搭建Hadoop开发环境(全过程)
文章目录
-
- 一、VMware环境准备
- 1.安装VMware
- 2.配置网络
- 二、配置Java Hadoop环境
- 1.xftp连接虚拟机
- 2.上传java hadoop压缩包到虚拟机
- 3.配置环境变量
- 三、完全分布式
- 1.修改配置文件
- 2.克隆虚拟机
- 3.设置主机名
- 4.修改网络地址
- 5.配置映射关系
- 6.免密登录
- 7.配置节点
- 8.格式化虚拟机
- 9.启动hadoop
- 三、Hadoop测试
- 1.初识Hadoop目录
- 2.hadoop管理界面
- 3.WordCount 案例
一、VMware环境准备
1.安装VMware
在官网下载安装包安装好VMware,输入密钥,激活软件(密钥可以在网上可以在网上搜索)
新建虚拟机

选择Linux操作系统和centos7版本

给虚拟机命名

配置虚拟机磁盘 设置虚拟机最大磁盘大小20GB

在自定义硬件中给虚拟机安装centos-7-x86-64-minimal-1708.ios映像文件


查看虚拟机信息 完成安装!开始安装centos
配置虚拟机


设置root密码 创建用户
完成安装
输入刚刚设置的用户名 密码就可以登录了

2.配置网络
获取root

关闭防火墙
systemctl status firewalld //查看防火墙

systemctl stop firewalld //停止防火墙
systemctl disable firewalld //彻底关闭防火墙

关闭selinux防火墙:
vi /etc/sysconfig/selinux
先把SELINUX改为disable
按“i”进入编辑模式 更改之后按esc键退出编辑模式 然后输入“:wq”保存后退出

通过配置ip地址 网关 子网掩码 ,主机虚拟网卡VMware network adapter vmware8 连接到vmnet8虚拟机交换机上,然后VMware虚拟机NET模式借助虚拟NET设备和虚拟HDCP服务器,使得虚拟机可以联网
设置VMware Network Adapter VMnet8 的ipv4

设置VMware网络
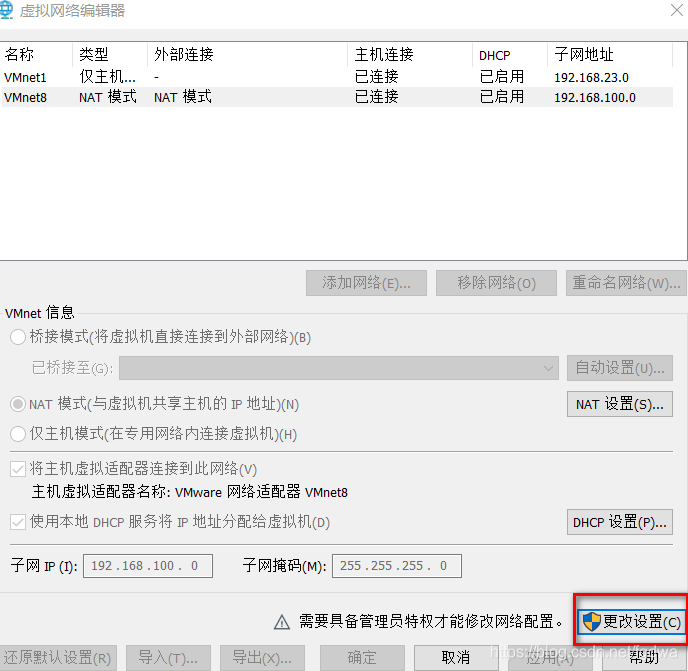

vi /etc/sysconfig/network-scripts/ifcfg-ens33 //设置VMware主机IP地址

改为:
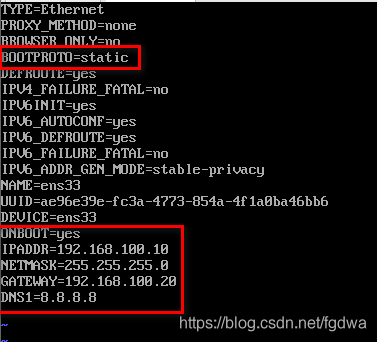
BOOTPROTO=static
ONBOOT=yes
IPADDR=192.168.100.10
NETMASK=255.255.255.0
GATEWAY=192.168.100.20
DNS1=8.8.8.8
BOOTPROTO:是获取的ip地址类型,static和none为静态地址。dhcp为静止获取IP地址。
ONB:设置网卡是否在Linux系统启动时激活,一般设置为yes
IPADDR=本机IP地址
NETMASK:子网掩码
GATEWAY:网关
DNS1:首选DNS服务器
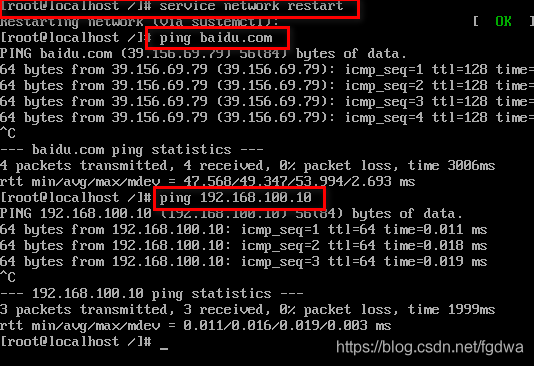
service network restart //重启网络
通过ping baidu.com检测外网环境
ping 虚拟机ip地址检测内部网络环境
二、配置Java Hadoop环境
1.xftp连接虚拟机

2.上传java hadoop压缩包到虚拟机
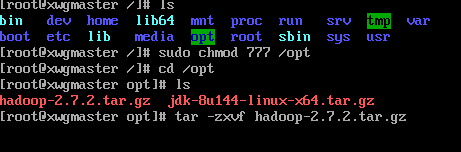
sudo chmod 777 /opt //将opt目录权限修改为可读可写可执行

通过xftp软件直接将java hadoop压缩包复制到虚拟机的/opt目录下

在当前目录下执行命令
tar -zxvf 压缩包名称
分别解压jdk和hadoop文件到当前目录下

rm -rf 文件名 //删除压缩包
mv 文件名 修改成的文件名
删除压缩包 然后重命名文件为 hadoop jdk


3.配置环境变量
vi /etc/profile //配置java hadoop 环境变量
在文件的最下面配置环境变量:
## set java environment
export JAVA_HOME=/opt/jdk
export PATH=$PATH:$JAVA_HOME/bin
##set hadoop environment
export HAOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

source /etc/profile //使刚刚配置的文件生效
java -version
hadoop version //查看环境

完成安装!
三、完全分布式
1.修改配置文件
hadoop-env.sh
sudo chmod 777 /opt/hadoop/etc/hadoop/hadoop-env.sh //将目录权限修改为可读可写可执行
然后在xftp里面的/opt/hadoop/etc/hadoop目录下进行操作,鼠标右键用文档编辑器hadoop-env.sh文件 然后直接在#the java implement to use 下面改为export JAVA_HOME=/opt/jdk(在虚拟机安装的jdk目录)然后保存!

export JAVA_HOME=/opt/jdk
core-site.xml
跟上面的操作一样 在虚拟机先输入命令获取每个文件的权限先,再在xftp软件中直接修改相应的文件,在文件的configuration /configuration中添加文件(中文注释的不要复制进去):

<property>
<name>fs.defaultFS</name>
<value>hdfs://xwgmaster:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件存放目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
然后去虚拟机创建目录
mkdir /opt/hadoop/hadoopdata //创建目录
下面的三个文件跟上面的操作一样 先在虚拟机输入命令获取相应文件名的权限 再直接在xftp软件中直接修改文件就可以了
hdfs-site.xml
<!—hadoop集群默认的副本数量是3 但是现在只是在单节点上进行伪分布式安装 无需保存3个副本 该属性的修改值为1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
mapred-site.xml
先修改文件名:
mv mapred-site.xml.template mapred-site.xml
<!—Mapreduce是运行在yarn架构上的 需要进行特别声明-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
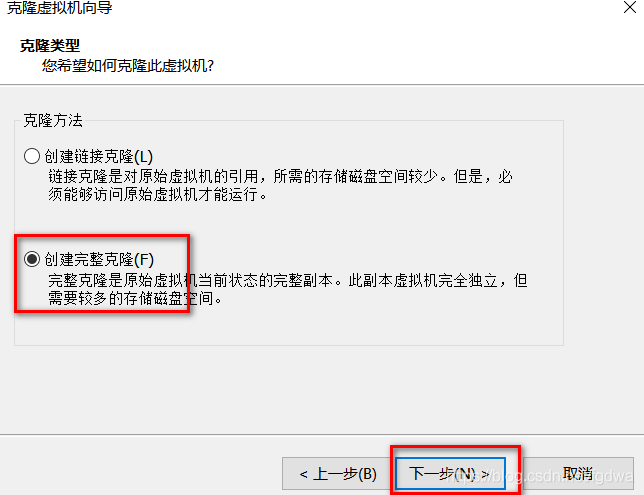
2.克隆虚拟机
右键虚拟机-管理-克隆-下一步:



3.设置主机名
vi /etc/sysconfig/network //设置主机名
NETWORK=yes
HOSTNAME=主机名

vi /etc/hostname

主机名
重置虚拟机就可以显示修改成的主机名了
其它两台虚拟机主机名设置为xwgslave1 xwgslave2
4.修改网络地址
将xwgslave xwgslave的IP地址 分别更改为
192.168.100.111
192.168.100.112


service network restart //每次设置完都要重置一下网络
5.配置映射关系
通过修改主机名和ip地址 使虚拟机通过计算机名也可以进行网络访问(三个虚拟机都要设置)
vi etc/hosts

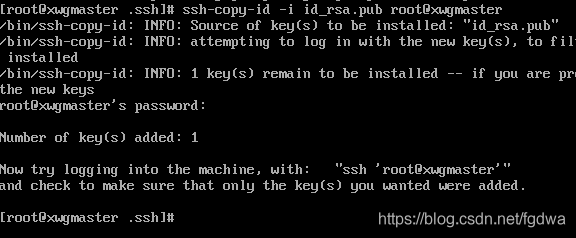
6.免密登录
ssh-keygen -t rsa //生成密钥

cd /root/.ssh
ll -a //在该目录下查看隐藏文件

ssh-copy-id -i id_rsa.pub root@主机名 将密钥发送到目标主机
ssh-copy-id -i id_rsa.pub root@xwgmaster
ssh-copy-id -i id_rsa.pub root@xwgslave1
ssh-copy-id -i id_rsa.pub root@xwgslave2
7.配置节点
在master配置节点
/opt/hadoop/etc/hadoop下的slaves文件
输入:
xwgmaster
xwgslave1
xwgslave2

8.格式化虚拟机
在xwgmaster中格式化系统
hadoop namenode-format
9.启动hadoop
start-all.sh
然后在三台虚拟机输入jps查看是否有节点显示:
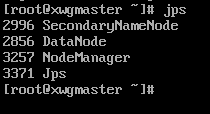
成功!!!
三、Hadoop测试
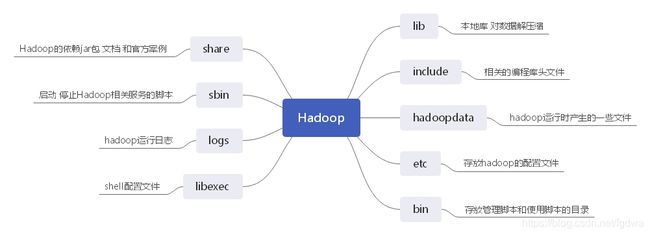
1.初识Hadoop目录
通过xftp可以看到远程虚拟机的hadoop目录

2.hadoop管理界面
在浏览器输入外网ip加端口号(http://192.168.56.210:50070)就可以登录hadoop管理页面 查看hdfs集群信息


3.WordCount 案例
在虚拟机实现文件上传 利用jar包统计单词计数的功能
测试hdfs和mapreduce(hadoop的两大核心模块)
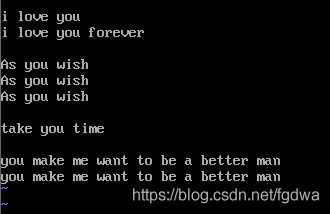
先在虚拟机本地创建文件:
cd /opt/hadoop //先进入hadoop目录下
ls //查看该目录下的文件
mkdir 文件夹名 //创建一个新文件夹
touch 文件名//创建一个新文件
vi 文件名 //对文件进行编辑

按i进入编辑模式 输入单词 然后按esc退出编辑 输入“:wq”保存后退出
将centos的本地文件上传到hdfs:
Hadoop fs -put /opt/Hadoop/test/wcinput /
//Hadoop fs -put 上传指令 目标文件地址 上传的目标地址



然后再进入/opt/hadoop目录:
bin/Hadoop jar share/Hadoop/mapreduce/Hadoop-mapreduce-examples-2.7.2.jar wordcount /wcinput /wcoutput
![]()
生成了一个名为wcoutput的文件
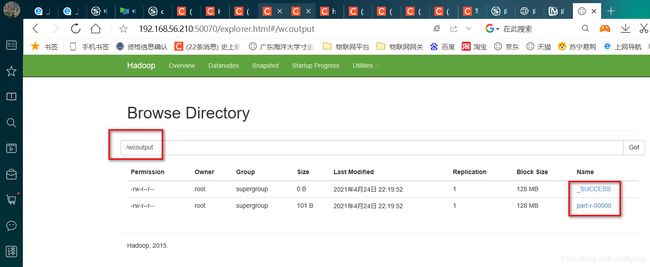
然后在虚拟机执行:
Hadoop fs -cat /wcoutput/part-r-00000
