#第19篇分享:python初识大数据(1)-Hadoop开发环境搭建(Hadoop+jdk)
#走进数据的世界-----------------------大数据
1.什么叫大数据(说白了就是超级多的数据):
大数据(big data),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低的四大特征。
大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
2.大数据行业做什么?
应用大数据框架或者工具,实现数据的收集,存储,计算,分析等。
3.我们需要使用哪些工具,做什么:
a.hadoop:这是一个大数据处理的框架系统,主要需要了解的就是:
基本定义
①.Hadoop Common: 为其他hadoop模块提供基础设施,可以先不做学习;
②.Hadoop HDFS: 一个高可靠、高吞吐量的分布式文件存储系统—存储数据的;
③.Hadoop YARN: 一个新的MapReduce框架,任务调度与资源管理 ——分布式资源管理框架。
④.Hadoop MapReduce: 一个分布式的离线并进行计算框架 ——分布式计算框架;
⑤.OZone:是当前Apache Hadoop生态圈的一款新的对象存储系统,可用于小文件和大文件存储,设计的目的是为了填充社区在对象存储方面的不足,同时能够提供百亿甚至千亿级文件规模的存储。
OZone与HDFS有着很深的关系,在设计上也对HDFS存在的不足做了很多改进,使用HDFS的生态系统可以无缝切换到OZone。
b.Kafka:是个分布式消息队列, 简单理解一下,HDFS是分布式存储文件的,也就是扩展存储空间;kafka也是扩展空间,但是是用于传播,也就是信息通道变宽了。文件与信息的本质区别就是,文件是生成的类似于.txt文件,消息是在形成文件前的传播形式。
c.Zookeeper:是一个分布式的,开放源码的分布式应用程序 协调服务,可以看出他就是起协调作用的,比如控制信息传播过程的服务器分配,与kafka可以搭配使用。
d:Spark:是一个分布式的计算系统,我们发现了,hadoop里面的mapreduce也是有计算功能的,spark相对于hadoop自带的mapreduce循环计算,不用重复的去磁盘中读取数据,而是从缓存的内存中取数据,所以计算更快,但是内存空间毕竟有限,有时候根据实际情况还是要选取mapreduce的;说了这么多其实spark可以看做是hadoop生态圈扩展出的计算框架。
e.Flume/filebeat: 是分布式数据读取的框架,主要应用在日志数据的收集,用在kafka之前。
Hive: Hive 依赖于 HDFS 存储数据,Hive 将 HQL 转换成 MapReduce 执行,所以说 Hive 是基于 Hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计算框架,对存储在 HDFS 中的数据进行分析和管理。
Hbase: Apache HBase 是 Hadoop 数据库,一个分布式、可伸缩的大数据存储;HBase是依赖Hadoop的,为什么HBase能存储海量的数据?因为HBase是在HDFS的基础之上构建的,HDFS是分布式文件系统,HBase只是一个NoSQL数据库,把数据存在HDFS上。
Flink: Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。Flink 集成了所有常见的集群资源管理器,例如 Hadoop YARN、 Apache Mesos 和 Kubernetes,但同时也可以作为独立集群运行。
clichouse: ClickHouse是近年来备受关注的开源列式数据库,主要用于数据分析(OLAP)领域。
业务类系统主要供基层人员使用,进行一线业务操作,通常被称为OLTP(On-Line Transaction Processing,联机事务处理)。
数据分析的目标则是探索并挖掘数据价值,作为企业高层进行决策的参考,通常被称为OLAP(On-Line Analytical Processing,联机分析处理)。
4.阶段实操:vm上搭建一个三台电脑的虚拟机Linux(centos或者ubantu都可,我喜欢刺激,主机ubantu,从机1centos6,从机2 centos7),并完成三台Linux的hadoop安装,最终可以用./hadoop version 正常查看软件版本;
注:
学习过程建议全程在root用户下创建,因为涉及到很多权限问题(我不服气,非得在自己构建用户下创建,其实也没啥,没权限sudo用超级用户改一下权限也就行了,会遇见很多意想不到的快乐,挠头的快乐):
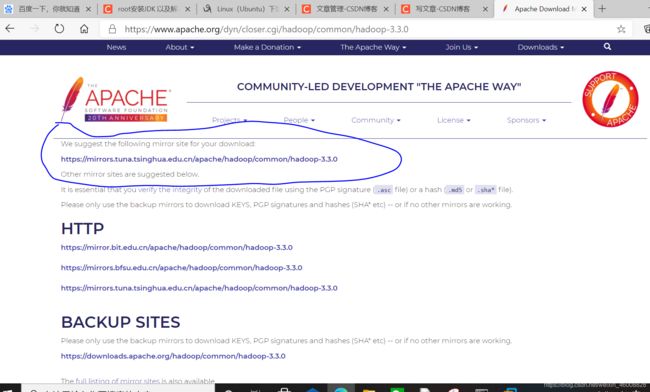
a.下载及安装hadoop:hadoop下载地址
注:
①.可以wget + hadoop下载网址(右键可以复制链接网址) 直接下载到Linux;
②.也可以先下到windows,然后再转入linux,我是用的这个,写过,自行查看(windows下载还是很快滴);Linux基本操作
b.安装Hadoop:
'''
Linux用到的命令:cd(切换路径),mkdir(创建目录),ll(查看文件), cp/mv -i(复制/移动文件),tar(解压),sudo(获得权限,提示你没有权限sudo一下即可),chmod(sudo权限还不够,chmod改一下即可),su(切换用户);
1.切换到root用户:su root 输入密码:xxxxxxx
2.切换到根目录:cd /
3.新建文件夹:mkdir program
4.把Hadoop压缩包导入program,cp(复制)/mv -i(移动)
5.解压即可用:tar -xvzf Hadoop-xxxxx(压缩包名称);
普通用户:sudo tar -xvzf Hadoop-xxxxx即可,需要输入密码;
''''
注:现在Hadoop还不可用,因为要依附Java环境,所以还需要安装Java,并且把Java的路径配置到Hadoop中的soft/hadoop-3.3.0/etc/hadoop/hadoop-env.sh(下面会介绍):

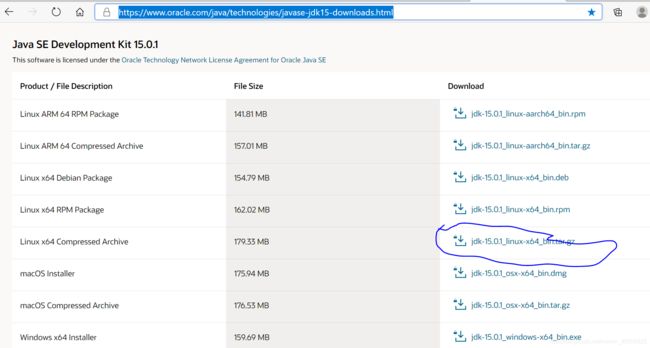
c.下载及安装java:java下载位置
'''
1.切换到root用户:su root 输入密码:xxxxxxx
2.切换到根目录:cd /
3.新建文件夹:mkdir soft
4.把java压缩包导入soft,cp(复制)/mv -i(移动)
5.解压即可用:tar -xvzf jdk-xxxxx(压缩包名称)
6.添加环境变量,为的是任何位置均可使用:(更改~/.bashrc:这是用户下面的环境变量,实践下来也是最有用的,/etc/profile说是配置全局环境变量,但是实践发现不咋好用):
a.vi ~/.bashrc(想在哪个用户下就去哪个用户下面改,这个环境变量配置是针对用户的)
b.然后再文件的末尾添加下面几行代码:
export JAVA_HOME= /soft/jdk-15.0.1(这里是你自己Java的安装目录)
export CLASSPATH=${JAVA_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
c.更新一下更改:source ~/.bashrc
d.验证是否成功:java -version(出现版本号就是成功了)
7.以上root用户的Java就好用了:普通用户想用,
a.进行文件目录授权,目的,让普通用户能够访问该目录,执行命令
sudo chmod -R 755 java安装目录
sudo chown -R [username] java安装目录
示例:
sudo chmod -R 755 /soft/jdk-15.0.1
sudo chown -R feiyuanhang /soft/jdk-15.0.1
b.普通用户username下设置环境变量:重复第六步骤即可;
''''
别看简单,属实是不容易呀:各种心酸,小白感受过才知道,不过弯路我已经走完了:

知识点:
#####################################
注:中间遇到的坑,现在来看一下:
1.jdk下载错误,下载成arm的了,也是环境变量不对,调了很久;
2.配置环境变量:自己也不懂,网上咋说咱就咋干,过后来看下这几种配置的区别吧,避免入坑:
a./etc/profile用来设置系统环境参数,比如$PATH. 这里面的环境变量是对系统内所有用户生效的;
b./etc/bashrc这个文件设置系统bash shell相关的东西,对系统内所有用户生效;只要用户运行bash命令,那么这里面的东西就在起作用。
c.~/.bash_profile用来设置一些环境变量,功能和/etc/profile 类似,但是这个是针对用户来设定的,也就是说,你在/home/user1/.bash_profile 中设定了环境变量,那么这个环境变量只针对 user1 这个用户生效.
d.~/.bashrc作用类似于/etc/bashrc, 只是针对用户自己而言,不对其他用户生效。另外/etc/profile中设定的变量(全局)的可以作用于任何用户,而~/.bashrc等中设定的变量(局部)只能继承/etc/profile中的变量,他们是”父子”关系.
注:
~/.bash_profile 是交互式、login 方式进入 bash 运行的,意思是只有用户登录时才会生效。
~/.bashrc 是交互式 non-login 方式进入 bash 运行的,用户不一定登录,只要以该用户身份运行命令行就会读取该文件。
e.sudoers(有的文章让改这个):sudo的权限控制可以在/etc/sudoers文件中查看到.如果想要控制某个用户(或某个组用户)只能执行root权限中的一部分命令, 或者允许某些用户使用sudo时不需要输入密码,就需要对该文件有所了解。
d.将java环境变量配置进Hadoop:soft/hadoop-3.3.0/etc/hadoop/hadoop-env.sh:命令:sudo vi hadoop-env.sh(进去后#export JAVA_HOME=是在的,找到解除注释,加上路径,保存退出,大功告成)

e.运行Hadoop看下效果吧(燥起来吧,万里长征第一步算是踏出去了):
注意路径:program/hadoop-3.3.0/bin
运行./hadoop version,你的配置好了吗?不懂就来交流交流,也不收钱,纯分享。

以上就完成了一个Hadoop开发环境的搭建,一起学习吧。
这篇博客写了有一阵子了,但是一直没有过来收个尾,是因为最近真的很烦呀,搭建HDFS的时候问题多多,下篇我在介绍,弄得我都怀疑自己了,好在经过几天的奋战,终于搞定了。
我们要相信,有些事情随着时间的流逝终会有结果,想有满意的结果的前提是我们从未停下脚步;前些天有个评论,说的是放弃很简单,但坚持很美,人人都知道,但坚持的痛苦真的是难以忍受,庆幸的是,我走过来了,虽然只是一小步,但足以让我对未来充满希望,支撑我走出下一步。
如果你也在前行,说明你还有选择的权力,我一直这么劝自己,哈哈哈哈
持续更新,,,,,,