ChatGPT是由OpenAI开发的大型语言模型,可以帮助我们解决很多日常生活中的事情,如更改错误、写小说、回答问题、翻译、写文案等。

GPT 的演进
GPT一共有三代,即GPT-1,GPT-2,GPT-3,目前非常火的ChatGPT是GPT-3.5。GPT-1诞生于2018年6月,比BERT略早几个月,层数为12层,词向量长度为768,训练参数量为1.17亿个,数据量为5GB;时隔半年之后,GPT-2诞生于2019年2月,训练参数量为15亿个,数据量为40GB;GPT-3诞生于2020年5月,训练参数量增长超过100倍至1750亿个,数据量达到45TB。

GPT-1以Transformer 为核心结构,是自左向右单向的。GPT-2提出了“所有的有监督学习都是无监督语言模型的一个子集”的思想,即它是一个无监督模型,中间所有的过程都是通过无监督去完成的。对比GPT-2,GPT-3的模型结构上没有做任何的改变,它使用了超大的数据和参数量,真正诠释了什么叫“暴力出奇迹”。GPT系列虽然都取得了不错的成果,但始终会存在一个问题,即怎么样让它无害,它会生产出一些假的新闻,造成不好的社会影响。
GPT-1
自然语言里面有很多未标注数据,标好的数据比较少。GPT-1面临的问题是在没有标注的地方学习一个语言模型,在标好的数据上训练一个小模型。在做无监督的时候,我们会遇到两个最大的问题,一是不知道目标函数是什么,二是怎么传递到下一个子任务。

GPT-1采用的是传统语言模型的方式,k是窗口的大小,窗口越大就代表整个任务会更难。

将这些预测的概率向量和它的位置编码进行结合,就可以得到h0,h0通过transform解码器去进行解码,最终就得到它的编码,最后会接上一个微调模型。
这是GPT-1里面的应用,主要包括分类、蕴含、相似和多选,每一类任务都有一个标记,告诉这是任务的开始阶段、中间阶段还是结束阶段,如果是分类任务就在开始和结束阶段中间抽取一个text,开始和结束符号一定是特殊符号,最好不要在这些文本当中出现,最后我们再接一个Linear的分类器。二是蕴含,即B是否能够支持A,举个例子,小王和小李是好朋友,如果后面一句话是小王送给小李一个馒头,那么它的结果可能是正确的,这句话能证明他们是好朋友。如果是小王今天中午吃了一个馒头,这并不能证明小王和小李是好朋友。三是相似度的训练,类似头条的去重可以用到这样的算法。四是多选,即有A、B、C三个选择,应该去选择哪一个。当然整个的效果是不如BERT的,从技术难度上来说,BERT会更简单,并且GPT-1用的数据本身没有BERT那么大。

GPT-2
GPT-2模型来自论文《Language Models are Unsupervised Multitask Learners》,它希望通过zero-shot有所创新,即对于下游任务,不需要标注信息,在任何地方都能用。这里不能引入之前模型没见过的符号,提示符看上去更像一句话,这也是ChatGPT最初的一个版本,冒号前面告诉它你要做什么事情,如在英语到法语的翻译任务中,给模型一个英语和法语。或者告诉模型去回答一个问题,这个问题是什么,它会告诉你答案是什么。作者在阅读理解、翻译、总结和回答问题上进行实验,可以发现GPT-2在阅读理解和回答问题上效果会更好一些,同时当它的数据量越大,模型能够继续上升。

GPT-3
GPT-3模型来自论文《Language Models are Few-Shot Learners》,受到了zero-shot的启发,我们发现用大量的数据去做标注很困难,但如果一个样本都没有,它的泛化性不一定好,同时人类不需要很大的数据去做任务。这里用了两个方法,一是元学习,二是in-context learning。

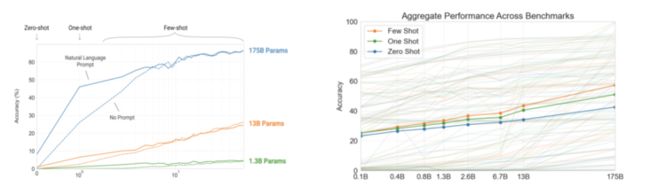
接下来我们来看一下Zero-shot、One-shot、Few-shot和Fine-tuning的区别。最常见的是Fine-tuning,即会给一批新的数据,需要对原来的数据做一定的梯度更新;Zero-shot是说只给提示,剩下自己去做;One-shot是说会告诉你去做什么,还会给一个示例;Few-shot是说会给更多的示例,告诉任务应该做成什么样。In-context learning是它的核心,指我们对模型进行引导,教会它应当输出什么内容。

作者对这3种学习方式分别进行了实验,可以看到在效果上Few-shot> One-shot > Zero-shot,且参数量越大模型表现越好。
ChatGPT的原理
ChatGPT的训练可以分成三步,第一步是需要去做一个有监督的模型;第二步是去收集数据给模型一个反馈,即做强化学习;第三步是根据强化学习,去优化原来的模型。

整个训练过程可以分为四个阶段,包括文字接龙、找一个老师、让老师给评分以及成为老师。

文字接龙
ChatGPT的第一个学习阶段是文字接龙,当我们给出一个不完整的句子,如“这个大白”,GPT会接下一个字,如“大白天”、“大白美”、“大白丑”,每次输出都会不一样,但是它会有一个概率。这里我们举个例子,如胡歌很帅,它刚开始学的就是胡,去预测胡歌;已知胡歌,去预测胡歌很;已知胡歌很,去预测胡歌很帅,整个过程完全不需要人工标注。

文字接龙有什么用呢?它就能够帮我们回答很多问题。如它在网上看到了一句话叫做“中国最大的淡水湖”,然后让它回答问题,它可以一个个字接下去,就可能会回答鄱阳湖。当然如果这样去做,它的准确率是非常低的,因为没有标注的数据,质量都是不可控制的。

比如说你问它“中国最大的淡水湖”,它可能回答“鄱阳湖”,也有可能回答“这个问题谁知道呢”,还有可能回答网上的一个选择题“是鄱阳湖还是太湖呢”。那么,怎么让它输出稳定下来变得更加可控呢?

找一个老师
要达到一个可用的状态,就要给它找到一个老师,去提供正确的答案,当然这种答案不需要特别多,ChatGPT里面大约给了一万个正确的答案。老师就会告诉它“中国最大的淡水湖是鄱阳湖”,然后对这些正确的答案加上更多的权重,告诉它人类的偏好是这样的,激发它本来的力量,本来ChatGPT也有能力生成这些答案。

让老师给评分
当它找到老师以后,就可以去慢慢模仿一个老师的喜好。当GPT去输出“鄱阳湖”、“太湖”的时候,会有一个判别器告诉说得分是多少,如果是“鄱阳湖”就可以给它更高的分数。

成为老师
在得到评分的标准后,我们需要把标准告诉GPT,让它知道这个答案是正确的,这就是比较常见的强化学习。即会告诉你,如果你回答对了,我会给你一个奖励,然后你去反馈到GPT当中去,给鄱阳湖加上更多的权重,这样ChatGPT就会自己成为老师,知道什么样的答案是正确的答案。

ChatGPT在营销的应用
ChatGPT最核心的观念有两个,一是使用了超大的参数,二是给数据做高质量的标注。这可以给算法同学一个启示,我们大部分时间可以不花在怎么用一些DIN、DCN、DeepFM之类的模型,更重要的是需要去给它更多的数据,加大它的参数量;二是高重量的标注,训练样本的质量一定要高,不能给一些错误或者模糊的答案,要给的数据标签一定要是非常正确的标签。在哈啰目前还没有一个超大模型出现,应用在推荐、营销、定价等各个方向。

应用场景主要有两个,一是逛逛,在ChatGPT上面我们可以告诉它一句话,然后它可以去生成图片,或者在逛逛里面的一个问题,我们可以用ChatGPT去辅助回答。二是运营同学在做广告标签的时候,我们可以去让ChatGPT生成这些标语,拿过来给它十句左右的提示语,适应哈啰的场景。

本文参与了SegmentFault 思否写作挑战赛,欢迎正在阅读的你也加入。