MacOS网页自动化教程(下)- PySeTest网站自动登录到下单测试手脚架#Python3 + Selenium3+ HTMLTestRunner#工欲善其事
PySeTest网站自动登录到下单测试手脚架#Python3 + Selenium3+ HTMLTestRunner
- 系统说明
- 如何使用
- 功能说明
- 实现步骤
-
- 测试路径
- 测试脚本代码实现
- 常用方法封装
- Selenium基础用法
-
- Selenium 中文文档
- Selenium3 定位方法
- Selenium的等待
- 自动生成Html测试报告
-
- HTMLTestRunner 兼容Python3
- 如何使用
- 总结
- 系列文章
系统说明
系统版本:MacOS 10.15.7
Python: 3.8.0
Selenium: 3.141.0
如何使用
- 项目地址:PySeTest
- 下载项目文件。修改testIndex.py中以下几个全局变量
home_url = 'http://www.mi.com/'
login_name = '输入登录名'
login_pass = '输入登录密码'
test_product = "小米10 pro"
- 如果需要自动登录操作,需要修改auto_login方法。否者注释掉auto_login方法将testMain方法中的脚本改成合适自己的测试流程即可。
功能说明
实现网页自动化的手脚架项目PySeTest。目前是根据小米商城自动化测试流程来做的。其他的网站可根据实际情况修改。通过该项目实现以下功能
- 自动登录网页并保持Cookie
- 根据需求自动填写预设的文本
- 根据Xpath定位列表并选中或点击某一项
- 可点击弹出窗口确认按钮
- 显示等待,通过Xpath和文本内容定位后并点击
- 显示等待,通过标签ID定位
- 测试结果自动输出Html测试报告
实现步骤
测试路径
根据我对小米商城网页的分析,通过以下路径就能走完整个从登陆到下单的流程。
- 打开首页
- 跳转登录页,并自动登录,登录成功后返回首页
- 输入搜索关键字测试
- 点击搜索
- 打开搜索结果的第一个产品
- 点击 加入购物车 按钮
- 点击 去购物车结算 按钮
- 填写商品数量
- 点击 去结算 按钮,起订单确认页面
- 选择第一个地址
- 点击立即下单
- 判断是否下单成功
测试脚本代码实现
logger('开始自动化测试,首页测试...')
driver.get(home_url)
webWaitById(driver, 'J_siteUserInfo', 10, "自动化测试失败:首页打开超时")
logger('开始登录...')
auto_login(driver, login_name, login_pass)
webWaitById(driver, 'J_siteUserInfo', 10, "自动化测试失败:返回首页超时")
logger('输入搜索关键字测试')
driver.find_element_by_id('search').send_keys(test_product)
logger('点击搜索')
driver.find_element_by_xpath('//*[@id="J_submitBtn"]/input').click()
webWaitById(driver, 'J_navCategory', 10, "自动化测试失败:打开搜索列表超时")
findListAndOpen(driver,"//div[@class='goods-item']/div/a",0)
waitByTextAndClick(driver, "//a[@class='btn btn-primary']", '加入购物车', 10, "自动化测试失败:打开产品失败",1, True)
waitByTextAndClick(driver, "//a[@class='btn btn-primary']", '去购物车结算', 10, "自动化测试失败:加入购物车失败",1, True)
waitByTextAndClick(driver, "//a[@class='btn btn-a btn-primary']", '去结算', 10, "自动化测试失败:去购物车结算失败",1)
logger('输入商品数量')
auto_fill(driver, '//input[@class="goods-num"]', 1)
driver.find_element_by_xpath("//a[@class='btn btn-a btn-primary']").click()
waitByTextAndClick(driver, "//a[@class='btn btn-primary']", '去结算', 10, "自动化测试失败:去结算失败",1)
logger('选择第1个收货地址')
driver.find_elements_by_xpath("//div[@class='address-item']")[0].click()
waitByTextAndClick(driver, "//a[@class='btn btn-primary']", '立即下单', 10, "自动化测试失败:选中地址失败",1, True)
waitByTextAndClick(driver, "//*[@class='fl']", '订单提交成功!去付款咯~', 10, "自动化测试失败:下单失败",1)
logger('自动化测试成功')
通过使用我们手脚架封装的一些方法后,整个代码其实是挺简单的了、大家主要是要找到定位标签的Xpath就好。
常用方法封装
- 自动登录代码
def auto_login(driver, username, password):
#定位首页登录按钮
el = driver.find_element_by_xpath('//*[@id="J_siteUserInfo"]/a[1]')
#获取data-href属性值该值包含登录路径的跳转位置
url=el.get_attribute("data-href")
#跳转登录界面
driver.get("https://"+url)
#验证是否正确的跳转到登录界面
webWaitById(driver, 'main-content', 5, "自动化测试失败:登录页打开超时")
auto_fill(driver, '//input[@class="item_account" and @name="user"]', username)
auto_fill(driver, '//input[@class="item_account" and @name="password"]', password)
#定位登录按钮并点击登录按钮
driver.find_element_by_xpath('//input[@id="login-button" and @class="btnadpt"]').click()
webWaitById(driver, 'J_siteUserInfo', 5, "自动化测试失败:登录超时")
cookie_items = driver.get_cookies() # 獲取cookie值
# 传入cookies
for cookie in cookie_items:
driver.add_cookie(cookie)
其实很多网站的登录界面都大同小异。只要针对性的修改下代码就好。目前还未实现需要图形验证码登录的情况。
- 显示等待,通过Xpath和文本内容定位后并点击
# 显示等待,通过Xpath和文本内容定位后并点击
# param _driver: driver
# param xpath: xpath
# param text: 查找的文本
# param timeout: 等待几秒
# param err_msg: 错误信息
# param finally_sleep: 有时候等待的结果显示已经找到元素了。但实际上使用的时候还是报错。所以,强制延时几秒
# param is_click: 是否点击找到的文本
def waitByTextAndClick(_driver, xpath, text, timeout, err_msg, finally_sleep=0, is_click = False):
try:
#显示等待,通过Xpath和文本内容定位
WebDriverWait(_driver, timeout).until( EC.text_to_be_present_in_element((By.XPATH, xpath), text))
except TimeoutException:
#等待超时后打印错误信息
sys.exit(err_msg)
finally:
time.sleep(finally_sleep)
if is_click:
logger("点击:"+text)
_driver.find_element_by_xpath(xpath).click()
显示等待,隐式等待、强制等待。是selenium很重要的概念。下面我们会说的。理解了什么是显示等待就能理解上面的封装了。
其他方法就不一一介绍了。大家自己看代码吧
Selenium基础用法
Selenium 中文文档
第一手资料: Selenium官方文档
Selenium3 定位方法
-
Selenium提供了8种定位方式。
id
name
class name
tag name
link text
partial link text
xpath
css selector -
这8种定位方式在Python selenium中所对应的方法为:
find_element_by_id()
find_element_by_name()
find_element_by_class_name()
find_element_by_tag_name()
find_element_by_link_text()
find_element_by_partial_link_text()
find_element_by_xpath()
find_element_by_css_selector()
#定位列表或者是有多个结果的可以使用下面的方法
find_elements_by_id()
find_elements_by_name()
find_elements_by_class_name()
find_elements_by_tag_name()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_xpath()
find_elements_by_css_selector()
- 在Selenium3 中还可以使用find_element(By.ID, “id”)这种方式。以下是8中方法对应关系
find_element(By.ID, "id")
find_element(By.NAME, "name")
find_element(By.CLASS_NAME, "class name")
find_element(By.TAG_NAME, "tag name")
find_element(By.LINK_TEXT, "link text")
find_element(By.PARTIAL_LINK_TEXT, "partial link text")
find_element(By.XPATH, "xpath")
find_element(By.CSS_SELECTOR, "css selector")
#定位列表或者是有多个结果的可以使用下面的方法
find_elements(By.ID, "id")
find_elements(By.NAME, "name")
find_elements(By.CLASS_NAME, "class name")
find_elements(By.TAG_NAME, "tag name")
find_elements(By.LINK_TEXT, "link text")
find_elements(By.PARTIAL_LINK_TEXT, "partial link text")
find_elements(By.XPATH, "xpath")
find_elements(By.CSS_SELECTOR, "css selector")
- 如何快速的通过chrome找到元素的xpath值。
- 打开chrome的开发者工具。选中你要定位的元素
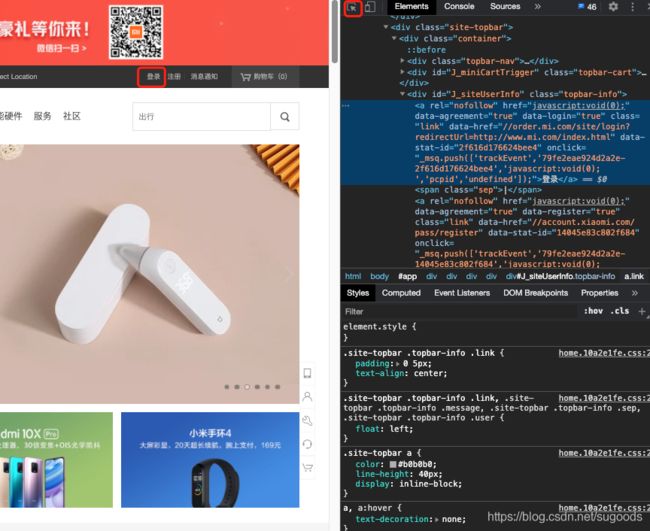
- 右键选中部分,copy -> Copy XPath
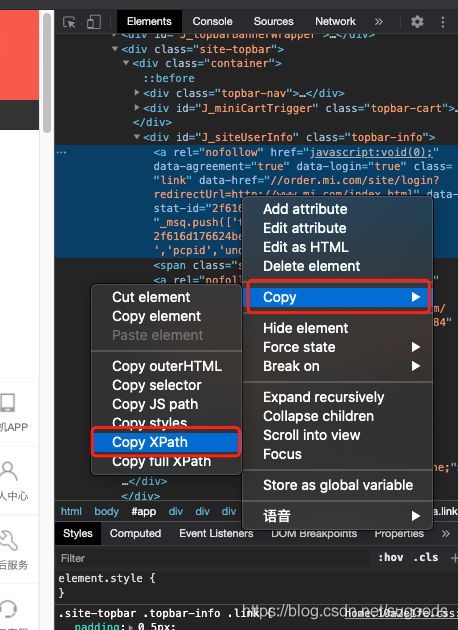
- 验证XPath的值是否能定位到对应的元素。可以使用快捷键cmd+F调出查找功能。然后粘贴刚刚复制的XPath值。如果能选中需要定位的内容那么证明XPath是符合预期的

- 小技巧
我们如果要自己手写XPath的时候,最好先通过chrome验证一下XPath再去跑脚本。这样比较省时间
Selenium的等待
等待是非常关键的,很多时候定位不到都是由于等待的时间不够导致的。因为代码的运算速度是很快的,但是Selenium需要等浏览器元素加载出来后才能定位到。如果我们不延时代码的执行,就可能出现代码跑完了界面还没加载出来,就抛出异常了。
所以,我们这里详细的说一下等待的使用,权威的内容请仔细查看官方文档,我自己总结的内容可能有些许偏差,希望大家谅解
Selenium等待部分的官方说明文档
- 强制等待
强制等待就是只要不死机或者脚本奔溃,就要强制等待完时间才能下一步。代码如下:
# -*- coding: utf-8 -*-
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
driver.get('https://github.com/sugood')
sleep(3) # 强制等待3秒再执行下一步
print driver.current_url
driver.quit()
- 隐式等待
隐式等待是设置一个最长时间,如果在规定时间内网页加载完成(就是浏览器标签栏那个小圈不再转),则执行下一步,否则一直等到时间截止,然后执行下一步。
# -*- coding: utf-8 -*-
from selenium import webdriver
driver = webdriver.Chrome()
driver.implicitly_wait(10) # 隐性等待,最长等10秒
driver.get('https://github.com/sugood')
print driver.current_url
driver.quit()
- 显式等待
WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了。它主要的意思就是:程序每隔xx秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.implicitly_wait(10) # 隐性等待和显性等待可以同时用,但要注意:等待的最长时间取两者之中的大者
driver.get('https://github.com/sugood')
locator = (By.LINK_TEXT, 'github')
try:
WebDriverWait(driver, 20,).until(EC.presence_of_element_located(locator))
print driver.find_element_by_link_text('github').get_attribute('href')
finally:
driver.close()
自动生成Html测试报告
HTMLTestRunner 兼容Python3
本项目已经集成了HTMLTestRunner,具体代码可以自行查看HTMLTestRunner.py文件,已经兼容Python3
如何使用
执行report.py会自动查找当前文件夹内所有test*.py并一一执行。同时在执行完所有的测试脚本后,自动生成测试结果(Html文件)在当前目录中。测试结果如下:
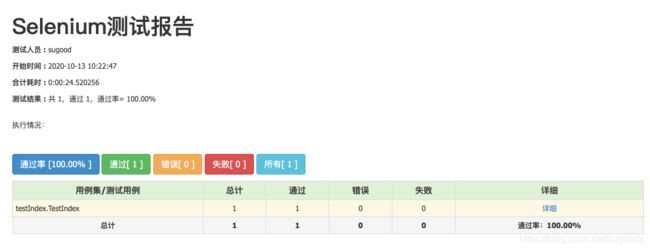
总结
一些小技巧。
- 遇到定位不到的情况,很可能是延时有问题。可以使用强制等待先测试没问题再换成显式等待。
- 显示等待成功后并不是所有操作都能执行的。显示操作成功只能说明元素加载出来了,但是,想要点击或者是跳转页面的时候。可能还不一定成功。因为这些操作可能还会涉及到其他的资源。需要等到所有相关的资源加载完才能操作。这个时候有个笨方法就是稍微加个强制等待再等以下。我们项目中的waitByTextAndClick方法就包含这种控制操作。
- 有时候遇到Max retries exceeded with url 报错很有可能是哪里脚本还未结束就执行了driver.quit()操作导致的
系列文章
MacOS网页自动化教程(上)- Python3 + Selenium3 + Chrome 环境安装#工欲善其事
MacOS网页自动化测试(中)- PyCharm配置Python教程并执行一个简单的脚本#工欲善其事
MacOS网页自动化教程(下)- PySeTest网站自动登录到下单测试手脚架#Python3 + Selenium3+ HTMLTestRunner#工欲善其事