黄萱菁:自然语言处理中的可理解分析
与深度学习所面临的困难相似,目前,大规模应用的神经网络模型同样让自然语言处理领域的研究结果难以解释。模型的性能和可解释性仿佛是天生的敌人,统计结果表明,其性能愈佳,结构就越发复杂,越发难以理解。
在诸如推荐系统,游戏等领域的模型应用,因为风险较小,是否可解释对其影响甚微,但在风险更高的领域,如征信体系中的用户画像、舆情监督、金融数据分析等,结果不明确的模型往往会带来巨大的潜在损失,这极大地削弱了自然语言处理研究的应用价值。近年关于NLP顶会论文主题的统计显示,有关可解释性问题的研究正逐年增长,大量工作为解决模型的可解释性问题提供了很多新的见解。
11月7日,复旦大学的黄萱菁教授在“第五届语言与智能高峰论坛”作了题为“自然语言处理中的可理解分析”的报告,分类讲解了近期领域内的重要工作,并介绍了团队主攻的多项研究。
作者:周寅张皓
1
为什么需要可解释的自然语言处理?
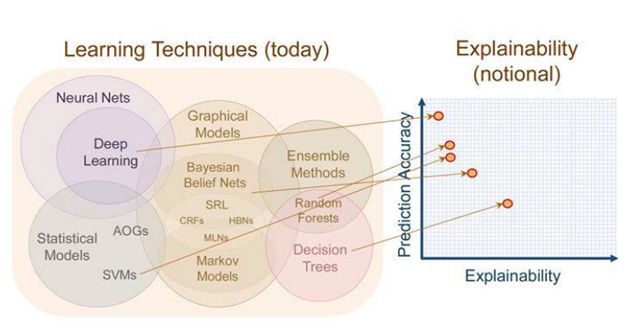
当前针对NLP领域研究结果的统计显示,NLP模型的性能正在不断地逼近某个上限,在诸多任务上的性能提升十分有限。分析表示,当前的工作存在一些普遍的问题:
深度学习技术使我们的研究任务从特征工程过渡到了结构工程,但如何选择更好、更有效的结构是一个经验控制的过程。
模型的不可解释带来应用领域的风险,需要规避风险以拓展其应用空间。
近年来学界对可解释性问题的关注展现了解决以上问题的可能性。
自然语言处理中的可解释性
2
如何定义可解释性?
2.1. 理解模型部件的功能属性
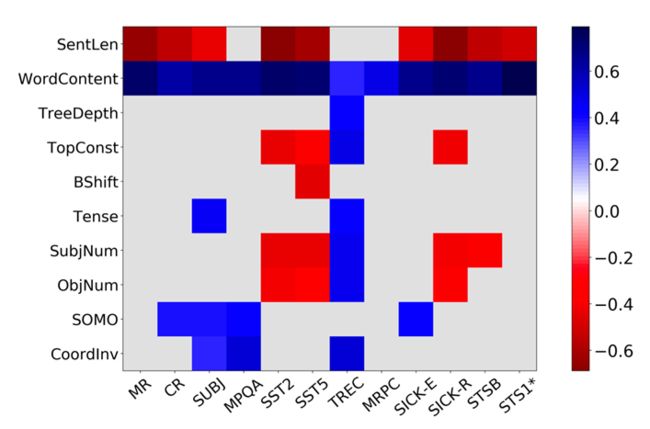
2018年Alex Conneau的开创性工作 [1] 为研究模型编码的功能提供了一种研究方法。作者设计了十种“探针任务”,分别针对不同的输入特征(语义、语法结构、句长等)进行考察,发现特定的词对于任务的性能有着广泛的正相关性。工作为后续的可解释性研究提供了一种评价的标准,其采用指针任务的分析思路也得到了许多后继工作的沿用。
2016年 Karpathy et al. [2] 展示了神经网络在捕捉长程依赖时,神经元激活的差异,并用红蓝不同色调在语料图中作了可视化分析。文章发现少部分神经元表现出了针对文本特征某种特定的相关性,例如在面对“if”、“(”、“)”等单词时激活。但大多数神经元未发现有明显的特性。

另外,Peters et al(2018) [3] 比较了在训练RNN、LSTM、Transformer等不同模型时的行为差异,确认了非监督双向语言模型的有效性,并通过分析得出底层网络的功能为捕捉短语信息,而高层能够发掘更复杂的语义信息。
Tang et al (2018) [4]重点比较了自注意力模型与CNN、RNN的不同的适用场景。分析得到,自注意力、RNN结构模型相较于CNN有更强的长程依赖捕捉能力,而自注意力优势则在于特征提取的能力。
2.2. 解释模型预测的行为
梯度方法
直观上,训练时的梯度大小反映了对应位置的参数或数据的重要程度,因此,通过分析输入数据梯度的大小,可以知晓不同模型预测过程中所关注的数据,从而理解输入特征对于结果预测的贡献。
芝加哥大学的Mukund et al (2017) [5] 发现存在模型在得到正确解答的情况下,错误地依赖了无关的输入特征,表明深度网络存在一定归因错误的问题。

注意力方法
与梯度方法类似,注意力方法通过比较注意力的权重值,来评估输入特征的重要程度。2019年的相关工作得出了不同的结论[6],工作发现Attention权重与基于梯度的特征权重并无关联,不同的任务带来的不同权重有可能得到相似的结果。但仍有工作 [7] 得出了相反的结论,在推广Attention定义后,注意力信息可以在一定程度上解释模型的归因。

注:文章(1)指文献[6],文章(2)指文献[7]
生成支撑决策的依据
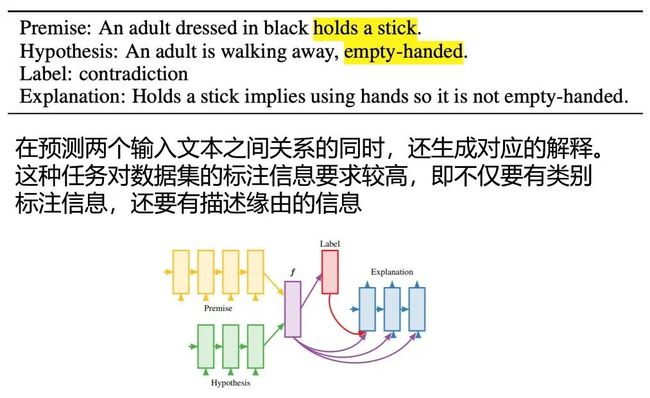
Camburu et al.在2018年的发表的工作 [8] 中提出了另外的解释方法,通过标注后的推断数据,给定输入的前提、假设,用模型判断输入之间存在的逻辑关系,并用模型输出相应解释。该方法很大程度上依赖数据集的标注。
3
模型诊断
近期,领域内的工作主要集中在对抗样本的使用和模型的诊断测试。
对抗样本采用数据集中的微小扰动,分析对应模型输出结果的变化,近期受关注的工作如下:

诊断测试则是构建不同的测试集,每个测试集用来分析不同种类的属性对模型性能的影响,近期受关注的工作如下:
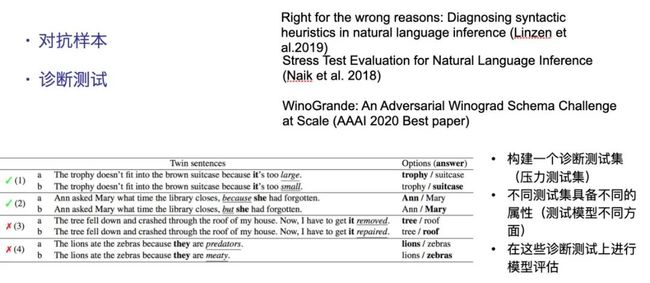
4
工作展示
黄教授带领的团队,近期针对模型部件功能的理解、模型诊断和对抗样本等多个方面开展了研究工作。
4.1. 理解模型部件的功能属性
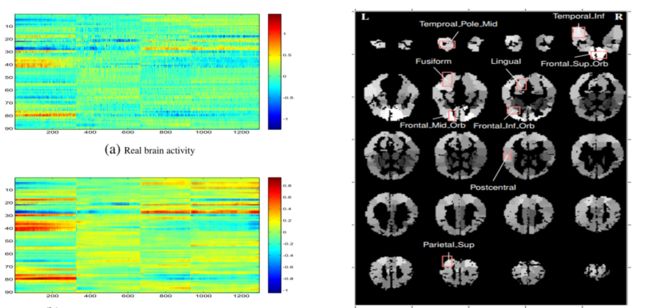
LSTM架构的认知解释
该工作 [9] 比较了人在阅读小说时大脑血氧动力学信号的变化,表示为高维向量,并与LSTM单元在处理语料时的记忆向量进行比较。结果发现映射后的向量和大脑活动真实的表示十分相似,Cosine相似度高达86%。另外,使用LSTM记忆向量重构出的大脑活动,近似于平滑后的真实活动,对于活动脑区的分析也进一步地表明了LSTM神经单元与大脑记忆和语言处理活动的相似性。
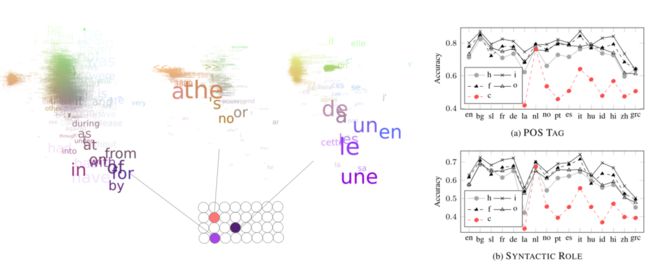
神经网络隐层编码的语言学特征
该工作 [10] 分析了隐层神经元对特定词汇的激活情况,发现存在特定的神经元,在训练中演化出了对特定词性、句法结构的激活识别,使用对应网络进行句法角色分析和词性分析的准确率高达0.6-0.7和0.8。
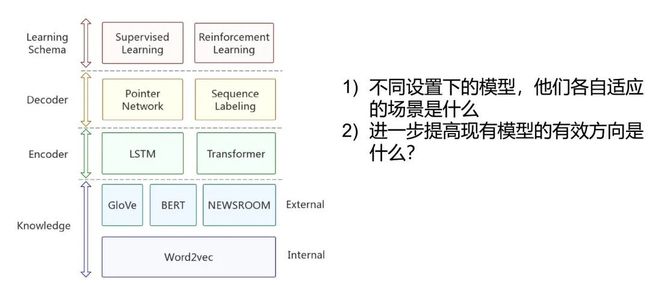
4.2. 模型诊断
针对抽取式文摘的任务,对不同模型进行分析,以了解导致不同配置的模型性能差异的原因。
工作 [11] 发现BERT等预训练词向量的有效性,在编码过程中,Transformer相比LSTM结构具有优越性能,而由自回归机制构建的解码器则在解码能力上超过其他模型。黄教授的团队依据分析的结果构建了新的模型结构,发现其表现得到了相应的提升。
4.3. 评估和增强基于神经网络的依存句法分析模型的鲁棒性
通过对数据集做微小扰动,观察其对于输出的影响。之前的工作主要的改变在于词义,黄教授团队尝试在句法任务上做对抗样本 [12]。因此,只要保证句法结构不变,可以对句子进行扰动的空间更大。通过将对抗数据加入训练,模型的泛化性能得到了提升。
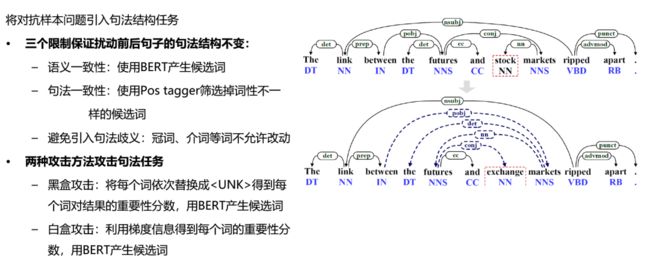
其他的工作包括了基于方面的情感分析(ABSA)中的方面鲁棒性 [13]、使用BERT对BERT的攻击 [14]、反思神经模型的泛化能力 [15] 等。
5
未来的展望
黄萱菁教授在报告最后对NLP模型可解释性的未来发展,提出了几点看法:
首先,需要建立一个可解释性的评价体系,包含统一的评估指标,测试数据和评估标准。
另外,我们需要一个可交互的平台化的可解释性工具。
此外,在研究推进的同时,我们不能忘记可解释性研究的目标,是利用我们对模型的理解来提高其可靠性和应用性能,因此如何探索更多的应用场景,也需要未来的研究者们不断思考。
参考文献:
[1] Conneau, Alexis, et al. "What you can cram into a single vector: Probing sentence embeddings for linguistic properties." arXiv:1805.01070 (2018).
[2] Karpathy, Andrej, Justin Johnson, and Li Fei-Fei. "Visualizing and understanding recurrent networks." arXiv:1506.02078 (2015).
[3] Peters, Matthew E., et al. "Dissecting contextual word embeddings: Architecture and representation." arXiv:1808.08949 (2018).
[4] Tang, Gongbo, et al. "Why self-attention? a targeted evaluation of neural machine translation architectures." arXiv:1808.08946 (2018).
[5] Mudrakarta, Pramod Kaushik, et al. "Did the model understand the question?." arXiv:1805.05492(2018).
[6] Jain, Sarthak, and Byron C. Wallace. "Attention is not explanation." arXiv:1902.10186 (2019).
[7] Wiegreffe, Sarah, and Yuval Pinter. "Attention is not not explanation." arXiv:1908.04626 (2019).
[8] Camburu, Oana-Maria, et al. "e-snli: Natural language inference with natural language explanations." Advances in Neural Information Processing Systems. 2018.
[9] Qian, Peng, Xipeng Qiu, and Xuanjing Huang. "Bridging lstm architecture and the neural dynamics during reading." arXiv:1604.06635 (2016).
[10] Qian, Peng, Xipeng Qiu, and Xuan-Jing Huang. "Analyzing linguistic knowledge in sequential model of sentence." Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. 2016.
[11] Zhong, Ming, et al. "Searching for Effective Neural Extractive Summarization: What Works and What's Next." arXiv:1907.03491 (2019).
[12] Zheng, Xiaoqing, et al. "Evaluating and enhancing the robustness of neural network-based dependency parsing models with adversarial examples." Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020.
[13] Xing, Xiaoyu, et al. "Tasty Burgers, Soggy Fries: Probing Aspect Robustness in Aspect-Based Sentiment Analysis." arXiv:2009.07964 (2020).
[14] Li, Linyang, et al. "Bert-attack: Adversarial attack against bert using bert." arXiv:2004.09984 (2020).
[15] Fu, Jinlan, et al. "Rethinking Generalization of Neural Models: A Named Entity Recognition Case Study." AAAI. 2020.