Speech Recognition Using attention-based sequence-to-sequence methods
Abstract—Speech is one of the most important and prominent manner to communicate among human being. It also has capacity to become a kind of medium when facing the human computer interaction. Speech recognition has become a popular area across research institutes and the Internet-related companies. This paper presents a brief overview on two main steps of speech recognition which are feature extraction and training model using deep learning. In particular, five art-of-state methods using attention-based sequence-to-sequence model for speech recognition training process are discussed.
Keywords-speech recognition; attention mechanism; sequence to sequence; neural transducer; Mel-frequency cepstrum coefficient
I. INTRODUCTION
Natural language refers to a kind of language that evolves naturally with culture, and it is also the primary tool of human communicating and thinking. While speech recognition, as the name suggests that takes natural language speech as the input into the model, and the output is the text of the speech. In other words, it is converting speech signals into text sequences. It is simple for humans to convert speech audio into text manually. Still, when facing large amounts of data, it takes plenty of time, and it is, to some extent, very difficult or impossible to covert in real-time for humans. Moreover, there are hundreds of languages in the world, so that few experts can master multiple languages simultaneously. As a result, people expect that machine learning can help people achieve this task.
At present, the typical steps of speech recognition include preprocessing, feature extraction, training, and recognition. For the feature extraction, because the speech signal is volatile, even if people try hard to say the same two sentences, the signals of which always have some differences. So, feature extraction of speech is difficult for computer scientists.
In this paper, we introduce the main process of speech recognition. For feature extraction, we introduce one of the most popular approaches of it which is called the Mel-frequency Cepstrum Coefficient (MFCC) [1]. For the training part, it is evident that the length of input (speech vectors sequence) and output (text vectors sequence) is probably different. Input is determined by humans (etc., select 25ms speech), and the specific output length is determined by the model itself. Thus, Sequence-To-Sequence (Seq2Seq) based models are most widely used nowadays.
The remainder of this article is organized as follows. In Section II, the MFCC feature extraction approach is illustrated. In Section III, we describe the basic attention mechanism, as well as five training methods based on it: Listen, Attend, and Spell Connectionist Temporal Classification, RNN transducer, Neural Transducer, and Monotonic Chunkwise Attention. Finally, concluding remarks are contained in Section IV.
II. FEATURE EXTRACTION
Because of the instability of speech signals, feature extraction of the speech signal is very difficult. It exists different features between each word. For each word, there are differences among different people, such as adults and children, male and female. Even for the same person and the same word, there also exists changes for a different time[2]. Mel-Fre-Frequency-Doppler is proposed based on the different auditory characteristics of human ears. It uses the nonlinear frequency unit, which names Mel frequency [4], to simulate the human auditory system [8,10,11,17,18]. The calculation method is shown in Formula (1):

Figure 1 shows the construction of the MFCC model.
The original acoustic wave through the window and other pre-processing, then we obtain the frame signal.
Because it is difficult to observe the characteristics of the signal in the time domain, transforming it into the energy distribution in the frequency domain can solve this problem. The energy distribution in the spectrum, which represents the characteristics of different sounds, is obtained by fast Fourier transform.
After the fast Fourier change of the speech signals is completed, Mel frequency filtering is performed [3]. The specific step is to redefine the filter bank composed of triangular bandpass filters, assuming that the center frequency of each filter is , is the low-pass frequency within the coverage range after the cross overlap of three filters, is the high pass frequency. Then the calculation method is shown as

We can obtain the output spectrum energy generated by each filter, and then the data should be transformed into a logarithm. Finally, the discrete cosine transform is converted to the time domain to obtain the final MFCC. In MFCC, the main advantage is that it uses Mel frequency scaling, which is very approximate to the human auditory system.
III. TRAINING MODEL
In this section, we first introduce the Sequence to sequence model and attention mechanism, and then we discuss five models based on Seq2seq and attention. The five models are named Listen, Attend, and Spell, Connectionist Temporal Classification, RNN transducer, Neural Transducer, and Monotonic Chunkwise Attention.
A. Description of attention-based sequence-to-sequence model
A typical sequence to sequence model has two parts – an encoder and a decoder. Both parts are practically two different neural network models combined into one network. The task of an encoder network is to understand the input sequence, and create a high-dimensional representation of it. This representation is forwarded to a decoder network which generates a sequence of its own that represents the output. Figure 2 shows the Encoder-decoder with an attention mechanism. Match can be Dot-product method or Additive attention method.

The attention mechanism [19] is achieved by Encoder and Decoder. When human tries to understand a picture, he/she focuses on specific portions of the image to get the whole essence of the picture. So, we can train an artificial system to focus on particular elements of the image to get the whole “picture”. This is essentially how the attention mechanism works. To implement an attention mechanism, we take input from each time step of the encoder – but give weightage to the time steps. The weightage depends on the importance of that time step for the decoder to optimally generate the next word in the sequence. The output is computed by the weighted sum of the values, where the weight of each value is calculated by the query and the corresponding key. [19] We compute the dot products of the query(Q) with all keys(K), divide each by and apply a softmax function to obtain the weights on the values. The calculation of attention is shown as
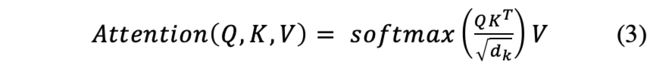
The common methods to achieve Match functions is Dot-product method [19]. Additive attention [26] is another function, we compute the sum operation instead of dot products, which using a feed-forward network with a single hidden layer, and this function is shown as
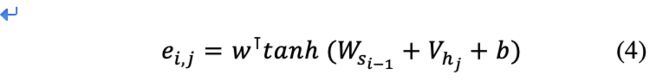
B. Speech recognition using attention-based sequence-to-sequence methods
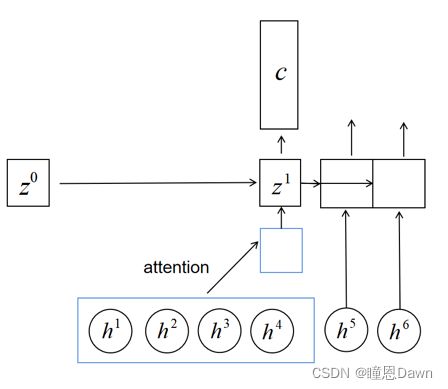
Attend and Spell (LAS) [9], a neural network that learns to transcribe an audio sequence signal to a word sequence, one character at a time, without using explicit language models, pronunciation models, HMMs, etc. LAS does not make any independent assumptions about the nature of the probability distribution of the output character sequence, given the input acoustic sequence. This method is based on the sequence-to-sequence learning framework with attention. It consists of an encoder Pyramid Recurrent Neural Network (p-RNN), which is named the Listener, and a decoder RNN, which is named the Speller. The Listener converts acoustic features which are generated from MFCC, into high-level features. The purpose of this module is to remove the noise from speech and extract the information which is only related to speech recognition, such as the difference between speaker and speaker. Listener can be processed by RNN or convolutional neural network (CNN) and the current mainstream approach is adding self-attention into loop management. While the signal of speech is often too long, and adjacent vectors carry repeated information in the RNN sequence. P-RNN adds the Down-sampling operation in Listen module. Figure 3 shows the structure of p-RNN, and the blocks in this figure mean that there are four vectors in the first layer in RNN but two vectors in the second layer.

Toward Down-sampling, Pooling Over Time [4] and Truncated Self-attention [17] are optional measures. Polling Over Time can select fewer vectors as output and Truncated Self-attention only consider part of sequence instead of the whole sequence. The difference between them is showed in Figure 4 and Figure 5.


The Speller is an RNN and it converts the higher level features into output discourse by affirm the probability distribution of the next character, given all of the acoustics and preceding characters. During each step, the RNN uses its internal state to guide an attention mechanism [21, 22, 23] to compute a “context” vector from the high level features of the listener. By using this context vector and internal state to both update the internal state and to predict the next character in the sequence. Figure 6 shows the construction of Listen, Attend and Spell Model.
Connectionist Temporal Classification (CTC) [11,15] can achieve online streaming speech recognition, which means it gives a token distribution when seeing one input vector. Figure 7 shows the structure of CTC and . In order to complete online management, Encoder need to use some model that seeing the whole sequence is not a necessary task and uni-directional RNN is an optional choice. One difficulty is that every acoustic feature is very short, so making the decision about what this acoustic belongs to is hard to machine. Toward this issue, model add an element in token distribution when machine cannot make sure the input vector’s class. In the end, we first merge duplicate tokens and then remove the output which include . Another problem is labeled label is not enough to process the cross-entropy. If we use Phoneme as the output token, 10 vectors may represent one word and meanwhile, it includes . According to the rule of merging and removing, designing and creating the new label is necessary and this operation is called Alignment. In that paper, the author selects exhaustion to help training.
In speech recognition, it is no doubt that people prefer obtaining a timely result to getting it after inputting the whole sentence. However, the sequence-to-sequence model is not suitable for these critical tasks. Neural transducer [13], one of the general sequence-to-sequence models, can meet the demand by separating the outputs into ‘chunks’. The key is using a transducer RNN which generates extensions to former output. Before the Neural Transducer model was published, some related models, such as sequence transducer which can model the conditional dependence of input and output at the same time. Moreover, there is no limit on the length of input and output in this model. However, its prediction model and transcription model cannot operate in one-time steps. The model generally intercepts the voice stream (such as 300ms) as a block according to a fixed time length. The neural transducer receives the voice information of the current block and decodes the corresponding text of the current voice stream segment. And then, it combines with the output text information of the previous block and the neural network state. By using this model, the decoding delay is effectively controlled. The presence of Neural Transducer as an extension of RNN and sequence-to-sequence model can realize ‘online’ speech recognition and produce output in real-time.


As one of the most popular models, Recurrent Neural Network has demonstrated great success in many kinds of tasks. In speech recognition, RNNs can transcribe raw speech waveforms. However, with the shortcomings such as the high costs, a system of end-to-end speech recognition [15] consisting of a single RNN architecture instead of a speech pipeline can improve performance. In this model, a combination of the deep bidirectional LSTM [6] recurrent neural network and the Connectionist Temporal Classification objective function plan an essential role in optimizing the word error rate. This method has been replied to, but the results are not convincing enough. The bidirectional LSTM recurrent neural network is the combination of BRNNs with LSTM. Figure 8 shows the structure of BRNNs.

The idea of the bidirectional recurrent neural network [5] is dividing the traditional cell into two parts, one is for positive time direction (forward states), and the other is for negative time direction (backward states). In addition, the outputs of forwarding states do not connect to the input of Backward states. Therefore, this structure provides the output layer with complete past and future context information for each point in the input sequence. In speech recognition, our data set is an audio file and its corresponding text. Unfortunately, audio files and text are difficult to align on the unit of words. Connectionist Temporal Classification objective functions allow an RNN to be trained for sequence transcription tasks without requiring any prior alignment between the input and target sequences. In general, it allows RNN to learn sequence data directly without labeling the mapping relationship between the input sequence and output sequence in training data in advance, breaks the data dependency constraint of RNN applied to speech recognition, and makes the RNN model achieve better application results in sequence learning tasks. Finally, combining the new models and the basic models improves the latest accuracy of independent speaker recognition.
In the network training, RNN transducer [7] is a kind of method for improving online speech recognition. It is an improvement of the CTC model. However, because there are still many problems in the CTC model, the most significant of which is that CTC assumes that the outputs of the model are conditionally independent. In view of the shortcomings of CTC, Alex graves proposed the RNN-t model around 2012. RNN-t model skillfully integrates language model and acoustic model and carries out joint optimization at the same time. It is a relatively perfect model structure in theory. Figure 9 shows the structure of RNN -t. It includes three modules: encoder network, language model prediction network, and joint network. Encoder network is generally composed of multi-layer Bi LSTM. Input the acoustic characteristics of the time sequence to obtain high-level feature expression. The Predictor is composed of multi-layer uni LSTM, embedding corresponding to the input label and the corresponding output. Joiner is a combination of multi-layer and full connection layers. The input is a linear combination of two codes, which is input into the feed-forward neural network to obtain the probability distribution function of prediction characters [14].

However, there were still some problems like the quadratic time and space cost happened in the decoding process. To overcome these problems and enhance the efficiency, the model called Monotonic Chunkwise Attention (MoCha) [17] solves these problems by splitting the input sequence into some small chunks.
The structure of MoCha is similar with that of sequence-to-sequence which combines with the soft attention which can convert the input sequence into a new output sequence. And Figure 9 displays the structure of MoCha. Transporting the generated output elements to the input can help regulate the output generation process more directly while the self-attention model cannot improve so much. And the main difference between MoCha and Neural Transducer is that the size of the window can change dynamically. And the window size is a parameter of model learning. And the other parts are all same as that of Neural Transducer, which can provide the output timely.
IV. CONCLUSION
In this paper, we have a review on MFCC which is a feature extraction method. And then we introduce Attention mechanism and Seq2seq model. In the end, we discuss five current prominent model about speech recognition base on Attention and Seq2seq mechanism.
In conclusion, MFCC is the essential first step of speech signal processing. It is a cepstrum parameter extracted in mel scale frequency domain. Mel scale describes the nonlinear characteristics of human ear frequency. LAS is a neural speech recognizer that can transfer acoustic features to characters directly without using any of the traditional components of a speech recognition system, such as HMMs. This approach is the cornerstone of new neural speech recognizers that are simpler to train and achieve better than traditional speech recognition systems. CTC is an online streaming speech recognition method, so it gives a token distribution when seeing one input vector. This mechanism is so flexible that it allows extremely non-sequential alignments. In speech recognition, the acoustic feature inputs and corresponding outputs generally produced in the same order with only small deviations. Another problem is that the input and output sequences have very different lengths, and they are different in different case, which depend on the speaking rate and writing system. So this issue making it more difficult to process the alignment. The Neural translator is a model that can help realize real-time transformation. It is helpful for the speech recognition system and is also very important for the future online speech translation system. Recurrent neural networks are a kind of neural network that can be used for prediction. It has no requirements for the input sequence length and has the prediction ability based on time series data. Some of its extensions and deformations have improved its defects and have a wide range of applications according to different needs. Moreover, RNN-t is an improvement based on CTC to improve real-time recognition. It adds an RNN with the previous output as the input based on the encoder of the CTC model, which is called a prediction network. It has fast training speed and high efficiency. MoCha is a seq2seq model with soft attention, which retains the advantages of hard monotonic attention linear time complexity and real-time decoding and allows soft alignment.
REFERENCES
W. Junqin, and Y. Junjun, “An improved arithmetic of MFCC in speech recognition system,” International Conference on Electronics, Communications and Control (ICECC), 2011, pp. 719–722.
Wang Sumin. The Research and Simulation of Isolated Word in Noise:[Master thesis], Jiangxi University of Science and Technology, 2009.
Chen Yong, Qu Zhiyi, Liu Ying, Jiu Kang, Guo Aiping, Yang Zhiguo,
The Extraction and Application of Phonetic Characteristic Parameter MFCC, Journal of Hunan Agricultural University (natural sciences), 2009.
C. Ittichaichareon, S. Suksri, and T. Yingthawornsuk “Speech recognition using MFCC,” International conference on computer graphics, simulation and modeling, 2012, pp. 135-138.
M. Schuster and K. K. Paliwal,“Bidirectional Recurrent Neural Networks,” IEEE Transactions on Signal Processing, vol. 45, pp. 2673–2681, 1997.
M.A. Graves and J. Schmidhuber, “Framewise Phoneme Classification with Bidirectional LSTM and Other Neural Network Architectures,”Neural Networks, vol. 18, no. 5-6, pp. 602–610, June/July 2005.
A. Graves, “Sequence transduction with recurrent neural networks,” in ICML Representation Learning Work-sop, 2012.
W. Han, C. Chan, C. Choy, and K. Pun, “An efficient MFCC extraction method in speech recognition,” IEEE International Symposium on Circuits and Systems, 2006, pp. 4- .
W. Chan, N. Jaitly, Q. Le, and O. Vinyals, “Listen, attend and spell: A neural network for large vocabulary conversational speech recognition,” IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 4960–4964.
G. Saha, and U. S. Yadhunandan, “Modified mel-frequency cepstral coefficient,” Proceedings of the IASTED, 2004.
S. Watanabe, T. Hori, S. Kim, J. R. Hershey, and T. Hayashi, “Hybrid CTC/Attention Architecture for End-to-End Speech Recognition,” IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 8, pp. 1240-1253, 2017.
A. Graves, and N. Jaitly, “Towards End-To-End Speech Recognition with Recurrent Neural Networks,” International conference on machine learning, 2014, pp. 1764-1772.
N. Jaitly, D. Sussillo, Q. V. Le, O. Vinyals, I. Sutskever, and S. Bengio, “A neural transducer,” arXiv preprint, 2015.
C. Yeh, J. Mahadeokar, K. Kalgaonkar, Y. Wang, D. Le, M. Jain, K. Schubert, C. Fuegen, and M. L. Seltzer, “Transformer-transducer: End-to-end speech recognition with self-attention,” arXiv preprint, 2019.
A. Graves, A. Mohamed, and G. Hinton “Speech recognition with deep recurrent neural networks,” IEEE international conference on acoustics, speech and signal processing, pp. 6645 - 6649, 2013.
C. Yeh, J. Mahadeokar, K. Kalgaonkar, Y. Wang, D. Le, M. Jain, K. Schubert, C. Fuegen, and M. L. Seltzer, “Transformer-transducer: End-to-end speech recognition with self-attention,” arXiv preprint, 2019.
C. C. Chiu, and C. Raffel, “Monotonic chunkwise attention,” arXiv preprint, 2017.
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, 2017, pp. 5998-6008.
D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint, 2014.
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
S. Hochreiter, Y. Bengio, P. Frasconi, and J. Schmidhuber, “Gradient flow in recurrent nets: the difficulty of learning long-term dependencies,” 2001.
S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural computation, pp. 1735–1780, 1997.
T. Hori, S. Watanabe, Y. Zhang, and W. Chan, “Advances in joint CTC-attention based end-to-end speech recognition with a deep CNN encoder and RNN-LM,” arXiv preprint, 2017.
A. Graves, S. Fernández, F. Gomez, and J. Schmidhuber, “Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks,” Proceedings of the 23rd international conference on Machine learning, 2006, pp. 369-376.
D. Bahdanau, K. Cho, and Y. Bengio, “Neural machine translation by jointly learning to align and translate,” arXiv preprint, 2014.
D. Bahdanau, J. Chorowski, D. Serdyuk, P. Brakel, and Y. Bengio, “End-to-end attention-based large vocabulary speech recognition,” IEEE international conference on acoustics, speech and signal processing (ICASSP), 2016, pp. 4945-4949.