图Gp(V,Er)。请注意,这三个视图有相同的节点,但有不同的边。对于每个视图,节点对应于单元区域,区域之间的视图特征(即POI、道路特征和事故风险)的相似性表示边的权重。对于每个节点(单元区域),我们选择具有最大特征相似度的Top-K节点作为其邻居。
因此问题可定义为:考虑到城市的单元区域R、粗化系数k、历史交通事故风险张量X、人类流动性张量{S1, ...S t, ...S T }、道路特征{P, F}、外部特征E以及前T个时隙的多视图空间图G(V, E),我们旨在同时预测下一个时隙T+1的细粒度和粗粒度交通事故风险图XfT+1、XcT+1。
三、Methodology
图2说明了所提模型的框架,它包含三个主要步骤,空间特征学习步骤、时间特征学习步骤和跨尺度多任务预测步骤。在空间特征学习步骤中,为了捕捉复杂的空间相关性,我们通过一个通道式CNN模块提取局部空间特征,并通过一个多视图GCN模块分别提取全局语义特征。为了解决数据稀疏的问题,我们同时对细粒度和粗粒度的交通事故风险数据进行了空间特征学习。定义5中的通道式CNN是在交通事故风险空间图上进行的,定义6中的多视角GCN是在多视角空间图上进行的。为了融合两个尺度数据的空间特征以解决数据稀疏性问题,提出了一个跨尺度的GCN。在时间特征学习步骤中,使用了Attention LSTM模块来学习输入数据的时间依赖性。为了整合本地地理和全局语义特征,设计了一个融合门,如图中右部所示。最后,在预测步骤中,采用了一个多任务学习框架来结合细粒度和粗粒度的预测。考虑到两个尺度的数据之间的空间关联,在最终目标函数中引入了结构约束损失。接下来,我们将详细介绍该模型。
3.1 Data preparation
根据定义5,我们将数值1、2、3分别分配给三种交通事故风险类型。为了准备拟议模型的数据,我们首先对交通事故的类型进行分类,并统计每个小区区域相应的事故数量。小区ri,j在时隙t中的交通事故风险值可按以下方式计算。

交通事故的发生受到各种外部环境特征的影响。图3的右边显示了芝加哥不同天气条件下的交通事故数量,包括晴天、阴天、雨天、雪天和雾天。图3的左边显示了在不同POI下发生的交通事故数量。我们可以看到,在不同的天气条件和POI下,事故数量有很大的变化,这意味着天气和POI对交通事故有很大的影响。因此,有必要考虑这些外部特征来协助预测。
以前的研究[12,19]表明,每个单元区域的当前交通事故风险与前几个时间段的风险以及前几天同一时间段的风险高度相关。为了充分反映短期和长期的时间相关性,我们将前κ个时间段的交通事故风险空间图以及前ρ周同一时间段的图作为输入的T个时间段(T = κ + ρ)。因此,输入数据可以被表述为两组历史交通事故风险空间图的结合,如下所示。
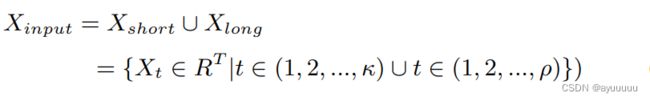
3.2 Channel-Wise CNN Block for Local Spatial Feature Learning
地理上接近的单元区域的交通状况通常是高度相关的,以往的工作中,卷积神经网络工程(CNN)被广泛用于捕捉邻里区域之间的局部空间相关性,用于交通事故风险预测[10]。然而,一般CNN模型的一个主要局限是,它只考虑了局部空间的交通事故数据,而忽略了各种相关特征的影响,包括人的流动模式和外部特征对交通事故发生的影响。因此,我们提出了一个分通道的CNN模块来捕捉道路特征和外部特征的不同影响。需要注意的是,与传统的多通道CNN模型不同,我们首先通过一个全局平均池化层和两个FC层来计算每个通道上的注意系数。全局平均池化层用于学习每个通道的高层表征,两个FC层用于学习表征的非线性相关关系。然后通过权重对原始输出进行重新调整。例如,天气特征可能比静态道路特征对交通事故风险有更大的影响。因此,通道式CNN应该能够学习不同类型特征对交通事故发生的影响权重。
 图4显示了拟议的通道式CNN模块的结构。它主要由multi-channel CNN和(挤压和激发网络)Squeeze-and-Excitation Networks(SENet)[20]组成,以学习局部空间相关性并捕捉不同特征对交通事故风险的影响。multi-channel CNN可以学习和汇总不同特征通道在局部接受区域上的表现。不同特征通道的重要性可以由SENET自动学习。SENet可以选择性地增强有用的特征通道,抑制无用的特征通道,从而实现每个特征通道的校准。信道式CNN模块将多信道特征,包括人的流动特征、道路特征、外部特征和交通事故风险空间图作为输入,并输出高层次的表示。具体来说,在时隙t,多通道特征被表示为张量Mt∈R D×H×W,其中D是特征通道的数量。为了使SENet更好地工作,我们使用卷积层来重构输入通道的尺寸。我们将通道尺寸从D压缩到C,然后将结果送入SENet以获得通道特征。
图4显示了拟议的通道式CNN模块的结构。它主要由multi-channel CNN和(挤压和激发网络)Squeeze-and-Excitation Networks(SENet)[20]组成,以学习局部空间相关性并捕捉不同特征对交通事故风险的影响。multi-channel CNN可以学习和汇总不同特征通道在局部接受区域上的表现。不同特征通道的重要性可以由SENET自动学习。SENet可以选择性地增强有用的特征通道,抑制无用的特征通道,从而实现每个特征通道的校准。信道式CNN模块将多信道特征,包括人的流动特征、道路特征、外部特征和交通事故风险空间图作为输入,并输出高层次的表示。具体来说,在时隙t,多通道特征被表示为张量Mt∈R D×H×W,其中D是特征通道的数量。为了使SENet更好地工作,我们使用卷积层来重构输入通道的尺寸。我们将通道尺寸从D压缩到C,然后将结果送入SENet以获得通道特征。
在l层卷积之后,输出为M t,l =[m1, m2, ...mc],每个元素mi代表了每个通道上的学习特征嵌入。对于SENet,我们首先使用全局平均集合来生成通道的统计数据s,有了通道的统计数字作为通道的重要性系数,接下来我们用以下公式来学习不同通道之间的非线性关系,即用两个全连接(FC)层组成一个bottleneck,并获得权重系数z。接下来,我们将每个通道的学习权重系数与原始表示相乘,得到一个新的表示,并将其与初始输入相加作为最终输出Ut。
3.3 Multi-View Self-Attention GCN for Global Semantic Feature Learning
接下来我们将介绍所提出的multi-view self-attention graph convolution network module,以从上下文特征中捕捉全局语义依赖。我们将首先介绍如何构建multi-view spatial graph,然后介绍multi-view self-attention GCN。
3.3.1 Multi-View Semantic Graph Construction
不同区域的交通事故风险的空间相关性很复杂,包括局部和全局的空间相关性。两个具有相似POI分布或功能(如商业区)但地理上相距甚远的小区,也可能出现相似的交通事故发生模式。交通事故风险的全局语义相关性在很大程度上可以通过道路特征如POI和道路网络来反映[17]。
为了捕捉道路特征所反映的全局空间相关性,我们从POI相似性、道路特征相似性和交通事故风险相似性的角度对单元区域之间的全局语义相关性进行建模,构建了一个多视图空间图。请注意,图中的每个节点都对应于空间地图中的一个像素。一个单元区域的POI分布可以反映该区域的功能以及交通流模式。道路特征包括道路长度、道路类型、道路上的车道数和高架电子标志的数量,也可以反映一个小区的交通模式。为了衡量两个单元区域之间的POI和道路特征的相似性,我们根据Jensen-Shannon(JS)发散来计算它们的分布相似性[21]。JS发散被广泛用于衡量两个概率分布的相似性。
基于所有单元区域之间的POI相似性和道路特征相似性,我们可以构建双视角空间图G,其中包含POI相似性图Gp和道路特征相似性图Gf。对于每一对小区区域ri,j和rm,n,我们也用DTW算法计算它们的交通事故风险相似度。两个区域的历史交通事故风险形成了两个时间序列,而DTW算法可以用来衡量这两个时间序列数据的相似性。对于每个小区区域ri,j,我们找到交通事故风险相似度最高的Top-k小区区域,并在ri,j和最相似的k个节点之间构建一条边。通过这种方式,我们构建了交通事故风险图Gr。
3.3.2 Multi-View Self-Attention GCN
为了学习所构建的多视图空间图中节点的全局语义特征,我们提出了一种多视图自我关注GCN。为了在谱域中进行GCN,我们首先构建拉普拉斯矩阵L(以下为图卷积基础部分,略),最终有:
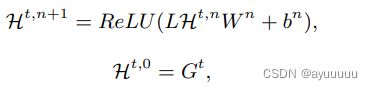
通过对时隙t的多视图空间图的两层图卷积,我们分别得到三个视角的图嵌入Ht (Gr), Ht (Gf), Ht (Gp)
为了简单起见,我们把三个视图的图嵌入表示为Ht = [H1 , H2 , H3]。通过global-attention layer,每个视图都可以有一个新的表示,其中包含了跨视图的信息。为了保留原始信息,原始嵌入和新嵌入通过fusion gate被整合。最后,我们用融合的结果作为global softmax layer的输入,以捕捉三种视角对风险预测的不同影响。
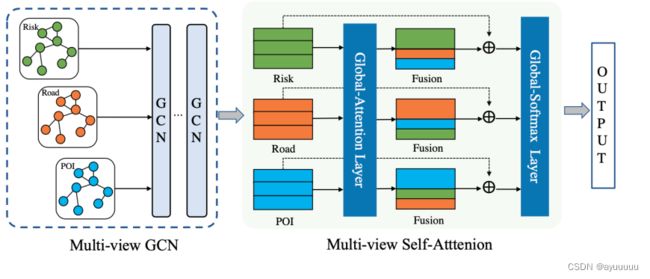
具体来说,给定输入Ht=[H1 ,...,Hn]∈R n×N×dh,其中n为视图数,N为节点数,dh为图卷积嵌入大小。受self-attention mechanism自我关注机制[22]的启发,用H得到三个subspace子空间,即query matrix查询矩阵Q、value matrix值矩阵V=H和一个key matrix钥匙矩阵K,如下所示。
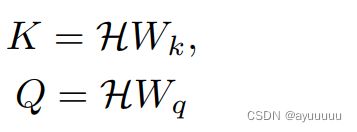
然后,我们将信息分散到所有三个视图中:
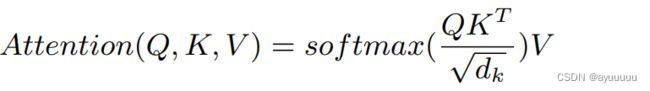
此外,为了获得每个视图的更丰富的全局信息,我们为每个视图提出了the multi-view attention based on multi-head attention。具体来说,我们将三个视图的特征串联在一起,并再次投射以获得最终值。这个过程可以被表述为以下公式 :

其中,Qi = HW Q i,Ki = HW K i,Vi = HWV i,Wo是可训练参数。经过multi-head attention layer,我们可以得到每个视图的相关全局信息。H' = [H1', H2', ..., Hn'] = MultiV iew(Q, K, V )。
然后,我们采用residual connection残差连接,以便通过gated linear units保留原始信息,对第i个视图的计算如下:
最终的输出可以通过global-softmax layer得到: :
:
3.4 Cross-Scale GCN for Fine- and Coarse-Grained Feature Fusion
与视频数据不同,在细粒度和粗粒度交通网络中,各区域之间存在着复杂的时空关联。例如,粗粒度交通网络中的节点可能涵盖商业区、学校或其他重要景点。粗粒度交通网络中的POI的语义信息在交通规划中非常有用,因此在粗粒度和细粒度的特征学习中都应该被捕获。(我细粒度就不用POI特征了吗)
如图2所示,多视图GCN是分别对粗粒度和细粒度的交通事故风险数据进行的。为了整合两种粒度的特征表示,我们需要在细粒度和粗粒度的预测任务之间进行多视图GCN的关联。由于每个粗粒度的单元区域是由多个细粒度的单元区域组成的,因此,粗粒度区域的嵌入应该被视为相应细粒度区域嵌入的聚合。简而言之,对于一个粗粒度的单元区域,其中的每个细粒度区域都应该反映其部分空间特征。因此,细粒度单元区域的特征聚集应该与相应的粗粒度单元区域特征一致。为此,我们使用一个assignment matrix分配矩阵Bfc来存储细粒度和粗粒度细胞区域之间的对应关系,如下所示:
然后,在时间间隔t,假设粗粒度和细粒度的图嵌入是Ht c和Ht f。我们提出一个cross-scale GCN module,在两个尺度的数据之间共享信息,具体如下:
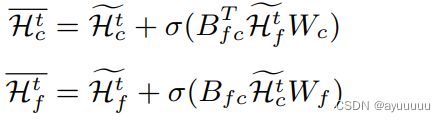
其中Wf , Wc是可训练参数,Bf c是赋值矩阵,BT f c是其转置矩阵。通过上述跨尺度的GCN操作,细粒度图和粗粒度图上的特征表示学习可以有效地融合和整合。
3.5 Attention LSTM For Temporal Feature Learning
有了上述方法学习的空间和语义特征,接下来我们介绍如何学习时间特征。在这里,我们建议使用attention LSTM module来学习历史交通事故风险的时间相关性。以多视角图卷积后的时间t的细粒度结果Htf为例,首先使用以下LSTM模块来学习连续时隙中特征的时间相关性。
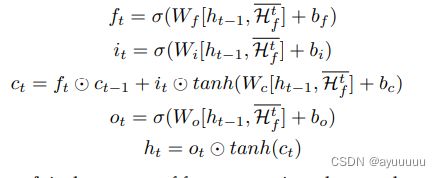 (LSTM运算,输出隐藏层ht)
(LSTM运算,输出隐藏层ht)
然后,对于一个单元的隐藏状态的输出ht,attention mechanism注意机制被应用如下:

其中m是时间步长的数量。Pf graph是多视图图的特征表示,它融合了全局语义和时间特征。
3.6 Local Spatial and Global Semantic Features Fusion
通过Attention LSTM,以细粒度的特征为例,它输出两种类型的特征表示。第一种是局部的空间和时间特征表示,可以表示为Pf grid。第二种是全局语义和时间特征表示,可以表示为Pf graph。接下来,我们需要整合这两类特征,将局部空间和全局语义特征融合起来。我们使用以下的全连接层来融合这两类特征![]()
四、Objective Function For Multi-Task Learning
我们的目标是同时预测细粒度和粗粒度的交通事故风险。因此,这两个预测任务可以在一个multi-task learning framework多任务学习框架下共同进行。所设计的多任务学习模型的目标函数包含三个部分:细粒度数据的prediction loss预测损失、粗粒度数据的prediction loss预测损失和两个视图之间的structure constraint loss结构约束损失。
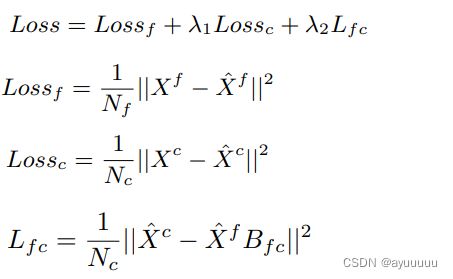
Lfc是两个尺度的数据之间的结构约束损失。根据我们对单元区域的定义,一个粗粒度的单元区域包含k×k细粒度的单元区域,其中k是粗化系数。为了表示细粒和粗粒单元区域之间的关系,我们使用一个分配矩阵Bfc,其每个条目Bf c(i, j)表示第i个细粒区域属于第j个粗粒区域(值1)或不属于(值0)(公式(21))。在细粒度区域和粗粒度区域之间的这种对应关系下,粗粒度区域的交通事故风险应该与相应的细粒度区域一致。也就是说,交通事故风险应该与属于粗粒度区域的所有细粒度单元区域的交通事故风险之和相一致。考虑到这一结构约束,我们设计了一个结构约束损失。
五、Experiment
5.1 Experiment settings
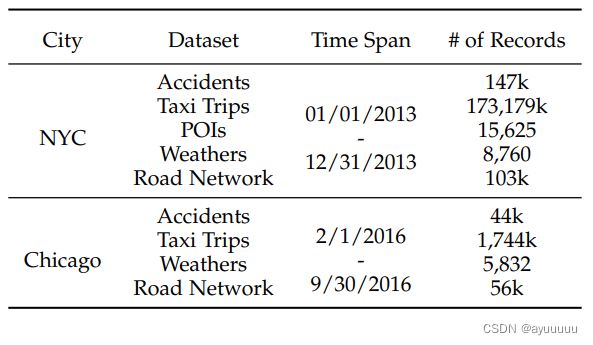
5.1 dataset
5.2 Evaluation Metrics
Root Mean Square Error (RMSE)、Accuracy of top L (Acc @ L)、mean average precision of L(MAP)。
5.3 Implementation Details
在我们的实验中,数据以6:2:2的比例被分为训练、评估和测试集。整个城市区域被划分为20×20个单元区域。由于不是所有的区域都有道路网络结构,在对纽约市进行细粒度预测时,保留了243个有道路网络结构的单元区域,在进行粗粒度预测时,保留了75个区域。(K=3)对于芝加哥,细粒度预测有197个具有道路网络结构的单元区域,粗粒度预测有59个区域。为了使训练更加有效,所有的数据在训练前都用Max-Min归一化方法进行归一化处理。长期(周)ρ和短期(近期)κ的长度分别设置为3和4。对于每个视图中的GCN,我们堆叠两层图卷积运算,每层的核数为64。对于通道明智的CNN块模块,卷积核被设置为3×3,学习率和批处理量分别设置为10-4和32。该模型的一部分是用Huawei MindSpore框架实现的,实验在NVIDIA GeForce RTX 3090的GPU上进行。
5.4 Baselines
ARIMA、LSTM、MLP、ConvLSTM、Hetero-ConvLSTM、STGCN、T-GCN、GSNet
5.5 Experiment Result
5.5.1 Performance Comparison
表2显示了MVMT-STN和基线在两个数据集的三个评价指标下的预测性能。为了进一步测试模型在交通事故更容易发生的高峰期的性能,我们还在表3中显示了这些方法在上午7:00至9:00和下午16:00至19:00的高峰期的预测性能。它显示,MVMT-STN在所有情况下都持续取得了最佳结果。我们还可以看到,在多任务学习框架下,细粒度和粗粒度的预测性能都得到了改善,这验证了所提出的多任务学习模型的有效性。

具体来说,在芝加哥数据集上,MVMT-STN在两个时间段内将最佳基线的性能提高了15.7%和17.4%。对于纽约市的数据集,在两个时间段内,MVMT-STN在MAP上的性能改进为7.9%和8.8%。这表明MVMT-STN能够更好地捕捉不同情况下的交通事故原因,因此它能够更好地预测每个地区的风险系数排名。可以发现,粗粒度预测的RMSE值总是比细粒度预测的RMSE值大。这主要是因为粗粒度的风险预测是相关细粒度区域的风险预测之和。由于粗粒度的区域更大,交通事故风险也比细粒度区域高,所以粗粒度预测的预测误差更大。粗粒度的预测结果也可以反映出MVMT-STN在粗粒度风险建模中的有效性,以及MVMT-STN在城市范围内交通事故风险预测中的可扩展性。
ARIMA的性能不如基于深度学习的方法,因为它不能捕捉复杂的非线性时空相关性。MLP是一个相对简单的神经网络模型,在挖掘足够的信息方面效果较差。LSTM只考虑时间上的关联,而忽略了空间上的关联。因此,这些简单模型的性能都不如其他深度学习模型。ConvLSTM同时考虑了时间和空间的相关性,而Hetero-Convlstm也考虑到了外部因素。因此可以看出,H-ConvLSTM的表现比ConvLSTM好,这验证了外部因素对所研究的问题是有用的。基于图的模型包括STGCN、T-GCN比基于CNN的模型ConvLSTM和H ConvLSTM表现更好,说明路网特征和全局语义特征也有助于提高预测性能。GSNet同时考虑了全局语义和局部地理空间特征。然而,它忽略了各种外部因素对交通事故的不同影响。总的来说,我们的MVMT-STN模型能够有效地捕捉到不同外部因素对交通事故的不同影响,同时考虑到复杂的节奏和空间相关性,因此在所有方法中取得了最佳的性能。
5.5.2 Ablation Study
为了研究我们模型中的所有成分是否都对所研究的问题有用,我们在本小节中进行消减研究。我们从MVMT STN中分别删除了Channel-wise CNN block、Multi-view GCN、attention和structure constraint(损失函数)成分,作为四个变体模型。我们将这四个变体命名为STN-CW、STN-MV、STN-AT和STN-CS。图6显示了MVMT-STN和四个变体在细粒度预测中的RMSE、Acc@50和MAP比较。可以看出,MVMT-STN在这三个指标上都优于四种变体,表明所提出的四种组件的有效性。我们还可以看到,多视图GCN对模型性能的提高贡献最大,在MAP方面有高达7.2%的提高。这说明多视角全局语义关联对交通事故风险预测任务特别重要。去除结构约束损失后,预测性能明显下降,这表明细粒度和粗粒度预测之间的多任务学习与单任务学习相比确实提高了性能。去掉LSTM的注意机制也会影响性能,这证明了动态建模历史数据重要性的必要性。将这些组件结合在一起可以达到最好的性能。因此,我们可以得出结论,MVMT-STN中精心设计的组件对交通事故风险预测问题也很有用。

5.5.3 Hyperparameter Study
为了研究不同的超参数对模型性能的影响,我们在图7中展示了纽约市数据集上不同的GCN和LSTM层数下的性能结果。从图中可以看出,当GCN层数为2层,LSTM层数为4层时,该模型取得了最好的性能,太小(1层)或太多(3或4层)的层数会损害性能。这可能是因为只有1层的GCN不能完全捕捉复杂的空间相关性,而过多的层数会导致过度拟合。适当数量的LSTM层如4层可以更好地捕捉长期的时间相关性。

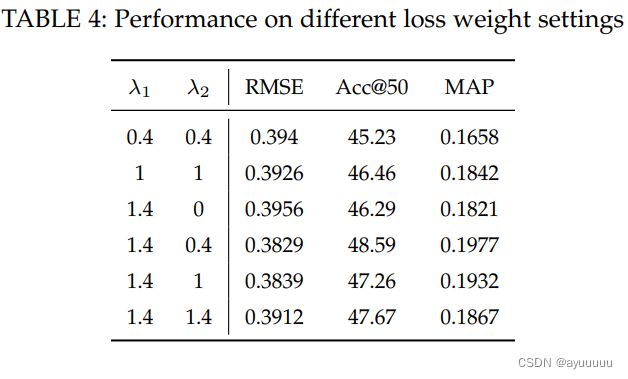
接下来,我们研究多任务学习的最终目标函数中的λ1和λ2对模型性能的影响。我们调整λ1和λ2的值,并记录不同数值设置下的RMSE、Acc@50和MAP。结果显示在表4中。可以看出,这三个指标随着两个参数的不同值而变化,这意味着它们都对模型的性能有重大影响。当λ1=1.4和λ2=0.4时,性能最好。
5.5.4 Visualization
为了进一步检验我们的模型在交通事故风险预测方面的能力,我们对两个数据集的预测结果和地面实况进行了可视化。图8和图9显示了纽约市从2013年11月17日至2013年11月24日和芝加哥从2016年9月9日至2016年9月17日一周内的细粒度和粗粒度交通事故风险热图的可视化结果和地面真相。可以看出,总体而言,两个数据集上的交通事故风险预测热图与地面实况非常相似,这意味着我们的模型可以提供非常准确的预测。人们还可以观察到,交通事故数据确实是稀疏的,因为大多数地区的交通事故数量非常少,而只有一小部分地区(城市的中心区域)的交通事故风险很高。对于交通流量大的城市中心区域,我们的预测也是非常准确的,因为预测的热力图颜色与地面实况颜色非常接近。因此,可视化的结果进一步验证了所提出的MVMT-STN模型的有效性。
5.5.5 Efficiency Analysis of MVMT-STN
我们在图10中显示了MVMT-STN和基线方法的计算时间,以研究这些方法的计算效率。左Y轴表示时间,右Y轴表示参数大小。
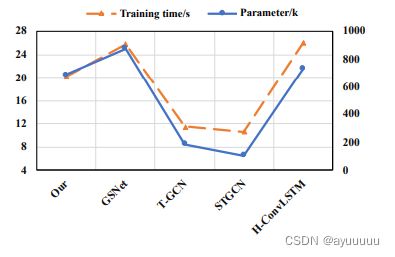
我们可以看到,受益于时间卷积结构,STGCN的参数数量最少,因此它需要的训练时间更少。由于MVMT-STN需要同时预测粗粒度和细粒度的交通事故风险,它需要更多的训练时间,MVMT-STN需要的训练时间比GSNet和Hetero-ConvLSTM少,但比其他方法需要更多时间。虽然MVMT-STN需要更多的训练时间,但其预测速度相当快,只需要2.58秒左右就可以完成整个城市的多尺度交通事故风险预测,可以满足实时预测的要求。
六、Related Work
我们从以下两个与本工作高度相关的方面回顾相关工作:交通事故预测和深度学习的时空数据预测。
交通事故预测。城市交通事故的预测是智能交通系统的关键课题之一。现有的解决方案一般可分为两类:基于模式的传统方法和基于深度学习的模型。传统的基于模式的方法包括SVM、决策树、KNN等。Bharti等人[27]使用高斯核的支持向量机(SVM)来分析城市交通事故。Caliendo等人[28]分别使用正切和曲线的泊松、负二项和负多项回归模型来模拟事故频率。Lv等人[16]基于欧氏距离选择交通事故特征,并采用KNN方法完成道路交通事故的实时预测。Lin等人[29]提出了一种基于频繁模式树(FP树)的变量选择方法,然后利用KNN和贝叶斯网络,通过所选特征来预测交通事故。基于模式的方法大多依靠经典的机器学习方法和静止假设来推断交通事故。然而,交通事故数据具有非线性和复杂的时空相关性,而且交通事故的发生会受到外部环境特征的影响,包括天气、POI和道路特征。如果不考虑这些特征,这些方法的预测精度就很难令人满意。最近,基于深度学习的方法被广泛用于预测交通事故。Yuan等人[7]提出了一个异构长短时记忆(Hetero ConvLSTM)模型来捕捉交通事故的空间异质性和时间自相关性。Ren等人[30]扩展了RNN架构和全连接(FC)网络来预测未来交通事故风险。Chen等人[18]收集了大量的异质数据,包括交通事故数据和GPS记录,以了解人类流动对交通事故风险的影响。Zhou等人[12]利用差分时变图神经网络获得了交通流的影响和空间依赖性。Wang等人[19]提出了一个模型来捕捉地理空间相关性和语义空间相关性。但他们忽略了各种外部环境特征的不同影响。
基于深度学习的时空数据预测。深度学习技术的最新进展大大改善了时空数据预测的研究领域[31, 32]。RNN及其变种包括LSTM和GRU[24]可以有效地模拟时间维度上的非线性相关。图形卷积网络(GCN)[25, 33]和卷积神经网络(CNN)[5]被广泛应用于空间图像和图形的空间相关性建模。
深度学习被广泛用于许多时空预测应用,如人群流动预测 [34, 35, 36], 人群管理 [37], 交通事故预测 [25], 空气质量推断 [38, 39], 犯罪率预测 [40, 41] 和道路位置推荐 [42] 。其中,Zhang等人[5]使用残差神经网络框架对复杂交通的时间接近性、周期和趋势属性进行建模。Yi等人[39]提出了一个由空间转换组件和深度分布式融合网络组成的模型(Deep-Air),可以预测未来各监测站的空气质量。Huang等人[41]提出了DeepCrime框架,该框架可以将所有的空间、时间和类型信息一起表示在一个隐藏的向量中,同时使用分层循环网络来捕捉犯罪动态,从而预测每个地区不同类型犯罪的发生率。Zhao等人[42]在研究POI推荐任务时,引入了情境感知的嵌入学习方法。
七、Conclusion
在本文中,我们提出了一个新的多视图多任务时空网络模型,名为MVMT-STN,以更有效地同时预测细粒度和粗粒度的城市交通事故风险。特别是,我们采用了一个多任务学习框架来联合预测细粒度和粗粒度的交通事故风险,以缓解数据的稀疏性问题。我们还设计了一个跨尺度的GCN和一个结构约束损失,以便在两个数据粒度上有效地耦合这两个预测任务。对于每个颗粒度,我们提出了一个信道明智的CNN和一个多视图的GCN来捕捉局部的地理和全球的语义依赖。为了获得外部环境特征对交通事故的不同影响,我们还提出了一个特征融合模块,实现了加权的多通道融合和跨视图信息共享。我们在两个真实世界的数据集上评估了我们的建议,结果验证了我们的模型优于最先进的方法。
在未来,进一步研究两个以上尺度的交通事故数据的时空相关性将是有趣的,因为更精细的相关性可能会进一步提高模型的性能,但也会导致粗粒度区域的数据更稀疏。研究该模型在其他时空数据预测任务中的扩展,如城市犯罪预测,也是很有意思的。
参考:注意力机制介绍:Attention机制详解(二)——Self-Attention与Transformer - 知乎