【阿旭机器学习实战】【35】员工离职率预测---决策树与随机森林预测
【阿旭机器学习实战】系列文章主要介绍机器学习的各种算法模型及其实战案例,欢迎点赞,关注共同学习交流。
本文的主要任务是通过决策树与随机森林模型预测一个员工离职的可能性并帮助人事部门理解员工为何离职。
目录
- 1.获取数据
- 2.数据预处理
- 3.分析数据
-
- 3.1 相关性分析
- 3.2 进行 T-Test
- 4. 建立预测模型:Decision Tree V.S. Random Forest
- 5. 模型评估
-
- 5.1ROC 图
- 5.2通过决策树分析不同的特征的重要性
1.获取数据
关注GZH:阿旭算法与机器学习,回复:“ML35”即可获取本文数据集、源码与项目文档
# 引入工具包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as matplot
import seaborn as sns
%matplotlib inline
# 读入数据到Pandas Dataframe "df"
df = pd.read_csv('HR_comma_sep.csv', index_col=None)
2.数据预处理
# 检测是否有缺失数据
df.isnull().any()
satisfaction_level False
last_evaluation False
number_project False
average_montly_hours False
time_spend_company False
Work_accident False
left False
promotion_last_5years False
sales False
salary False
dtype: bool
# 数据的样例
df.head()
| satisfaction_level | last_evaluation | number_project | average_montly_hours | time_spend_company | Work_accident | left | promotion_last_5years | sales | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.38 | 0.53 | 2 | 157 | 3 | 0 | 1 | 0 | sales | low |
| 1 | 0.80 | 0.86 | 5 | 262 | 6 | 0 | 1 | 0 | sales | medium |
| 2 | 0.11 | 0.88 | 7 | 272 | 4 | 0 | 1 | 0 | sales | medium |
| 3 | 0.72 | 0.87 | 5 | 223 | 5 | 0 | 1 | 0 | sales | low |
| 4 | 0.37 | 0.52 | 2 | 159 | 3 | 0 | 1 | 0 | sales | low |
注:“turnover”列为标签:1表示离职,0表示不离职,其他列均为特征值
# 重命名
df = df.rename(columns={'satisfaction_level': 'satisfaction',
'last_evaluation': 'evaluation',
'number_project': 'projectCount',
'average_montly_hours': 'averageMonthlyHours',
'time_spend_company': 'yearsAtCompany',
'Work_accident': 'workAccident',
'promotion_last_5years': 'promotion',
'sales' : 'department',
'left' : 'turnover'
})
# 将预测标签‘是否离职’放在第一列
front = df['turnover']
df.drop(labels=['turnover'], axis=1, inplace = True)
df.insert(0, 'turnover', front)
df.head()
| turnover | satisfaction | evaluation | projectCount | averageMonthlyHours | yearsAtCompany | workAccident | promotion | department | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.38 | 0.53 | 2 | 157 | 3 | 0 | 0 | sales | low |
| 1 | 1 | 0.80 | 0.86 | 5 | 262 | 6 | 0 | 0 | sales | medium |
| 2 | 1 | 0.11 | 0.88 | 7 | 272 | 4 | 0 | 0 | sales | medium |
| 3 | 1 | 0.72 | 0.87 | 5 | 223 | 5 | 0 | 0 | sales | low |
| 4 | 1 | 0.37 | 0.52 | 2 | 159 | 3 | 0 | 0 | sales | low |
3.分析数据
- 14999 条数据, 每一条数据包含 10 个特征
- 总的离职率: 24%
- 平均满意度为 0.61
df.shape
(14999, 10)
# 特征数据类型.
df.dtypes
turnover int64
satisfaction float64
evaluation float64
projectCount int64
averageMonthlyHours int64
yearsAtCompany int64
workAccident int64
promotion int64
department object
salary object
dtype: object
turnover_rate = df.turnover.value_counts() / len(df)
turnover_rate
0 0.761917
1 0.238083
Name: turnover, dtype: float64
# 显示统计数据
df.describe()
| turnover | satisfaction | evaluation | projectCount | averageMonthlyHours | yearsAtCompany | workAccident | promotion | |
|---|---|---|---|---|---|---|---|---|
| count | 14999.000000 | 14999.000000 | 14999.000000 | 14999.000000 | 14999.000000 | 14999.000000 | 14999.000000 | 14999.000000 |
| mean | 0.238083 | 0.612834 | 0.716102 | 3.803054 | 201.050337 | 3.498233 | 0.144610 | 0.021268 |
| std | 0.425924 | 0.248631 | 0.171169 | 1.232592 | 49.943099 | 1.460136 | 0.351719 | 0.144281 |
| min | 0.000000 | 0.090000 | 0.360000 | 2.000000 | 96.000000 | 2.000000 | 0.000000 | 0.000000 |
| 25% | 0.000000 | 0.440000 | 0.560000 | 3.000000 | 156.000000 | 3.000000 | 0.000000 | 0.000000 |
| 50% | 0.000000 | 0.640000 | 0.720000 | 4.000000 | 200.000000 | 3.000000 | 0.000000 | 0.000000 |
| 75% | 0.000000 | 0.820000 | 0.870000 | 5.000000 | 245.000000 | 4.000000 | 0.000000 | 0.000000 |
| max | 1.000000 | 1.000000 | 1.000000 | 7.000000 | 310.000000 | 10.000000 | 1.000000 | 1.000000 |
# 分组的平均数据统计
turnover_Summary = df.groupby('turnover')
turnover_Summary.mean()
| satisfaction | evaluation | projectCount | averageMonthlyHours | yearsAtCompany | workAccident | promotion | |
|---|---|---|---|---|---|---|---|
| turnover | |||||||
| 0 | 0.666810 | 0.715473 | 3.786664 | 199.060203 | 3.380032 | 0.175009 | 0.026251 |
| 1 | 0.440098 | 0.718113 | 3.855503 | 207.419210 | 3.876505 | 0.047326 | 0.005321 |
3.1 相关性分析
# 相关性矩阵
corr = df.corr()
#corr = (corr)
sns.heatmap(corr,
xticklabels=corr.columns.values,
yticklabels=corr.columns.values)
corr
| turnover | satisfaction | evaluation | projectCount | averageMonthlyHours | yearsAtCompany | workAccident | promotion | |
|---|---|---|---|---|---|---|---|---|
| turnover | 1.000000 | -0.388375 | 0.006567 | 0.023787 | 0.071287 | 0.144822 | -0.154622 | -0.061788 |
| satisfaction | -0.388375 | 1.000000 | 0.105021 | -0.142970 | -0.020048 | -0.100866 | 0.058697 | 0.025605 |
| evaluation | 0.006567 | 0.105021 | 1.000000 | 0.349333 | 0.339742 | 0.131591 | -0.007104 | -0.008684 |
| projectCount | 0.023787 | -0.142970 | 0.349333 | 1.000000 | 0.417211 | 0.196786 | -0.004741 | -0.006064 |
| averageMonthlyHours | 0.071287 | -0.020048 | 0.339742 | 0.417211 | 1.000000 | 0.127755 | -0.010143 | -0.003544 |
| yearsAtCompany | 0.144822 | -0.100866 | 0.131591 | 0.196786 | 0.127755 | 1.000000 | 0.002120 | 0.067433 |
| workAccident | -0.154622 | 0.058697 | -0.007104 | -0.004741 | -0.010143 | 0.002120 | 1.000000 | 0.039245 |
| promotion | -0.061788 | 0.025605 | -0.008684 | -0.006064 | -0.003544 | 0.067433 | 0.039245 | 1.000000 |

正相关的特征:
- projectCount VS evaluation: 0.349333
- projectCount VS averageMonthlyHours: 0.417211
- averageMonthlyHours VS evaluation: 0.339742
负相关的特征:
- satisfaction VS turnover: -0.388375
# 比较离职和未离职员工的满意度
emp_population = df['satisfaction'][df['turnover'] == 0].mean()
emp_turnover_satisfaction = df[df['turnover']==1]['satisfaction'].mean()
print( '未离职员工满意度: ' + str(emp_population))
print( '离职员工满意度: ' + str(emp_turnover_satisfaction) )
未离职员工满意度: 0.666809590479516
离职员工满意度: 0.44009801176140917
3.2 进行 T-Test
进行一个 t-test, 看离职员工的满意度是不是和未离职员工的满意度明显不同
import scipy.stats as stats
stats.ttest_1samp(a = df[df['turnover']==1]['satisfaction'], # 离职员工的满意度样本
popmean = emp_population) # 未离职员工的满意度均值
Ttest_1sampResult(statistic=-51.3303486754725, pvalue=0.0)
T-Test 显示pvalue (0) 非常小, 所以他们之间是显著不同的
degree_freedom = len(df[df['turnover']==1])
LQ = stats.t.ppf(0.025,degree_freedom) # 95%致信区间的左边界
RQ = stats.t.ppf(0.975,degree_freedom) # 95%致信区间的右边界
print ('The t-分布 左边界: ' + str(LQ))
print ('The t-分布 右边界: ' + str(RQ))
The t-分布 左边界: -1.9606285215955626
The t-分布 右边界: 1.9606285215955621
# 概率密度函数估计
fig = plt.figure(figsize=(15,4),)
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'evaluation'] , color='b',shade=True,label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'evaluation'] , color='r',shade=True, label='turnover')
ax.set(xlabel='Employee Evaluation', ylabel='Frequency')
ax.legend()
plt.title('Employee Evaluation Distribution - Turnover V.S. No Turnover')
Text(0.5, 1.0, 'Employee Evaluation Distribution - Turnover V.S. No Turnover')

# 概率密度函数估计
fig = plt.figure(figsize=(15,4))
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'averageMonthlyHours'] , color='b',shade=True, label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'averageMonthlyHours'] , color='r',shade=True, label='turnover')
ax.legend()
ax.set(xlabel='Employee Average Monthly Hours', ylabel='Frequency')
plt.title('Employee AverageMonthly Hours Distribution - Turnover V.S. No Turnover')
Text(0.5, 1.0, 'Employee AverageMonthly Hours Distribution - Turnover V.S. No Turnover')

# 概率密度函数估计
fig = plt.figure(figsize=(15,4))
ax=sns.kdeplot(df.loc[(df['turnover'] == 0),'satisfaction'] , color='b',shade=True, label='no turnover')
ax=sns.kdeplot(df.loc[(df['turnover'] == 1),'satisfaction'] , color='r',shade=True, label='turnover')
plt.title('Employee Satisfaction Distribution - Turnover V.S. No Turnover')
ax.legend()

from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report, precision_score, recall_score, confusion_matrix, precision_recall_curve
# 将string类型转换为整数类型
df["department"] = df["department"].astype('category').cat.codes
df["salary"] = df["salary"].astype('category').cat.codes
# 产生X, y
target_name = 'turnover'
X = df.drop('turnover', axis=1)
y = df[target_name]
# 将数据分为训练和测试数据集
# 注意参数 stratify = y 意味着在产生训练和测试数据中, 离职的员工的百分比等于原来总的数据中的离职的员工的百分比
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.15, random_state=123, stratify=y)
df.head()
| turnover | satisfaction | evaluation | projectCount | averageMonthlyHours | yearsAtCompany | workAccident | promotion | department | salary | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0.38 | 0.53 | 2 | 157 | 3 | 0 | 0 | 7 | 1 |
| 1 | 1 | 0.80 | 0.86 | 5 | 262 | 6 | 0 | 0 | 7 | 2 |
| 2 | 1 | 0.11 | 0.88 | 7 | 272 | 4 | 0 | 0 | 7 | 2 |
| 3 | 1 | 0.72 | 0.87 | 5 | 223 | 5 | 0 | 0 | 7 | 1 |
| 4 | 1 | 0.37 | 0.52 | 2 | 159 | 3 | 0 | 0 | 7 | 1 |
4. 建立预测模型:Decision Tree V.S. Random Forest
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
# 决策树
dtree = tree.DecisionTreeClassifier(
criterion='entropy',
#max_depth=3, # 定义树的深度, 可以用来防止过拟合
min_weight_fraction_leaf=0.01 # 定义叶子节点最少需要包含多少个样本(使用百分比表达), 防止过拟合
)
dtree = dtree.fit(X_train,y_train)
print ("\n\n ---决策树---")
dt_roc_auc = roc_auc_score(y_test, dtree.predict(X_test))
print ("决策树 AUC = %2.2f" % dt_roc_auc)
print(classification_report(y_test, dtree.predict(X_test)))
# 随机森林
rf = RandomForestClassifier(
criterion='entropy',
n_estimators=1000,
max_depth=None, # 定义树的深度, 可以用来防止过拟合
min_samples_split=10, # 定义至少多少个样本的情况下才继续分叉
#min_weight_fraction_leaf=0.02 # 定义叶子节点最少需要包含多少个样本(使用百分比表达), 防止过拟合
)
rf.fit(X_train, y_train)
print ("\n\n ---随机森林---")
rf_roc_auc = roc_auc_score(y_test, rf.predict(X_test))
print ("随机森林 AUC = %2.2f" % rf_roc_auc)
print(classification_report(y_test, rf.predict(X_test)))
---决策树---
决策树 AUC = 0.93
precision recall f1-score support
0 0.97 0.98 0.97 1714
1 0.93 0.89 0.91 536
accuracy 0.96 2250
macro avg 0.95 0.93 0.94 2250
weighted avg 0.96 0.96 0.96 2250
---随机森林---
随机森林 AUC = 0.97
precision recall f1-score support
0 0.98 1.00 0.99 1714
1 0.99 0.94 0.97 536
accuracy 0.98 2250
macro avg 0.99 0.97 0.98 2250
weighted avg 0.98 0.98 0.98 2250
5. 模型评估
5.1ROC 图
# ROC 图
from sklearn.metrics import roc_curve
rf_fpr, rf_tpr, rf_thresholds = roc_curve(y_test, rf.predict_proba(X_test)[:,1])
dt_fpr, dt_tpr, dt_thresholds = roc_curve(y_test, dtree.predict_proba(X_test)[:,1])
plt.figure()
# 随机森林 ROC
plt.plot(rf_fpr, rf_tpr, label='Random Forest (area = %0.2f)' % rf_roc_auc)
# 决策树 ROC
plt.plot(dt_fpr, dt_tpr, label='Decision Tree (area = %0.2f)' % dt_roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC Graph')
plt.legend(loc="lower right")
plt.show()

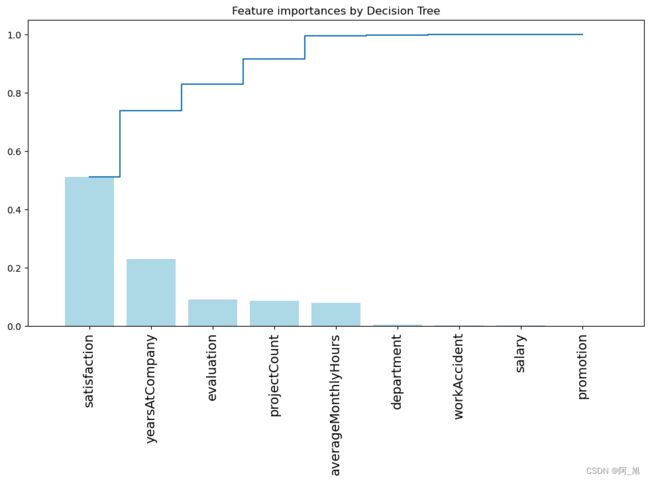
5.2通过决策树分析不同的特征的重要性
## 画出决策树特征的重要性 ##
importances = rf.feature_importances_
feat_names = df.drop(['turnover'],axis=1).columns
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(12,6))
plt.title("Feature importances by RandomForest")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()

## 画出决策树的特征的重要性 ##
importances = dtree.feature_importances_
feat_names = df.drop(['turnover'],axis=1).columns
indices = np.argsort(importances)[::-1]
plt.figure(figsize=(12,6))
plt.title("Feature importances by Decision Tree")
plt.bar(range(len(indices)), importances[indices], color='lightblue', align="center")
plt.step(range(len(indices)), np.cumsum(importances[indices]), where='mid', label='Cumulative')
plt.xticks(range(len(indices)), feat_names[indices], rotation='vertical',fontsize=14)
plt.xlim([-1, len(indices)])
plt.show()
如果文章对你有帮助,感谢点赞+关注!
关注下方GZH:阿旭算法与机器学习,回复:“ML35”即可获取本文数据集、源码与项目文档,欢迎共同学习交流