区块链共识机制技术一——POW(工作量证明)共识机制
什么是共识机制
所谓“共识机制”,是通过特殊节点的投票,在很短的时间内完成对交易的验证和确认;对一笔交易,如果利益不相干的若干个节点能够达成共识,我们就可以认为全网对此也能够达成共识。
区块链作为一个去中心化的分布式账本系统,然而在实际运行中,怎么解决因为去中心化后,保证整个系统能有效运行,各个节点诚实记账,在没有所谓的中心的情况下,互相不信任的个体之间就交易的合法性达成共识的共识机制。
共识机制的目标
区块链作为一种按时间顺序存储数据的数据结构,可支持不同的共识机制。共识机制是区块链技术的重要组件。区块链共识机制的目标是使所有的诚实节点保存一致的区块链视图,同时满足两个性质:
1)一致性。所有诚实节点保存的区块链的前缀部分完全相同。
2)有效性。由某诚实节点发布的信息终将被其他所有诚实节点记录在自己的区块链中。
为什么需要共识机制?
在分布式系统中,各个不同的主机通过异步通信方式组成网络集群。为了保证每个主机达成一致的状态共识,就需要在主机之间进行状态复制。异步系统中,可能会出现各样的问题,例如主机出现故障无法通信,或者新能下降,而网络也可能发生拥堵延迟,类似的种种故障有可能会发生错误信息在系统内传播。因此需要在默认不可靠的异步网络中定义容错协议,以确保各主机达成安全可靠的状态共识。所以,利用区块链构造基于互联网的去中心化账本,需要解决的首要问题是如何实现不同账本节点上的账本数据的一致性和正确性。
这就需要借鉴已有的在分布式系统中实现状态共识的算法,确定网络中选择记账节点的机制,以及如何保障账本数据在全网中形成正确、一致的共识。
如何评价一个共识机制的优劣:
- 安全性:能否有效防止二次支付,私自挖矿
- 扩展性:当系统成员和待确认交易数量增加时,所带来的系统负载和网络通信量的变化,通常以网络吞吐量来衡量
- 性能效率:每秒可以处理的交易数量
- 资源消耗:达成共识过程中,所要消耗的CPU、内存等计算资源
区块链分类
在开始进行共识机制梳理前,首先需要对目前的区块链进行一个简单的了解。目前市面上根据共识算法及应用场景把区块链分为三类:公有链、联盟链和私有链。
公有链,是一个完全开放的分布式系统。公有链中的节点可以很自由的加入或者退出,不需要严格的验证和审核,比如比特币、以太坊、EOS等。共识机制在公有链中不仅需要考虑网络中存在故障节点,还需要考虑作恶节点,并确保最终一致性。
联盟链,是一个相对开放的分布式系统。对于联盟链,每个新加入的节点都是需要验证和审核的,比如Fabric、BCOS等。联盟链一般应用于企业之间,对安全和数据的一致性要求较高,所以共识机制在联盟链中不仅需要考虑网络中存在故障节点,还需要考虑作恶节点,同时除过确保最终一致性外,还需要确保强一致性。
私有链,是一个封闭的分布式系统。由于私有链是一个内部系统,所以不需要考虑新节点的加入和退出,也不需要考虑作恶节点。私有链的共识算法还是传统分布式系统里的共识算法,比如zookeeper的zab协议,就是类paxos算法的一种。只考虑因为系统或者网络原因导致的故障节点,数据一致性要求根据系统的要求而定。
共识机制有哪些?
常见的共识就机制包括:POW(工作量证明机制)、POS(权益证明机制)、POW+POS(混合共识机制)、DPOS(股份授权证明)等等,另外还有Pool验证池、Ripple瑞波共识协议、PBFT(使用拜占庭容错算法)等等。今天先介绍POW共识机制。
POW工作量证明共识机制
一、前言
PoW(Proof of Work),即工作量证明,闻名于比特币,俗称"挖矿”。PoW是指系统为达到某一目标而设置的度量方法。简单理解就是一份证明,用来确认你做过一定量的工作。监测工作的整个过程通常是极为低效的,而通过对工作的结果进行认证来证明完成了相应的工作量,则是一种非常高效的方式。PoW是按劳分配,算力决定一起,谁的算力多谁记账的概率就越大,可理解为力量型比较。以下内容基于比特币的PoW机制。
工作量证明(PoW)通过计算一个数值( nonce ),使得拼揍上交易数据后内容的Hash值满足规定的上限。在节点成功找到满足的Hash值之后,会马上对全网进行广播打包区块,网络的节点收到广播打包区块,会立刻对其进行验证。
如何才能创建一个新区块呢?通过解决一个问题:即找到一个nonce值,使得新区块头的哈希值小于某个指定的值,即区块头结构中的“难度目标”。
如果验证通过,则表明已经有节点成功解迷,自己就不再竞争当前区块打包,而是选择接受这个区块,记录到自己的账本中,然后进行下一个区块的竞争猜谜。网络中只有最快解谜的区块,才会添加的账本中,其他的节点进行复制,这样就保证了整个账本的唯一性。
假如节点有任何的作弊行为,都会导致网络的节点验证不通过,直接丢弃其打包的区块,这个区块就无法记录到总账本中,作弊的节点耗费的成本就白费了,因此在巨大的挖矿成本下,也使得矿工自觉自愿的遵守比特币系统的共识协议,也就确保了整个系统的安全。
在了解pow共识机制前,我们先了解下比特币区块的结构,下图是比特币区块的结构图:
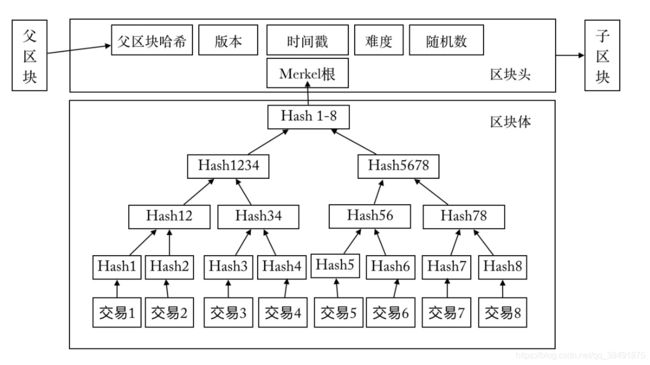
从图上可知,比特币的结构分为区块头和区块体,其中区块头细分为:
父区块头哈希值:前一区块的哈希值,使用SHA256(SHA256(父区块头))计算。占32字节
版本:区块版本号,表示本区块遵守的验证规则。占4字节
时间戳:该区块产生的近似时间,精确到秒的UNIX时间戳,必须严格大于前11个区块时间的中值,同时全节点也会拒绝那些超出自己2个小时时间戳的区块。占4字节
难度:该区块工作量证明算法的难度目标,已经使用特定算法编码。占4字节
随机数(Nonce):为了找到满足难度目标所设定的随机数,为了解决32位随机数在算力飞升的情况下不够用的问题,规定时间戳和coinbase交易信息均可更改,以此扩展nonce的位数。占4字节
Merkle根:该区块中交易的Merkle树根的哈希值,同样采用SHA256(SHA256())计算。占32字节
如此,细心的同学会发现,区块头总共占了80字节。
区块体除了筹币交易记录(由一棵Merkle二叉树组成)外,还有一个交易计数。
比特币的任何一个节点,想生成一个新的区块,必须使用自己节点拥有的算力解算出pow问题。因此,我们先了解下pow工作量证明的三要素。
二、POW工作量证明的三要素
工作机制
为了使区块链交易数据记录在区块链上并在一定时间内达到一致(共识),PoW提供了一种思路,即所有区块链的网络节点参与者进行竞争记账,所谓竞争记账是指,如果想生成一个新的区块并写入区块链,必须解出比特币网络出的工作量证明谜题,谁先解出答案,谁就获得记账权利,然后开始记账并将将解出的答案和交易记录广播给其他节点进行验证,自己则开始下一轮挖矿。如果区块的交易被其他节点参与者验证有效并且谜题的答案正确,就意味着这个答案是可信的,新的节点将被写入验证者的节点区块链,同时验证者进入下一轮的竞争挖矿。
这道题关键的三个要素是工作量证明函数、区块及难度值。工作量证明函数是这道题的计算方法,区块决定了这道题的输入数据,难度值决定了这道题的所需要的计算量。
1、工作量证明函数
在比特币中使用的是SHA256算法函数,是密码哈希函数家族中输出值为256位的哈希算法。
2、 区块
区块头在前言中已经做详细介绍,这里我们就介绍下区块体的 Merkle树算法:
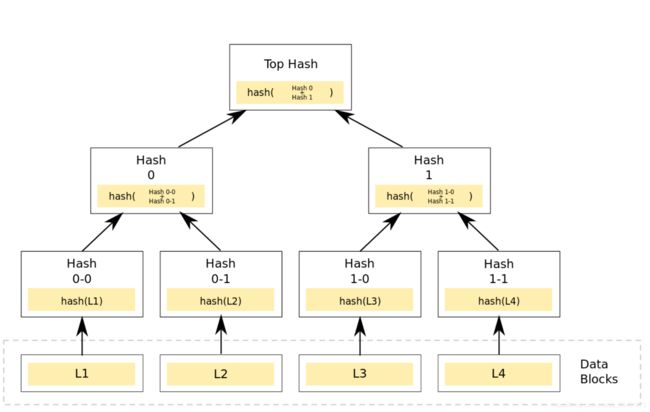
如上图所示,首先对4个交易记录L1–L4,分别计算hash(L1)–hash(L4),然后计算hash0=hash0-0+hash0-1和hash1=hash1-0+hash1-1,最后计算出根节点的hash值top hash。
3、难度值
关于难度值,我们直接看公式:
新难度值=旧难度值*(过去2016个区块花费时长/20160分钟)
tips:难度值是随网络变动的,目的是为了在不同的网络环境下,确保每10分钟能生成一个块。
新难度值解析:撇开旧难度值,按比特币理想情况每10分钟出块的速度,过去2016个块的总花费接近20160分钟,这样,这个值永远趋近于1。
目标值=最大目标值/难度值
目标值解析:最大目标值为一个固定数,若过去2016个区块花费时长少于20160分,那么这个系数会小,目标值将会被调大些,反之,目标值会被调小,因此,比特币的难度和出块速度将成反比例适当调整出块速度。
那如何计算呢?SHA256(SHA256(Block_Header)),即只需要对区块头进行两次SHA256运算即可,得到的值和目标值进行比较,小于目标值即可。
区块头中有一个重要的东西叫MerkleRoot的hash值。这个东西的意义在于:为了使区块头能体现区块所包含的所有交易,在区块的构造过程中,需要将该区块要包含的交易列表,通过Merkle Tree算法生成Merkle Root Hash,并以此作为交易列表的摘要存到区块头中。
至此,我们发现区块头中除过nonce以外,其余的数据都是明确的,解题的核心就在于不停的调整nonce的值,对区块头进行双重SHA256运算。
介绍完pow工作量证明的三要素后,我们就可以讲解下工作量证明的流程。
三、POW工作量证明流程
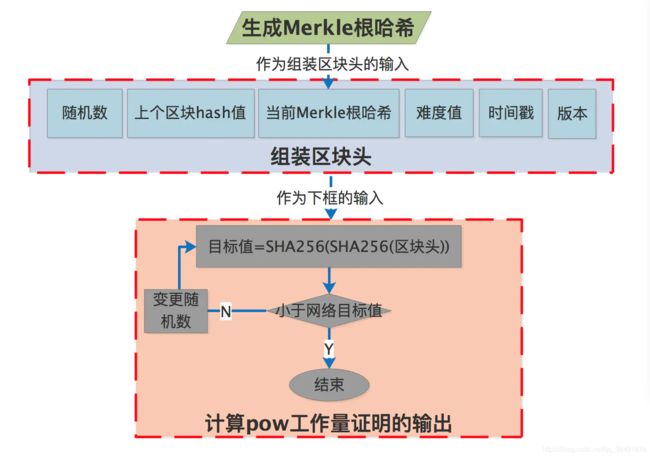
从流程图中看出,pow工作量证明的流程主要经历三步:
1.生成Merkle根哈希
生成Merkle根哈希在第二章节中的第2要素中已经有讲解,即节点自己生成一笔筹币交易,并且与其他所有即将打包的交易通过Merkle树算法生成Merkle根哈希,所以为什么说区块是工作量证明的三要素之一。
2.组装区块头
区块头将被作为计算出工作量证明输出的一个输入参数,因此第一步计算出来的Merkle根哈希和区块头的其他组成部分组装成区块头,这也就是为什么我们在前言中大费周章的去提前讲解比特币的区块头。
3.计算出工作量证明的输出
下面我们直接通过公式和一些伪代码去理解工作量证明的输出:
i. 工作量证明的输出=SHA256(SHA256(区块头))
ii. if(工作量证明的输出<目标值),证明工作量完成
iii.if(工作量证明的输出>=目标值),变更随机数,递归i的逻辑,继续与目标值比对。
注:目标值的计算见第二章节的要素3的难度值。
上面的流程图及解析即pow工作量证明的整个过程。
四、POW共识记账
前面三部分中讲解的是单节点工作量证明流程,有了这个计算流程,我们就得将其使用起来,在比特币平台中,中本聪就是运用的pow工作量证明来使全网节点达到51%及以上的共识记账,以下将介绍pow工作量证明共识是如何记账的?
首先,客户端产生新的交易,向全网广播
第二,每个节点收到请求,将交易纳入区块中
第三,每个节点通过第三章中描述的pow工作量证明
第四,当某个节点找到了证明,向全网广播
第五,当且仅当该区块的交易是有效的且在之前中未存在的,其他节点才认同该区块的有效性
第六,接受该区块且在该区块的末尾制造新的区块
大概时序图如下:

五、POW的优缺点
通过上面的描述,PoW优点很明显:
- 完全去中心化(任何人都可以加入);
- 节点自由进出,容易实现;
- 破坏系统花费的成本巨大;
关于破坏系统成本巨大可以分两层意思理解:
- 在指定时间内,给定一个难度,找到答案的概率唯一地由所有参与者能够迭代哈希的速度决定。与之前的历史无关,与数据无关,只跟算力有关。
- 掌握51%的算力对系统进行攻击所付出的代价远远大于作为一个系统的维护者和诚实参与者所得到的。
缺点也相当明显:
- 对节点的性能网络环境要求高;
- 浪费资源;
- 每秒钟最多只能做七笔交易,效率低下;
- 矿场的出现违背了去中心的初衷;
- 不能确保最终一致性;
- 比特币产量每4年减半,利益驱动性降低导致旷工数量减少从而导致比特币网络瘫痪。
六、网络攻击和链分叉
1)网络攻击
假定一个恶意节点试图双花之前的已花费的交易,攻击者需要重做包含这个交易的区块,以及这个区块之后的所有的区块,创建一个比目前诚实区块链更长的区块链。只有网络中的大多数节点都转向攻击者创建的区块链,攻击者的攻击才算成功了。由于每一个区块都包含了之前的所有区块的交易信息,所以随着块高的增加,之前的区块都会被再次确认一次,确认超过6次,可以理解为无法被修改。
考虑交易T包含在区块b1中。每个后续区块b2,b3,b4,……bn会降低交易T被修改的可能性,因为修改这些后续的区块需要更多的算力。中本聪用概率理论证明,六个区块后攻击者追赶上最长链的可能性降低到0.0002428%。在过4个或更多区块后这个可能行会降到0.0000012%。每新增一个区块bn,攻击的可能性就会以指数形式下降,很快整个攻击的可能性就会低到可以忽略的程度。
2)链分叉
所谓的链分叉,主要是由于在计算hash时,每个人拿到的区块内容是不同的,导致算出的区块结果也不同,但都是正确结果,于是,区块链在这个时刻,出现了两个都满足要求的不同区块,那旷工怎么办呢?由于距离远近、网络等原因,不同旷工看到这两个区块的先后顺序是不一样的,通常情况下,旷工会把自己先看到的区块链复制过来,然后接着在这个区块上开始新的挖矿工作,于是就出现了链分叉。
PoW解决方案:
从分叉的区块起,由于不同的矿工跟从了不同的区块,在分叉出来的两条不同链上,算力是有差别的。由于解题能力和矿工的算力成正比,因此两条链的增长速度也是不一样的,在一段时间之后,总有一条链的长度要超过另一条。当矿工发现全网有一条更长的链时,他就会抛弃他当前的链,把新的更长的链全部复制回来,在这条链的基础上继续挖矿。所有矿工都这样操作,这条链就成为了主链,分叉出来被抛弃掉的链就消失了。
能够让区块链保证唯一性的前提是:所有矿工都遵从同样的机制。当旷工遵从不同的机制时,就会出现硬分叉,这种分叉会导致资产增加,且两条链同时存在,比如BBC。