【Python】基于某些列删除数据框中的重复值
Python按照某些列去重,可用drop_duplicates函数轻松处理。本文致力用简洁的语言介绍该函数。
文章目录
-
- 一、drop_duplicates函数介绍
- 二、加载数据
- 三、按照某一列去重
-
-
- 1. 按照某一列去重(参数为默认值)
- 2. 按照某一列去重(改变keep值)
- 3. 按照某一列去重(inplace=True)
-
- 四、按照多列去重
一、drop_duplicates函数介绍
drop_duplicates函数可以按某列去重,也可以按多列去重。具体语法如下:
DataFrame.drop_duplicates(subset=None,keep='first',inplace=False)
代码解析:
DataFrame:待去重的数据框。
subset:用来指定特定的列,根据指定的列对数据框去重。默认值为None,即DataFrame中一行元素全部相同时才去除。
keep:对重复值的处理方式,可选{‘first’, ‘last’, ‘False’}。默认值first,即保留重复数据第一条。若选last为保留重复数据的最后一条,若选False则删除全部重复数据。
inplace:是否在原数据集上操作。默认值False,即把原数据copy一份,在copy数据上删除重复值,并返回新数据框(原数据框不改变)。值为True时直接在原数据视图上删重,没有返回值。
二、加载数据
加载有重复值的数据,并展示数据。
# coding: utf-8
import os #导入设置路径的库
import pandas as pd #导入数据处理的库
import numpy as np #导入数据处理的库
os.chdir('F:/微信公众号/Python/26.基于多列组合删除数据框中的重复值') #把路径改为数据存放的路径
name = pd.read_csv('name.csv',sep=',',encoding='gb18030')
name
得到结果:
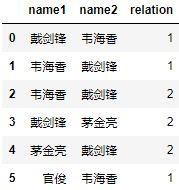
注:后文所有的数据操作都是在原始数据集name上进行。
三、按照某一列去重
1. 按照某一列去重(参数为默认值)
按照name1对数据框去重。
new_name_1 = name.drop_duplicates(subset='name1')
new_name_1
得到结果:
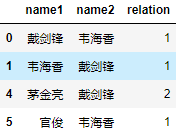
从结果知,参数为默认值时,是在原数据的copy上删除数据,保留重复数据第一条并返回新数据框。感兴趣的可以打印name数据框,删重操作不影响name的值。
2. 按照某一列去重(改变keep值)
2.1 实例一(keep=‘last’)
按照name1对数据框去重,并设置keep=‘last’。
new_name_1 = name.drop_duplicates(subset='name1',keep='last')
new_name_1
得到结果:
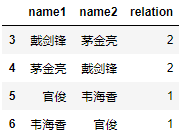
从结果知,参数keep=‘last’,是在原数据的copy上删除数据,保留重复数据最后一条并返回新数据框,不影响原始数据框name。
2.2 实例二(keep=False)
按照name1对数据框去重,并设置keep=False。
new_name_2 = name.drop_duplicates(subset='name1',keep=False)
new_name_2
得到结果:

从结果知,参数keep=False,是把原数据copy一份,在copy数据框中删除全部重复数据,并返回新数据框,不影响原始数据框name。
3. 按照某一列去重(inplace=True)
按照name1去重,并设置inplace=True。
new_name_3 = name.drop_duplicates(subset='name1',inplace=True)
new_name_3
结果中new_name_3的值为空,即设置inplace=True时没有返回结果,是在原始数据框name上直接进行操作。打印name可得结果:
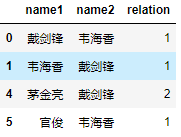
结果和按照某一列去重(参数为默认值)是一样的。如果想保留原始数据框直接用默认值即可,如果想直接在原始数据框删重可设置参数inplace=True。
四、按照多列去重
对多列去重和一列去重类似,只是原来根据一列是否重复删重。现在要根据指定的列判断是否存在重复(顺序也要一致才算重复)删重。接下来看一个实例:
new_name = name.drop_duplicates(subset=['name1','relation'])
new_name
得到结果:

原始数据中只有第二行和最后一行存在重复,默认保留第一条,故删除最后一条得到新数据框。想要根据更多列数去重,可以在subset中添加列。如果不写subset参数,默认值为None,即DataFrame中一行元素全部相同时才去除。
从上文可以发现,在Python中用drop_duplicates函数可以轻松地对数据框进行去重。但是对于两列中元素顺序相反的数据框去重,drop_duplicates函数无能为力。如需处理这种类型的数据去重问题,参见基于多列组合删除数据框中的重复值。
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python画好看的星空图(唯美的背景)
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)
