回归问题的置信区间AUC_样本不平衡问题操作手册

引言
何谓样本不平衡——简单来说就是数据集中负样本的数量远远大于正样本的数量。在这个情况下,模型就会倾向于把样本预测为负样本,因为这是最便捷的降低损失、提高模型准确率的方法。例如:有一个正样本数量为1,负样本数量为99的数据集,模型就算无脑地把全部样本预测为负样本也能达到99%的准确度,试想有这么一个分类器,每次我们把数据喂‘给它时,在不调整阈值的情况下,它都倾向于把测试集的样本预测为负样本,你觉得这样的分类器还会是一个好的分类器吗?
下面以一个真实业务数据集为例,展现一下提高分类器表现的过程。

分类器评估标准
首先最重要的是要意识到准确率accuracy已经不再适用。
至于评估分类器的其他指标如召回率(Recall),精确度(Precision)等虽然可以直观得衡量模型捕捉少数类样本的能力,但是在不同的概率阈值下,它们都会发生改变,我们可以通过改变概率阈值达到自己的目的——“如果我们需要尽可能地捕捉少数类即提高召回率,可以适当得降低概率阈值;相反,如果我们希望捕捉少数类的命中率越高越好即提高精确度,我们可以适当得提高概率阈值。”
| 预测值=1 | 预测值=0 | |
|---|---|---|
| 真实值=1 | 11 | 10 |
| 真实值=0 | 01 | 00 |
AUC或者是P-R曲线的面积是可参考的综合指标。
1.Precision-Recall曲线,因为同一个分类器下,使用不同的概率阈值对同一个测试集的样本进行预测,随着概率阈值的变化,Precision(精确度)和Recall(召回率)是成反比的,所以P-R曲线呈现出一个抛物线,不同的分类器有不同的抛物线,计算该抛物线下的面积是评估标准之一;

2.其次是ROC曲线,它的思想和P-R曲线类似,基于不同阈值下,分类器的FPR(FPR=1-Precision)和Recall是成正比的,所以在图像上就表现为一个正比例曲线,该曲线下的面积就是auc的大小。


“ROC的曲线越靠近左上角,auc的值就越大,我们可以通过调整相应的概率阈值,使得FPR尽可能小的同时(Precision尽可能大),Recall的值也尽可能大;召回率Recall较高,说明分类器可以把为数不多的正样本都找出来,当特异度FPR较小,说明我们分类器并没有误伤多数类样本,因为Precision = 1-FPR,所以精确度Precision也会较高,说明分类器预测为少数类的样本中,确实为少数类的样本数量较多,这样,我们就可以大胆得说这是一个不错的分类器了”
3.G-Mean(recall和precision的几何平均数),F1-score(precision和recall的调和平均数)也是可参考的评估标准
数据集介绍
| 负样本数量 | 正样本数量 | 总数 | |
|---|---|---|---|
| 训练集 | 1336617 | 1797 | 1338414 |
| 测试集 | 572912 | 693 | 573605 |
“训练集的正负样本比例约为1:743,测试集的正负样本比例约为1:826;训练集的样本数量大约是测试集的2倍“
Baseline
其实分类算法——逻辑回归、支持向量机等在训练模型有帮助解决样本不平衡问题的参数——class_weight,虽然理论上单个分类器的效果远不如集成学习器,但可以简单感受一下这些参数能否带来改变。 注:逻辑回归、支持向量机因为涉及梯度、距离的计算,所以在训练之前需要对连续性特征进行标准化,也可以提高运算速度
结果汇总
| Model | 训练集auc | 测试集auc | 训练集PR | 测试集PR |
|---|---|---|---|---|
| Gradient Boosting Trees | 87.89 | 86.02 | 8.59 | 1.66 |
| Random Forest_withoutbalanced | 100.0 | 69.54 | 100.0 | 0.92 |
| Logistic Regression_withbalanced | 82.31 | 82.81 | 0.92 | 0.76 |
| Logistic Regression_withoutbalanced | 79.32 | 80.54 | 0.77 | 0.62 |
| Random Forest_withbalanced | 100.0 | 65.01 | 100.0 | 0.49 |
实践证明,使用逻辑回归的class_weight = ‘balanced’对auc和PR值都略有提升;但使用此参数后随机森林的表现反而降低了。
关于class_weight & scale_pos_weight
class_weight——支持向量机、逻辑回归
我们先看看逻辑回归的损失函数——(支持向量机同理,只不过是交叉熵损失换成了Hinge Loss)

当正则化系数C逐渐变小,正则化强度就会逐渐增大,参数的θ的取值就会逐渐减小,相对应的预测概率值就会减小 ——“因为,当正则项时,和正则项的比是1:1,当C减小,相对地,部分就会增大,损失函数对它的惩罚就加重,导致就会压缩得越来越小“。
(注意这里的正则化系数的位置,不同于之前的
逻辑回归class_weight参数的底层原理就是在训练模型时根据正负样本的数量改变C的大小,其中,正样本的数量较少,则对应的C的取值较大,从而对θ的压缩程度较小,则相应得能提高预测概率值。
scale_pos_weight——XGBoost
XGBoost中存在着调节样本不平衡的参数scale_pos_weight,通常我们在参数中输入的是负样本量与正样本量之比
底层原理:通过scale_pos_weight改变了正负样本的权重,进而改变了正负样本损失函数的大小,最终改变了样本的概率预测值 wi。
#源码截取:
w = 1 #默认是1
if (label == 1.0f) {
w *= scale_pos_weight;
}
# w = scale_pos_weight,即负样本的数量/正样本的数量
# 改变了损失函数,即改变了损失函数的一阶导和二阶导大小,落到每个叶结点的概率预测值也随之改变。
_out_gpair[_idx] = GradientPair(Loss::FirstOrderGradient(p, label) * w,
Loss::SecondOrderGradient(p, label) * w);XGBoost第t棵树的损失函数:
样本落在第t棵树的第j个叶子节点的概率预测值为:
“其中是损失函数关于上一棵树的预测值的的一阶导,是损失函数关于上一棵树的预测值的二阶导,当正样本的损失函数发生改变,相应的叶子节点的预测值也会发生改变。”
本质上说,scale_pos_weight参数也是通过调节样本的预测概率值来改变预测结果,当我们需要提高模型的评估标准 ——如 auc、召回率recall的大小等,可以通过调整scale_pos_weight参数达到我们的目的;但是,假如需要确切了解每个样本为正样本的可能性大小时,不宜使用scale_pos_weight参数。
改进方法一:XGBoost
经验上来看,XGBoost的效果应该会优于GBDT,实际效果是不是这样呢?
调整XGBoost的参数
能够调整的参数如下:
第一步:学习率和迭代次数
1.eta/learning_rate(学习率):0.1#为了加快收敛速度,先设定一个较大的值;
2.n_estimators/num_round(迭代次数):100~1500
第二步:调整树的参数(主要为了解决过拟合问题)
1
1.1 max_depth(树的深度):4-9
1.2 min_child_weight:3-16;
2
2.1 gamma:
2.2 reg_lambda(L2正则项):1~10
2.3 reg_alpha(L1正则项):1~10
3
3.1 subsample(从样本进行采样的比例):0.5~1.0
3.2 colsample_bytree(构造每一棵树的随机抽样出的特征占所有特征的比例):0.5~1.0
第三步:样本不平衡的参数(尝试)
scale_pos_weight:
第四步:降低学习率,提高迭代次数(为了提高准确率)
eta/learning_rate:0.01
n_estimators:1000
结果汇总
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 93.15 | 86.84 | 17.8 | 1.89 | XGBoost | 默认参数 |
| 96.32 | 86.86 | 14.02 | 1.77 | XGBoost | scale_pos_weight = 100 |
| 94.89 | 87.21 | 25.49 | 1.81 | XGBoost | colsample_bytree = 0.55 |
| 93.17 | 87.22 | 17.32 | 1.98 | XGBoost | reg_lambda = 9.5 |
| 91.16 | 87.35 | 9.01 | 1.8 | XGBoost | reg_alpha = 6.5 |
“scale_pos_weight’作为官方指定的针对样本不平衡问题的参数,使用之后,虽然训练集的表现提高了,但是测试集的表现还不如默认参数,说明该参数并不能提高模型的泛化能力,也许在测试集和训练集分布更接近的情况下效果会有所不同“;
“‘colsample_bytree=0.5时’虽然提高了模型在测试集上的表现,但是加剧了过拟合的现象”;
“基于此数据集,调整正则项的效果是最优的,不仅可以缓解过拟合,而且提高了模型在测试集auc的表现”。
改进方法二:重采样 + XGBoost
重采样(Over-Sample,也翻译为过采样)即通过一定的方法增加正样本的数量,使正样本和负样本数量之比趋于平衡;关于增加正样本的方法无非有两种,一是从正样本的数据集中随机挑选出为达到我们目标正负样本比例的正样本数量;二是通过线性插值的方法,随机生成正样本。
什么是线性插值呢?简单来说就是选择两个点A、B,连成线之后随机选择一个步长产生一个新的点。
线性插值选择基准点A的方法不同,就构成了不同生成正样本的方法:
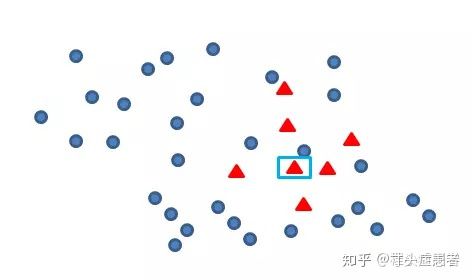
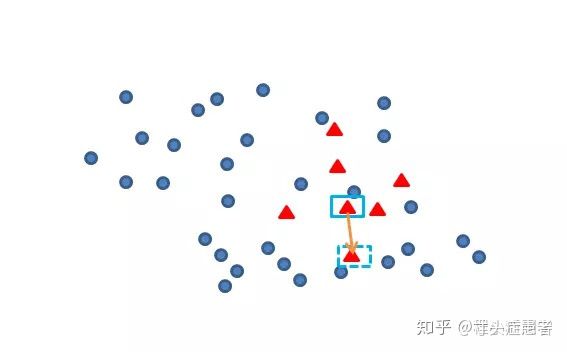
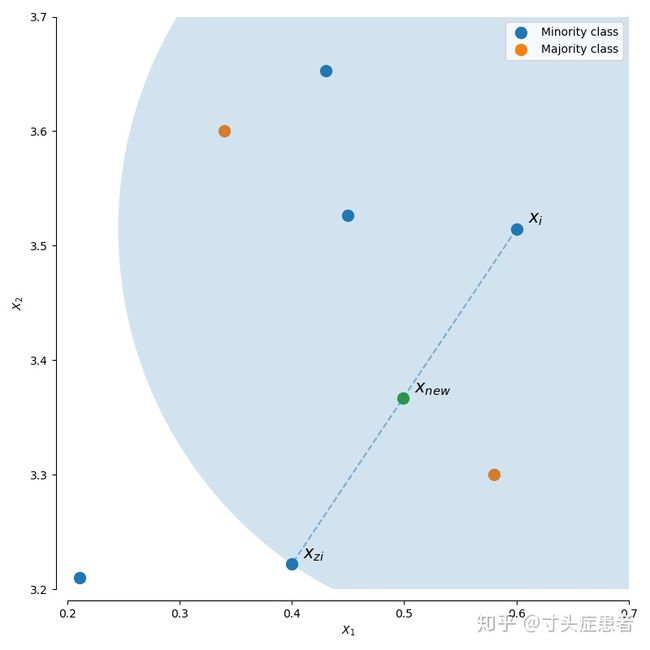
以SMOTE和BorderlineSMOTE为例,普通的SMOTE是从所有的少数类样本中随机选择一个点A,在从这个A的K个近邻中随机挑选一个B,把A-B连线,然后随机选择一个步长steps,就能生成一个正样本;不断重复该步骤,就能生成我们想要的数量;
BorderLine选择A点的规则不同,它倾向于选择被负样本包围的正样本,然后也是从 K个近邻中随机挑选一个点构成B,然后再线性插值生成一个正样本;
不同的SMOTE就是选择A点的方法不同,在此不一一枚举。
具体算法细节可查看:https://imbalanced-learn.org/
结果汇总
重采样方法效果全览:
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 | 耗时 |
|---|---|---|---|---|---|---|
| 99.79 | 80.11 | 99.81 | 0.55 | ADASYN | 默认参数(采样后1:1) | 2h51m |
| 99.98 | 79.03 | 99.98 | 0.5 | BorderlineSMOTE | 默认参数(采样后1:1) | 2h50min |
| 99.76 | 80.28 | 99.97 | 0.59 | SMOTE | 默认参数(采样后1:1) | 4sec |
| 96.18 | 85.41 | 95.74 | 1.48 | RandomOverSampler | 默认参数(采样后1:1) | 4sec |
改变重采样后正负样本的比例
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 95.1 | 86.94 | 37.47 | 1.74 | RandomOverSampler | sampling_strategy = 0.005(重采样后1:200) |
| 95.6 | 87.05 | 56.1 | 1.77 | RandomOverSampler | sampling_strategy = 0.02(重采样后1:50) |
重采样后,调整正则项
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 97.38 | 86.95 | 69.85 | 1.67 | RandomOverSampler | sampling_strategy = 0.02(重采样后1:50);reg_lambda=10.5 |
| 95.01 | 87.33 | 29.56 | 1.6 | RandomOverSampler | sampling_strategy = 0.002(重采样后1:500);reg_lambda=9.5 |
| 96.83 | 87.24 | 51.39 | 1.64 | RandomOverSampler | sampling_strategy = 0.004(重采样后1:250);reg_lambda=4.5 |
“使用重采样的方法之后,虽然平衡了正负样本比例(默认参数是1:1),但无论是线性插值还是随机采样的重采样方法都增加了不少冗余数据和噪音数据,这时候分类器可能把少数类样本都判断正确了,但同时也会误伤不少多数类样本,使得模型在各个指标的表现还不如原数据集;当改变重采样后正负样本的比例,虽然表现仍然不如原数据集,但是相对于默认参数,模型的表现略有提升,这启发我们训练模型时,训练集的正负样本比例不能过于偏离验证集;
无论是原数据集还是重采样后的数据集,调整正则项都对模型的AUC和P-R值有所提升。“
改进方法三:降采样 + XGBoost
降采样(Under_Sampling),如果说重采样是想尽办法增加正样本,那么降采样就是想尽办法减少负样本;除了随机抽样的降采样方法之外,其他所有的降采样的方法都可以总结为“清除噪音数据”,定义噪音数据的规则不同,就形成了不同的降采样方法,因为是根据噪音数据进行降采样,必须是满足算法定义的噪音才能够被清除,所以很多方法我们并不能控制降采样后的正负样本比例。
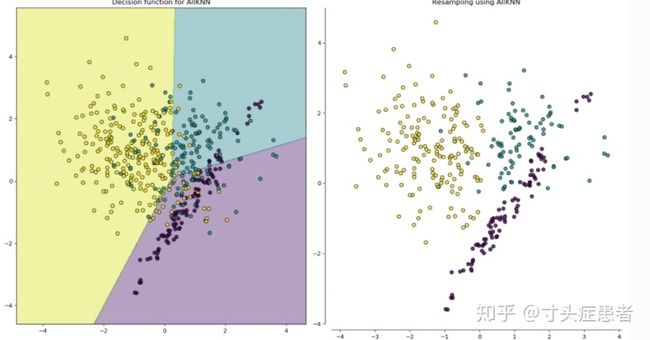

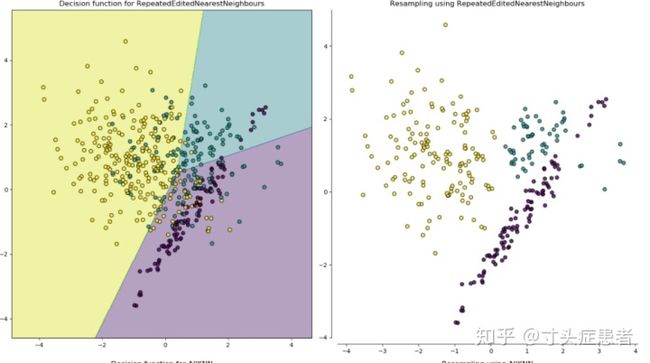
简单看来,第一降采样方法——A11KNN,似乎对噪音的清除不如后两种彻底;但是它们都倾向于清除夹杂在正负样本之间的数据。
具体算法细节可查看:https://imbalanced-learn.org/
结果汇总
降采样方法总览
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 | 耗时 |
|---|---|---|---|---|---|---|
| 94.38 | 87.61 | 20.44 | 2.34 | A11KNN | 默认参数(降采样后1:1) | 7h30m |
| 99.18 | 86.64 | 99.34 | 1.3 | RandomUnderSampler | 默认参数(降采样后正负样本比例几乎没有变化) | 1sec |
| 100.0 | 32.58 | 100.0 | 0.1 | ClusterCentroids | 默认参数(降采样后1:1) | 1h2m |
| 100.0 | 70.72 | 100.0 | 0.25 | NearMiss | 默认参数(降采样后1:1) | 16sec |
改变降采样后正负样本的比例
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 93.39 | 86.9 | 20.64 | 1.91 | RandomUnderSampler | sampling_strategy = 0.002(重采样后1:500) |
| 94.5 | 87.01 | 52.7 | 1.67 | RandomUnderSampler | sampling_strategy = 0.02(重采样后1:50) |
| 96.43 | 87.15 | 88.91 | 1.46 | RandomUnderSampler | sampling_strategy = 0.2(重采样后1:50) |
“降采样去除了一部分多数类样本,虽然在提高运行速度的同时也使样本比例趋于平衡,但是同时也使得模型失去了不少的学习机会,使得结果偏向于少数类,导致把部分多数类的样本分错,最终模型的相关评估指标反而还不如降采样之前,在尝试了不同的采样后正负样本的比例之后,结果有所改善。“
降采样后调整正则项
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 92.48 | 87.3 | 16.69 | 1.97 | RandomUnderSampler | sampling_strategy = 0.002(重采样后1:500);reg_lambda=5.5 |
| 92.38 | 87.33 | 23.79 | 1.86 | RandomUnderSampler | sampling_strategy = 0.005(重采样后1:200);reg_lambda=10.5 |
| 93.47 | 87.53 | 61.36 | 1.64 | RandomUnderSampler | sampling_strategy = 0.05(重采样后1:20);reg_lambda=10.5 |
| 92.94 | 87.36 | 34.19 | 1.95 | RandomUnderSampler | sampling_strategy = 0.01;reg_lambda= 9.0 |
改进方法四:混合采样 + XGBoost
既然重采样可能增加噪音数据,而降采样可以清除噪音数据,如果把两种方法结合,结果又会如何呢?
结果汇总
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 99.78 | 80.23 | 99.81 | 0.55 | SMOTENN | 默认参数 |
| 99.76 | 80.15 | 99.78 | 0.61 | SMOTETomek | 默认参数 |
改变一下混合采样后,正负样本的比例
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 99.22 | 84.35 | 89.32 | 0.76 | SMOTENN | sampling_strategy = 0.02 |
”auc和P-R值都不如单纯的使用降采样或者重采样”
改进方法五:改进的集成算法
传统的Bagging(袋装)集成学习器——如随机森林,虽然是集合了多个基分类器,但是在训练每个基分类器时,都是基于一个不平衡样本(从训练集中随机有放回到地采样),所以最终训练的模型为了追求低损失,还是会将预测结果偏向多数类; 为了改善此现象,可以把每个基分类器的训练数据设定为经过重采样(bootstrap)后的平衡数据,然后再综合每个基分类器的预测结果 官方API: [1] https://imbalanced-learn.org/stable/ensemble.html; [2] https://imbalanced-learn.org/stable/auto_examples/ensemble/plot_comparison_ensemble_classifier.html#sphx-glr-auto-examples-ensemble-plot-comparison-ensemble-classifier-py
BalancedRandomForestClassifier
即改进的随机森林,训练每一棵决策树都是基于一个降采样后的数据集——因为直接降采样之后再训练集成算法有可能丢失不少信息量,如果把原数据集的多数类样本分成若干份,这若干份的多数类样本都和少数类样本集合成一个个训练集提供给随机森林(这样就能充分利用每一个多数类样本)。
结果汇总
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 98.36 | 85.61 | 14.21 | 0.91 | BRFC | 默认参数 |
| 99.28 | 86.36 | 28.72 | 0.98 | BRFC | sampling_strategy =0.5 |
“基于此数据集,改进后的随机森林方法的确优于原始的随机森林方法。“
[题外话]——为什么GBDT和XGBoost不能用这种改进方法?
因为RFC(随机森林)训练每一棵决策树都是并行的,每一棵树的训练集可以不同;而GBDT和XGBoost是串行的,每一棵树的训练集必须相同。
”和XGBoost、GBDT相比,除了基分类器的训练数据不同,每一个基分类器(每一棵树)的形成原理也不同——前者是拟合梯度,往梯度下降的方向生成决策树;后者是根据信息增益‘’
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 方法 |
|---|---|---|---|---|---|
| 99.26 | 86.19 | 29.48 | 1.02 | RandomUndersample+RFC | 先降采样到1:500;然后使用BFC |
改进方法六:基于AdaBoost的集成——EasyEnsemble&BalanceCascade
为什么算法的作者要选择AdaBoost作为基分类器?首先,AdaBoost的每一个基分类器(每一棵树)的权重都是基于训练结果决定;其他的集成算法如GBDT、XGBoost的基分类器的权重都是不变的超参数,事先决定的,和训练结果无关;其次AdaBoost还有一个特点就是在训练每一个基分类器(每一棵树)之后都会根据训练结果改变训练集的样本权重——增加分类错误的样本,降低分类正确的样本权重;
Q1:传统的AdaBoost和这两种方法有什么不同?
1.AdaBoost的基分类器是树模型;而后者的基分类器是AdaBoost——集成算法的集成;
2.AdaBoost在训练每一个基分类器时都是基于整个数据集;而后者的基分类器在训练数据时都是基于一个随机降采样后的数据集(比例可以选择,不一定是1:1)
Q2:BalanceCascade和EasyEnsemble相比作了什么优化

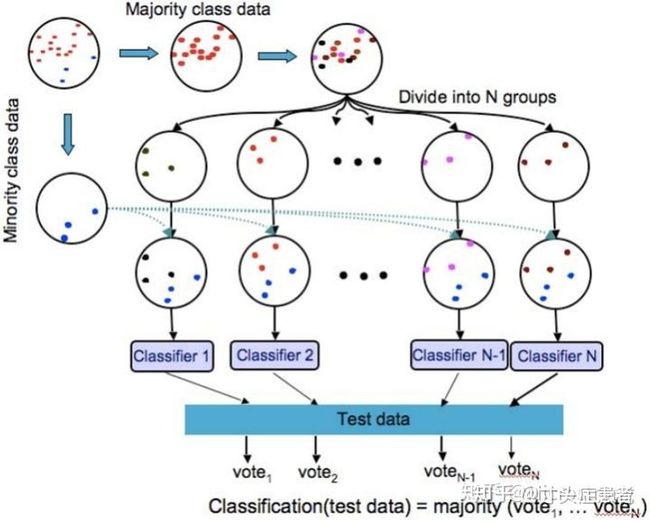
EasyEnsemble只是简单的基于AdaBoost的集成,阈值是固定的事先选定的超参数,最终标签的决定是使用投票法;
Balance Cascade也是基于AdaBoost的集成,但是每一个基分类器都有各自的概率阈值,换言之,概率阈值不再是超参数,会根据每一个基分类器的训练结果改变,然后把预测正确的多分类样本删除,再从剩下的样本中进行Boostrap方法的降采样,最终的标签预测值也是由投票法决定,见下图


而BalanceCascade的每一个基分类器的概率阈值又是如何决定的呢?
“训练出一个基分类器——AdaBoost之后,对全体多数类样本进行预测,得到每一个多数类样本的概率预测值;得到多数类样本的概率预测值之后,开始计算为达到特定的假正率(FPR)——概率阈值应该设定的大小(联想假正率(FPR)的意义:所有多数类样本中被预测错误的比率,为了达到较低的假正率(FPR),需要较高的预测概率阈值,这时候被误伤的多数类样本就越少),在这么高的概率阈值下,都能把这部分的负样本预测错误,说明它们对正样本的预测干扰较大,应该留下来继续训练,其他预测正确的多数类样本可以移除;
结果汇总
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 98.65 | 85.78 | 16.17 | 0.93 | EasyEnsemble | 默认参数,基分类器adaboost |
| 89.93 | 86.66 | 4.17 | 1.72 | EasyEnsemble | 默认参数,基分类器是GBDT |
| 98.17 | 87.25 | 39.52 | 1.93 | EasyEnsemble | 默认参数,基分类器是XGBoost |
| 87.89 | 1.32 | 86.51 | 1.05 | BalanceCascade | 默认参数,n_estimators = 100 |
“基于此数据集使用‘EasyEnsemble’的方法,似乎可以提高模型(GBDT)的泛化能力。“
“BalanceCascade方法虽然在测试集的不如XGBoost(和GBDT差不多)但是其泛化能力和稳定性似乎是最好的,是否可以尝试优化这个模型?“
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 88.16 | 1.38 | 86.42 | 0.96 | BalanceCascade | 基分器数量不变,把基分器Adaboost调成更复杂 |
很遗憾,只提高了训练集的表现,并没有提高测试集的表现。
[注]

BalanceCascade是09年左右提出的方法,这个方法关注的是当前的基分类器——一个AdaBoost分类错误的负样本,如果分类错误就留下来给下一个基分类器继续训练,分类正确就删除;同时还不要忘了AdaBoost的特点——增大分类错误样本的权重(无论正负)。这种思想最大优点就是可以增强模型的复杂度,但是又让人不免担心有过拟合的风险,除非测试集的正负样本和训练集的分布类似——‘噪声类‘数据较多。
假如噪声类数据不多,或者我们比较关注模型的泛化能力,10年之后又有人提出了一个新的算法
——Self-paced Ensemble
改进方法七:Self-paced Ensemble

首先需要认识以下几个概念:
1.分类硬度分布——Hardness contribution
其实就是损失函数——交叉熵,平方根误差rmse或者平均绝对值误差mae,可以理解为分类难度,损失函数越大,分类难度就越大;
2.基分类器是什么?
可以是集成算法、也可以是单一的分类器;
3.训练每一个基分类器的数据是怎样的?
都是降采样后的数据,和改进方法六类似;但是不舍弃任何数据,而且采样的方法有创新:简单来说就是,把多数类样本分成两类,噪声类数据和非噪声数据,我们的模型应该集中训练非噪声数据,即噪声数据采样的权重较小,非噪声数据采样的权重较大;
其中,噪声和非噪声是一个相对的概念,由分类硬度函数决定(Hardness contribution)——这个函数的大小也决定了对多数类样本的采样情况,而且分类硬度函数的大小随着基分类器的增加会发生变化,降采样后的数据也会发生变化——这也是自适应(Self-paced)的由来。
“因为普通的随机降采样方法不能保证采样后的数据在空间上的分布和采样前的一致,所以此方法先通过对多数类样本进行分箱,然后每一箱都抽取一定的比例和少数类样本组成1:1的训练集训练基分类器;这样就能保证每一次训练基分器的多数类样本分布都能和原数据的多数类样本保持一致;具体抽取的比例根据每一箱的分类难度而定,对于易误分类的样本,抽取的数量较少,反之较多,这样的优点是能够保证分类器的鲁棒性以及减轻对噪声的敏感性”
结果汇总
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 89.41 | 85.41 | 1.46 | 0.73 | 基分类器是GBDT | n_estimators=100 |
| 99.7 | 87.06 | 92.87 | 1.23 | 基分类器是XGBClassifier | n_estimators=150 |
| 100.0 | 86.16 | 100.0 | 1.2 | 基分类器是决策树 | n_estimators= 350 |
降采样到1:50,后使用SPE
| 训练集auc | 测试集auc | 训练集PR | 测试集PR | 方法 | 参数 |
|---|---|---|---|---|---|
| 99.72 | 87.25 | 97.74 | 1.27 | 基分类器是XGBclassifier | n_estimators=100 |
| 89.54 | 85.4 | 18.84 | 0.74 | 基分类器是GBDT | n_estimators=100 |
经验总结
首选方法:
- 降采样:一般是用来平衡数据集、去噪。平衡数据集的有随机欠采样/NearMiss,采样和训练速度都很快。随机欠采样在任何情况下都能用,但在数据集不平衡程度较高时会不可避免地丢弃大部分多数类样本造成信息损失。NearMiss对噪声极端敏感,有噪声基本就废掉。去噪方法有很多,如Tomeklink,AllKNN等,需要数据集上有良好定义的距离度量,在大规模数据集上计算量大。去噪之后对有的分类器有效,有的无效。
- 集成:随机降采样+集成,在不平衡比较高时需要较多的基学习器来达到较好的效果。注意Boosting容易被噪声影响,Bagging方法是真正的万金油,增加基学习器数量效果一般不会下降。高级降采样+集成,也可以尝试,运行会慢并且效果不能保证比随机方法好。高级过采样+集成,同上,数据规模大且不平衡程度高情况下,训练样本数量爆炸。尤其是集成方法还要训练好多个基学习器。BalanceCascade,信息利用效率高,只用很少的基学习器就能达到较好的效果,但对噪声不鲁棒。
效果不大的方法:
- 过采样:随机过采样任何情况下都不要用,及其容易造成过拟合。SMOTE、ADASYN在小规模数据上可以一试。当数据规模大且不平衡程度高时,过采样方法生成巨量的合成样本,需要很多额外计算资源。同时此类过采样基于少数类样本的结构信息,在少数类的表示质量很差时甚至会反向优化:过采样效果还不如直接训练。
- 混合采样:理论上加入了去噪类的欠采样算法来清洁过采样之后的数据集。实际使用起来我没感觉到有什么不同,唯一的区别是加了去噪方法之后更慢了。
参考资料
[1] 极端类别不平衡数据下的分类问题S01:困难与挑战 - 刘芷宁的文章 - 知乎 https://zhuanlan.zhihu.com/p/54199094
[2] 极端类别不平衡数据下的分类问题S02:问题概述,模型选择及人生经验 - 刘芷宁的文章 - 知乎 https://zhuanlan.zhihu.com/p/66373943
[3] Self-paced Ensemble: 高效、泛用、鲁棒的不平衡学习框架 - 刘芷宁的文章 - 知乎 https://zhuanlan.zhihu.com/p/86891438
[4] 机器学习不平衡数据处理参考 - 小方哥哥的文章 - 知乎 https://zhuanlan.zhihu.com/p/68099299
[5] sklearn中SVC和LogisticRegression的class_weight作用? - 何事秋风的回答 - 知乎 https://www.zhihu.com/question/265420166/answer/293896934
[6] 非平衡分类问题 | BalanceCascade方法及其Python实现 - 家里蹲大学研究僧的文章 - 知乎 https://zhuanlan.zhihu.com/p/36093594
后记
其实整个过程恰恰印证了那句最经典的话——“数据决定了模型评分的上限,模型只是逼近这个上限罢了”,因为省略了特征工程,所以我的整个探索归结起来就是一个如何处理XGBoost的过拟合问题。稍微翻了一下其他人的分类方案,他们大多都是在特征工程上下功夫,或者最后加一个Stack(模型融合);还有一个重要的点必须声明:方案不具有普适性——不同的数据集有不同的情形,需要多尝试多探索