ElasticSearch —— 中级介绍(三)
倒排索引(全文检索底层采用的是倒排索引实现的)
为什么倒排索引比数据库中B-tree树查询效率还要快?
1.正排索引: 由文档指向关键词
文档--> 单词1 ,单词2
单词1 出现的次数 单词出现的位置; 单词2 单词2出现的位置 ...
2.倒排索引: 由关键词指向文档
单词1--->文档1,文档2,文档3
单词2--->文档1,文档2
ElasticSearch 高级查询
先初始化点数据
PUT /mymayikt/user/1
{
"name":"xiaoming",
"age":29,
"sex":1,
"car":"宝马5系"
}
PUT /mymayikt/user/2
{
"name":"xiaohua",
"age":28,
"sex":1,
"car":"奥迪a6"
}
PUT /mymayikt/user/3
{
"name":"xiaozhang",
"age":30,
"sex":1,
"car":"大众朗逸"
}
PUT /mymayikt/user/4
{
"name":"xiaochen",
"age":29,
"sex":1,
"car":"大众速腾"
}
PUT /mymayikt/user/5
{
"name":"xiaoshui",
"age":27,
"sex":1,
"car":"宝沃BX5"
}
GET /mymayikt/user/4
###POST 创建文档
POST /mymayikt/user
{
"name":"xiaomei",
"age":29,
"sex":1,
"car":"宝马5系"
}
###根据POST自动生成的id查询文档
GET /mymayikt/user/qv3Y6HEBaA-jnACp8AXO
### 查询当前mymayikt 索引下面类型为user 的所有文档
GET /mymayikt/user/_search
###根据多个id查询对应的文档
GET /mymayikt/user/_mget
{
"ids":[1,2]
}
##查询年龄为29岁的
GET /mymayikt/user/_search?q=age:29
##查询年龄为22岁到40岁之间的 ,并且按照倒叙排列 from size 就是分页 0 - 2 条数据
GET /mymayikt/user/_search?q=age[22 TO 40]&sort=age:desc&from=0&size=2什么是DSL语言?
ES中查询请求有两种方式,一种是简易版的查询(上面使用的都是简易版的查询,相当的繁琐也不美观),另外一种是使用json完整的请求体,叫做结构化查询(DSL)
DSL查询是POST过去一个json,由于POST的请求是json格式的,所以存在很多灵活性,也有很多形式。
#####DSL
####term查询是精确匹配
GET /mymayikt/user/_search
{
"query":{
"term":{
"name":"zhouqm"
}
}
}
####like match支持分词查询
GET /mymayikt/user/_search
{
"match":{
"term":{
"name":"zhouqm"
}
}
}
####过滤年龄大于20,小于40岁
GET /mymayikt/user/_search
{
"query":{
"bool":{
"must":[{
"match_all":{}
}],
"filter":{
"range": {
"age": {
"gte": 20,
"lte": 40
}
}
}
}
}
}什么是中文分词器?
因为elasticsearch中默认的标准分词器对中文不是很友好,会将中文词语拆分成一个一个中文的汉子。因此引入中文分词器(es-ik插件)。
注意:es-ik分词器插件一定要与elasticsearch版本一致。
地址:https://github.com/medcl/elasticsearch-analysis-ik/releases下载压缩包 。找到E:\java\ES\elasticsearch-7.6.0\plugins 新建ik文件夹,将压缩的文件解压放入ik文件夹中。重启服务即可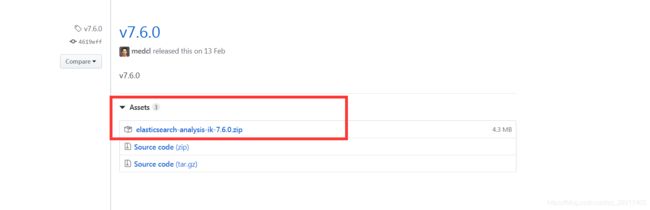

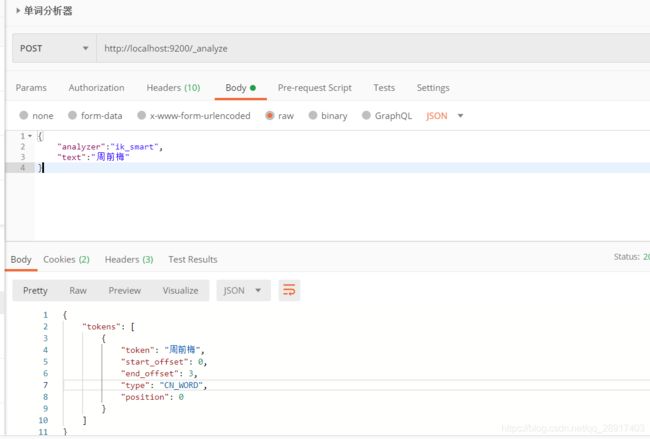
如何扩展单词分析器的字典呢?
打开E:\java\ES\elasticsearch-7.6.0\plugins\ik\config\IKAnalyzer.cfg.xml 文件,
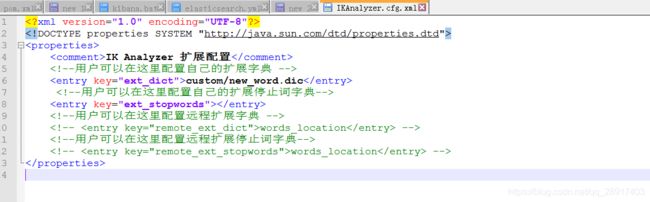
E:\java\ES\elasticsearch-7.6.0\plugins\ik\config\custom 目录下创建new_word.dic 在里头填入热词。
注意:这里好多人喜欢新建txt改名字存入热词。重启es服务热词是不生效的。可能是编码格式问题,大家注意下就可以了。