论文(四)YOLOv4解读及一些思考
目录
1. Mosaic技巧与mini-batch有什么关系?
2. 作者为啥要参考2019年的CSPNet,采用CSP模块?
3. 主干网络采用mish:
4. Dropblock
5. SPP模块(neck)
6. FPN+PAN(neck)
7. Prediction创新
(1)CIOU_loss
(2)DIOU_nms
8.YoloV4相关代码
8.1 python代码
8.2 C++代码
8.3 python版本的Tensorrt代码
8.4 C++版本的Tensorrtrt代码
1. Mosaic技巧与mini-batch有什么关系?
2. 作者为啥要参考2019年的CSPNet,采用CSP模块?
CSPNet论文地址:https://arxiv.org/pdf/1911.11929.pdf
CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中从计算量很大的问题。
CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。
因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。
因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点:
优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。
优点二:降低计算瓶颈
优点三:降低内存成本
3. 主干网络采用mish:
Mish激活函数是2019年下半年提出的激活函数
论文地址:https://arxiv.org/abs/1908.0868
4. Dropblock
Yolov4中使用的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式。
Dropblock在2018年提出,论文地址:https://arxiv.org/pdf/1810.12890.pdf
传统的Dropout很简单,一句话就可以说的清:随机删除减少神经元的数量,使网络变得更简单。
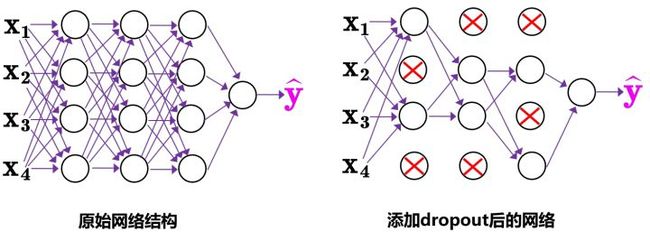
而Dropblock和Dropout相似,比如下图:

中间Dropout的方式会随机的删减丢弃一些信息,但Dropblock的研究者认为,卷积层对于这种随机丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。
因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。
所以右图Dropblock的研究者则干脆整个局部区域进行删减丢弃。
这种方式其实是借鉴2017年的cutout数据增强的方式,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。

Dropblock的研究者与Cutout进行对比验证时,发现有几个特点:
优点一:Dropblock的效果优于Cutout
优点二:Cutout只能作用于输入层,而Dropblock则是将Cutout应用到网络中的每一个特征图上
优点三:Dropblock可以定制各种组合,在训练的不同阶段可以修改删减的概率,从空间层面和时间层面,和Cutout相比都有更精细的改进。
Yolov4中直接采用了更优的Dropblock,对网络的正则化过程进行了全面的升级改进。
5. SPP模块(neck)
在Yolov4中,SPP模块仍然是在Backbone主干网络之后:

作者在SPP模块中,使用k={1*1,5*5,9*9,13*13}的最大池化的方式,再将不同尺度的特征图进行Concat操作。
注意:这里最大池化采用padding操作,移动的步长为1,比如13×13的输入特征图,使用5×5大小的池化核池化,padding=2,因此池化后的特征图仍然是13×13大小。
在2019提出的《DC-SPP-Yolo》文章:https://arxiv.org/ftp/arxiv/papers/1903/1903.08589.pdf
也对Yolo目标检测的SPP模块进行了对比测试。
和Yolov4作者的研究相同,采用SPP模块的方式,比单纯的使用k*k最大池化的方式,更有效的增加主干特征的接收范围,显著的分离了最重要的上下文特征。
6. FPN+PAN(neck)
PAN结构比较有意思,看了网上Yolov4关于这个部分的讲解,大多都是讲的比较笼统的,而PAN是借鉴图像分割领域PANet的创新点,有些同学可能不是很清楚。
下面大白将这个部分拆解开来,看下Yolov4中是如何设计的。
Yolov3结构:
我们先来看下Yolov3中Neck的FPN结构
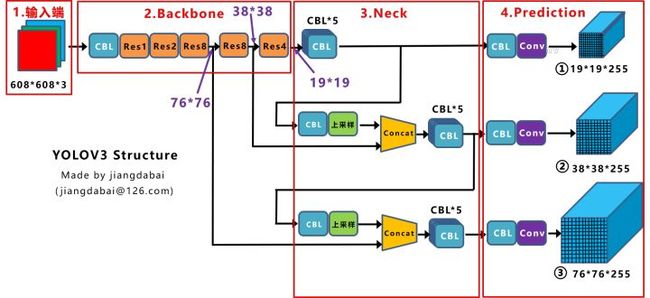
可以看到经过几次下采样,三个紫色箭头指向的地方,输出分别是76*76、38*38、19*19。
以及最后的Prediction中用于预测的三个特征图①19*19*255、②38*38*255、③76*76*255。[注:255表示80类别(1+4+80)×3=255]
我们将Neck部分用立体图画出来,更直观的看下两部分之间是如何通过FPN结构融合的。
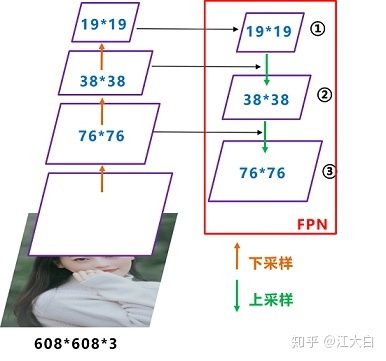
如图所示,FPN是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。
Yolov4结构:
而Yolov4中Neck这部分除了使用FPN外,还在此基础上使用了PAN结构:
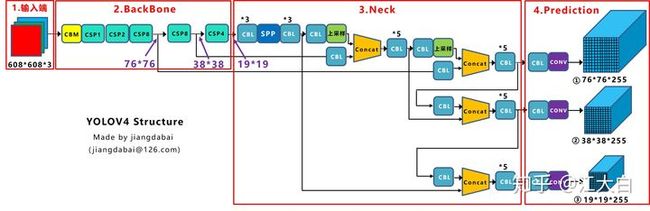
前面CSPDarknet53中讲到,每个CSP模块前面的卷积核都是3*3大小,步长为2,相当于下采样操作。
因此可以看到三个紫色箭头处的特征图是76*76、38*38、19*19。
以及最后Prediction中用于预测的三个特征图:①76*76*255,②38*38*255,③19*19*255。
我们也看下Neck部分的立体图像,看下两部分是如何通过FPN+PAN结构进行融合的。

和Yolov3的FPN层不同,Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。
其中包含两个PAN结构。
这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合,这样的操作确实很皮。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
不过这里需要注意几点:
注意一:
Yolov3的FPN层输出的三个大小不一的特征图①②③直接进行预测
但Yolov4的FPN层,只使用最后的一个76*76特征图①,而经过两次PAN结构,输出预测的特征图②和③。
这里的不同也体现在cfg文件中,这一点有很多同学之前不太明白,
比如Yolov3.cfg最后的三个Yolo层,
第一个Yolo层是最小的特征图19*19,mask=6,7,8,对应最大的anchor box。
第二个Yolo层是中等的特征图38*38,mask=3,4,5,对应中等的anchor box。
第三个Yolo层是最大的特征图76*76,mask=0,1,2,对应最小的anchor box。
而Yolov4.cfg则恰恰相反
第一个Yolo层是最大的特征图76*76,mask=0,1,2,对应最小的anchor box。
第二个Yolo层是中等的特征图38*38,mask=3,4,5,对应中等的anchor box。
第三个Yolo层是最小的特征图19*19,mask=6,7,8,对应最大的anchor box。
注意点二:
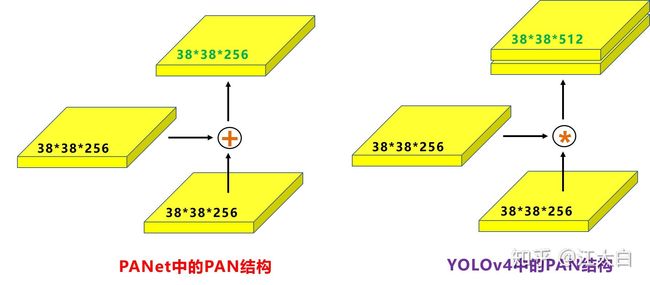
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用concat(route)操作,特征图融合后的尺寸发生了变化。
7. Prediction创新
(1)CIOU_loss
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。
Bounding Box Regeression的Loss近些年的发展过程是:Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
我们从最常用的IOU_Loss开始,进行对比拆解分析,看下Yolov4为啥要选择CIOU_Loss。
a.IOU_Loss
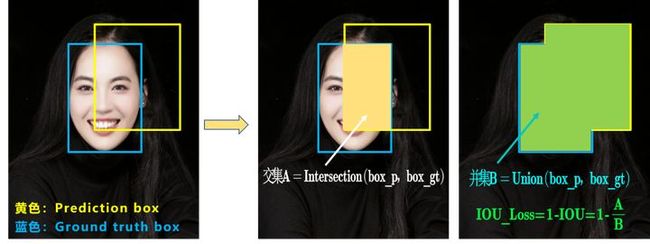
可以看到IOU的loss其实很简单,主要是交集/并集,但其实也存在两个问题。

问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况。
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
因此2019年出现了GIOU_Loss来进行改进。
b.GIOU_Loss
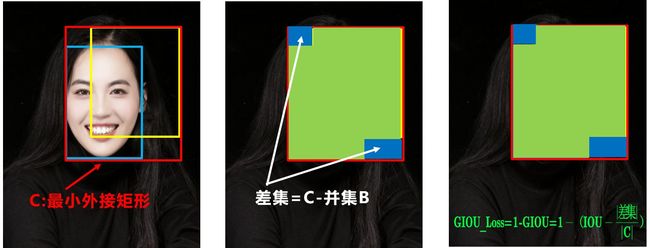
可以看到右图GIOU_Loss中,增加了相交尺度的衡量方式,缓解了单纯IOU_Loss时的尴尬。
但为什么仅仅说缓解呢?
因为还存在一种不足:

问题:状态1、2、3都是预测框在目标框内部且预测框大小一致的情况,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
基于这个问题,2020年的AAAI又提出了DIOU_Loss。
c.DIOU_Loss
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU和GIOU存在的问题,作者从两个方面进行考虑
一:如何最小化预测框和目标框之间的归一化距离?
二:如何在预测框和目标框重叠时,回归的更准确?
针对第一个问题,提出了DIOU_Loss(Distance_IOU_Loss)

DIOU_Loss考虑了重叠面积和中心点距离,当目标框包裹预测框的时候,直接度量2个框的距离,因此DIOU_Loss收敛的更快。
但就像前面好的目标框回归函数所说的,没有考虑到长宽比。

比如上面三种情况,目标框包裹预测框,本来DIOU_Loss可以起作用。
但预测框的中心点的位置都是一样的,因此按照DIOU_Loss的计算公式,三者的值都是相同的。
针对这个问题,又提出了CIOU_Loss,不对不说,科学总是在解决问题中,不断进步!!
d.CIOU_Loss
CIOU_Loss和DIOU_Loss前面的公式都是一样的,不过在此基础上还增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去。
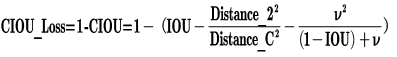
其中v是衡量长宽比一致性的参数,我们也可以定义为:

这样CIOU_Loss就将目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比全都考虑进去了。
再来综合的看下各个Loss函数的不同点:
IOU_Loss:主要考虑检测框和目标框重叠面积。
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
DIOU_Loss:在IOU和GIOU的基础上,考虑边界框中心点距离的信息。
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
Yolov4中采用了CIOU_Loss的回归方式,使得预测框回归的速度和精度更高一些。
(2)DIOU_nms
Nms主要用于预测框的筛选,常用的目标检测算法中,一般采用普通的nms的方式,Yolov4则借鉴上面D/CIOU loss的论文:https://arxiv.org/pdf/1911.08287.pdf
将其中计算IOU的部分替换成DIOU的方式:
再来看下实际的案例

在上图重叠的摩托车检测中,中间的摩托车因为考虑边界框中心点的位置信息,也可以回归出来。
因此在重叠目标的检测中,DIOU_nms的效果优于传统的nms。
注意:有读者会有疑问,这里为什么不用CIOU_nms,而用DIOU_nms?
答:因为前面讲到的CIOU_loss,是在DIOU_loss的基础上,添加的影响因子,包含groundtruth标注框的信息,在训练时用于回归。
但在测试过程中,并没有groundtruth的信息,不用考虑影响因子,因此直接用DIOU_nms即可。
总体来说,YOLOv4的论文称的上良心之作,将近几年关于深度学习领域最新研究的tricks移植到Yolov4中做验证测试,将Yolov3的精度提高了不少。
虽然没有全新的创新,但很多改进之处都值得借鉴,借用Yolov4作者的总结。
Yolov4 主要带来了 3 点新贡献:
(1)提出了一种高效而强大的目标检测模型,使用 1080Ti 或 2080Ti 就能训练出超快、准确的目标检测器。
(2)在检测器训练过程中,验证了最先进的一些研究成果对目标检测器的影响。
(3)改进了 SOTA 方法,使其更有效、更适合单 GPU 训练。
8.YoloV4相关代码
8.1 python代码
代码地址:https://github.com/Tianxiaomo/pytorch-Yolov4
作者的训练和测试推理代码都已经完成
8.2 C++代码
Yolov4作者Alexey的代码,俄罗斯的大神,应该是个独立研究员,更新算法的频繁程度令人佩服。
在Yolov3作者Joseph Redmon宣布停止更新Yolo算法之后,Alexey凭借对于Yolov3算法的不断探索研究,赢得了Yolov3作者的认可,发布了Yolov4。
代码地址:https://github.com/AlexeyAB/darknet
8.3 python版本的Tensorrt代码
目前测试有效的有tensorflow版本:weights->pb->trt
代码地址:https://github.com/hunglc007/tensorflow-Yolov4-tflite
8.4 C++版本的Tensorrtrt代码
代码地址:https://github.com/wang-xinyu/tensorrtx/tree/master/Yolov4
作者自定义了mish激活函数的plugin层,Tensorrt加速后速度还是挺快的。
参考:https://zhuanlan.zhihu.com/p/143747206
https://blog.csdn.net/nan355655600/article/details/106246625/(图片清晰无水印)
个人的一些思考:
1. yolov4利用一个特征图经过两次PAN得到另外两个特征图进行预测,yolov3直接利用FPN输出三个特征图进行预测,这两者有什么区别?
2. yolov4中为什么最大的特征图对应最小的anchor box?
3. 为什么yolov4中将add操作改为concat?
(各位如果有知道的还请指导一下)