YOLOv1论文解读/总结
文章目录
前言
摘要
一、Introduction—介绍
二、 Unified Detection-统一检测
三、Comparison to Other Detection Systems—与其他目标检测算法的比较
四. Experiments--实验
五. Real-Time Detection In The Wild--野外实时检测
六、Conclusion—结论
YOLO系列论文:YOLOv1论文(You Only Look Once:Unified, Real-Time Object Detection)(原文+解读/总结+翻译)
前言
YOLO是Joseph Redmon为主要作者,在2015年提出的第一个基于单个神经网络的目标检测系统。也是一种新的目标检测算法。 它与之前的目标检测算法不同之处在于,YOLOv1是一种端到端的算法,它把目标检测问题看作回归问题,作者将图片输入进单一的神经网络,然后就输出得到了图片的物体边界框以及相关类别概率的回归问题。
Joseph Redmon 被我们称作YOLO之父,也被叫做小马哥。小马哥是一位相当牛皮的大佬,负责编写了YOLO系列的V1,V2,V3系列,但是因为后期美国军方曾将YOLO智能识别技术用于军事武器开发,作者不希望自己的成果被用在军事上,因此他后面个人在推特上声明,停止一切有关CV的研究,退出了计算机视觉方面的研究和工作,导致后面的V4到V6都是由继任者完成的维护,升级。是一个相当有责任担当且水平超高风趣幽默的一位大佬。下面我们来学习介绍大佬的YOLO系列论文开篇巨作—YOLOv1。下面是论文总结及原文:
论文原文:You Only Look Once: Unified, Real-Time Object Detection (cv-foundation.org)
论文翻译:YOLO系列论文:YOLOv1论文 论文翻译(已校正)_耿鬼喝椰汁的博客-CSDN博客
摘要
作者在第一段首先说提出了一种新的目标检测方法YOLO,他们与之前使用的目标检测方法不同:
(1)他们将目标检测框定为空间分离的边界框和相关类别概率的回归问题。
(2)整个流水线为单个网络。
(3)在检测性能上是端对端的优化。
接下来作者介绍YOLO算法与传统目标检测方法优点:
(1)检测速度快:每秒45帧的检测速率,可用在实时视频检测中,在更小的模型上甚至达到155帧;
(2)通用性好:在真实图像数据上训练的网络,可以用在虚构的绘画作品上。
一、Introduction—介绍
作者在此模块介绍了以下几点:1.YOLO算法与之前算法相比步骤上如何十分简单。2.YOLO算法与之前算法相比的三大优点及不足。
1.步骤对比:
之前的检测方法:(1)DMP:系统采用分类器,并在测试图像中的各种位置和尺度 处评估该对象。使用滑动窗口方法,其分类器在整个图像上均匀间隔的位置上运行。
(2)RCNN:使用区域候选策略,生成边界框-运行分类器-分类-细化边界框,消除重复检测-基于场景回归。
(之前检测流程复杂很难优化且每个部分都需要单独训练)
YOLO检测方法:(十分简单) 它仅用单个卷积网络就能同时预测多个边界框和这些框的类别概率。YOLO在整个图像上训练并能直接优化检测性能。 YOLO
训练步骤:(1)将输入图像的大小调整为448 × 448,
(2)在图像上运行单个卷积网络
(3)通过模型的置信度对检测结果进行阈值处理。

2.YOLO三大优点及不足:
优点:
(1)YOLO速度极快。 --在Titan X GPU上没有批处理的情况下,YOLO的基础版本以每秒45帧的速度运行,而快速版本运行速度超过150fps。这意味着我们可以在不到25毫秒的延迟内,实时处理流媒体视频。
(2)YOLO是在整个图像上进行推断的。 --YOLO在训练和测试期间都会顾及到整个图像,很少会将背景块误检为目标。与Fast R-CNN相比,YOLO的背景误检数量不到一半。
(3)YOLO能学习到目标的泛化表征。 --由于YOLO具有高度的泛化能力,因此在应用于新领域或碰到意外的输入时,它不太可能崩溃。
不足: YOLO在准确性方面仍然落后于最先进的检测系统。很难精确定位一些物体,特别是小物体。
二、 Unified Detection-统一检测
作者在此章节主要介绍了检测原理、网络结构、以及损失函数。
检测原理:
yolov1将图像划分为S*S的网格,如果检测物体落到网格中心,那么就由这个网络来预测该物体。
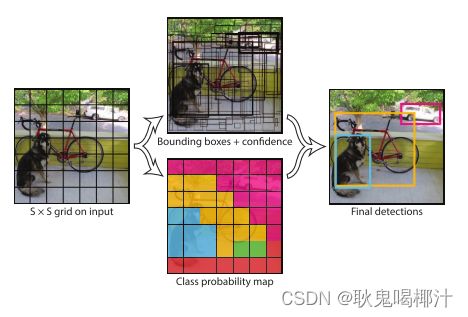
每个网格预测B个边界框和那些边界框的置信度。置信度反映了该边界框是否包含目标且包含目标的准确度。置信度的定义: 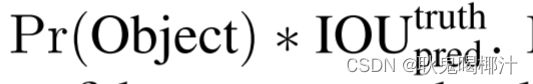
置信度定义式左边表示概率,右边表示IOU。如果该网格中不存在检测物体,那么置信度为0,如果存在检测物体,那么置信度为预测框和真实框的IOU。
每个边界框都由五个数字组成,分别为:x , y , w , h , 置信度。(x,y)是边界框中心坐标相较于网格的坐标。h,w,是预测框相较于整个图像的高和宽。也就是说这里的x,y,w,h都不是真实值,而是相对值,分别相较于网格和整个图像。最后置信度表示预测框和真实框的IOU.
每个网络还负责预测C个类条件概率。定义为:
(这里只是预测每个网络含有每类物体的概率,不是每个预测框。)
在测试的时候 ,将类条件概率和单个框的置信度相乘,
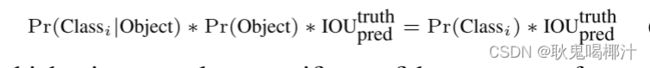
就得到了每个边界框关于某个类别的置信度。该置信度表示了该类目标出现在该边界框的概率和该预测框和真实边界框的拟合程度。
网络结构
YOLO输入图像的尺寸为 448 × 448 ,经过24个卷积层,2个全连接的层(FC),输出的特征图大小为 7 × 7 × 30。
(YOLO网络结构图)
(1)YOLO主要是建立一个CNN网络生成预测 7 × 7 × 1024 的张量
(2)然后使用两个全连接层执行线性回归,以进行 7 × 7 × 2 边界框预测。将具有高置信度得分(大于0.25)的结果作为最终预测。
(3)在 3 × 3 的卷积后通常会接一个通道数更低 1 × 1 的卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力。
(4)除了最后一层使用了线性激活函数外,其余层的激活函数为 Leaky ReLU ;(5)在训练中使用了 Dropout 与数据增强的方法来防止过拟合。
(6)对于最后一个卷积层,它输出一个形状为 (7, 7, 1024) 的张量。 然后张量展开。使用2个全连接的层作为一种线性回归的形式,它输出 个参数,然后重新塑形为 (7, 7, 30) 。

(YOLO网络概括图)
YOLO网络借鉴了GoogleNet的思想,但与之不同的是,为了更好的性能,它增加额外的4层卷积层(conv)。YOLO一共使用了24个级联的卷积层和2个全连接层(fc),其中conv层中包含了1×1和3×3两种卷积核,最后一个fc全连接层后经过reshape之后就是YOLO网络的输出,最后经过识别过程得到最终的检测结果。
在整个网络(24+2)的训练过程中,除最后一层采用ReLU函数外,其他层均采用leaky ReLU激活函数。leaky ReLU相对于ReLU函数可以解决在输入为负值时的零梯度问题。YOLOv1中采用的leaky ReLU函数的表达式为: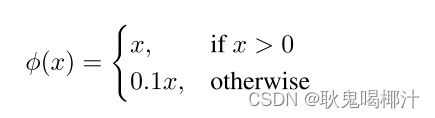
损失函数:
损失函数包括:
localization loss -> 边框损失
confidence loss -> 置信度损失
classification loss -> 分类损失

图中为论文中提出的loss函数公式,可以把他分为三类,分别是bbox的边框误差,bbox的置信度误差,单元格的分类误差。其中i表示单元格,j表示每个单元格对应的box,obj表示存在目标物体(前景),入表示权重。其中第二行的宽高损失使用根号为了确保大边框和小边框的宽高差损失差距不大。
其中使用非极大值抑制的方法过滤掉重复的边框,减少不必要的计算。
三、Comparison to Other Detection Systems—与其他目标检测算法的比较
作者在此章节将自己模型与之前模型对比了以下:
DMP: 计算量巨大,而且是个静态的,没办法匹配很多变化的东西,鲁棒性差。
R-CNN:YOLO对比他们俩都很强,YOLO和R-CNN也有相似的地方。
Other Fast Detectors :Fast和Faster R-CNN :这俩模型都是基于R-CNN的进阶版,速度和精度都提升了很多,但是也没办法做到实时监测。
Deep MultiBox:YOLO和MultiBox都使用卷积网络来预测图像中的边界框,但YOLO是一个完整的检测系统。
OverFeat:OverFeat可以有效地执行滑动窗口检测,优化定位,但没优化检测性能。与DPM一样,OverFeat不能推理全局上下文。
MultiGrasp:YOLO在设计上与Redmon等人的抓取检测工作相似。 MultiGrasp只需要为包含一个目标的图像预测一个可抓取区域。 它不必估计目标的大小,位置或边界或预测它的类别,只需找到适合抓取的区域就可以了。 而YOLO则是预测图像中多个类的多个目标的边界框和类别概率。
四. Experiments--实验
首先,作者在PASCAL VOC 2007上比较了YOLO和其他实时检测系统、对YOLO和Fast R-CNN在VOC 2007进行误差分析、Fast R-CNN与YOLO的结合、提供了VOC 2012结果。最后,作者在两个艺术品数据集上证明了YOLO比其他检测器更好地推广到新的领域。
五. Real-Time Detection In The Wild--野外实时检测
作者将YOLO连接到摄像头上,并验证它是否保持了实时性能,包括从摄像头中获取图像和显示检测结果的时间。结果证明效果很好,如下图所示,除了第二行第二个将人误判为飞机以外,别的没问题。

六、Conclusion—结论
作者对YOLO模型进行总结:
YOLO--一种用于物体检测的统一模型。模型构造简单,可以直接在完整图像上训练。 与基于分类器的方法不同,YOLO是通过与检测性能直接对应的损失函数进行训练的,并且整个模型是一起训练的。
快速YOLO是文献中最快的通用目标检测器,YOLO推动实时对象检测的最新技术。 YOLO还能很好地推广到新领域,使其成为快速,鲁棒性强的应用的理想选择。
这篇论文的学习和总结到这里就结束啦,如果有什么问题可以在评论区留言呀~
如果帮助到大家,可以一键三连支持下~