Zookeeper集群和Hadoop集群安装(保姆级教程)
1. HA
-
HA(Heigh Available)高可用
- 解决单点故障,保证企业服务 7*24 小时不宕机
- 单点故障:某个节点宕机导致整个集群的宕机
-
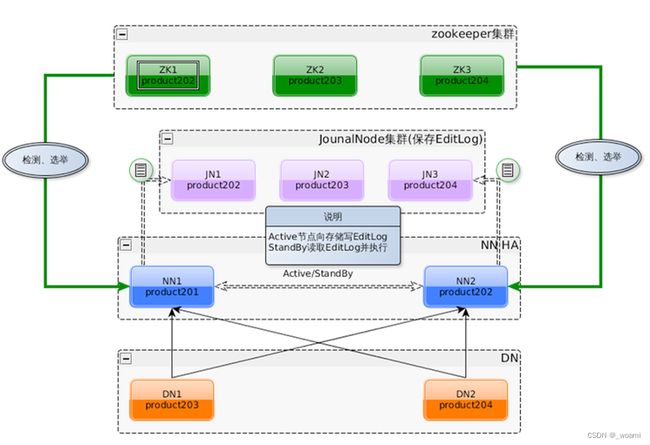
Hadoop 的 HA
- NameNode 存在单点故障的可能,需要配置 HA 解决
- 引入第二个 NameNode 作为备份
- 同步两个 NameNode 的数据
- 在第一个 NameNode 宕机后启用第二个 NameNode
-
HA架构
2. Zookeeper
-
Zookeeper 是一个分布式服务器框架
- 提供了分布式程序通用的功能
- 统一命名服务
- 状态同步服务
- 集群管理
- 分布式应用配置项
-
Zookeeper 集群
- 为了防止 Zookeeper 出现单点故障问题,
- Zookeeper 通常以集群的方式使用
- 一般为 3 或 5 个节点
-
Zookeeper 集群角色
- Leader:被选举出的,与客户端交互
- Follower:Leader 的备份,参与选举操作
-
Zookeeper 集群选举机制
- 少数服从多少
- 编号大的优先
2.1 Zookeeper 的安装
#1、上传 Zookeeper 到 /home/hadoop 目录
#2、解压 Zookeeper 到 /usr/local 目录中
sudo tar -xvf apache-zookeeper-3.6.1-bin.tar.gz -C /usr/local
#3、进入 /usr/local 目录
cd /usr/local
#4、将解压的目录重命名为 zookeeper
sudo mv apache-zookeeper-3.6.1-bin/ zookeeper
#5、修改 zookeeper 目录的拥有者为 Hadoop
sudo chown -R hadoop zookeeper
#6、进入 Zookeeper 安装目录下的 conf 目录
cd /usr/local/zookeeper/conf
#7、重命名 zoo_sample.cfg 文件为 zoo.cfg
mv zoo_sample.cfg zoo.cfg
#8、编辑环境变量
vim /home/hadoop/.bashrc
#9、在环境变量增加以下内容
export ZOOKEEPER_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin
#10、刷新环境变量
source /home/hadoop/.bashrc
2.2 Zookeeper 的使用
#启动 Zookeeper
zkServer.sh start
#查看 Zookeeper 的状态
zkServer.sh status
#关闭 Zookeeper
zkServer.sh stop

3. Zookeeper 的集群规划
| 节点主机名 | ip |
|---|---|
| master | 192.168.114.133 (自己的电脑IP,后面顺延就行) |
| slave1 | 192.168.114.134 |
| slave2 | 192.168.114.135 |
-
搭建 3 节点的 Zookeeper 集群
- 规划 主机名 和 IP
-
修改节点的主机名
-
#修改 sudo hostnamectl set-hostname master #查看 hostname
-
3.1 克隆虚拟机
1、关闭虚拟机中的所有软件并关闭虚拟机
2、在已有的虚拟机下右键点击“管理”->“克隆”
3、选择完整克隆
4、点击下一步直到去修改虚拟机信息
5、等待克隆完成后关闭操作窗口
6、重置虚拟机网卡7、使用 root 用户登录,密码为 123456
8、配置 IP 地址
#1、 编辑 IP 配置文件 vim /etc/netplan/50-cloud-init.ymal #2、修改 IP 地址为 192.168.114.134 #3、重启网络 netplan apply #9、修改主机名 hostnamectl set-hostname slave1 hostname10、照上操作再克隆出一个虚拟机
设置 IP 为 原克隆节点顺延后的ip
设置主机名为 slave2
3.2 搭建 Zookeeper 集群
#1、启动三台虚拟机,使用 Hadoop 用户登录
#2、编辑三台虚拟机的 hosts 文件
sudo vim /etc/hosts#3、在文件最后添加以下内容(ip是自己电脑上的ip)
192.168.114.133master
192.168.114.134slave1
192.168.114.135slave2#4、互相之间使用 ping 命令,验证是否配置成功
ping master、ping slave1、ping slave2#5、配置三个节点之间的免密登录
#1、删除 3 个节点上的 ssh 配置文件(3 个节点都执行)rm -rf /home/hadoop/.ssh#2、在 3 个节点上生成公钥(3 个节点都执行)
ssh-keygen#3、发送各个节点的公钥给 master(3 个节点都执行)
ssh-copy-id master#4、master 发送 authorized_keys 给 slave1 和 slave2
#仅在 master 执行scp /home/hadoop/.ssh/authorized_keys hadoop@slave1:/home/hadoop/.ssh/ scp /home/hadoop/.ssh/authorized_keys hadoop@slave2:/home/hadoop/.ssh/#6、配置 Zookeeper 的配置文件----------------------
#1、编辑 3 个节点上的 zoo.cfg 文件(3 个节点都执行) vim /usr/local/zookeeper/conf/zoo.cfg #2、修改第 12 行的 dataDir 值(3 个节点都执行) dataDir=/usr/local/zookeeper/data #3、在文件最后追加以下内容(3 个节点都执行) server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888#7、配置 Zookeeper 的节点编号-----------------------
#1、在 3 个节点上创建 data 目录(3 个节点都执行) mkdir /usr/local/zookeeper/data #2、在 data 目录下创建 myid 文件(3 个节点都执行) vim /usr/local/zookeeper/data/myid #3、在 myid 文件填入每个节点的编号(3 个节点都执行) master 节点填入 1 slave1 节点填入 2 slave2 节点填入 3
3.3 使用 Zookeeper 集群
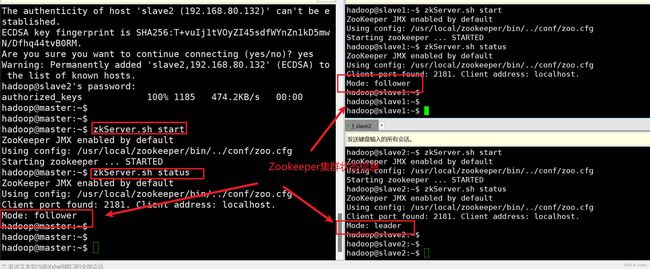
#启动 Zookeeper 集群(3 个节点都执行)
zkServer.sh start
#查看 Zookeeper 集群的状态(3 个节点都执行)
zkServer.sh status
#关闭 Zookeeper 集群(3 个节点都执行)
zkServer.sh stop
验证状态:
4. Hadoop的HA配置
4.1 搭建Hadoop的分布式集群
-
把slave1和slave2两个节点作为DataNode和NodeManager加入Hadoop集群
-
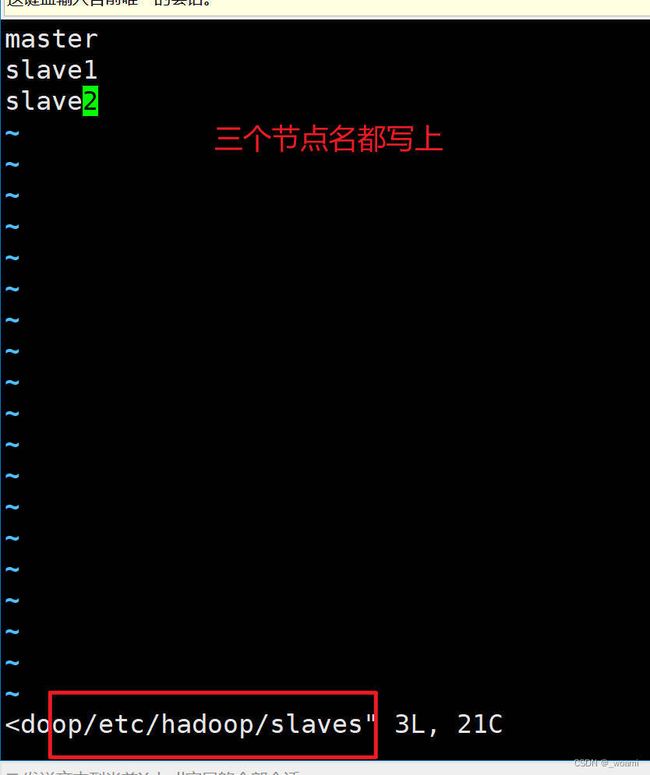
在masterj节点编辑slaves文件,设置Hadoop中的DataNode和NodeManager节点
-
vim /usr/local/hadoop/etc/hadoop/slaves -
替换localhost为以下内容:
-
master
slave1
slave2
验证状态:
- master把修改后的slaves文件发送给slave1和slave2节点
scp /usr/local/hadoop/etc/hadoop/slaves hadoop@slave1:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/slaves hadoop@slave2:/usr/local/hadoop/etc/hadoop/
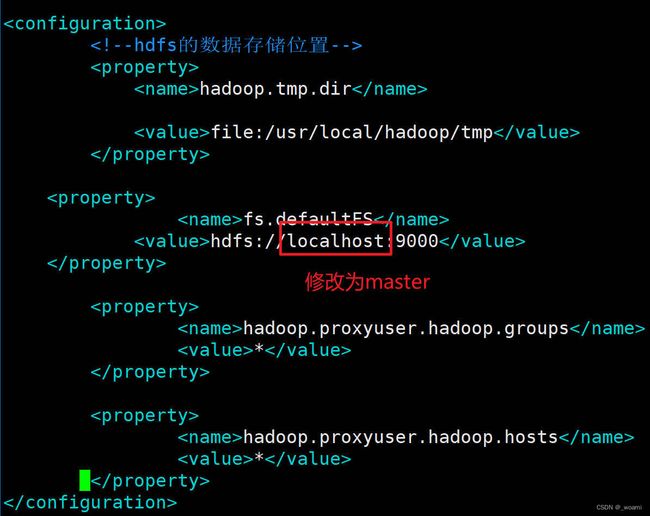
- 在master修改core-site.xml文件,使用master(master:9000)替换ip地址做为Hadoop的访问地址
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.proxyuser.hadoop.groupsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hadoop.hostsname>
<value>*value>
property>
configuration>
示例图片:
- 将修改好的core-site.xml文件发送给slave1和slave2文件
#发送给slave1
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave1:/usr/local/hadoop/etc/hadoop/
#发送给slave2
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave2:/usr/local/hadoop/etc/hadoop/
- 因为我们的slave1和slave2是从master克隆出来的,带有一些HDFS存储在master上的数据,我们需要删除。
保险起见,在三个节点执行删除操作
rm -rf /usr/local/hadoop/tmp/dfs/
- 修改完配置文件后,注意在master节点初始化namenode节点
hdfs namenode -format

- 在master节点分别使用start-dfs.sh和start-yarn.sh命令启动HDFS和Yarn。
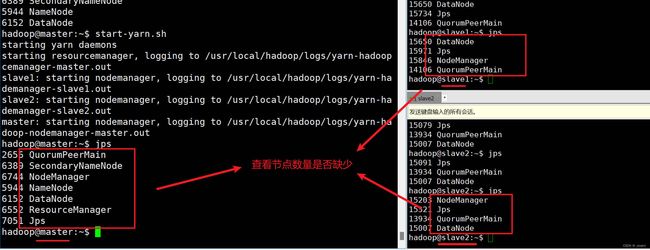
4.2 配置Hadoop的HA
背景:
Hadoop集群已经是一个包含了3个节点的分布式集群了。其中NameNode和ResourceManager都是运行在master节点上,一旦master节点宕机,整个Hadoop集群就无法对外提供服务。为了防止出现这种情况,我们可以在slave1上再准备一份备用的NameNode和ResourceManager。由Zookeeper监控master上NameNode和ResourceManager的状态,一旦不可以立即切换slave1的NameNode和ResourceManager进行工作。
- 修改master节点的core-site.xml
#1 在master修改core-site.xml文件,使用ns(集群名字)替换master做为Hadoop的访问地址
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/hadoop/tmpvalue>
property>
<property>
<name>fs.defaultFSname>
<value>hdfs://nsvalue>
property>
<property>
<name>hadoop.proxyuser.hadoop.groupsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.hadoop.hostsname>
<value>*value>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>master:2181,slave1:2181,slave2:2181value>
property>
configuration>
- 将修改好的core-site.xml文件发送给slave1和slave2文件
#发送给slave1
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave1:/usr/local/hadoop/etc/hadoop/
#发送给slave1
scp /usr/local/hadoop/etc/hadoop/core-site.xml hadoop@slave2:/usr/local/hadoop/etc/hadoop/
- 在master修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.nameservicesname>
<value>nsvalue>
property>
<property>
<name>dfs.ha.namenodes.nsname>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1name>
<value>master:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns.nn1name>
<value>master:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2name>
<value>slave1:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns.nn2name>
<value>slave1:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://master:8485;slave1:8485;slave2:8485/nsvalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/usr/local/hadoop/tmp/journalvalue>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/hadoop/tmp/dfs/datavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.nsname>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>sshfencevalue>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.qjournal.write-txns.timeout.msname>
<value>60000value>
property>
configuration>
注意理解下面每个步骤的作用
#(4) 将修改好的hdfs-site.xml文件发送给slave1和slave2文件
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml hadoop@slave1:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml hadoop@slave2:/usr/local/hadoop/etc/hadoop/
#(5) 3个节点都执行以下命令清除HDFS上存储的数据
rm -rf /usr/local/hadoop/tmp/dfs/
#(6) 3个节点都使用以下命令启动Zookeeper
#启动Zookeeper:
zkServer.sh start
#查看Zookeeper状态:
zkServer.sh status
#(7) 3个节点都使用以下命令启动JournalNode
hadoop-daemon.sh start journalnode
#(8)在master上格式化NameNode,在master使用以下命令:
#注意仅仅是master节点!!!!
hdfs namenode -format
#看到格式化成功的标志再进行后面操作!!!
#看到格式化成功的标志再进行后面操作!!!
#看到格式化成功的标志再进行后面操作!!!

#(9)启动master上的NameNode,在master使用以下命令:
#注意仅仅是master节点!!!!
hadoop-daemon.sh start namenode
#(10) 同步master上NameNode的数据到slave1,在slave1使用以下命令:
#换节点了,注意是slave1节点!!!!
#执行完毕后同样有和上面类似的格式化成功的信息,检查
hdfs namenode -bootstrapStandby
#(11) 关闭master上的NameNode,在master使用以下命令:
#回到master节点了!!!!
hadoop-daemon.sh stop namenode
#(12) 在master初始化Zookeeper监控工具,在master使用以下命令:
hdfs zkfc -formatZK
#(13) 安装切换NameNode状态的psmisc软件,在master和slave1使用以下命令:
sudo apt-get install psmisc
#(14) 启动hdfs验证NameNode的HA,在master使用以下命令:
start-dfs.sh
4.3 验证Hadoop的HA
#(1) 启动Zookeeper集群,在3个节点都执行以下命令:
zkServer.sh start
#(2) 启动Hadoop集群,在master节点执行以下命令:
start-dfs.sh
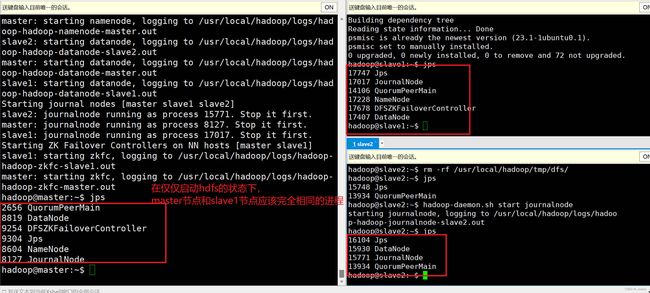
#(3) 查看各个节点的进程,在3个节点都执行以下命令:
jps
验证状态:
此时的状态是启动了,hdfs,Zookeeper
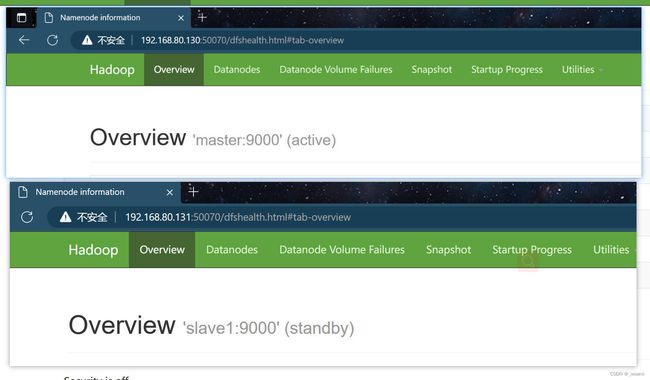
(4) 在浏览器访问HDFS的监控页面,分别输入以下地址:
http://(master的ip):50070
http://(slave1的ip):50070
我们可以看到现在master上的NameNode处于active状态,slave1上的NameNode处于standby状态,
- 现在我们模拟master的NameNode宕机,验证是否可以切换slave1的NameNode为active状态。
- 通过使用jps命令查询出NameNode对应的进程ID是8604,使用kill -9 8604命令杀死NameNode进程,模拟master宕机。

- 等待几秒钟,然后再次访问slave1的监控页面,可以发现slave1的NameNode已经切换为active状态,接替master的NameNode为集群提供服务。
