nginx 499/500/502/504 错误分析
一、前言
在开始之前,我们先来看几个在 Nginx 作为反向代理工具中经常遇到的几个异常状态码:
- 499: 客户端主动断开连接。通常为一次请求未在客户端指定时间内返回,客户端主动关闭连接,客户端无数据返回 (在 Nginx 中会记录 499)。一般是
客户端超时 - 500: 服务器内部错误。服务器遇到未知错误导致无法完成请求处理,通常由于后端业务逻辑异常导致 (本身 Bug)
- 502: 网关错误。通常为网关未从上游服务中获取期望的响应 (
上游未返回数据或未按照协议约定返回数据),网关感觉自己没用了,返回了网关错误。一般是后端服务器宕机或业务逻辑超时 - 504: 网关超时。表示网关没有及时从上游获取响应数据。一般是 Nginx 网关作为客户端去向上游服务请求响应的过程中,Nginx 网关超时导致,但此时对于上游服务器来将,它会继续执行,直到结束。(
Nginx网关作为客户端时的超时)
# 499 的实际情况就是,客户端指定超时时间为N秒,但是该请求在服务端实际需要执行M秒(M>N秒),客户端等的不耐烦了就关闭了
# 对于499状态来讲,解决方式是优化后端代码逻辑或者修改nginx参数
$ cat nginx.conf
proxy_ignore_client_abort on;
$ curl -i -m 3 http://127.0.0.1/hello.php
# 502的实际情况通常是Nginx网关后端的服务器直接宕机了(所以就拿不到上游的响应了)
# 当然也有可能是上游服务器真正的执行逻辑超过了上游服务器的超时时间限制(比如php-fpm.conf设置request_terminate_timeout5s,但是实际的业务逻辑需要7s才能完成),此时上游服务器端出现`业务逻辑超时`,给Nginx网关返回了异常的数据造成的
# 502时后端的几种错误日志
recv() failed (104: Connection reset by peer) while reading response header from upstream
upstream prematurely closed connection while reading response header from upstream
connect() failed (111: Connection refused) while connecting to upstream
# 整体来说502出现的问题通常是因为后端挂了,或者因为后端负载太高,暂时不可响应
# 可以在nginx侧增加proxy_read_timeout来暂时缓解
$ cat nginx.conf
proxy_read_timeout 20s;
# 504的实际情况就是客户端->Nginx->Backend,在过程中Nginx需要作为客户端访问Backend服务,但是在Backend还没用执行完成时,Nginx首先超过了自己的客户端超时时间,此时就会出现504的异常(但是对于客户端来说返回什么呢?)
# 对于504场景而言,通常的做法就是优化Backend的逻辑,适当减少执行时间;另外也可以适当的增加Nginx作为客户端时的超时时间
# 要知道,当Nginx作为客户端时,是以一个Proxy的角色存在的,配置如下参数即可
$ cat nginx.conf
uwsgi_connect_timeout 5;
uwsgi_send_timeout 5;
uwsgi_read_timeout 5;
fastcgi_read_timeout 5;
fastcgi_send_timeout 5;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;二、499问题描述:
Nginx 服务器大量499报错
220.181.165.136 - - [18/May/2015:10:31:02 +0800] "POST /v1/jobsHTTP/1.1" 499 0 "" "bdHttpRequest/1.0.0"
115.239.212.7 - - [18/May/2015:10:31:03 +0800] "GET /v1/job/643309e3-dc73-4025-aa69-c9405c1d818fHTTP/1.1" 499 0"http://www.baidu.com/?tn=91638679_hao_pg&s_j=1""Mozilla/5.0 (Windows NT 6.1; Trident/7.0; rv:11.0) like Gecko"
140.207.202.187 - - [18/May/2015:10:30:58 +0800] "POST/v3/violations HTTP/1.1" 499 0 "-" "-"
42.236.10.71 - - [18/May/2015:10:30:59 +0800] "POST /v3/violationsHTTP/1.1" 499 0 "-" "-"
106.120.173.17 - - [18/May/2015:10:30:58 +0800] "POST/v3/violations HTTP/1.1" 499 0 "-" "Mozilla/5.0 (Windows NT6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131Safari/537.36"
180.97.35.164 - - [18/May/2015:10:30:52 +0800] "GET/v1/job/f86bdecc-2a61-4a42-bb7b-aa794b77f89b HTTP/1.1" 499 0"http://www.baidu.com/s?word=%E5%8D%81%E5%A0%B0%E5%A4%A9%E6%B0%94&tn=sitehao123&ie=utf-8""Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)"问题分析:
1 499出现的原因
google定义:
499 / ClientClosed Request
An Nginx HTTP server extension. This codeis introduced to log the case when the connection is closed by client whileHTTP server is processing its request, making server unable to send the HTTP header back
维基百科定义:
499 Client Closed Request (Nginx)
Used in Nginx logs to indicate when the connection has been closed by client while the server is still processing itsrequest, making server unable to send a status code back
Nginx源码:
grep一下nginx源码,定义在ngx_request_t.h :
/*
* HTTP does notdefine the code for the case when a client closed
* the connectionwhile we are processing its request so we introduce
* own code to logsuch situation when a client has closed the connection
* before we even tryto send the HTTP header to it
*/
#define NGX_HTTP_CLIENT_CLOSED_REQUEST 499这是nginx定义的一个状态码,用于表示这样的错误:服务器返回http头之前,客户端就提前关闭了http连接.
继续grep :

这很有可能是因为服务器端处理的时间过长,客户端“不耐烦”了。
要解决此问题,就需要在程序上面做些优化了。
再grep下“NGX_HTTP_CLIENT_CLOSED_REQUEST”,发现目前这个状态值只在ngx_upstream中赋值
upstream在以下几种情况下会返回499:
(1)upstream 在收到读写事件处理之前时,会检查连接是否可用:
ngx_http_upstream_check_broken_connection,
if (c->error) { //connecttion错误
……
if (!u->cacheable) { //upstream的cacheable为false,这个值跟http_cache模块的设置有关。指示内容是否缓存。
ngx_http_upstream_finalize_request(r, u, NGX_HTTP_CLIENT_CLOSED_REQUEST);
}
}如上代码,当连接错误时会返回499。
(2)server处理请求未结束,而client提前关闭了连接,此时也会返回499。
(3)在一个upstream出错,执行next_upstream时也会判断连接是否可用,不可用则返回499。
总之,这个错误的比例升高可能表明服务器upstream处理过慢,导致用户提前关闭连接。而正常情况下有一个小比例是正常的。
继续分析:
问题的核心就是要排查为什么服务端处理时间过长
可能问题:
1 后台python程序处理请求时间过长
2 mysql慢查询
通过查看监控:
1 cpu和内存的使用,都在正常范围
2 后台程序访问正常
3 MySQL没有慢查询
结果:
经过询问老大后得知,这个nginx为查询违章的api,用户提交查询后, python就去数据库或者交通局的网站查询。这个查询会有消耗一定的时间,所以,用户会主动断开连接
解决问题:
proxy_ignore_client_abort on; #让代理服务端不要主动关闭客户端的连接。
默认 proxy_ignore_client_abort 是关闭的,此时在请求过程中如果客户端端主动关闭请求或者客户端网络断掉,那么 Nginx 会记录 499,同时 request_time 是「后端已经处理」的时间,而upstream_response_time 为“-“ (已验证)。
如果使用了 proxy_ignore_client_abort on, 那么客户端主动断掉连接之后,Nginx 会等待后端处理完(或者超时),然后记录「后端的返回信息」到日志。所以,如果后端返回 200,就记录 200 ;如果后端放回 5XX ,那么就记录 5XX 。(但是有nginx链接池溢出的风险)
proxy_ignore_client_abort on; 这个参数后面又从nginx注释了,如果真的是服务端有某些接口响应有问题,这个参数会引起连接不能释放,最后可能拖垮服务端,建议只在出现问题的时候,作为排查临时使用。
如果超时(默认60s,可以用 proxy_read_timeout 设置),Nginx 会主动断开连接,记录 504
注:只在做反向代理的时候加入,作为其他服务器的时候,关闭为好,默认设置是关闭的!
三、502问题描述:
问题背景
我们这边是一个基于Nginx的API网关(以下标记为A),最近两天有调用方反馈,偶尔会出现502错误,我们从Nginx的error日志里看,就会发现有" upstream prematurely closed connection while reading response header from upstream"这么一条错误日志,翻译过来其实就是上游服务过早的关闭了连接,意思很清楚,但是为什么会出现这种情况呢。而且是在业务低峰出现这种情况(也只是小概率的出现),在业务高峰的时候没有出现这种情况,而且上游服务方(以下标记为B)说出问题的请求他们那边没有收到,也就是没有任何记录,这就比较诡异了。测试环境不知道如何去复现,也就不好排查。
排查过程
1、在服务器上开启tcpdump抓包 tcpdump -nps0 -iany -w /tmp/20180617.pcap net [ip] and net [ip],如果不知道tcpdump怎么使用的同学可以百度一下。![]()
2、在nginx的error.log中观察到到有两条" upstream prematurely closed connection while reading response header from upstream"错误日志,分别是2018/06/07 20:41:27和2018/06/08 09:10:46两个时间点,如下图
3、然后查看抓包数据,找到了对应时间点的包数据,从这个可以看出,A向B发送了一个1060-2143的包,,而服务端发送了一个Fin断开连接。为什么服务端会断开连接了,我们不得而知。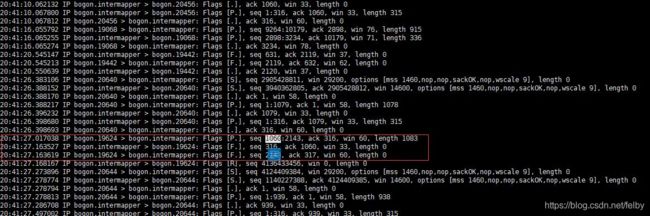
4、上一步A发送包首字节数是1060,那必然前面肯定发送过包,那我们继续往上查,发现了如下图所示的现象。在20:40:22的时候3次握手建立连接并发送了第一个包;而且也查了在20:40:22到20:41:27中间这条长连接没有发送任何包
5、和B沟通,他们的Nginx中的keepalive_timeout配置为65秒,keepalive_timeout这个配置的意思是说长连接保持的时间,如果没有任何数据传输的话,超过这个时间,服务端会关闭这个连接。那这就对上了,说明在这65秒没有任何数据传输,也正好在这个点,A向B发送了数据,而B关闭了这个连接,于是就出现了上面的现象。
6、当然这是我根据抓包分析出来的结果,我也自己模拟了这种情况,写了一个定时任务,每隔一分钟向第一台nginx发送请求,转发到第二台nginx上。第二台nginx的keepalive_timeout配置为60,在发送第七次的时候,出现了同样的问题,nginx打印同样的错误日志,抓包的结果也和上述情况一致。验证了我上述的分析过程。
问题总结
1、如果系统并发量不大,没有必要开启长连接,有两种方式,一、第一台nginx可以去除proxy_http_version 1.1; proxy_set_header Connection “0”;这两个配置;二、第二台nginx的keepalive_timeout可以配置为0(默认是75)。
2、上述问题我的解决方案是:暂时调大keepalive_timeout的值,先观察,但很有可能还是会有这个问题。
后记
1、网络问题的排查过程是很痛苦了,再一次验证了基础知识的重要性。
2、偶然报出的问题,一定不要忽视,说不定以后就是系统的瓶颈
四、Nginx 502 错误原因
1、服务器已关闭
如果您的后端服务器(不是反向代理服务器)因请求过多而过载,并且出现故障,则Nginx将返回502 Bad gateway error。如果您的服务器由于错误的代码,插件和模块而停机,也可能发生这种情况。
2、服务器频繁重启
如果您的后端服务器配置不正确,则它可能会重复启动并导致Nginx给出502 Bad Gateway响应。
3、网络问题
由于网络问题(例如DNS解析问题,路由问题或防火墙阻止服务器),也会发生这种情况。
二、Nginx 502 解决方案
1、清除浏览器缓存并刷新页面。
2、检查DNS是否正确传播。
3、检查服务器上的负载,如果负载过大,请进行修复。
4、检查Nginx错误日志。
5、检查防火墙中端口80/443是否被阻止
6、检查并确认Nginx错误日志上是否存在任何连接超时错误。
7、在Nginx conf上进行必要的更改,然后重新启动Nginx。
参考:
服务器排障 之 nginx 499 错误的解决_51CTO博客_nginx 499解决办法