计算机操作系统 实验二:进程的控制
1 .实验目的
通过进程的创建、撤消和运行加深对进程概念和进程并发执行的理解,明确进程与程序之间的区别。
2 .实验内容
(1) 了解系统调用fork()、execvp()和wait()的功能和实现过程。
(2) 编写一段程序,使用系统调用fork()来创建两个子进程,并由父进程重复显示字符串“parent:”和自己的标识数,而子进程则重复显示字符串“child:”和自己的标识数。
(3) 编写一段程序,使用系统调用fork()来创建一个子进程。子进程通过系统调用execvp()更换自己的执行代码,新的代码显示“new program.”。而父进程则调用wait()等待子进程结束,并在子进程结束后显示子进程的标识符,然后正常结束。
3.实验步骤
(1) 了解系统调用fork()、execvp()和wait()的功能和实现过程。
fork()函数创建了和当前进程基本一模一样的一个子进程。当控制转到内核中的fork代码之后,内核先分配新的内存块和内核数据结构,然后将原来的进程复制到新的进程中去。最后向运行进程中添加新的进程并且控制重新返回到进程中。
wait()函数主要做两件事,首先wait暂停调用它的进程直到子进程结束,然后wait通过status取得子进程结束时传给exit的值。wait返回结束进程的PID,如果进程没有子进程或没有得到终止状态值,则返回-1。
execvp()函数用来执行指明的程序
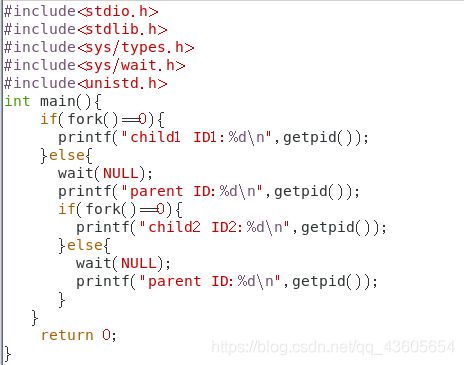
(2) 编写一段程序,使用系统调用fork()来创建两个子进程,并由父进程重复显示字符串“parent:”和自己的标识数,而子进程则重复显示字符串“child:”和自己的标识数。
#include
#include
#include
#include
#include
int main(){
if(fork()==0){
printf("child1 ID1:%d\n",getpid());
}else{
wait(NULL);
printf("parent ID:%d\n",getpid());
if(fork()==0){
printf("child2 ID2:%d\n",getpid());
}else{
wait(NULL);
printf("parent ID:%d\n",getpid());
}
}
return 0;
} 
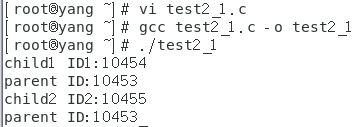
(3) 编写一段程序,使用系统调用fork()来创建一个子进程。子进程通过系统调用execvp()更换自己的执行代码,新的代码显示“new program.”。而父进程则调用wait()等待子进程结束,并在子进程结束后显示子进程的标识符,然后正常结束。
test3_1.c:
#include
#include
#include
int main(){
int p;
p=fork();
if(p==0){
execl("/root/test3_new",0);
}else{
printf("parent=%d\n",getpid());
waitpid();
printf("child=%d\n",getpid());
}
return 0;
} 
test3_new:
#include
int main(){
printf("new Program.\n");
return 0;
} 
运行结果:

4 .思考
按照自己的理解写的,很多地方不准确,有错误还请大佬指正
(1) 系统调用fork()是如何创建进程的?
一个进程调用fork()函数后,系统先给新的进程分配资源,例如存储数据和代码的空间。然后把原来的进程的所有值都复制到新的新进程中,只有少数值与原来的进程的值不同。相当于克隆了一个自己。
(2) 当首次将CPU 调度给子进程时,其入口在哪里?
fork系统调用创建的子进程继承了原进程的context,也就是说fork调用成功后,子进程与父进程并发执行相同的代码。但由于子进程也继承了父进程的程序指针,所以子进程是从fork()后的语句开始执行(也就是新进程调用的入口)。另外fork在子进程和父进程中的返回值是不同的。在父进程中返回子进程的PID,而在子进程中返回0。所以可以在程序中检查PID的值,使父进程和子进程执行不同的分支。
(3) 系统调用execvp()是如何更换进程的可执行代码的?
execvp()会从PATH 环境变量所指的目录中查找符合参数file 的文件名,找到后便执行该文件,然后将第二个参数argv传给该欲执行的文件。
(4) 对一个应用,如果用多个进程的并发执行来实现,与单个进程来实现有什么不同?
使用多个进程并发执行,则说明有许多个进程同时处理应用,比单个进程单独处理的效率要高,但是相对的并发执行消耗的资源页更多,要求也更高。
如果对你有帮助点个赞鼓励一下吧!