Elasticsearch个人学习笔记
文章目录
-
- Elasticsearch (7.x) 学习
-
- 1、Index(索引)
- 2、Mapping(映射)
- 3、Document(文档)
- 4、索引的基本操作
-
- 4.1 创建索引
- 4.2 查询索引
- 4.3 删除索引
- 5、文档的基本操作
-
- 5.1 创建文档
- 5.2 查询文档
- 5.3 修改文档
- 5.4 删除文档
- 5.5 文档批量操作
- 5、ES中的高级查询
-
- 5.1 查询所有文档数据(match_all)
- 5.2 查询文档数据,并指定返回字段(_source)
- 5.3 关键词查询(term)
- 5.4 范围查询(range)
- 5.5 前缀查询(prefix)
- 5.6 通配符查询(wildcard)
- 5.7 多id查询(ids)
- 5.8 模糊查询(fuzzy)
- 5.9 布尔查询(bool)
- 5.10 多字段查询(multi_match)
- 5.11 默认字段分词查询(query_string)
- 5.12 高亮查询(highlight)
- 5.13 返回指定条数(size)
- 5.14 指定返回起始位置(from)
- 5.15 指定字段排序(sort)
- 6、ES倒排索引原理
- 7、ES中的过滤查询
-
- 7.1 使用语法
- 7.2 term过滤器
- 7.3 terms过滤器
- 7.4 range过滤器
- 7.5 exists过滤器
- 7.6 ids过滤器
- 8、ES中的分词器
-
- 8.1 简介
- 8.2 ES中内置的分词器
- 8.3 ES中内置分词器测试
- 8.4 创建索引时,指定字段使用的分词器
- 8.5 总结
- 8.6 ES中的中文分词器
-
- 8.6.1 IK分词器下载与安装
- 8.6.2 IK分词器使用
- 8.6.3 扩展词和停用词的配置
- 9、ES中的聚合查询
-
- 9.1 简介
- 9.2 根据字段分组,并统计个数
- 9.3 求最大值
- 9.4 求最小值
- 9.5 求平均值
- 9.6 求和
- 10、SpringBoot整合ES
-
- 10.1 整合准备
- 10.2 API测试:
- 11、ES集群
-
- 11.1 搭建ES集群步骤:
- 11.2 下载google插件
- 11.3 Kibana连接ES集群启动时的一些坑:
- 12、ES中的数据类型
-
- 12.1 nested 类型理解
Elasticsearch (7.x) 学习
es7.x版本,移除了type类型,需要jdk11支持
1、Index(索引)
索引类似于mysql中的表(空表,没有字段)
一个索引就是一个拥有几分相似特征文档的集合。一个索引由一个名称来标识(这个名称必须是小写字母)
2、Mapping(映射)
映射类似于mysql中的表结构(即表中的字段名称及字段类型)
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。
映射有:1、自动创建 2、手动创建 两种方式
3、Document(文档)
文档类似于mysql中的一条记录(即表中的一行记录)
文档是索引中一条条数据,一条文档是可被索引的最小单元。文档采用json格式数据表示。
4、索引的基本操作
4.1 创建索引
- 创建索引
// 1.创建索引语法
PUT /索引名称 ===> PUT /article
// 索引健康状态:red(索引不可用)、yellow(索引可用,存在风险)、green(健康)
// 默认创建的索引指定分片和副本都为1,这时索引的健康状态为yellow,主要是分片和副本放在同一台机器上,所以给出警告
// 2.创建索引指定分片和副本信息
PUT /article
{
"settings": {
"number_of_shards": 1, //指定分片数为1
"number_of_replicas": 0 // 指定副本数为0
}
}
- 创建索引并指定映射
// 创建article索引,指定映射(id、title、author、create_time、content、is_publish)
// es中的数据类型:
字符串类型:keyword、text
数字类型:integer、long
小数类型:float、double
布尔类型:boolean
日期类型:date
// 例子:
PUT /article
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": { // properties固定写法
"id":{ // id
"type": "integer"
},
"title":{ // 标题
"type": "keyword"
},
"author":{ // 作者
"type": "keyword"
},
"create_time":{ // 创建时间
"type": "date"
},
"content":{ // 文章内容
"type": "text"
},
"is_publish":{ // 是否公开
"type": "boolean"
}
}
}
}
4.2 查询索引
- 查询单个索引
// 语法: GET /_cat/indices/索引名称
GET /_cat/indices/article
// 如果在后面指定?v 可以显示状态信息的含义
GET /_cat/indices/article?v
- 查询所有索引
GET /_cat/indices
- 查看索引的映射信息
GET /article/_mapping
4.3 删除索引
- 删除单个索引
// 语法: DELETE /索引名称
DELETE /article
- 删除所有索引
DELETE /*
5、文档的基本操作
5.1 创建文档
- 创建单个文档
// 1.创建文档指定id, 语法:POST /索引名称/_doc/指定id {json格式数据}
// 指定的id和json数据中的id保持一致
POST /article/_doc/1
{
"id":"1",
"title":"深入理解Java虚拟机",
"author":"周志明",
"create_time":"2011-06-27",
"content":"《深入理解Java虚拟机:JVM高级特性与最佳实践》内容简介:作为一位Java程序员,你是否也曾经想深入理解Java虚拟机,但是却被它的复杂和深奥拒之门外?没关系,本书极尽化繁为简之妙,能带领你在轻松中领略Java虚拟机的奥秘。本书是近年来国内出版的唯一一本与Java虚拟机相关的专著,也是唯一一本同时从核心理论和实际运用这两个角度去探讨Java虚拟机的著作,不仅理论分析得透彻,而且书中包含的典型案例和最佳实践也极具现实指导意义。全书共分为五大部分。第一部分从宏观的角度介绍了整个Java技术体系的过去、现在和未来,以及如何独立地编译一个OpenJDK7,这对理解后面的内容很有帮助。第二部分讲解了JVM的自动内存管理,包括虚拟机内存区域的划分原理以及各种内存溢出异常产生的原因;常见的垃圾收集算法以及垃圾收集器的特点和工作原理;常见的虚拟机的监控与调试工具的原理和使用方法。第三部分分析了虚拟机的执行子系统,包括Class的文件结构以及如何存储和访问Class中的数据;虚拟机的类创建机制以及类加载器的工作原理和它对虚拟机的意义;虚拟机字节码的执行引擎以及它在实行代码时涉及的内存结构。第四部分讲解了程序的编译与代码的优化,阐述了泛型、自动装箱拆箱、条件编译等语法糖的原理;讲解了虚拟机的热点探测方法、HotSpot的即时编译器、编译触发条件,以及如何从虚拟机外部观察和分析JIT编译的数据和结果。第五部分探讨了Java实现高效并发的原理,包括JVM内存模型的结构和操作;原子性、可见性和有序性在Java内存模型中的体现;先行发生原则的规则和使用;线程在Java语言中的实现原理;虚拟机实现高效并发所做的一系列锁优化措施。",
"is_publish": "true"
}
// 2.创建文档不指定id,有es自动生成,此时json数据中无需指定id值,
// 语法:POST /索引名称/_doc/ {json格式数据}
POST /article/_doc
{
"title":"Java并发编程的艺术",
"author":"程晓明",
"create_time":"2015-06-27",
"content":"《Java并发编程的艺术》正是为了解决这个问题而写的。书中采用循序渐进的讲解方式,从并发编程的底层实现机制入手,逐步介绍了在设计Java并发程序时各种重要的技术、设计模式与应用,同时辅以丰富的示例代码,使得开发人员能够更快地领悟Java并发编程的要领,围绕着Java平台的基础并发功能快速地构建大规模的并发应用程序。",
"is_publish": "true"
}
- 批量创建文档
// 语法:
POST /索引名称/_doc/_bulk
{"index":{"_id":"3"}}
{"title":"王者荣耀","author":"二哈","create_time":"2015-06-27","content":"hahah。","is_publish": "true"}
注意:{index} 与 json数据换行,并且开头一个空格,并且json数据不能格式化,只能紧凑连接在一起
// 例子:指定id创建文档,也可以不指定
POST /article/_doc/_bulk
{"index":{"_id":"3"}}
{"title":"王者荣耀","author":"二哈","create_time":"2015-06-27","content":"hahah。","is_publish": "true"}
{"index":{"_id":"4"}}
{"title":"王者荣耀22","author":"二哈2","create_time":"2015-06-27","content":"hahah。","is_publish": "true"}
5.2 查询文档
- 查询单个文档
// 语法:GET /索引名称/_doc/指定id
GET /article/_doc/1
GET /article/_doc/VjP2mIEB6nx-kiDdJe_X
- 查询所有文档
// 语法:GET /索引名称/_search
GET /article/_search
5.3 修改文档
- 修改单个文档(全量修改)
// 语法:
PUT /索引名称/_doc/指定id
{
"字段名称":"要修改的字段值" //要修改的字段名称
}
// 例如:
PUT /article/_doc/2
{
"title":"lhb个人自传"
}
注意:这种方式会把其他没有更新的字段删除掉,即删除之后再新增
所以需要更新某个字段但又不删除原来的字段,需要把原来字段带上
//更新title为lhb个人自传,则
PUT /article/_doc/2
{
"title":"lhb个人自传",
"author":"lhb",
"create_time":"2015-06-27",
"content":"个人自传,很精彩!",
"is_publish": "true"
}
- 修改单个文档(仅修改文档中某几个字段)
// 语法:
POST /所用名称/_doc/指定id/_update
{
"doc":{
"字段名称":"要修改的字段的值"
}
}
// 例如:
POST /article/_doc/2/_update
{
"doc":{
"title":"lin个人自传"
}
}
// 更新如果字段不存在会新增
- 批量修改文档(仅修改文档中某几个字段)
// 更新文档中标题为指定的值
POST /article/_doc/_bulk
{"update":{"_id":"3"}}
{"doc":{"title":"李白"}}
{"update":{"_id":"4"}}
{"doc":{"title":"韩信"}}
5.4 删除文档
- 删除单个文档
//语法:DELETE /索引名称/_doc/指定id
DELETE /article/_doc/2
- 批量删除文档
DELETE /索引名称/_doc/*
- 批量删除文档
POST /article/_doc/_bulk
{"delete":{"_id":"3"}}
{"delete":{"_id":"4"}}
5.5 文档批量操作
文档的批量操作可以混合在一起使用(即可以同时进行增、删、改),并且每个操作都是独立的,不会因为一个失败而全部失败,而是继续执行后续的操作,在返回结果时,按顺序返回执行的状态结果。
5、ES中的高级查询
5.1 查询所有文档数据(match_all)
match_all 关键字查询所有
// 语法:GET /索引名称/_doc/_search {json格式的搜索条件数据}
GET /article/_doc/_search
{
"query":{
"match_all":{}
}
}
// 上述方式在kibnana中没有语法提示,可以简化写法,去除_doc,这样就有语法提示了。
// 语法:GET /索引名称/_search {json格式的搜索条件数据}
GET /article/_search
{
"query":{
"match_all":{}
}
}
5.2 查询文档数据,并指定返回字段(_source)
_source 关键字 只展示指定的字段
// 语法:_source 关键字指定展示的字段
GET /索引名称/_doc/_search
{
"query":{
"match_all":{}
},
"_source":["id","title"]
}
// 例如:检索所有文档,并只展示id和title两个字段
GET /article/_doc/_search
{
"query":{
"match_all":{}
},
"_source":["id","title"]
}
5.3 关键词查询(term)
term 关键字,用来使用
关键词查询在es中,除了text类型,其他的类型都是不分词的,所以都是按整体来查询的;
在es中,没有设置分词器,默认采用的是标准分词器,标准分词器对于text类型的中文数据默认是按单个字进行分词的。对于英文数据是单词进行分词。
所以使用term进行关键词中文查询时,并且采用标准分词器,且想要查询出数据,只能单个字,单个字进行搜索。
// 语法:
GET /索引名称/_search
{
"query": {
"term": {
"字段名称": {
"value": "字段名称的值,这个值是按词的方式进行检索的"
}
}
}
}
// 例如:查询article索引中title="个人自传"的文档
GET /article/_search
{
"query": {
"term": {
"title": {
"value": "个人自传"
}
}
}
}
5.4 范围查询(range)
range 关键字,用来指定查询字段指定范围的文档
// 语法:
GET /索引名称/_search
{
"query": {
"range": {
"字段名称": {
"gte": 1,
"lte": 10
}
}
}
}
// 例如:查询article索引中id字段中(1<=id<=10)范围的文档
GET /article/_search
{
"query": {
"range": {
"id": {
"gte": 1,
"lte": 10
}
}
}
}
5.5 前缀查询(prefix)
prefix 关键字,用来检索含有指定前缀的
关键词的相关文档,只能搜索关键词
// 语法:
GET /索引名称/_search
{
"query": {
"prefix": {
"字段名称": {
"value": "要搜索的关键词,注意text类型的中文数据的标准分词器是单个字分词"
}
}
}
}
// 例如:查询article索引中title字段的前缀为"个"的文档
GET /article/_search
{
"query": {
"prefix": {
"title": {
"value": "个"
}
}
}
}
5.6 通配符查询(wildcard)
wildcard 关键字,通配符查询 ? 用来匹配一个任意字符 * 用来匹配多个任意字符
此查询方式也是只能查询
关键字
// 语法:
GET /索引名称/_search
{
"query": {
"wildcard": {
"字段名称": {
"value": "需要搜索的关键词,与?或*组合而成的"
}
}
}
}
// 例如: 查询索引article中content字段的内容满足 "*深*" 的文档
GET /article/_search
{
"query": {
"wildcard": {
"content": {
"value": "*深*"
}
}
}
}
5.7 多id查询(ids)
ids 关键字,值为数组类型,用来根据一组id获取多个对应的文档
// 语法:
GET /索引名称/_search
{
"query": {
"ids": {
"values": ["id1","id2","id3"]
}
}
}
// 例如:查询索引article中ids为:["1","2","VjP2mIEB6nx-kiDdJe_X"]的文档
GET /article/_search
{
"query": {
"ids": {
"values": ["1","2","VjP2mIEB6nx-kiDdJe_X"]
}
}
}
5.8 模糊查询(fuzzy)
fuzzy 关键字,用来模糊查询含有指定
关键字的文档当输入关键字进行搜索时,fuzzy会尝试进行纠错,再更我们的某个字段进行模糊查询,
默认会纠错2次,每次纠错是纠错一个关键词,注意是词。
对
关键词进行模糊搜索。可以使用fuzziness设置纠错次数。
输入的关键字与关键词匹配,将返回对应的文档。
// 语法:
GET /索引名称/_search
{
"query": {
"fuzzy": {
"字段名称": "关键字,有一定的匹配规则"
}
}
}
// 注意:fuzzy 模糊查询 最大模糊错误 默认必须在0-2之间
1.搜索关键词长度为2,不允许存在模糊
2.搜索关键词长度3-5之间,允许一次模糊
3.搜索关键词长度大于5,允许最大2次模糊
允许几次模糊的含义,可以理解为允许出错几个词
//例如: 根据关键字"人自传",模糊查询索引article中的文档
GET /article/_search
{
"query": {
"fuzzy": {
"title": "人自传"
}
}
}
//解释:文档中title原来的值为"个人自传",长度为4,符合上述2的情况,允许一次模糊匹配关键词,由于输入的关键字为"人自传",进行一次模糊"?人自传",满足关键词"个人自传",所以会返回对应的文档。
// 如果输入",没人自传",也能搜索到,模糊一次,相当于纠错一个汉字。
5.9 布尔查询(bool)
bool 关键字,用来组合多个条件实现复杂查询
must:相当于&&同时成立
should:相当于||成一个就行
must_not:相当于!不能满足任何一个
// 例子:查询article索引中(id=1&&author="周志明")的文档
GET /article/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"id": {
"value": "1"
}
}
},{
"term": {
"author": {
"value": "周志明"
}
}
}
]
}
}
}
// 例子:查询article索引中(id=1||author="程晓明")的文档
GET /article/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"id": {
"value": "1"
}
}
},{
"term": {
"author": {
"value": "程晓明"
}
}
}
]
}
}
}
// 例子:查询article索引中(id!=1 && author!="程晓明")的文档
GET /article/_search
{
"query": {
"bool": {
"must_not": [
{
"term": {
"id": {
"value": "1"
}
}
},{
"term": {
"author": {
"value": "程晓明"
}
}
}
]
}
}
}
5.10 多字段查询(multi_match)
根据字段类型进行查询:
1、非text类型,不分词,将查询条件作为整体进行查询
2、text类型,分词,将查询条件分词之后进行查询
// 查询article索引中title、content字段包含Java的文档
GET /article/_search
{
"query": {
"multi_match": {
"query": "Java", //搜索条件
"fields": ["title","content"] // 哪些字段进行搜索
}
}
}
5.11 默认字段分词查询(query_string)
查询规则:
1、非text类型,不分词,将查询整体进行查询
2、text类型,分词,将查询条件分词之后进行查询
// 查询article索引中title值为"个人自传"的文档
GET /article/_search
{
"query": {
"query_string": {
"default_field": "title", // 默认查询字段
"query": "个人自传" // 查询条件
}
}
}
5.12 高亮查询(highlight)
highlight 关键字,可以将符合条件的文档中的关键词高亮
// 查询article索引中title="个人字段",并对"个人自传"关键词进行高亮
GET /article/_search
{
"query": {
"term": {
"title": {
"value": "个人自传"
}
}
},
"highlight": {
"fields": {
"*":{} //对查询条件搜索到的所有关键词进行高亮
}
}
}
// 高亮的查询结果会单独展示出来,不会对原文档进行修改,所以高亮完之后需要替换原文档的内容
自定义HTML标签进行高亮
GET /article/_search
{
"query": {
"term": {
"content": {
"value": "个"
}
}
},
"highlight": {
"pre_tags": [""], //自定义html标签前缀
"post_tags": [""], // 自定义html标签后缀
"fields": {
"*":{
}
}
}
}
对所有字段进行高亮,不仅仅是指定的查询字段,但是前提是按词进行高亮
GET /article/_search
{
"query": {
"term": {
"content": {
"value": "个"
}
}
},
"highlight": {
"pre_tags": [""],
"post_tags": [""],
"require_field_match": "false", // 是否只开启查询字段高亮,false:就是全部
"fields": {
"*":{
}
}
}
}
// 比如:对content中的个进行查询,查询到了进行高亮,而此时在title中也有个,并且个是一个词,那么title中的个也会被高亮
5.13 返回指定条数(size)
size 关键字,指定查询结果中返回指定条数,默认返回值10条。
GET /article/_search
{
"query": {
"match_all": {}
},
"size": 2 //返回2条
}
5.14 指定返回起始位置(from)
from 关键字,用来指定起始返回位置,和size关键字连用可实现分页效果。
GET /article/_search
{
"query": {
"match_all": {}
},
"from": 1, //起始位置从1开始
"size": 2 //返回2条记录
}
5.15 指定字段排序(sort)
GET /article/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"id": { //根据id降序
"order": "desc"
}
}
]
}
6、ES倒排索引原理
在ES中通过value去找key的方式,就是倒排索引,在ES中,会将数据放在元数据区,然后value中的关键词放在索引区,查询关键词时通过关键词找id的方式,就是倒排索引。
基础数据:
| id | title | author | content |
|---|---|---|---|
| 1 | 深入理解Java虚拟机 | 小明 | 学习虚拟机 |
| 2 | Java并发编程艺术 | 小红 | 学习并发编程 |
| 3 | 高性能MySQL | 小兰 | 学习数据库 |
在ES中存储的数据结构:
| 索引区 | 元数据区 |
|---|---|
| 深入理解Java虚拟机:1 小明:1 学:[1,2,3] 习:[1,2,3] 虚:1 拟:1 机:1 Java并发编程艺术:1 小红:1 并:1 发:1 编:1 程:1 高性能MySQL:1 小兰:1 数:1 据:1 库:1 |
| 1 | 深入理解Java虚拟机 | 小明 | 学习虚拟机 | |
| 与上面合并 | | 2 | Java并发编程艺术 | 小红 | 学习并发编程 | |
| 与上面合并 | | 3 | 高性能MySQL | 小兰 | 学习数据库 | |
当搜索到上述索引区中的关键词时,会查询到相对应的文档id,即找到对应的文档数据。
7、ES中的过滤查询

7.1 使用语法
GET /索引名称/_search
{
"query":{
"bool":{
"must":[
{"match_all":{}} // 查询条件
],
"filter":{...} //过滤条件
}
}
}
注意:
- 在执行filter和query时,先执行filter再执行query
- Elasticsearch会自动缓存经常使用的过滤器的文档,以加快性能
类型:
常见过滤器类型:term、terms、range、exists、ids等filter
7.2 term过滤器
term关键字,进行单个关键词过滤
// 过滤content中关键词含“个”的文档,并对过滤后的文档match_all全部输出
GET /article/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"term": {
"content": "个"
}
}
]
}
}
}
7.3 terms过滤器
terms 关键字,进行多个关键词过滤
// 过滤article索引中content字段中包含"优","彩"的文档,并对过滤后的结果进行全部输出
GET /article/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"terms": {
"content": [
"优",
"彩"
]
}
}
]
}
}
}
7.4 range过滤器
range 关键字,对关键词进行范围过滤
// 过滤article索引中(1<=id<=10)的文档,并全部输出
GET /article/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"range": {
"id": {
"gte": 1,
"lte": 10
}
}
}
]
}
}
}
7.5 exists过滤器
exists 关键字,对文档中某个字段是否存在进行过滤
// 过滤article索引中存在content字段的文档,并对过滤后的数据全部输出
GET /article/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"exists": {
"field": "content"
}
}
]
}
}
}
7.6 ids过滤器
ids 关键字,对文档中存在的id,进行过滤
// 过滤article索引中_id:[1,2,5]的文档,并全部输出
GET /article/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {}
}
],
"filter": [
{
"ids": {
"values": [
"1",
"2",
"5"
]
}
}
]
}
}
}
8、ES中的分词器
8.1 简介


8.2 ES中内置的分词器
- Standard Analyzer - 默认分词器,英文按单词切分,中文按字切分,(符号被过滤)并小写处理
- Simple Analyzer - 按照(非字母切分)切分,(符号被过滤),并小写处理
- Stop Analyzer - 过滤停用词(the、a、is),(符号被过滤),并小写处理
- Whitespace Analyzer - 按照空格切分,(符号不会被过滤)不转小写
- Keyword Analyzer - 不分词,直接将输入当作输出
8.3 ES中内置分词器测试
// standard 分词器
POST /_analyze
{
"analyzer": "standard",
"text": "我是中国人&this is a good Man!"
}
// simple 分词器
POST /_analyze
{
"analyzer": "simple",
"text": "我是中国人&this is a good Man!"
}
// stop 分词器
POST /_analyze
{
"analyzer": "stop",
"text": "我是中国人&this is a good Man!"
}
// whitespace 分词器
POST /_analyze
{
"analyzer": "whitespace",
"text": "我是中国人&this is a good Man!"
}
// keyword 分词器
POST /_analyze
{
"analyzer": "keyword",
"text": "我是中国人&this is a good Man!"
}
8.4 创建索引时,指定字段使用的分词器
PUT /article
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id":{
"type": "integer"
},
"title":{
"type": "keyword",
"analyzer": "standard" //指定分词器
}
}
}
}
8.5 总结
ES中内置的分词对中文都不是很好的分词,所以就需要引入中文分词器来对中文进行更好的支持
8.6 ES中的中文分词器
在ES中支持中文分词器非常多,如:smartCN、IK等,推荐的就是IK分词器。
8.6.1 IK分词器下载与安装
https://elasticsearch.cn/download/
注意:IK分词器插件的版本要和ElasticSearch的版本一致
安装:
将安装包解压,放置es的plugins文件下,重新启动es。

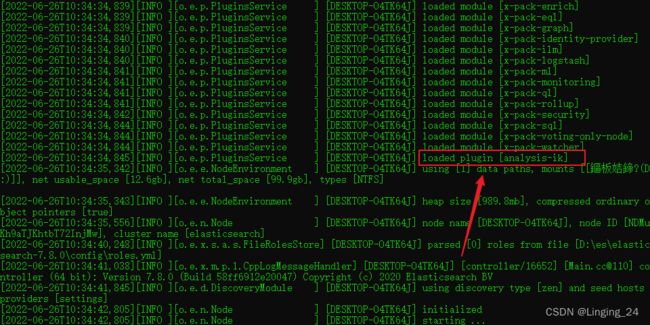
说明ik分词器安装成功。
8.6.2 IK分词器使用
IK分词器有两种颗粒度的拆分:
ik_smart:会做最粗粒度的拆分ik_max_word:会将文本做最细粒度的拆分
POST /_analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国国歌"
}
POST /_analyze
{
"analyzer": "ik_max_word",
"text": "中华人民共和国国歌"
}
8.6.3 扩展词和停用词的配置

DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">entry>
<entry key="ext_stopwords">entry>
properties>
新建一个扩展字典,以*.dic结尾即可,在文件中写入需要扩展的字典。默认提供了extra_main.dic
新建一个停用词扩展字典,以*.dic结尾,在文件中写入需要停用的字典。默认提供了extra_stopword.dic
在上述配置文件配置,并重启ES即可。
DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置comment>
<entry key="ext_dict">extra_main.dicentry>
<entry key="ext_stopwords">extra_stopword.dicentry>
properties>
9、ES中的聚合查询
9.1 简介

测试数据:
// 创建索引和映射
PUT /books
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id":{
"type": "integer"
},
"name":{
"type": "keyword"
},
"author":{
"type": "keyword"
},
"price":{
"type": "double"
},
"introduction":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
// 插入数据
POST /books/_bulk
{"index":{"_id": 1}}
{"id":1,"name":"Java编程思想","author":"布鲁斯·埃克尔","price":129.8,"introduction":"主体部分共 22 章,内容包含对象、操作符、控制流、初始化和清理、复用、多态、接口、内部类、集合、函数式编程、流、异常、代码校验、文件、字符串、泛型等。"}
{"index":{"_id": 2}}
{"id":2,"name":"算法图解","author":"巴尔加瓦","price":52.0,"introduction":"本书示例丰富,图文并茂,以让人容易理解的方式阐释了算法,旨在帮助程序员在日常项目中更好地发挥算法的能量。书中的前三章将帮助你打下基础,带你学习二分查找、大O表示法、两种基本的数据结构以及递归等。余下的篇幅将主要介绍应用广泛的算法,具体内容包括:面对具体问题时的解决技巧,比如,何时采用贪婪算法或动态规划;散列表的应用;图算法;Kzui近邻算法。"}
{"index":{"_id": 3}}
{"id":3,"name":"Java核心技术","author":"凯·S·霍斯特曼","price":149.0,"introduction":"本书由拥有20多年教学与研究经验的资深Java技术专家撰写(获Jolt大奖),是程序员的优选Java指南。本版针对Java SE 9、10和 11全面更新。"}
{"index":{"_id": 4}}
{"id":4,"name":"深入理解Java虚拟机","author":"周志明","price":64.5,"introduction":"这是一部从工作原理和工程实践两个维度深入剖析JVM的著作,是计算机领域公认的经典,繁体版在中国台湾地区也颇受欢迎。"}
{"index":{"_id": 5}}
{"id":5,"name":"Java并发编程实战","author":"Brian Goetz","price":64.5,"introduction":"《Java并发编程实战》深入浅出地介绍了Java线程和并发,是一本完美的Java并发参考手册。书中从并发性和线程安全性的基本概念出发,介绍了如何使用类库提供的基本并发构建块,用于避免并发危险、构造线程安全的类及验证线程安全的规则,如何将小的线程安全类组合成更大的线程安全类,如何利用线程来提高并发应用程序的吞吐量,如何识别可并行执行的任务,如何提高单线程子系统的响应性,如何确保并发程序执行预期任务,如何提高并发代码的性能和可伸缩性等内容,最后介绍了一些高级主题,如显式锁、原子变量、非阻塞算法以及如何开发自定义的同步工具类。"}
9.2 根据字段分组,并统计个数
// 按price字段分组,并统计个数
GET /books/_search
{
"query": {
"match_all": {} //查询所有文档
},
"aggs": {
"price_group": { // price_group为分组名成,自定义,随便写
"terms": {
"field": "price" //指定分组的字段
}
}
},
"size": 0 //不返回文档数据,只返回分组的信息
}
9.3 求最大值
// 查询price的最大值
GET /books/_search
{
"query": {
"match_all": {}
},
"aggs": {
"price_group": {
"max": {
"field": "price"
}
}
},
"size": 0
}
9.4 求最小值
// 查询price最小值
GET /books/_search
{
"query": {
"match_all": {}
},
"aggs": {
"price_group": {
"min": {
"field": "price"
}
}
},
"size": 0
}
9.5 求平均值
// 查询price的平均值
GET /books/_search
{
"query": {
"match_all": {}
},
"aggs": {
"price_group": {
"avg": {
"field": "price"
}
}
},
"size": 0
}
9.6 求和
// 查询price的总和
GET /books/_search
{
"query": {
"match_all": {}
},
"aggs": {
"price_group": {
"sum": {
"field": "price"
}
}
},
"size": 0
}
10、SpringBoot整合ES
10.1 整合准备
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
配置客户端:
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {
@Bean
@Override
public RestHighLevelClient elasticsearchClient() {
ClientConfiguration configuration = ClientConfiguration.builder()
.connectedTo("127.0.0.1:9200")
.build();
RestHighLevelClient client = RestClients.create(configuration).rest();
return client;
}
}
配置完客户端,ES会为我们创建两个客户端对象:
- ElasticsearchOperations - 这个对象是基于面向对象的,以对象方式来操作ES的,在对象中加注解。
- RestHighLevelClient - 这个对象是以rest的方式来操作Es,推荐这种方式。
10.2 API测试:
https://blog.csdn.net/Linging_24/article/details/125549820?spm=1001.2014.3001.5502
11、ES集群
11.1 搭建ES集群步骤:
- 创建cluster文件夹
- 将ES的压缩文件复制三份,分别命名为:
node-1001、node-1002、node-1003 - 修改
config/elasticsearch.yml配置文件 - 分别启动
bin/elasticsearch.bat
node-1001配置文件:
#节点 1 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1001
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1001
#tcp 监听端口
transport.tcp.port: 9301
#discovery.seed_hosts: ["localhost:9301", "localhost:9302","localhost:9303"]
#discovery.zen.fd.ping_timeout: 1m
#discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1001", "node-1002","node-1003"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
#集群中至少2个节点,该集群可用
gateway.recover_after_nodes: 2
node-1002配置文件:
#节点 2 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1002
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1002
#tcp 监听端口
transport.tcp.port: 9302
#ES服务发现
#配置该节点会与哪些候选地址进行通信
discovery.seed_hosts: ["localhost:9301"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1001", "node-1002","node-1003"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
#集群中至少2个节点,该集群可用
gateway.recover_after_nodes: 2
node-1003配置文件:
#节点 3 的配置信息:
#集群名称,节点之间要保持一致
cluster.name: my-elasticsearch
#节点名称,集群内要唯一
node.name: node-1003
node.master: true
node.data: true
#ip 地址
network.host: localhost
#http 端口
http.port: 1003
#tcp 监听端口
transport.tcp.port: 9303
#候选主节点的地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["localhost:9301", "localhost:9302"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
#集群内的可以被选为主节点的节点列表
#cluster.initial_master_nodes: ["node-1001", "node-1002","node-1003"]
#跨域配置
#action.destructive_requires_name: true
http.cors.enabled: true
http.cors.allow-origin: "*"
#集群中至少2个节点,该集群可用
gateway.recover_after_nodes: 2
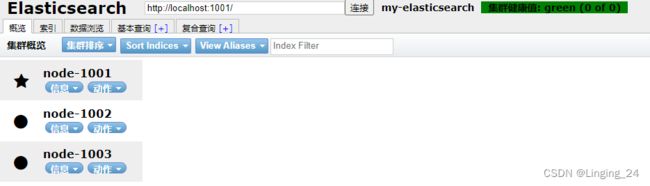
随机访问一个节点,查看集群是否正常。
// 查看集群状态:
http://localhost:1001/_cat/health?v
http://localhost:1001/_cluster/health
![]()
11.2 下载google插件
elasticsearch-head.crx 可以查看集群健康状态
下载地址:https://github.com/mobz/elasticsearch-head/blob/master/crx/es-head.crx
11.3 Kibana连接ES集群启动时的一些坑:
-
提示"Kibana server is not ready yet"
解决:将kibana配置文件kibana.yml,下面参数设置大点。
elasticsearch.requestTimeout: 90000 -
提示"503 Failed to poll for work: [cluster_block_exception] blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"
解决:经查错误的原因是Kibana所在挂载点的磁盘空间不足,解决方法是将将kibana移到磁盘空间较大的目录下,即可启动成功。
12、ES中的数据类型
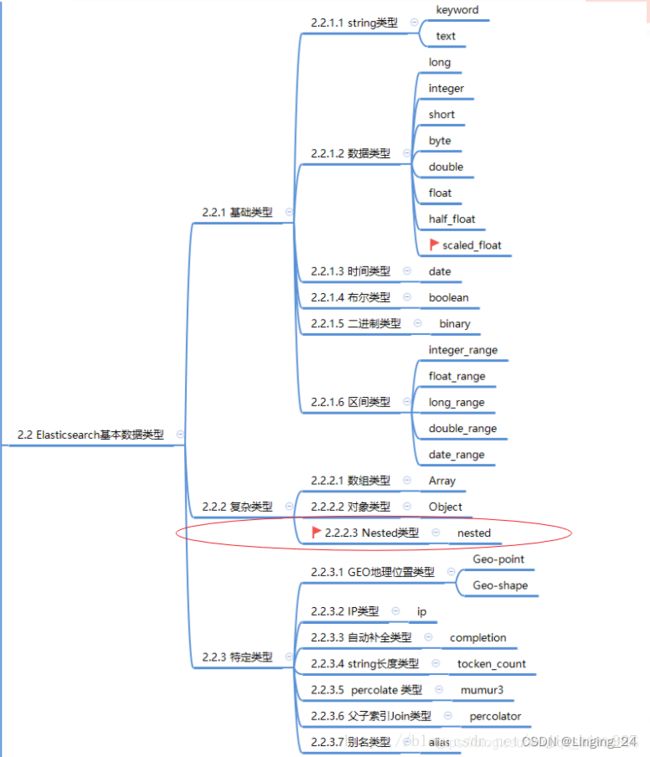
在ES中,数组不需要专用字段数据类型。默认情况下,任何字段都可以包含零个或多个值,但是,数组中的所有值必须是相同的字段类型。
12.1 nested 类型理解
https://blog.csdn.net/qq_28834355/article/details/108711227
nested类型-创建映射:
PUT /blogs_new
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"body": {
"type": "text",
"analyzer": "ik_max_word"
},
"tags": {
"type": "keyword"
},
"published_on": {
"type": "keyword"
},
"comments": {
"type": "nested",
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word"
},
"comment": {
"type": "text",
"analyzer": "ik_max_word"
},
"age": {
"type": "short"
},
"rating": {
"type": "short"
},
"commented_on": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
}
}
nested类型-新增:
POST /blogs_new/_doc/1
{
"title": "Invest Money",
"body": "Please start investing money as soon...",
"tags": ["money", "invest"],
"published_on": "18 Oct 2017",
"comments": [
{
"name": "William",
"age": 34,
"rating": 8,
"comment": "Nice article..",
"commented_on": "30 Nov 2017"
},
{
"name": "John",
"age": 38,
"rating": 9,
"comment": "I started investing after reading this.",
"commented_on": "25 Nov 2017"
},
{
"name": "Smith",
"age": 33,
"rating": 7,
"comment": "Very good post",
"commented_on": "20 Nov 2017"
}
]
}
POST blogs_new/_doc/2
{
"title": "Hero",
"body": "Hero test body...",
"tags": ["Heros", "happy"],
"published_on": "6 Oct 2018",
"comments": [
{
"name": "steve",
"age": 24,
"rating": 18,
"comment": "Nice article..",
"commented_on": "3 Nov 2018"
}
]
}
nested类型-查询:
GET /blogs_new/_search
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "John"
}
},
{
"match": {
"comments.age": "38"
}
}
]
}
}
}
},
{
"match": {
"title": "11"
}
}
]
}
}
}
nested类型-更新:
// 更新comments属性的值
POST /blogs_new/_update/2
{
"doc":{
"comments":[
{
"name": "linging",
"age": 24,
"rating": 18,
"comment": "Nice article..",
"commented_on": "3 Nov 2018"
}
]
}
}
// 更新comments属性中的某个属性的值
// 更新文档id=2中comments对象数组中name=='linging'的age=25 和 comment='very very good article...'
POST blogs_new/_update/2
{
"script": {
"source": "for(e in ctx._source.comments){if (e.name == 'linging') {e.age = 25; e.comment = 'very very good article...';}}"
}
}
nested类型-删除:
// 删除comments数组对象中name=='John'的元素
POST blogs_new/_update/1
{
"script": {
"lang": "painless",
"source": "ctx._source.comments.removeIf(it -> it.name == 'John');"
}
}
nested类型-聚合:
nested聚合属于bucket聚合分类
// 查询blogs_new索引中博客评论者的最小年龄
GET /blogs_new/_search
{
"size": 0,
"aggs": {
"comm_aggs": {
"nested": {
"path": "comments"
},
"aggs": {
"min_age": {
"min": {
"field": "comments.age"
}
}
}
}
}
}