selenium八大元素定位方法
目录
1.为什么要学习元素定位?
1.1元素定位的底层逻辑
2.定位方法总结
(1)id定位
(2)name定位
(3)class_name定位
(4)tag_name定位
(5)link_text定位
(6)partial_link_text定位
(7)元素组定位
(8)xpath定位
(9)css定位
1.为什么要学习元素定位?
1.让程序操作指定元素,就必须先找到此元素。
2.程序不像人类的眼睛能够直接定位到元素
1.1元素定位的底层逻辑
使用python+selenium实现寻找的底层逻辑,通过元素的属性和元素的路径来寻找。定位元素的方式有两种,一是find_element,如果通过定位方式+定位值能定位到多个元素则默认返回第一个元素对象;二是find_elemens,返回多个元素的list,使用下标可以得到单一元素对象。
webDriver提供了以下八种元素定位的方法:

2.定位方法总结
1.id、name、class_name、tag_name:根据元素的标签或元素的属性进行定位
2.link_text、partial_link_text:根据超链接的文本来进行定位(a标签)
3.xpath:为元素路径定位
4.css:为css选择器定位(样式定位)
(1)id定位
说明:HTML规定id属性在整个HTML文档中必须是唯一的,id定位就是通过元素的id属性来定位元素。
前提:元素有id属性。
id定位方法:find_element_by_id()
案例:以百度的搜索框为例,定位在搜索框,点击右键,点击检查,可定位到搜索框元素。,如下图
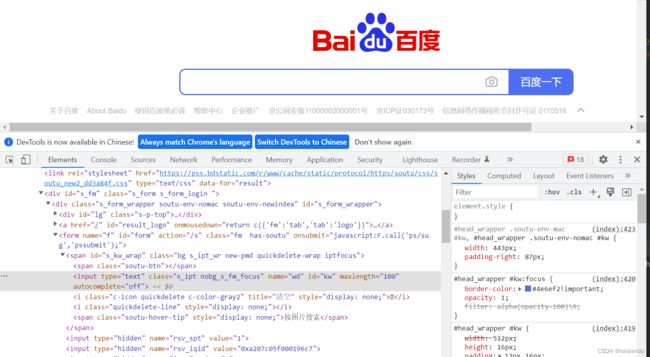
实现案例1:打开百度(http://www.baidu.com),通过id定位,输入搜索词:手机。
#selenium-version:4.4.3
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element(by="id", value="kw").send_keys("手机")
time.sleep(3)
driver.quit()
(2)name定位
说明:HTML规定name属性来指定元素的名称,name属性值在当前文档中可以不是唯一的,name定位就是根据name属性来定位。
前提:元素有name属性
name定位方法:find_element_by_name()
实现案例2:打开百度(http://www.baidu.com),通过name定位,输入搜索词:手机。
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element(by="name", value="wd").send_keys("手机")
time.sleep(3)
driver.quit()
(3)class_name定位
说明:HTML规定class属性来指定元素的类名,name属性值在当前文档中可以不是唯一的,class定位就是根据class属性来定位。用法和name、id类似。
前提:元素有class属性
name定位方法:find_element_by_class()
实现案例3:打开百度(http://www.baidu.com),通过class_name定位,输入搜索词:手机。
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("http://www.baidu.com")
driver.find_element(by="class name", value="s_ipt").send_keys("手机")
time.sleep(3)
driver.quit()
(4)tag_name定位
说明:HTML本质是由不同的tag(标签)组成,而每个tag都是指同一类,所以定位率低,一般不建议使用;tag_name定位就是使用标签名来定位。
前提:元素有tag_name属性
name定位方法:find_element_by_tag_name()
实现案例4:打开论坛界面,通过tag定位,输入用户名和密码
(5)link_text定位
说明:link_text定位于前面4个定位有所不同,它专门用来定位超链接文本(文本值/
前提:定位的元素是链接属性(a标签)
name定位方法:find_element_by_link_text()
实现案例5:打开百度界面,通过link_text定位。
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.find_element(by="link text", value="hao123").click()
time.sleep(3)
driver.quit()
(6)partial_link_text定位
说明:partial_link_text定位是link_text定位的补充,partial_link_text为模糊匹配,link_text是全部匹配。
前提:定位的元素是链接属性(a标签)
name定位方法:find_element_by_partial_link_text()
通过传入a标签的局部文本/全部文本来定位元素,要求输入的文本能够唯一的找到这个元素。
实现案例5:打开百度界面,通过partial_link_text定位。
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.find_element(by="partial link text",value="hao").click()
time.sleep(3)
driver.quit()
(7)元素组定位
元素组定位方式:find_element_by_xxx
作用:
1.查找返还定位所有符合条件的元素
2.返还的定位元素格式为列表格式
说明:
列表数据格式的读取需要指定下标(下标从0开始)
xpath定位和css定位:
为什么要学习?
1.在实际项目中没有id、class、name属性
2.id、class、name属性值为动态获取,随着刷新或加载而变化
xpath定位和css定位可以解决以上两类问题
(8)xpath定位
xpath定位概述:位置定位(路径方式)
1.xpath为xml path的简称,它是一种用来确定xml文档中某部分位置的语言。
2.HTML可以看作是XML的一种实现,所以selenium用户可以使用这种强大的语言在web项目中来定位元素。
3.xpath为强大的语言,因为它有非常灵活的定位策略。
定位方法:find_element_by_xpath()
xpath定位策略:
1.路径定位-绝对路径、相对路径
2.利用元素属性定位
3.层级与属性结合定位
4.属性和逻辑定位结合
案例:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
driver.find_element(by="xpath",value='//*[@id="kw"]').send_keys("手机")
time.sleep(3)
driver.quit()
(9)css定位
css概述:
1.css(Cascading Style Sheets)是一种语言,它用来描述HTML和XML的元素显示样式。
2.css语言中有css选择器,在selenium中可以使用这种选择器来进行元素定位。
3.css定位方法比xpath快,而且css语言也非常强大,所以非常推荐这种定位方法。
定位方法:find_element_by_css_selector()
css定位策略(方式):
1.id选择器
2.class选择器
3.元素选择器
4.属性选择器
5.层级选择器