欢迎来到大数据时代-----赶快来了解一些大数据的基础知识
作者刚开始接触大数据不久,现在想通过这篇文章分享一些我学到的,我自己理解的知识;希望大家学有所获。
Hadoop离线是大数据生态圈的核心与基石,是整个大数据的入门。
linux、hadoop、hive三者形成一体,掌握这些知识就可以独立基于数据仓库是实现离线数据分析的可视化报表开发。
大数据导论:
数据是什么?
针对客观事物的描述(描述包括,数字、文字、字母、数字符号的组合、图像、影像......)
生活中的数据爆炸,例如:个人的信息,身高,年龄,性别,籍贯,姓名.....数据随处可见。。。
数据如何产生?
人为或是利用智能设备等记录数据
例如:远古时代,猎人打猎,把每天的打猎数据拿绳子记录下来;
我们平时做的笔记,写的日记,这些都算数据;
再或者,我们的手机,穿戴设备,里面记录了很多的数据,QQ消息、银行卡.......
可见:生活中充满了数据,多不胜数。
企业数据分析方向:
把隐藏在数据中的这些信息提取出来,总结规律,提供了经验,利于人类社会的发展与创新。
三大方向:
现状分析->原因分析->预测分析
一句话:数据会说话,一切以数据说话;
数据反应了当下的现状,引起我们的沉思,面对未来,我们更好地打算......
原因分析:
离线分析:针对旧的数据进行分析;例如:每一周的数据;一天过去,这一天产生的数据;这一几个小时产生的数据,离线分析对的是旧数据。面向过去,分析已经存在的数据,这种处理方式也叫做批处理。

现状分析:
实时分析:针对刚刚(数据产生的时间非常短)产生的新数据的处理,间断时间可以达到毫秒级。例如:双十一的时候,人们网上购物,京东,阿里电商平台的数据是很庞大的,通过实时分析技术可以分析人们的消费习惯,人们的兴趣,各个方面(从各个方面,各个角度分析用户)。实时分析面向当下产生的数据进行分析。
预测分析:
机器学习:
基于历史数据和当下实时产生的数据预测未来发生的事情;
侧重于数学算法运用、分类聚类关联预测....

企业中数据分析:
现状分析(当下的数据):分析后,各个部分的构成、发展、变动。
原因分析(过去的数据):分析后,做出相应的调整。
预测分析(结合数据预测未来):分析后,看到(万事万物包括在内)未来的趋势。
数据分析的流程:
其重要性体现在如何开展数据分析提供了强有力的逻辑支撑。

1、清楚需求和目标
其为分析起点,明确方向,分析框架体系化,从什么角度思量问题?如何分析?
数据分析方法论是一些营销管理类的相关理论,例如:用户行为,PEST分析法、5W2H。
2、数据采集
数据从无到有的过程,例如收集用户行为(购物,诚信,经济...)数据;
数据传输搬运的过程,比如:采集数据库数据到数据分析平台。
分类:
业务数据、日志数据、爬虫数据、互联网公开数据
对应:
RDBMS 服务器、应用日志、爬虫数据库、行业政府网站
3、数据预处理
拿到的数据可能有缺失,有违背现实情况的假数据,等,对于这些脏数据我们有对应的流程进行控制,所以首先拿到数据先要进行加工处理,形成适合分析的数据。主要包括:数据清洗、数据转化、数据提取、数据计算。
数据预处理的好处:保证数据的尽量真实性,让数据变得干净规整的结构化数据,方便后续操作。

思考:
(1)当下的企业用于分析的数据侧重于文本数据多一些还是视频、音频?
文本数据 文字不会说谎
(2)什么叫赶紧规整的结构化数据?有非结构化数据?
二维表数据,行列对应,方便操作;
通俗来说就是,格式清晰、利于解读的数据。
4、数据分析
使用适当的方法工具对处理过的数据进行的分析,提取有价值的信息,形成有效的过程;这步操作需要各种数据分析方法,还要分析人员熟悉数据分析的操作。

5、数据可视化
通过数据分析结合用价值的数据(信息),进行处理,进行展示。因为,人类对于图像的印象比起文字、声音能更好地记忆,更加深刻;
数据可视化属于数据应用的一种;
注意:数据分析的结果不只是有可视化展示,还可以有数据挖掘 如: python运用到(matplotlib/numpy/pandas)工具处理数据,将数据中的有价值信息进一步提取。
6、撰写报告
这步是数据分析的总结与呈现
把数据的起因、过程、结果及其建议完整地呈现出来,以供决策者参考决定权益。

总之:
一切围绕数据展开工作;
数据从哪里来,数据到哪里去;
核心步骤:采集、处理、分析、应用
大数据技术背景:

大数据时代已经来到!
5V大数据特点:
量、种类、价值密度、数据数据产生密度、质量
大数据的定义:
说白了:大数据就是数据太大了,数据爆炸了,太多了......
大数据应用:
大数据应用真的太广了,贯穿人类的生活,例如:交通,购物、医疗、政府管理、部队信息、科技、金融、房产、天气...
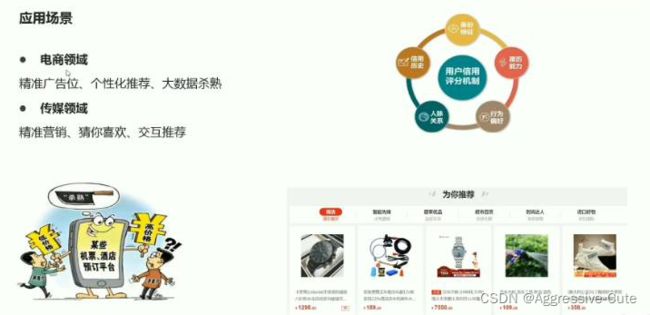



用户画像:根据你的各种信息,综合考虑,判断你的身份,你需要什么,就会向你提供什么;生成一幅画,你的兴趣、社交习惯、消费习惯、等等 给你贴标签....;精准定位:通过卫星定位 导航技术,判定你身处的位置,获取你的一切信息;推荐系统:例如:某音的大数据推荐,根据方法,猜你喜欢。购物时,弹出你想要购买的商品,跟根据推荐算法,向用户发送消费信息......
分布式和集群:
二者针都是多台机器(服务器)的环境;
区别:分布式是不同的组件;集群是相同组件的机器。
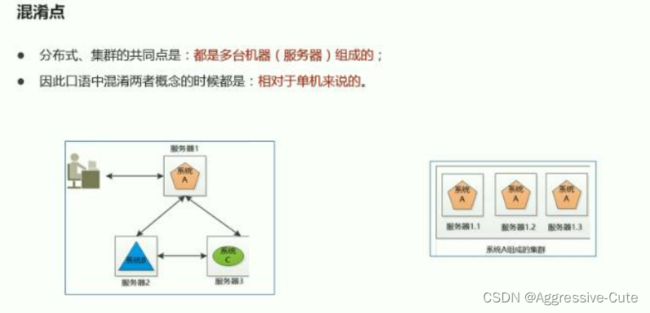
这么多的数据如何实现存储,如何计算呢?
分布式:
走进linux操作系统(Opering System):
os不用多说他的重要性了吧;
连接 硬件和软件,硬件之上,软件之下。没有操作系统,计算机就是(啥也不是)(没有装操作系统的计算机称为“裸机”)






移动设备上的操作系统:去年不是华为自主研发的鸿蒙系统嘛,瞄准5G技术。
linux之父:
linux操作系统最牛皮的还要说他的内核(最核心的技术,主要功能):

Linux的发行版:

我们熟悉的ubantu(合适个人桌面) 红帽(旗舰版)/centos(社区版)(适合服务器)
那问题来了,我们学习大数据怎样能搭建一个局域网来学习大数据呢???
准备什么?
服务器?机架?网线光纤???
其实不然,我们利用对硬态资源的虚拟就能实现,在电脑上面安装多台虚拟机,为我们模拟一个大数据处理数据的环境,分布式,集群啊都可以实现。
虚拟机下载:参考其他文章,Vmware.
我文章虽然写的很烂,但是我会坚持的!!!
下一篇文章见!
