OC 面试题 集锦(每题都有代码证明)
一直觉得自己写的不是技术,而是情怀,一个个的教程是自己这一路走来的痕迹。靠专业技能的成功是最具可复制性的,希望我的这条路能让你们少走弯路,希望我能帮你们抹去知识的蒙尘,希望我能帮你们理清知识的脉络,希望未来技术之巅上有你们也有我。
面试的题目都是来自网上面来的,然后我看了之后理解了,然后把它写在这里,用来自己以后复习用的,又担心将来想找的时候就消失了。
0.开发中有没有遇到过很难解决的问题
iOS 需求 下载mp3歌曲网络卡顿(断点续传)
OC 需求 检测手机是否安装某个App,app是否安装(删除)appmusic
Swift 需求 音乐播放暂停淡出淡放(声音逐渐消失)(视频)(源码)
17.什么是runloop?
OC 面试题 Runloop
18.什么是runtime
我之前写过一篇关于runtime使用的文章:https://blog.csdn.net/weixin_38716347/article/details/122329979
runtime是C语言的一个底层的API。OC的代码运行过程最终经过runtime转化成C执行。
runtime的主要功能:
1.万能转换器(把字符串转换成类名)
2.方法的交换(交换push方法用于埋点)
3.为分类动态添加属性
4.动态添加方法
5.动态修改属性的值
6.自动字典转换模型
7.实现自动归档解档
5.ios 有哪些设计模式
ios 有哪些设计模式
1.单例模式
2.委托模式
3.观察者模式
4.工厂模式
5.命令模式
6.适配器模式
7.策略模式
8.原型/外观模式
9.组合模式
10.装饰模式
11.桥接模式
12.备忘录模式
13.生成器模式
21.KVC 底层实现原理
KVC 底层实现原理
6.iOS 数据存储的常用方式
比较普片的是沙盒存储:
一个可以存在Documents app使用用产生的图片数据,保存游戏关卡的数据。
有一个Library Cachaes 网络下载下来的图片
Preferences 是一个Plist文件用来存储app的常规设置 是否显示广告
Tmp文件 缓存文件 app重启 释放内存
还有Core Data
SQLite3
常用的YYCaches
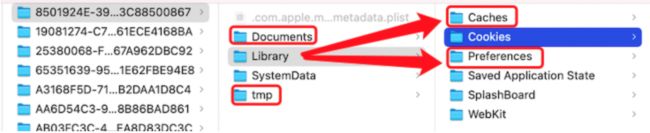
关于存储的方式 我也写过一篇文章:OC 技术 Sandbox 沙盒(本地存储) 归档解档
13.1Block循环引用的问题?
该链接有详细说明
14.UITableView性能优化与卡顿问题
UITableView性能优化与卡顿问题
1. 什么是响应链,它是怎么工作的?
这个问题的答案:ios开发—事件处理与如何获得最佳点击的View
响应链的意思就是:有多个响应对象串连起来的对象就是响应链。
工作原理:
用户点击屏幕产生的一个触摸事件,经过一系列的传递过程后,会找到一个最适合的视图来处理事件.找到最合适的视图控件后,就会调用控件的touches方法来作具体的时间处理.touches的默认做法是将事件顺着响应者链条向上传递,将事件交给上一个响应者处理
如何去寻找上一个响应者?
1.如果当前的View是控制器的View,那么控制器就是上一个响应者
2.如果当前的View不是控制器的View,那么他的父控件就是上一个响应者
3.在视图层次结构的最顶级视图,如果也不能处理收到的事件或消息,则其将事件或消息传递给window对象进行处理
4.如果window对象也不处理,则其将事件或消息传递给UIApplication对象
5.如果UIApplication也不能处理该事件或消息,则将其丢弃
系统是如何寻找最合适的View
1.先判断自己是否能接收触摸事件
2.再判断触摸的当前点在不在自己身上
3.如果在自己身上,它会从后往前遍历子控件,遍历出每一个控件后,重启前两步
4.如果没有符合条件的子控件,那么自身就是最合适的View
在寻找最合适View的过程中,系统会调用2个方法
//作用:寻找最适合的View
//什么时候调用:当事件传递给当前View时就会调用这个方法
-(UIView *)hitTest:(CGPoint)point withEvent:(UIEvent *)event{
UIView *fitView = [super hitTest:point withEvent:event];
NSLog(@"%@",fitView);
return fitView;
}
//作用:判断触摸点在不在当前的View上.
//什么时候调用:在hitTest方法当中会自动调用这个方法.
//注意:point必须得要跟当前View同一个坐标系.
-(BOOL)pointInside:(CGPoint)point withEvent:(UIEvent *)event{
return YES;
}
那么hitTest: withEvent:方法底层是如何实现的呢?
// 判断自己能否接收事件
if(self.userInteractionEnabled == NO || self.hidden == YES || self.alpha <= 0.01){
return nil;
}
// 触摸点在不在自己身上
if ([self pointInside:point withEvent:event] == NO) {
return nil;
}
// 从后往前遍历自己的子控件(重复前面的两个步骤)
int count = (int)self.subviews.count;
for (int i = count -1; i >= 0; i--) {
UIView *childV = self.subviews[i];
// point必须得要跟childV相同的坐标系.
// 把point转换childV坐标系上面的点
CGPoint childP = [self convertPoint:point toView:childV];
UIView *fitView = [childV hitTest:childP withEvent:event];
if (fitView) {
return fitView;
}
}
// 如果没有符合条件的子控件,那么就自己最适合处理
return self;
在开发中或多或少会需要一些特殊的点击,这里有2个小例子供大家参考
一个按钮被一个半透明的View部分遮挡,需要点击到按钮的时候,按钮始终响应
一个View超出了父视图的范围,需要点击超出范围的View也有响应
- (UIView *)hitTest:(CGPoint)point withEvent:(UIEvent *)event{
//当触摸点在按钮上的时候,才让按钮去响应事件.
//把当前点转换成按钮坐标系上的点.
CGPoint btnP = [self convertPoint:point toView:self.btn];
if ( [self.btn pointInside:btnP withEvent:event]) {
return self.btn;
}else{
return [super hitTest:point withEvent:event];
}
}
2.如何访问并修改一个类的私有属性?
有两种方法可以访问私有属性,一种是通过KVC获取,一种是通过runtime访问并修改私有属性
获取类的私有属性(KVO)源码
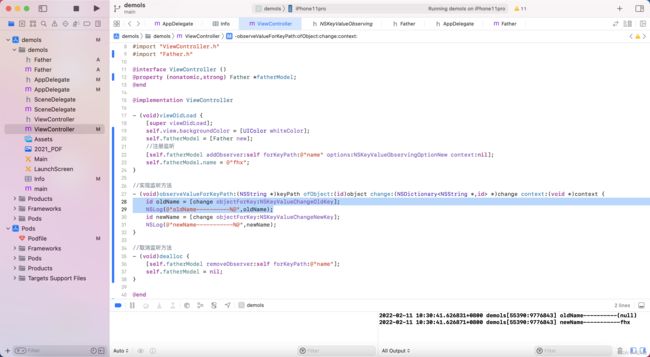
创建一个Father类,声明一个私有属性name,并重写description打印name的值,在另外一个类中通过runtime来获取并修改Father中的属性
获取类的私有属性(RunTime)源码
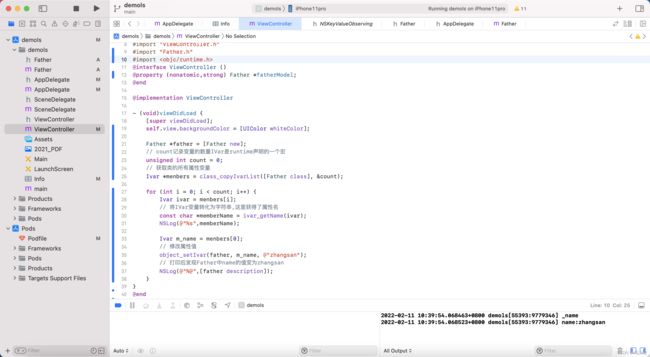
3.iOS Extension 是什么?能列举几个常用的 Extension 么?
Extension是扩展,没有分类名字,是一种特殊的分类,类扩展可以扩展属性,成员变量和方法
常用的扩展是在.m文件中声明私有属性和方法

4.如何把一个包含自定义对象的数组序列化到磁盘?
在类里面通过归档解档,实现NSCoding协议即可
(OC)归档解档(嵌套模型)(模型数组)源码
(OC)归档解档(单个模型)源码
- (void)viewDidLoad
{
[super viewDidLoad];
User *user = [User new];
Account *account = [Account new];
NSArray *userArray = @[user, account];
// 存到磁盘
NSData * tempArchive = [NSKeyedArchiver archivedDataWithRootObject: userArray];
}
// 代理方法
- (instancetype)initWithCoder:(NSCoder *)coder
{
self = [super initWithCoder:coder];
if (self) {
self.user = [aDecoder decodeObjectForKey:@"user"];
self.account = [aDecoder decodeObjectForKey:@"account"];
}
return self;
}
// 代理方法
-(void)encodeWithCoder:(NSCoder *)aCoder{
[aCoder encodeObject:self.user forKey:@"user"];
[aCoder encodeObject:self.account forKey:@"account"];
}
关于数据持久化跟归档解档我之前写过一篇文章:OC 技术 Sandbox 沙盒(本地存储) 归档解档
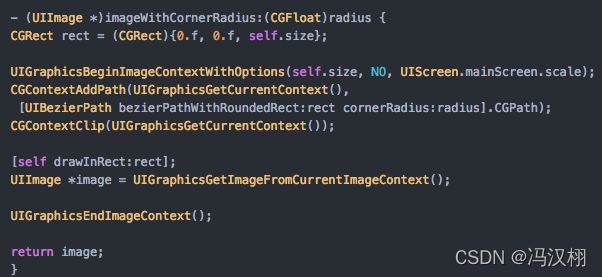
7.如何高效的裁切图片
其实就是防止离屏渲染产生的性能消耗
https://www.jianshu.com/p/d1954c9a4426
下面这个是重回这行图片
UIGraphicsBeginImage
8.如何知道当前的OC对象是否被使用
查看引用计数器是否为0
打印当前引用计数器的个数

手动想引用计数器加1
![]()
手动引用计数器减1
![]()
在Person类里面重写dealloc方法去检测person是否被回收

如果想要知道引用计数器的值。可以向OC对象发送一条retainCount消息。
9.创建属性的时候为什么要用@property
如果不使用@property创建出来的属性生成不了set get 方法
@property的括号里面还紧跟好几个属性的设置,下面说明一下:
1、readwrite:是可读可写特性,需要生成getter方法和setter方法。
2、readonly:是只读特性,只会生成getter方法,不会生成setter方法,不希望属性在类外改变。
3、retain表示持有特性,setter方法将传入参数先保留,再赋值,传入参数的引用计数retaincount会+1.
4、nonatomic非原子性操作,决定编译器生成的setter、getter方法是否加锁。
atomit表示多线程安全,一般使用nonatomic。
5、assign是赋值特性,setter方法将传入参赛赋值给实例变量,仅设置变量时,assign用于简单数据类型,如NSInteger,double,bool。非OC对象。
6、weak弱引用,在ARC中,在有可能出现循环引用的时候,往往要通过让其中一端使用weak来解决。比如:delegate代理属性。OC对象
weak与assign的不同?
weak此特质表明该属性定义了一种“非拥有关系”为这种属性设置新值时,设置方法既不保留新值,也不释放旧值。此特质同assign类似,然而在属性所指的对象遭到摧毁时,属性值也会清空。而assign的“设置方法”只会执行针对“纯量类型”(CGFlot或NSInteger等)的简单赋值操作。
7、strong强引用
8、copy表示赋值特性,setter方法将传入参数对象赋值一份,需要完全一份新的变量时。
copy修饰NSMutableArray时:@property (nonatomic, copy) NSMutableArray *arr;
[XXXXXX copy];生成的对象都是不可变的;
[XXXXXX mutableCopy];生成的对象是可变的;
NSMutableArray *arr = [NSMutableArray array];
arr = [arr copy]; arr是不可变的
9、_block/_weak修饰符区别:
_block在ARC和MRC环境下都能用,可以修饰对象,也能修饰基本数据类型
_weak只能在ARC环境下使用,只能修饰对象(NSString),不能修饰基本数据类型(int)
_block对象可以在block中重新赋值,_weak不行。
10、NSString的时候用copy和strong的区别:
OC中NSString为不可变字符串的时候,用copy和strong都是只分配一次内存,但是如果用copy的时候,需要先判断字符串是否是不可变字符串,如果是不可变字符串,就不再分配空间,如果是可变字符串才分配空间。如果程序中用到NSString的地方特别多,每一次都要先进行判断就会耗费性能,影响用户体验,用strong就不会再进行判断,所以,不可变字符串可以直接用strong。
顺便解释:深赋值、浅赋值
深赋值:内容赋值,会产生新对象,新对象引用指数+1
浅赋值:指针赋值,不会产生新对象,原对象的引用指数+1
注意:不可变对象用copy修饰时是浅赋值,剩下其他都是深复制。
因为使用的是copy,所得到的实际上是NSArray类型,它是不可变的,若在使用中使用了增、删、改操作,则会crash。
10.创建属性的时候为什么有一些属性要带*有一些属性不需要

看创建出来的属性是否是一个OC对象。
11.OC能多继承么?
虽然Objective-C在语法上禁止类使用多继承,但是在协议的遵守上却允许使用多继承。所以可以用协议来实现多继承。
12.OC分类跟扩展的区别
1.声明方法的时候分类的共有,扩展是私有
2.分类可以实现方法,扩展只有声明没有实现
3.分类不能声明属性,扩展能声明属性
一、分类
当你已经封装好了一个类,不想在改动这个类了,可是随着程序功能的增加需要在类中增加一个方法,
二、扩展
1、适用范围
扩展是分类的一种特殊形式。
2、语法格式
@interface 主类类名()
@end
4、分类和扩展的区别
分类是不可以声明实例变量,通常是公开的,文件名是:主类名+分类名.h
扩展是可以声明实例变量,是私有的,文件名为:主类名_扩展标识.h,在主类的.m文件中#import该头文件
三、协议(只声明没有实现)
1、适用范围
协议用来制定一个规则,一个对象遵守某个协议,就相当于必须遵守它的规则(实现必须实现的方法),也就拥有了一种能力。通常适用协议来实现委托代理模式的传值和消息发送。
13.为什么block要使用copy而不是strong或者其他属性修饰?
block本身是像对象一样可以retain,和release。但是,block在创建的时候,它的内存是分配在栈上的,而不是在堆上。他本身的作于域是属于创建时候的作用域,一旦在创建时候的作用域外面调用block将导致程序崩溃。因为栈区的特点就是创建的对象随时可能被销毁,一旦被销毁后续再次调用空对象就可能会造成程序崩溃,在对block进行copy后,block存放在堆区.
使用retain也可以,但是block的retain行为默认是用copy的行为实现的,
因为block变量默认是声明为栈变量的,为了能够在block的声明域外使用,所以要把block拷贝(copy)到堆,所以说为了block属性声明和实际的操作一致,最好声明为copy。
附带:如何在block内部修改外部变量
__block int a = 0; void (^foo)(void) = ^{ a = 1; }; foo(); //这里,a的值被修改为1
15.IOS的反射机制 RunTime10大用法当中的一种(万能控制器.推送返回Json跳转到指定控制器)
iOS 万能跳转界面方法 (runtime实用篇一)
IOS的反射机制
// 假设从服务器获取JSON串,通过这个JSON串获取需要创建的类为ViewController,并且调用这个类的getDataList方法。
Class class = NSClassFromString(@"ViewController”);
ViewController *vc = [[class alloc] init];
SEL selector = NSSelectorFromString(@"getDataList”);
[vc performSelector:selector];
16.说一下你对static的理解
1.static可以修饰局部变量。修饰局部变量的属性离开方法的作用域之后,属性的值不会清0,它的作用域变成是在整个控制器里面
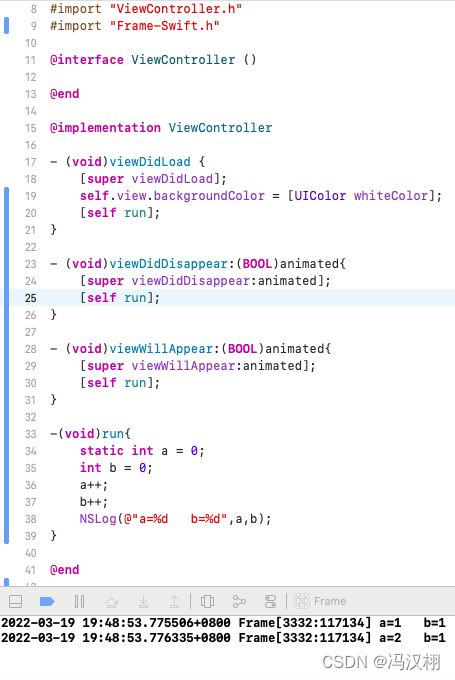
2.用static修饰的属性,这个属性只给当前类的对象访问。其他类的对象是访问不来的。
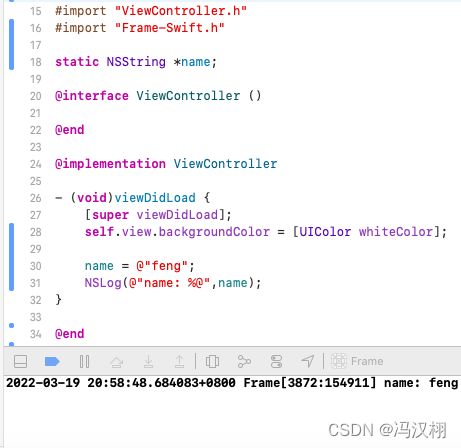
19.说一下你对setter getter方法的理解?
1.重点:Setter Getter 方法
setter getter方法的诞生
1.setter getter的出现是为了对属性的赋值进行过滤出现的
2.类的外面不能直接访问类的属性,但是可以自己写一个方法间接对类的属性进行设置和获取。但是设置和获取的方法创建有规范的,就是我们的setter getter方法。
例如age的属性
setter -(void)setAge:(int)age;
getter -(int)age;
其实setter getter 随便你怎么写都是可以的,记得你写的方法,能调用,通过方法传递的参数,进行成员变量赋值就可以了,写了setter getter方法赋值之后。我们以后在view或者controller,可以通过self点出属性。
我们为什么要规范setter getter。因为我们通常使用属性的时候,都是self点出属性赋值的,就必须先写setter getter方法。其实如果创建一个属性的时候,就必须要实现setter getter 才能用,没用人用成员变量赋值的。所以如果人人都有自己不一样创建的setter getter方法的话这样看起来会很乱。所以苹果就把setter getter方法规范好了上面的两种方法。在后面学的时候会用@Proprey来创建属性,就自动实现setter getter方法,不用我们去实现。除非你对属性的值有别的特殊要求进行实现。
20.ios 若你去设计一个通知中心,你会怎样设计?
A控制器
注册通知
实现通知方法
移除通知
B控制器
创建通知
发送通知
1.1 KVC 常用的方法
(1)赋值类方法 - (void)setValue:(nullable id)value forKey:(NSString *)key;
- (void)setValue:(nullable id)value forKeyPath:(NSString *)keyPath;
- (void)setValue:(nullable id)value forUndefinedKey:(NSString *)key;
- (void)setValuesForKeysWithDictionary:(NSDictionary
*)keyedValues;
(2)取值类方法 // 能取得私有成员变量的值
- (id)valueForKey:(NSString *)key;
- (id)valueForKeyPath:(NSString *)keyPath;
- (NSDictionary *)dictionaryWithValuesForKeys:(NSArray *)keys;
21.KVO
(1)KVO 是基于 runtime 机制实现的
(2)当一个对象(假设是person对象,对应的类为 JLperson)的属性值age发生改变时,系统会自动生成一个继承自JLperson的类NSKVONotifying_JLPerson,
在这个类的 setAge 方法里面调用
[super setAge:age];
[self willChangeValueForKey:@"age”];
[self didChangeValueForKey:@"age”]
三个方法,而后面两个方法内部会主动调用
-(void)observeValueForKeyPath:(NSString *)keyPath ofObject:(id)object change:(NSDictionary
KVO使用
注册监听
实现监听方法 observeValueForKeyPath
移除监听
22.扩大按钮(UIButton)点击范围(随意方向扩展哦)
重写按键的方法:- (BOOL)pointInside:(CGPoint)point withEvent:(UIEvent*)event{}
23.iOS 开发中为什么更新UI都要放在主线程中?
1、在子线程中是不能进行UI 更新的,而可以更新的结果只是一个幻像:因为子线程代码执行完毕了,又自动进入到了主线程,执行了子线程中的UI更新的函数栈,这中间的时间非常的短,就让大家误以为分线程可以更新UI。如果子线程一直在运行,则子线程中的UI更新的函数栈 主线程无法获知,即无法更新
2、只有极少数的UI能,因为开辟线程时会获取当前环境,如点击某个按钮,这个按钮响应的方法是开辟一个子线程,在子线程中对该按钮进行UI 更新是能及时的,如换标题,换背景图,但这没有任何意义
24.在oc里面是否有垃圾回收机制?
在手机是没有垃圾回收机制的。但是在mac的1.1上面是有的,那么手机上面主要是有ARC
和MRC,ARC是iOS 5推出的新功能,全称叫 ARC(Automatic Reference Counting)。简单地说,就是代码中自动加入了retain/release,原先需要手动添加的用来处理内存管理的引用计数的代码可以自动地由编译器完成了。MRC就是在程序中手动添加引用计数器。手动释放。
25.CALayer和UIView的关系?(偏门)
一个UIView包含CALayer,CALayer是一个数据模型,它里面有很多能够显示的出来的数据,但是他自己本身并不能显示,它想显示自己的数据必须考UIView来帮它进行显示。
26.你知道同步支付结果跟异步支付结果有什么区别吗?
同步支付结果是用于发送给我们的客户端,仅仅是用来展示的,异步支付结果是发给我们的服务器存到数据库中。
27.@property属性关键字的使用(assign/weak/strong/copy)
一、assign
用于 ‘基本数据类型’、‘枚举’、‘结构体’ 等非OC对象类型
eg:int、bool等
二、 weak
- 一般应用: UI控件
- 详细说明:
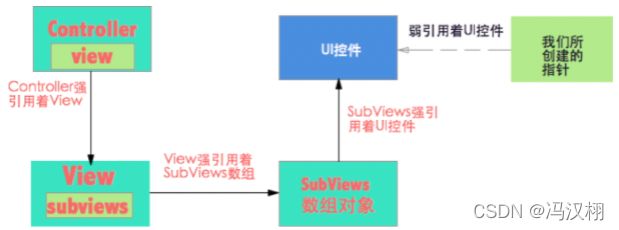
(1)为什么建议UI控件一般使用weak?首先我们从controller来看,controller是被系统用强指针引用着,所以如果 controller 还存在,里面的子控件也会存在,那么controller 强引用着它的view(从 controller 中它的 view 的属性是 retain 看出来的,retain 就是 MRC 年代的强引用),那么 view 又强引用着它的数组对象subviews,数组对象又引用着它所包含的数组内容,所以当我们创建出来一个UI控件并将其加入到subviews的时候,它就会被一个强指针所引用着,我们可以简化一下这个过程:–> Controller --> View --> Subviews(数组) --> 数组内容(添加到其中的UI控件)
(2)清楚了过程之后,我们来看我们所创建的对象,如果我们所创建的是一个临时变量的话,那么当出去作用域之后对象就被销毁,但是这里请注意,这里分为两个内存空间,一个是对象的内存空间,一个是指针的内存空间,如果创建的是临时变量的话,一旦出了作用域那么我们的指针内存是被清空了,但是我们的内容如果加到了subviews中,就会被subviews强引用,那么我们的控件就还会存在,只不过是一个指向它的指针被清空了而已。
(3)回过头我们说说全局变量,全局变量的话,指针会一直存在,这里面谈谈为什么要用weak,其实只要我们创建的控件加入到subviews中去的话,那么这个控件就会一直存在,所以在这里我们所创建的指针是weak或strong其实只不过是多一个实线虚线的问题,也就是控件已经被强引用了,你再给它添加一个强引用或者弱引用在使用上都不会有什么问题,但是问题来了,如果我们remove了这个控件,我们subViews中的那根线被切断,也就是这个代表我不再需要这个控件了,那么这个时候如果再用一个strong来连接它,那么对象就不会被清除,既然我们都不需要它了,为什么我还强引用它?这也就是为什么我们再这里用弱引用的原因。`简言之,就是内存使用上的合理性,当这个控件我们需要的时候其实已经有一个强引用在引用着它,我们没有必要再弄一根指针来强引用着它,当我们不需要它的时候,如果是weak的话自然而然直接释放掉了,如果strong的话还会保留它,既然我们没用了我们为什么还要留着它而占用我们宝贵的内存呢?我们也可以看一下这张图片用来理解:
(4)这里特殊说一下IBOutlet中的拖线创建,我们可以发现,如果用storyboard或者xib进行的脱线创建,苹果都会自动降属性置为weak,这种做法似乎也符合我们之前的说法,但是苹果又会在之前加了一个IBOutlet这个关键词,那么这个词是什么意思呢?我们看一下苹果的官网解释: The symbol IBOutlet is used only by Xcode, to determine when a property is an outlet; it has no actual value. 意思很清楚了,它仅仅是指定了一个属性是一个 外部设置的,并没有实质的含义,通常与外界连接是通过当前的 viewcontroller 。那么在引用上又有什么不同呢?在官方文档中是这么说的,在我们创建了IBOutlet之后,我们系统会有一个自动对它进行一个强引用,也就是又多了一条实线连接着它,当控件从我们的subviews中移除之后,这条线会自动判断去留,也就是不会对我们的内存的性能造成影响,该在的时候我在,该消失的时候自己就会消失了。这里也用一张图来说明:
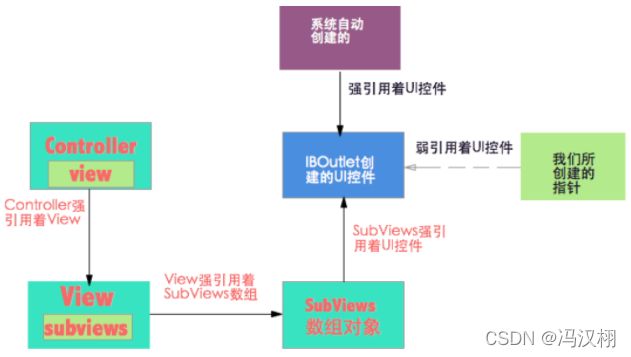
在我写demo的时候有一点需要注意,就是当我们将控件从subViews中remove调之后,这个时候打印指针还存在,说明指针并不会马上销毁,而是进行下一轮消息循环之后才会发现这个指针被销毁了.
- 总结:
我们首先是从内存的利用上,我们建议对UI控件采用weak,其次是观察苹果的声明方式,依然是建议使用weak,因为标准都是参考于苹果,而且合理性也摆在那里,为什么不用呢?
三、 strong
OC对象类型(NSArray、NSDate、NSNumber、模型类)
一个对象只要有强指针引用着,就不会被销毁
四、 copy
-
一般用在NSString*类型、block类型上
-
copy语法的作用:产生副本。 且copy返回的是不可变的副本,mutableCopy返回的是可变的副本。
-
修改了副本并不会影响源对象,修改了源对象,并不会影响副本。
-
copy在属性声明中的使用,直接举例说明
@interface ViewController ()//注意这里虽然是copy的属性,但是我们这个指针还是强引用的
@property(nonatomic,copy)NSString*name;
@end
@implementation Viewcontroller
-(void)viewDidLoad
{
[self viewDidLoad];
NSMutableString*str = [NSMutableString stringWithFormat:@"aaa"];
self.name = str;
[str appendString:@"bbb"];
NSLog(@"str= %@",str);
NSLog(@"name = %@",self.name);
NSLog(@"%p,%p",str, self.name);
}
@end
我们来看一下说出的结果:
str = aaabbb
name = aaa
输出的内存地址:0x7f90f3028180 , 0x7f90f3027450
这说明了这个copy的含义就是,我们在给name属性赋值的时候,,系统默认先将str执行一次copy方法,然后再将结果赋给我们的属性,只有这样你再之后对str修改之后,name的值还是不变的,说明两个指针其实指向的是不同的内容,之后我们又打印了我们的指针值,得出不同的结果又证明了上述所说。
-
注意:并不是所有情况下我们的string都必须使用copy,因为如果我们的需求是希望string是随着我的改变而改变的,那么这个时候应该使用strong。
-
类的copy:
如果我们想实现类的copy,必须实现一个方法:-(id)copyWithZome:(NSZone*)zone; 这是为什么呢?我们去 NSString 中去寻找答案,那么我们会发现其实 NSString 已经遵守了 NSCopying 与 NSMutableCopying 的协议,我们主要看 NSCopying ,进入这个协议之后你会发现 -(id)copyWithZome:(NSZone*)zone 这个方法,也就是说NSString 已经遵守了协议的这个方法,所以才能直接实现 copy 的方法。所以如果想实现自定义类的 copy 方法,我们是需要先遵守 NSCopying 协议,然后实现-(id)copyWithZome:(NSZone*)zone的方法:
-(id)copyWithZone:(NSZone *)zone{
Mitchell*copyMit = [[Mitchell allocWithZone:zone] init];
copyMit.name = self.name;return copyMit;
}
zone:系统返回给我们 copy 对象的内存空间
注意:必须在初始化方法中给属性赋值,才能让 copy 出的对象和原来的对象有相同的属性。
- 再说一下 copy 类中的 set 方法,如果属性是 copy 的,那么系统默认只会在 set 方法中调用 copy 的方法:
-(void)setName:(Mitchell*)name{
_name = [name copy];
}
strong / weak / unsafe_unretained 的区别?
weak只能修饰OC对象,使用weak不会使计数器加1,对象销毁时修饰的对象会指向nil
strong等价与retain,能使计数器加1,且不能用来修饰数据类型
unsafe_unretained等价与assign,可以用来修饰数据类型和OC对象,但是不会使计数器加1,且对象销毁时也不会将对象指向nil,容易造成野指针错误
网络
1.串行和并发
在执行任务时,串行是任务顺序执行,执行完一个下一个。并发就是任务可能同时执行多个任务。在GCD中一个任务就是一个闭包,这比NSOperation中的任务更加容易理解。
2.串行队列的优点
能确保对一个共享资源进行串行化的访问,避免了数据竞争;任务的执行顺序是可预知的,你向一个串行队列提交任务时,它们被执行的顺 序与它们被提交的顺序相同;
3.并发队列的优点
并发队列可以让你并行的执行多个任务。任务按照它们被加入到队列中的顺序依次开始,但是它们都是并发的被执行,并不需要彼此等待才开始。并发队列能保证任务按同一顺序开始,但你不能知道执行的顺序、执行的时间以及在某一时刻正在被执行任务的数量
4.同步和异步
在计算机领域,同步就是指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才继续执行下去;异步是指进程不需要一直等下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样可以提高执行的效率。
临界区

多线程想访问公共资源的一段代码,那么公共资源只能够有一个线程去访问它的资源,如果线程A正在访问公共资源,B视图也想进去访问,那么线程B就会被挂起一致等待,等到线程A进入临界区的线程,临界区释放后,B线程才能够进入公共资源进行访问。
线程安全
线程安全的代码是多线程或者并发任务的安全调度,程序不会出现任何问题(例如:崩溃和数据损坏),例如我们let一个数组,因为这个数组是只读,多线程同时去访问它的时候不会对数组中的数据产生影响,但是Var一个数组中的时候,数组中的数据不但是能够读取,而且还能够修改,如果多线程去访问并且修改数据的时候就会出现问题。
死锁
简单来说就是A线程在等待B线程完成后执行,B线程也在等待A线程完成后执行,这样就出现了死锁的现象。
5.上下文切换
上下文切换是存储和恢复执行的状态,是你在一个进程中执行不同的线程之间切换的过程。这个过程是编写多任务处理应用程序时很常见,但也带来了一些额外的开销成本。就像并发就是通过切换上下文来实现的。
6.什么是SEL
它是一个方法选择器,在NSThread作为线程的入口,在代理传值的时候填写方法的时候就是写在它里面@selector(方法)
7.什么是进程
1.进程是指在程序中正在运行的程序(就像相当于正在运行的QQ,微信)
2.每一个进程之间是独立的
8.什么是线程
1.进程必须在线程上面执行,一个线程至少有一个进程
2.进程是线程的基本单位
9.线程间是如何通讯的?
就例如:在子线程里面下载一张图片,下载完成后回到主线程里面刷新UI。
例如GCD吧,当点击按钮下载一张图片的时候,在函数里面开启异步线程下载图片 dispatch_async下面写下载图片的函数,下载完成之后用 dispatch_sync,线程框填写 dispatch_get_main_queue回到主线程里面,block函数写刷新UI。(如何刷新UI?赋值图片self.image=image)
10.多线程是什么?
多线程是为了解决耗时操作的。
实现方案一共有三种:pthread,NSThread,GCD,NSOperation(面试不要讲pthread)
11.什么是异步线程,同步线程,区别
同步线程是不会开启线程的,而且按顺序执行(在主线程里面执行)
异步线程是会开启线程的,而且会不按顺序执行(在异步线程里面执行)
12.什么是NSThread
每一个NSThread对象对应一个线程,量级较轻,NSThread有3个使用方法
alloc/initWithTarget
detachNewThreadSelector
performSelectorInBackGround(继承NSOblect,就是任何一个对象都能够调用这个方法开启线程)
13.NSThrad的优点跟缺点
•NSThread:–优点:NSThread 比其他两个轻量级,使用简单–缺点:需要自己管理线程的生命周期、线程同步、加锁、睡眠以及唤醒等。
14.什么是GCD。
GCD是纯C语言的API,它所有的任务通过一个Block没有参数,没有返回值的函数完成的。
它可以用在同步或者异步线程里面。所有GCD的函数都是dispatch_函数开头如果开启异步线程的话就async,如果在同步就sync。
GCD有一个好处,当开启异步线程去执行Block里面的代码的时候,它对线程有一个回收操作的,当任务完成之后他会收回当前的线程,如果在1分钟之内又有新的任务的时候,他就会使用原来的线程,不会去重复创建,相当于TableViewCell的重用机制一样,当任务完成1分钟之后,没有任务,线程被释放,1分钟后有任务来就会创建出一个新的子线程。这样就能够节省线程空间,提高程序的运行速度
网上的好处
1.GCD用纯C编写,可以提高应用程序的响应能力,更加高效;
2.GCD使用简单,会自动利用更多的CPU内核(比如双核、四核),自动管理线程的生命周期(创建线程、调度任务、销毁线程),程序员只需要告诉GCD想要执行什么任务,不需要编写任何线程管理代码,提供更容易并发模型,有助于避免并发错误。
GCD总结:
1.GCD会开启线程
2.同步不会开启线程。代码会在当前线程执行。
15.GCD与NSThread的区别
- GCD所有的任务都是通过block来完成,所有的代码都存在一起,比较直观
- NSThread 都是通过选择器(SEL)指定线程的入口方法
- GCD 开启线程,只需要使用异步就可以
- 在回到主线程上,GCD直接通过主队列就可以。NSThread 回到主线程,只能通过NSObject的分类方法
16.NSOperationQueue跟GCD的区别
1> GCD是纯C语言的API,NSOperationQueue是基于GCD的OC版本封装
2> GCD只支持FIFO的队列,NSOperationQueue可以很方便地调整执行顺 序、设置最大并发数量
3> NSOperationQueue可以在轻松在Operation间设置依赖关系,而GCD 需要写很多的代码才能实现
4> NSOperationQueue支持KVO,可以监测operation是否正在执行 (isExecuted)、是否结束(isFinished),是否取消(isCanceld)
5> GCD的执行速度比NSOperationQueue快 任务之间不太互相依赖:GCD 任务之间有依赖\或者要监听任务的执行情况:NSOperationQueue
17.NSOperationQueue跟GCD如何选择。
如果在一个复杂的多线程开发的时候使用NSOperationQueue如果项目开发获取网络数据不算复杂的话就使用简洁的GCD。
18.什么是 TCP 连接的三次握手
第一次握手是客户端发送一个syn包给服务器,然后等到服务器确认,当服务器收到客户端的syn包之后,第二次握手,服务器会发送回一个syn+ck包给客户端,等待客户端确认,第三次握手是客户端想服务器发送确认包ack包给服务器,在这个过程中不涉及数据的传递,三次握手完毕之后,客户端跟服务器开始传送数据,理想情况下,如果TCP一旦建立任何一方没有主动断开连接,连接将保持下去。
19.简单说一下你会HTTP的理解
HTTP是超文本传输协议,它是网络上面的一种请求-应答式的协议——客户端发送一个请求,服务器返回该请求的应答,所有的请求与应答都是HTTP包。HTTP协议使用可靠的TCP连接,默认端口是80。
HTTP下一只要分为3部分:
消息报头,请求行,请求正文。
有3个特点:
1.支出客户服务器模式
2.简单快速
3.灵活
4.无连接(限制每次连接只处理一次请求)
5.无状态
20.什么是UDP协议
UDP是一种用户数据包协议。
特点:只管发动,不会确保对方时候能够收到
不需要建立连接,所以数据的可靠性不强,容易丢失数据。
传输数据量小,64K以内
传输速度快
使用场景:视频的实时共享,直播,网络游戏。
21.TCP跟UDP有什么区别?
TCP是面向连接,是产生连接的,可靠,拥塞控制,效率低
UDP不面向连接,不产生连接,不可靠,没有拥塞控制,效率高
内存管理
1.栈跟堆有什么区别?
比较好理解的答案:
内存的栈区 : 由编译器自动分配释放, 存放函数的参数值, 局部变量的值等. 其操作方式类似于数据结构中的栈.
内存的堆区 : 一般由程序员分配释放, 若程序员不释放, 程序结束时可能由OS回收. 注意它与数据结构中的堆是两回事, 分配方式倒是类似于链表.
管理:
栈是自动管理的,无需手动控制。
堆是需要人工释放,通常很容易产生内存泄露。
分配空间:
栈是向低地址扩展的数据结构
堆是向高地址扩展的数据结构
栈的分配空间比堆要小
碎片问题:
栈是先进后出,堆是先进先出。
效率:
栈是压栈,出栈都是系统指令管理的,效率比堆要高。
2.通知,代理,block,KVO的使用场景分别是什么,有什么区别?
- 通知: 适用于毫无关联的页面之间或者系统消息的传递,属于一对多的信息传递关系。例如系统音量的改变,系统状态的改变,应用模式的设置和改变,都比较适合用通知去传递信息。
- 代理: 一对一的信息传递方式,适用于相互关联的页面之间的信息传递,例如push和present出来的页面和原页面之间的信息传递。
- block: 一对一的信息传递方式,效率会比代理要高(毕竟是直接取IMP指针的操作方式)。适用的场景和代理差不多,都是相互关联页面之间的页面传值。
- KVO: 属性监听,监听对象的某一属性值的变化状况,当需要监听对象属性改变的时候使用。例如在UIScrollView中,监听contentOffset,既可以用KVO,也可以用代理。但是其他一些情况,比如说UIWebView的加载进度,AVPlayer的播放进度,就只能用KVO来监听了,否则获取不到对应的属性值
1.+load 和 +initialize 的区别是什么?
+load 和 +initialize 的区别是什么?举例说明。
1.两个方法都只会调用一次
2.程序启动肯定会调用load方法,无论是否有创建实例,而且在main之前调用。
3.initialize是在创建实例才会调用。
+load
先调用类的+load,后调用分类的+load
先调用父类+load,后调用子类的+load
按照编译顺序调用+load(先编译先调用)
+initialize
先初始化分类,后初始化子类
先调用父类,后调用子类
2.深拷贝与浅拷贝的区别
浅拷贝是指针赋值
深拷贝是内容赋值,新的指针,新的内存,把值赋值过来
关于拷贝的这个问题,很多人多多少少都听过或者知道的,但是在项目开发过程中真正用到在哪里,很多人我想一时半刻很难马上想出来,下面就在我开发中用到深拷贝的地方。
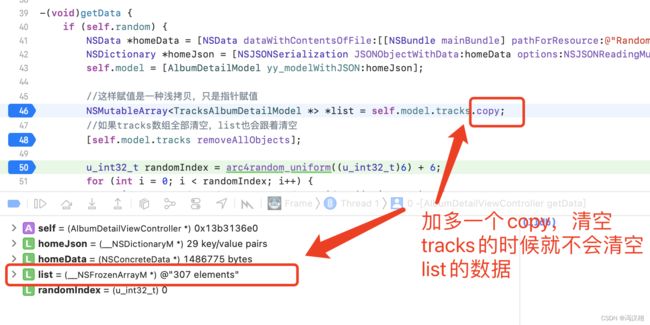
下面的例子只能用深拷贝,不能用浅拷贝,不然无法实现,我想把拿回来来的数据self.model.tracks先给一个临时变量list,所以就想下面这样写
![]()
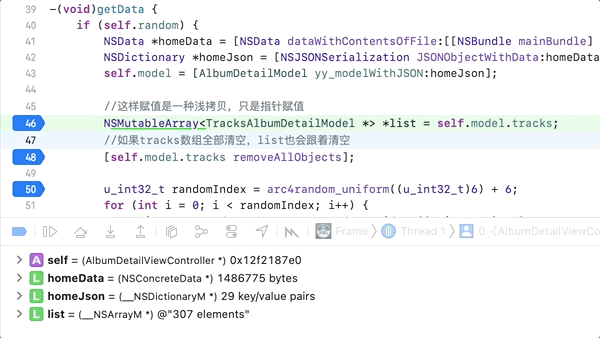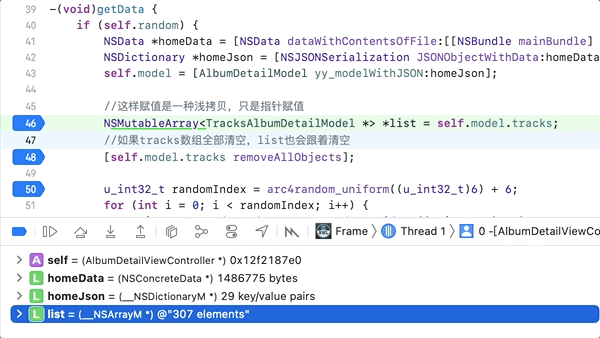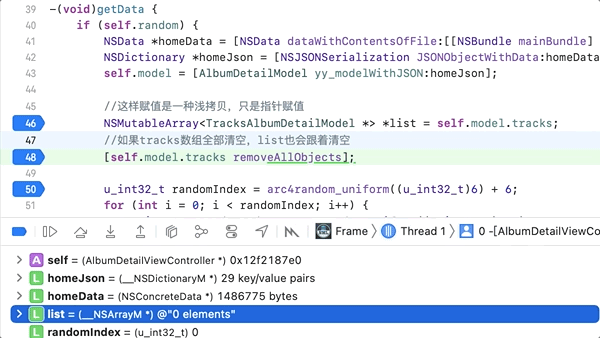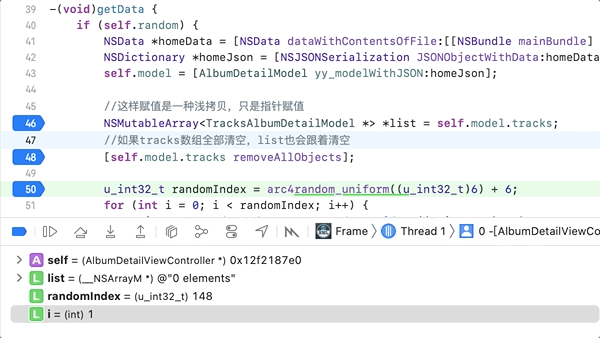
然后把self.model.tracks数组清空,
![]()
结果打印出来的list也是全部清空的。也可以看下面gif图的效果。获取回来数组是307个的,结果连list也清空了。
修改办法很简单。