大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——InputFormat数据输入
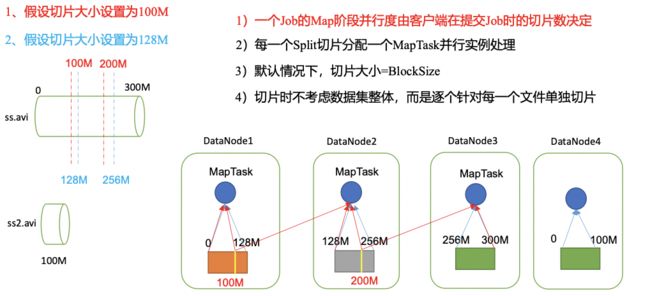
3.1.1切片与MapTask并行度决定机制
1、问题引出
MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个Job的处理速度。
思考:1G的数据,启动8个MapTask,可以提高集群的并发处理能力。那么1K的数据,也启动8个MapTask,会提高集群性能吗?MapTask并行任务是否越多越好呢?哪些因素影响了MapTask并行度?
2、MapTask并行度决定机制
**数据块:**Block是HDFS物理上把数据分成一块一块。
**数据切片:**数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。
3.1.2Job提交流程源码和切片源码详解
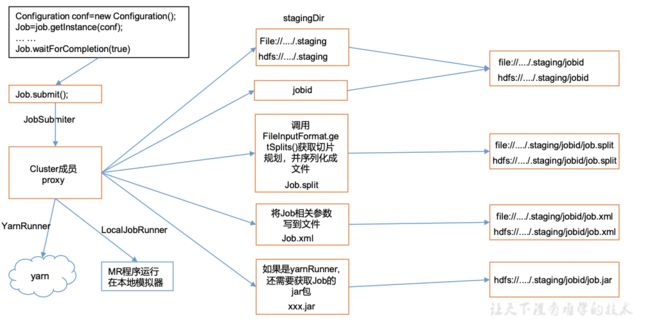
1、Job提交流程源码详解
waitForCompletion()
submit();
// 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地yarn还是远程
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());
2、Job提交流程源码解析
wordcount:断点打在Driver集群提交的代码
boolean result = job.waitForCompletion(true);
DEBUG:step into
3.1.3FileInputFormat切片机制
1、切片机制
(1)简单地按照文件的内容长度进行切片
(2)切片大小,默认等于Block大小
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片
2、案例分析
(1)输入数据有两个文件:
file1.txt 320M
file2.txt 10M
(2)经过FileInputFormat的切片机制运算后,形成的切片信息如下:
file1.txt.split1-- 0~128
file1.txt.split2-- 128~256
file1.txt.split3-- 256~320
file2.txt.split1-- 0~10
FileInputFormat切片大小的参数配置
(1)源码中计算切片大小的公式
Math.max(minSize, Math.min(maxSize, blockSize));
mapreduce.input.fileinputformat.split.minsize=1 默认值为1
mapreduce.input.fileinputformat.split.maxsize=Long.MAXValue 默认值Long.MAXValue
因此,默认情况下,切片大小=blocksize。
(2)切片大小设置
maxsize(切片最大值):参数如果调的比blockSize小,则会让切片变小,而且就等于配置的这个参数值。
minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blockSize还大。
(3)获取切片信息API
// 获取切片的文件名称
String name = inputSplit.getPath().getName();
// 根据文件类型获取切片信息
FileSplit inputSplit = (FileSplit) context.getInputSplit();
3.1.4CombineTextInputFormat切片机制
框架默认的TextInputFormat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个MapTask,这样如果有大量小文件,就会产生大量的MapTask,处理效率极其低下。
1、应用场景:
CombineTextInputFormat用于小文件过多的场景,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个MapTask处理。
2、虚拟存储切片最大值设置
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);// 4m
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
3、切片机制
生成切片过程包括:虚拟存储过程和切片过程二部分。

(1)虚拟存储过程:
将输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
例如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分成一个4M。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
(2)切片过程:
(a)判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。
(b)如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
(c)测试举例:有4个小文件大小分别为1.7M、5.1M、3.4M以及6.8M这四个小文件,则虚拟存储之后形成6个文件块,大小分别为:
1.7M,(2.55M、2.55M),3.4M以及(3.4M、3.4M)
最终会形成3个切片,大小分别为:
(1.7+2.55)M,(2.55+3.4)M,(3.4+3.4)M
3.1.5CombineTextInputFormat案例实操
1、需求
将输入的大量小文件合并成一个切片统一处理。
(1)输入数据
准备4个小文件
(2)期望
期望一个切片处理4个文件
2、实现过程
(1)不做任何处理,运行1.6节的WordCount案例程序,观察切片个数为4。
(2)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为3。
(a)驱动类中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置4m
CombineTextInputFormat.setMaxInputSplitSize(job, 4194304);
(b)运行如果为3个切片。
![]()
(3)在WordcountDriver中增加如下代码,运行程序,并观察运行的切片个数为1。
(a)驱动中添加代码如下:
// 如果不设置InputFormat,它默认用的是TextInputFormat.class
job.setInputFormatClass(CombineTextInputFormat.class);
//虚拟存储切片最大值设置20m
CombineTextInputFormat.setMaxInputSplitSize(job, 20971520);
(b)运行如果为1个切片。
![]()
3.1.6FileInputFormat实现类
思考:**在运行MapReduce程序时,输入文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。**那么,针对不同的数据类型, MapReduce是如何读取这些数据的呢?
FileInputFormat常见的接口实现类包括:TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等
1、TextInputFormat
TextInputFormat是默认的FileInputFormat实现类。按行读取每条记录。键是存储该行在整个文件中的起始字节偏移量,LongWritable类型。值是这行的内容,不包括任何终止符(换行符和回车符),Text类型。
以下是一个示例。比如,一个分片包含了如下4条文本记录。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
每条记录表示以下键/值对:
(0,Rich learning form)
(19,Intelligent learning engine)
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
2、KeyValueTextInputFormat
每一行均为一条记录,被分隔符分割为key,value。可以通过在驱动类中设置**conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, “\t”);**来设定分隔符。默认分隔符是tab(\t)。
以下是一个示例,输入时一个包含4条记录的分片。其中—>表示一个(水平方向的)制表符。
line1—>Rich learning form
line2—>Intelligent learning engine
line3—>Learning more convenient
line4—>From the real demand for more close to the enterprise
每条记录表示为以下键/值对:
(line1,Rich learning form)
(line2,Intelligent learning engine)
(line3,Learning more convenient)
(line4,From the real demand for more close to the enterprise)
此时的键是每行排在制表符之前的Text序列。
3、NLineInputFormat
如果使用NLineInputFormat,代表每个map进程处理的**InputSplit不再按Block块去划分,而是按NLineInputFormat指定的行数N来划分。**即输入文件的总行数/N=切片书,如果不整除,切片数=商+1。
以下是一个示例,仍然以上面的4行输入为例。
Rich learning form
Intelligent learning engine
Learning more convenient
From the real demand for more close to the enterprise
例如,如果N是2,则每个输入分片包含两行。开启2个MapTask。
(0,Rich learning form)
(19,Intelligent learning engine)
另一个mapper则受到后两行:
(47,Learning more convenient)
(72,From the real demand for more close to the enterprise)
这里的键和值和TextInputFormat生成的一样。
3.1.7KeyValueTextInputFormat使用案例
1、需求
统计输入文件中每一行的第一个单词相同的行数。
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
(2)期望结果数据
banzhang 2
xihuan 2
2、需求分析

3、代码实现
(1)编写Mapper类
package com.cuiyf41.kvtext;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class KVTextMapper extends Mapper<Text, Text, Text, LongWritable> {
// 1 设置value
LongWritable v = new LongWritable(1);
@Override
protected void map(Text key, Text value, Mapper<Text, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// 2 写出
context.write(key, v);
}
}
(2)编写Reducer类
package com.cuiyf41.kvtext;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class KVTextReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0;
// 1 汇总统计
for(LongWritable value:values){
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
}
(3)编写Driver类
package com.cuiyf41.kvtext;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueLineRecordReader;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class KVTextDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/kvtext.txt", "e:/output1" };
Configuration conf = new Configuration();
// 设置切割符
conf.set(KeyValueLineRecordReader.KEY_VALUE_SEPERATOR, " ");
// 1 获取job对象
Job job = Job.getInstance(conf);
// 2 设置jar包位置,关联mapper和reducer
job.setJarByClass(KVTextDriver.class);
job.setMapperClass(KVTextMapper.class);
job.setReducerClass(KVTextReducer.class);
// 3 设置map输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4 设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5 设置输入输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
// 设置输入格式
job.setInputFormatClass(KeyValueTextInputFormat.class);
// 6 设置输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
job.waitForCompletion(true);
}
}
3.1.8NLineInputFormat使用案例
1、需求
对每个单词进行个数统计,要求根据每个输入文件的行数来规定输出多少个切片。此案例要求每三行放入一个切片中。
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
(2)期望输出数据
Number of splits:4
2、需求分析

3、代码实现
(1)编写Mapper类
package com.cuiyf41.nline;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class NLineMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private Text k= new Text();
private LongWritable v = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] splited = line.split(" ");
// 3 循环写出
for(int i = 0; i < splited.length; i++){
k.set(splited[i]);
context.write(k, v);
}
}
}
(2)编写Reducer类
package com.cuiyf41.nline;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class NLineReducer extends Reducer<Text, LongWritable,Text, LongWritable> {
LongWritable v = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException {
long sum = 0;
// 1 汇总
for(LongWritable value:values){
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
}
(3)编写Driver类
package com.cuiyf41.nline;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.NLineInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class NLineDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/nline.txt", "e:/output1" };
// 1 获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 7设置每个切片InputSplit中划分三条记录
NLineInputFormat.setNumLinesPerSplit(job, 3);
// 8使用NLineInputFormat处理记录数
job.setInputFormatClass(NLineInputFormat.class);
// 2设置jar包位置,关联mapper和reducer
job.setJarByClass(NLineDriver.class);
job.setMapperClass(NLineMapper.class);
job.setReducerClass(NLineReducer.class);
// 3设置map输出kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 4设置最终输出kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 5设置输入输出数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 6提交job
job.waitForCompletion(true);
}
}
4、测试
(1)输入数据
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang
banzhang ni hao
xihuan hadoop banzhang banzhang ni hao
xihuan hadoop banzhang
(2)输出结果的切片数,如图4-10所示:
![]()
3.1.9自定义InputFormat
在企业开发中,Hadoop框架自带的InputFormat类型不能满足所有应用场景,需要自定义InputFormat来解决实际问题。
自定义InputFormat步骤如下:
(1)自定义一个类继承FileInputFormat。
(2)改写RecordReader,实现一次读取一个完整文件封装为KV。
(3)在输出时使用SequenceFileOutPutFormat输出合并文件。
3.1.10自定义InputFormat案例实操
无论HDFS还是MapReduce,在处理小文件时效率都非常低,但又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义InputFormat实现小文件的合并。
1、需求
将多个小文件合并成一个SequenceFile文件(SequenceFile文件是Hadoop用来存储二进制形式的key-value对的文件格式),SequenceFile里面存储着多个文件,存储的形式为文件路径+名称为key,文件内容为value。
(1)输入数据
one.txt
yongpeng weidong weinan
sanfeng luozong xiaoming
two.txt
longlong fanfan
mazong kailun yuhang yixin
longlong fanfan
mazong kailun yuhang yixin
three.txt
shuaige changmo zhenqiang
dongli lingu xuanxuan
(2)期望输出文件格式
2、需求分析
1)自定义一个类继承FileInputFormat
- 重写isSplitable()方法,返回false不可分割
- 重写createRecordReader(),创建自定义的RecordReader对象,并初始化
2)改写Recor,实现一次读取一个完整文件封装为KV
- 采用IO流一次读取一个文件输出到value中,因为设置了不可切片,最终把所有文件都封装到了value中
- 获取文件路径信息+名称,并设置key
3)设置Driver
// 设置输入的inputFormat
job.setInputFormatClass(WholeFileInputformat.class);
// 设置输出的outputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
3、程序实现
(1)自定义InputFromat
package com.cuiyf41.inputfile;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
// 定义类继承FileInputFormat
public class WholeFileInputformat extends FileInputFormat<Text, BytesWritable>{
@Override
protected boolean isSplitable(JobContext context, Path filename) {
return false;
}
@Override
public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
WholeRecordReader recordReader = new WholeRecordReader();
recordReader.initialize(split, context);
return recordReader;
}
}
(2)自定义RecordReader类
package com.cuiyf41.inputfile;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class WholeRecordReader extends RecordReader<Text, BytesWritable>{
private Configuration configuration;
private FileSplit split;
private boolean isProgress= true;
private BytesWritable value = new BytesWritable();
private Text k = new Text();
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException {
this.split = (FileSplit)split;
configuration = context.getConfiguration();
}
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (isProgress) {
// 1 定义缓存区
byte[] contents = new byte[(int)split.getLength()];
FileSystem fs = null;
FSDataInputStream fis = null;
try {
// 2 获取文件系统
Path path = split.getPath();
fs = path.getFileSystem(configuration);
// 3 读取数据
fis = fs.open(path);
// 4 读取文件内容
IOUtils.readFully(fis, contents, 0, contents.length);
// 5 输出文件内容
value.set(contents, 0, contents.length);
// 6 获取文件路径及名称
String name = split.getPath().toString();
// 7 设置输出的key值
k.set(name);
} catch (Exception e) {
}finally {
IOUtils.closeStream(fis);
}
isProgress = false;
return true;
}
return false;
}
@Override
public Text getCurrentKey() throws IOException, InterruptedException {
return k;
}
@Override
public BytesWritable getCurrentValue() throws IOException, InterruptedException {
return value;
}
@Override
public float getProgress() throws IOException, InterruptedException {
return 0;
}
@Override
public void close() throws IOException {
}
}
(3)编写SequenceFileMapper类处理流程
package com.cuiyf41.inputfile;
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class SequenceFileMapper extends Mapper<Text, BytesWritable, Text, BytesWritable>{
@Override
protected void map(Text key, BytesWritable value, Mapper<Text, BytesWritable, Text, BytesWritable>.Context context) throws IOException, InterruptedException {
context.write(key, value);
}
}
(4)编写SequenceFileReducer类处理流程
package com.cuiyf41.inputfile;
import java.io.IOException;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class SequenceFileReducer extends Reducer<Text, BytesWritable, Text, BytesWritable> {
@Override
protected void reduce(Text key, Iterable<BytesWritable> values, Reducer<Text, BytesWritable, Text, BytesWritable>.Context context) throws IOException, InterruptedException {
context.write(key, values.iterator().next());
}
}
(5)编写SequenceFileDriver类处理流程
package com.cuiyf41.inputfile;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.BytesWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.SequenceFileOutputFormat;
public class SequenceFileDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 输入输出路径需要根据自己电脑上实际的输入输出路径设置
args = new String[] { "e:/input/format", "e:/output" };
// 1 获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包存储位置、关联自定义的mapper和reducer
job.setJarByClass(SequenceFileDriver.class);
job.setMapperClass(SequenceFileMapper.class);
job.setReducerClass(SequenceFileReducer.class);
// 7设置输入的inputFormat
job.setInputFormatClass(WholeFileInputformat.class);
// 8设置输出的outputFormat
job.setOutputFormatClass(SequenceFileOutputFormat.class);
// 3 设置map输出端的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(BytesWritable.class);
// 4 设置最终输出端的kv类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(BytesWritable.class);
// 5 设置输入输出路径
Path input = new Path(args[0]);
Path output = new Path(args[1]);
// 如果输出路径存在,则进行删除
FileSystem fs = FileSystem.get(conf);
if (fs.exists(output)) {
fs.delete(output,true);
}
FileInputFormat.setInputPaths(job, input);
FileOutputFormat.setOutputPath(job, output);
// 6 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}