AI绘画后面的论文——ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models
AI绘画后面的论文——ControlNet:Adding Conditional Control to Text-to-Image Diffusion Models
代码:lllyasviel/ControlNet: Let us control diffusion models! (github.com)
论文地址
最近AI绘画又双叒叕进化了,前一次还只能生成二次元,这次三次元都能生成了。这次AI绘画这么火爆的原因跟下面这篇文章脱不开关系,它将AI绘画带到了一个新的高度。
摘要
我们提出了一个神经网络结构controlnet网络来控制预训练的大扩散模型以支持额外的输入条件。controlnet网络以端到端的方式学习任务特定条件,即使在训练数据集较小( < 50k )的情况下,学习也是鲁棒的。此外,训练一个controlnet网络和微调一个扩散模型一样快,并且模型可以在个人设备上训练。或者,如果有强大的计算集群,模型可以扩展到大量的(百万到十亿)数据。我们报告了像Stable Diffusion这样的大型扩散模型可以用ControlNets来增强,以启用边缘图、分割图、关键点等条件输入。这可能会丰富控制大型扩散模型的方法,进而方便相关应用。
介绍
提出的问题
- 基于文本提示的控制来生成图像是否满足我们的需求?
- 在图像处理中,考虑到许多长期存在的具有明确问题表述的任务,能否应用这些大模型来方便这些特定的任务?
- 我们应该构建什么样的框架来处理广泛的问题条件和用户控制?
- 在特定的任务中,大型模型可以保留从数十亿张图像中获得的优势和能力?
文章的发现
- 任务特定领域的可用数据规模并不总是像一般图文领域那样大。像姿势理解这些领域的数据集就很小。这就要求在针对特定问题训练大型模型时,采用稳健的神经网络训练方法以避免过拟合并保持泛化能力。
- 当使用数据驱动的解决方案处理图像处理任务时,大型计算集群并不总是可用的,因为耗时耗内存。所以需要利用预训练的权重,以及微调策略或迁移学习。
- 各种图像处理问题具有不同形式的问题定义、用户控制或图像标注。考虑到一些特定的任务,如depth-to-image、pose-to-person等,这些问题本质上需要将原始输入解释为对象级或场景级的理解,这使得hand-crafted的过程性方法变得不可行。为了在许多任务中实现学习到的解决方案,端到端的学习是必不可少的。
根据以上的发现,文章提出了控制大型图像扩散模型(像Stable Diffusion)去学习任务特定输入条件的端到端神经网络架构ControlNet。
模型介绍
- ControlNet将大型扩散模型的权重克隆为"trainale copy"和"locked copy":locked copy保留了从数十亿张图像中学习到的网络能力,而trainale copy则在任务特定的数据集上训练学习条件控制。
- 可训练和锁定的神经网络块与一种称为"zero-convolution"的独特类型的卷积层连接,其中卷积权重以学习的方式从零到优化参数逐步增长。由于保留了production-ready权重,因此训练在不同规模的数据集上具有鲁棒性。由于zero-convolution并没有给深度特征增加新的噪声,因此与从头开始训练新层相比,训练速度与微调扩散模型一样快。
令人十分欣喜的是,在深度到图像等任务中,在个人计算机(1个Nvidia RTX 3090TI)上训练ControlNets可以取得与在拥有TB级GPU内存和数千GPU小时的大型计算集群上训练的商业模型相当的结果。
网络概览

解释:
-
整体还是U-Net框架
-
注意整个网络是一起训练的,右边绿色部分的初始参数是从左边copy过来的,左边部分的参数不能训练,右边部分的可以训练。
-
使用ControlNet创建稳定扩散的12个编码块和1个中间块的trainable copy,对应右边绿色部分的。
-
将条件图像变成64 × 64的特征空间方法:使用一个4 × 4 kernel,2 × 2步长的4个卷积层,卷积层通过ReLU激活,通道数分别为16、32、64、128,以高斯权重初始化,与整个模型联合训练)的网络,公式描述如下:
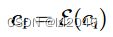
cf是转换后的特征图。
方法
所作的工作

初始网络块
如图a所示:没有使用ControlNet之前的一个网络块,用公式描述就是:
![]()
其中x是一个特征图,F代表一个神经网络块,它的参数是Θ,这个网络块将x转换成另一个特征图
使用了ControlNet的网络块
如图b所示:使用了ControlNet之后的一个网络块,它所作的修改如下:
(1)它从原来的网络中复制了一份参数,这份参数是可以训练的(论文中叫trainable copy,它的参数为Θc),而原来网络的参数是不能训练的(论文中叫locked copy),也就是图中加锁的部分。
这样做的目的是为了防止数据量小的时候过拟合并且保留之前模型的生成质量。
(2)增加了zero-convolution,它的特点是权重和偏差都初始化为0。
经过(1)(2)的修改后,新的网络块用公式描述就是:
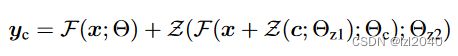
其中Z表示zero convolution操作,Θz1和Θz2是两个zero convolution的参数。
zero-convolution的训练介绍
在第一个训练阶段,有:

因此我们可以推出:
![]()
因为优化之前卷积部分的参数都是0,根据卷积操作的运算过程可知卷积的结果都是0。
由此可以看到:在第一个训练步骤中,神经网络块的trainable copy和locked copy的所有输入和输出都与ControlNet网络不存在时一致。也就是说在开始优化参数之前,ControlNet不会对深度神经特征造成任何影响。任何进一步的优化都将变得像微调(相比于从头训练这些层)一样快。
梯度下降过程:
一个卷积层的公式描述如下:

I是输入的特征图,B是偏差,W是权重。
它的梯度为:(注意它的权重W和偏差B初始值都是0)

从这个公式可以看出,zero-convolution可以导致特征项I上的梯度变为零,但是权重和偏置的梯度不受影响。
在本文中,I为输入数据或从数据集中采样的条件向量,肯定不为0,则在第一次梯度下降迭代中将权重W优化为非零矩阵。梯度下降过程如下:

然后特征上的梯度变为:

此时特征上的梯度不为0,由此神经网络开始学习。
训练
损失函数跟扩散模型差不多,增加了任务指向型的条件参数cf。

同时文章将50 %的文本提示ct随机替换为空字符串。这有利于增强ControlNet从输入条件图中识别语义内容的能力。
实验效果
挑几个出来。
(1)使用Hough lines

(2)使用Canny算子

(3)使用姿势

不足
当语义解释是错误的,模型生成正确的内容可能会有困难。

本来轮廓应该是杯子,但是即使给出文字提示是杯子也无法逆转过来。