合工大python期末复习知识点汇总
文章目录
- Python序列
-
- map函数
- eval函数
- divmod
- sort sorted
- os与os.path模块
- 列表
-
- 切片
- 列表推导式
- 编写算法实现嵌套列表的平铺
- 列出当前文件夹下所有Python源文件
- 元组
-
- 序列解包(sequence unpacking
- 生成器推导式
- 字典
- 集合
- 其他数据结构:队列 堆栈 二叉树
- 程序的控制结构
-
- 应用
- 例:编写程序,判断今天是今年的第几天?
- 例:计算1+2+3+…+100 的值。
- 例:输出“水仙花数”。
- 例:判断一个数是否为素数。
- 例:生成一个含有20个随机数的列表,
- 计算百钱买百鸡问题。
- 例 编写程序,实现十进制整数到其他任意进制的转换。
- 例 计算前n个自然数的阶乘之和1!+2!+3!+...+n!的值。
- 例 判断一个数字是否为丑数。
- 字符串和正则表达式
-
- find()、rfind()、index()、rindex()、count()
- split()
- join
- 格式化
- 与字符串处理有关的标准库
- 编写程序,把一个英文句子中的单词倒置
- 例: 编写程序,查找一个字符串中最长的数字子串。
- 面向对象程序设计
-
- self参数:
- 私有成员和公有成员
- 类中的方法
- 属性
- 继承
Python序列
| 列表 | 元组 | 字典 | 集合 | |
|---|---|---|---|---|
| 类型名称 | list | tuple | dict | set |
| 定界符 | 方括号[] | 圆括号() | 大括号{} | 大括号{} |
| 是否可变 | 是 | 否 | 是 | 是 |
| 是否有序 | 是 | 是 | 否 | 否 |
| 是否支持下标 | 是(序号作为下标) | 是(序号作为下标) | 是(“键”作为下标) | 否 |
| 元素分隔符 | 逗号 | 逗号 | 逗号 | 逗号 |
| 对元素形式的要求 | 无 | 无 | 键:值 | 必须可哈希 |
| 对元素值的要求 | 无 | 无 | “键”必须可哈希 | 必须可哈希 |
| 元素是否可重复 | 是 | 是 | “键”不允许重复,“值”可以重复 | 否 |
| 元素查找速度 | 非常慢 | 很慢 | 非常快 | 非常快 |
| 新增和删除元素速度 | 尾部操作快 其他位置慢 | 不允许 | 快 | 快 |
map函数
>>> def square(x) : # 计算平方数
... return x ** 2
...
>>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方
<map object at 0x100d3d550> # 返回迭代器
>>> list(map(square, [1,2,3,4,5])) # 使用 list() 转换为列表
[1, 4, 9, 16, 25]
>>> list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) # 使用 lambda 匿名函数
[1, 4, 9, 16, 25]
eval函数
以下展示了使用 eval() 方法的实例:
>>>x = 7
>>> eval( '3 * x' )
21
>>> eval('pow(2,2)')
4
>>> eval('2 + 2')
4
>>> n=81
>>> eval("n + 4")
85
eval(input()如果输入的是数字,则转换为数字;如果不是数字,报错。
int(input())如果是数字,整数的话,没为题,小数的话,丢失小数部分;如果不是数字,报错。
divmod
Python divmod() 函数:
接收两个数字类型(非复数)参数,返回一个包含商和余数的元组(a // b, a % b)
sort sorted
“sort()与sorted()的不同在于,sort是在原位重新排列列表,而sorted()是产生一个新的列表
▶▶sort 是应用在 list 上的方法,属于列表的成员方法,sorted 可以对所有可迭代的对象进行排序操作。
▶▶list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
▶▶sort使用方法为ls.sort(),而sorted使用方法为sorted(ls)。
[('a', 1), ('b', 2), ('c', 3), ('d', 4)]
sorted(L, key=lambda x:x[1])
l:[('a', 1), ('b', 2), ('e', 3), ('d', 4), ('c', 6)]
l.sort(key=lambda x : x[1], reverse=True)
os与os.path模块
| 方法 | 功能说明 |
|---|---|
| access(path, mode) | 测试是否可以按照mode指定的权限访问文件 |
| chdir(path) | 把path设为当前工作目录 |
| chmod(path, mode, *, dir_fd=None, follow_symlinks=True) | 改变文件的访问权限 |
| curdir | 当前文件夹 |
| environ | 包含系统环境变量和值的字典 |
| extsep | 当前操作系统所使用的文件扩展名分隔符 |
| get_exec_path() | 返回可执行文件的搜索路径 |
| getcwd() | 返回当前工作目录 |
| listdir(path) | 返回path目录下的文件和目录列表 |
| open(path, flags, mode=0o777, *, dir_fd=None) | 按照mode指定的权限打开文件,默认权限为可读、可写、可执行 |
| popen(cmd, mode=‘r’, buffering=-1) | 创建进程,启动外部程序 |
列表
▶▶列表是Python中内置有序、可变序列,列表的所有元素放在一对中括号“[]”中,并使用逗号分隔开;
▶▶当列表元素增加或删除时,列表对象自动进行扩展或收缩内存,保证元素之间没有缝隙;
▶▶在Python中,一个列表中的数据类型可以各不相同
可以同时分别为整数、浮点数、字符串等基本类型,甚至是列表、元组、字典、集合以及其他自定义类型的对象。
列表常用方法
| 方法 | 说明 |
|---|---|
| lst *= n | 更新列表lst, 其元素重复n次 |
| lst.append(x) | 将元素x添加至列表lst尾部 |
| lst.extend(L) 或lst += L | 将列表L中所有元素添加至列表lst尾部 |
| lst.insert(index, x) | 在列表lst指定位置index处添加元素x,该位置后面的所有元素后移一个位置 |
| lst.remove(x) | 在列表lst中删除首次出现的指定元素,该元素之后的所有元素前移一个位置 |
| lst.pop([index]) | 删除并返回列表lst中下标为index(默认为-1)的元素 |
| lst.clear() | 删除列表lst中所有元素,但保留列表对象 |
| lst.index(x) | 返回列表lst中第一个值为x的元素的下标,若不存在值为x的元素则抛出异常 |
| lst.count(x) | 返回指定元素x在列表lst中的出现次数 |
| lst.reverse() | 对列表lst所有元素进行逆序 |
| lst.sort(key=None, reverse=False) | 对列表lst中的元素进行排序,key用来指定排序依据,reverse决定升序(False)还是降序(True) |
| lst.copy() | 返回列表lst的浅复制 |
(1)可以使用“+”运算符将元素添加到列表中
>>> aList = [3,4,5]
>>> aList = aList + [7]
>>> aList
[3, 4, 5, 7]
严格意义上来讲,这并不是真的为列表添加元素,而是创建了一个新列表,并将原列表中的元素和新元素依次复制到新列表的内存空间。
由于涉及大量元素的复制,该操作速度较慢,在涉及大量元素添加时不建议使用该方法。
(2)使用列表对象的append()方法在当前列表尾部追加元素,原
地修改列表
所谓“原地”,是指不改变列表在内存中的首地址。
是真正意义上的在列表尾部添加元素,速度较快。
>>> aList.append(9)
>>> aList
[3, 4, 5, 7, 9]
3)使用列表对象的extend()方法可以将另一个迭代对象的所有元素添加 至该列表对象尾部。
通过extend()方法来增加列表元素也不改变其内存首地址,属原地操作。
>>> a= [1,2,3]
>>> id(a)
46036232
>>> a.extend([2,3,4])
>>> id(a)
46036232
>>> print(a)
[1, 2, 3, 2, 3, 4]
(4)使用列表对象的insert()方法将元素添加至列表的指定位置。
>>> a.insert(3, 6) #在下标为3的位置插入元素6
>>> print(a)
[1, 2, 3, 6, 2, 3, 4]
>>> id(a)
46036232
(5)使用乘法来扩展列表对象,将列表与整数相乘,生成一个新列表, 新列表是原列表中元素的重复
>>> aList = aList*3
>>> aList
[3, 5, 7, 3, 5, 7, 3, 5, 7]
>>> bList
[3,5,7]
>>> id(aList), id(bList)
(57092680, 57091464)
▶▶使用列表对象的count()方法统计指定元素在列表对象中出现的次数。
▶▶使用in关键字来判断一个值是否存在于列表中,返回结果为“True”或“False”。
>>> bList = [[1], [2], [3]]
>>> 3 in bList
False
切片
切片适用于列表、元组、字符串、range对象等类型,但作用于列表时功能最强大。
可以使用切片来截取列表中的任何部分,得到一个新列表,也可以通过切片来修改和删除列表中部分元素,甚至可以通过切片操作为列表对象增加元素。
切片使用2个冒号分隔的3个数字来完成:
形式上,切片使用2个冒号分隔的3个数字来完成。
[startstep]
1
第一个数字start表示切片开始位置,默认为0;
第二个数字end表示切片截止(但不包含)位置(默认为列表长度);
第三个数字step表示切片的步长(默认为1)。
当start为0时可以省略,当end为列表长度时可以省略,当step为1时可以省略,省略步长时还可以同时省略最后一个冒号。
当step为负整数时,表示反向切片,这时start应该在end的右侧才行。
切片操作不会因为下标越界而抛出异常,而是简单地在列表尾部截断或者返回一个空列表,代码具有更强的健壮性。
>>> aList = [3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
>>> aList[::] #返回包含所有元素的新列表
[3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
>>> aList[::-1] #逆序的所有元素
[17, 15, 13, 11, 9, 7, 6, 5, 4, 3]
>>> aList[::2] #偶数位置,隔一个取一个
[3, 5, 7, 11, 15]
>>> aList[1::2] #奇数位置,隔一个取一个
[4, 6, 9, 13, 17]
>>> aList[3::] #从下标3开始的所有元素
[6, 7, 9, 11, 13, 15, 17]
>>> aList[3:6] #下标在[3, 6)之间的所有元素
[6, 7, 9]
>>> aList[0:100:1] #前100个元素,自动截断 切片开始位置大于列表长度时,返回空列表
[3, 4, 5, 6, 7, 9, 11, 13, 15, 17]
>>> aList[100:] #下标100之后的所有元素,自动截断
[]
>>> aList[100] #直接使用下标访问会发生越界
IndexError: list index out of range
>>> aList = [3, 5, 7]
>>> aList[:2] = [1, 2] #替换前2个元素
>>> aList
[1, 2, 7]
>>> aList = list(range(10))
>>> aList
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> aList[::2] = [0]*5 #替换偶数位置上的元素
>>> aList
[0, 1, 0, 3, 0, 5, 0, 7, 0, 9]
>>> aList[::2] = [0]*3
列表推导式
列表推导式(又称列表解析式)提供了一种简明扼要的方法来创建列表。
它的结构是在一个中括号里包含一个表达式,然后是一个for语句,然后是 0 个或多个 for 或者 if 语句。那个表达式可以是任意的,意思是你可以在列表中放入任意类型的对象。返回结果将是一个新的列表,在这个以 if 和 for 语句为上下文的表达式运行完成之后产生。
列表推导式的执行顺序:
各语句之间是嵌套关系,左边第二个语句是最外层,依次往右进一层,左边第一条语句是最后一层。
[x*y for x in range(1,5) if x > 2 for y in range(1,4) if y < 3]
即:
for x in range(1,5)
if x > 2
for y in range(1,4)
if y < 3
x*y
编写算法实现嵌套列表的平铺
[[1,2,3], [4,5,6]] -> [1, 2, 3, 4, 5, 6]
解答一:
>>> vec = [[1, 2, 3], [4, 5, 6]]
>>> result = []
>>> for elem in vec:
for num in elem:
result.append(num)
>>> result
[1, 2, 3, 4, 5, 6]
解答二:
>>> vec = [[1, 2, 3], [4, 5, 6]]
>>> sum(vec, [])
[1, 2, 3, 4, 5, 6, 7, 8, 9]
解答三:使用列表推导式实现
>>> vec = [[1,2,3], [4,5,6]]
>>> [num for elem in vec for num in elem]
[1, 2, 3, 4, 5, 6, 7, 8, 9]
列出当前文件夹下所有Python源文件
>>> import os
>>> [filename for filename in os.listdir('.')
if filename.endswith(('.py', '.pyw'))]
过滤不符合条件的元素
>>> aList = [-1,-4,6,7.5,-2.3,9,-11]
>>> [i for i in aList if i>0]
[6, 7.5, 9]
元组
▶▶元组一旦定义就不允许更改。
▶▶元组没有append()、extend()和insert()等方法,无法向元组中添加元素。
▶▶元组没有remove()或pop()方法,也无法对元组元素进行del操作,不能从元组中删除元素。
▶▶使用tuple函数将其他序列转换为元组
▶▶元组的定义方式和列表相同,但定义时所有元素是放在一对圆括号“()”中,而不是方括号中。
zip() 函数:用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
>>>a = [1,2,3]
>>> b = [4,5,6]
>>> c = [4,5,6,7,8]
>>> zipped = zip(a,b) # 打包为元组的列表
[(1, 4), (2, 5), (3, 6)]
>>> zip(a,c) # 元素个数与最短的列表一致
[(1, 4), (2, 5), (3, 6)]
>>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式
[(1, 2, 3), (4, 5, 6)]
tuple函数的使用:
>>> tuple('abcdefg') #把字符串转换为元组
('a', 'b', 'c', 'd', 'e', 'f', 'g')
>>> aList
[-1, -4, 6, 7.5, -2.3, 9, -11]
>>> tuple(aList) #把列表转换为元组
(-1, -4, 6, 7.5, -2.3, 9, -11)
>>> s = tuple() #空元组
>>> s
()
使用del可以删除元组对象,不能删除元组中的元素
元组的优点
元组的速度比列表更快。如果定义了一系列常量值,而所需做的仅是对它进行遍历,那么一般使用元组而不用列表。
元组对不需要改变的数据进行“写保护”将使得代码更加安全。
元组可用作字典的“键”,也可以作为集合的元素。列表永远不能当做字典键使用,也不能作为集合的元素,因为列表不是不可变的。
序列解包(sequence unpacking
当函数或方法返回元组时,将元组中值赋给变量序列中的变量,这个过程就叫做序列解包。
可以使用序列解包功能对多个变量同时赋值
>>> x, y, z = 1, 2, 3 #多个变量同时赋值
>>> v_tuple = (False, 3.5, 'exp')
>>> (x, y, z) = v_tuple
>>> x, y, z = v_tuple
>>> x, y, z = range(3) #可以对range对象进行序列解包
>>> x, y, z = iter([1, 2, 3]) #使用迭代器对象进行序列解包
>>> x, y, z = map(str, range(3)) #使用可迭代的map对象进行序列解包
>>> a, b = b, a #交换两个变量的值
>>> x, y, z = sorted([1, 3, 2]) #sorted()函数返回排序后的列表
>>> a, b, c = 'ABC' #字符串也支持序列解包
>>> x = [1, 2, 3, 4, 5, 6]
>>> x[:3] = map(str, range(5)) #切片也支持序列解包
序列解包遍历多个序列
>>> keys = ['a', 'b', 'c', 'd']
>>> values = [1, 2, 3, 4]
>>> for k, v in zip(keys, values):
print((k, v), end=' ')
('a', 1) ('b', 2) ('c', 3) ('d', 4)
使用序列解包遍历enumerate对象
>>> x = ['a', 'b', 'c']
>>> for i, v in enumerate(x):
print('The value on position {0} is {1}'.format(i,v))
The value on position 0 is a
The value on position 1 is b
The value on position 2 is c
>>> aList = [1,2,3]
>>> bList = [4,5,6]
>>> cList = [7,8,9]
>>> dList = zip(aList, bList, cList)
>>> for index, value in enumerate(dList):
print(index, ':', value)
0 : (1, 4, 7)
1 : (2, 5, 8)
2 : (3, 6, 9)
生成器推导式
生成器推导式的结果是一个生成器对象。
使用生成器对象的元素时,可以根据需要将其转化为列表或元组,也可以使用生成器对象__next__()方法或内置函数next()进行遍历,或者直接将其作为迭代器对象来使用。
生成器对象具有惰性求值的特点,只在需要时生成新元素,比列表推导式具有更高的效率,空间占用非常少,尤其适合大数据处理的场合。
不管用哪种方法访问生成器对象,都无法再次访问已访问过的元素。
>>> g = ((i+2)**2 for i in range(10)) #创建生成器对象
>>> g
<generator object <genexpr> at 0x0000000003095200>
>>> tuple(g) #转换为元组
(4, 9, 16, 25, 36, 49, 64, 81, 100, 121)
>>> list(g)
[]
>>> g = ((i+2)**2 for i in range(10)) #重新创建生成器对象
>>> g.__next__() #使用生成器对象的__next__()方法获取元素
4
>>> next(g) #使用函数next()获取生成器对象中的元素
16
# 使用for循环直接迭代生成器对象中的元素
>>> g = ((i+2)**2 for i in range(10))
>>> for item in g: #使用循环直接遍历生成器对象中的元素
print(item, end=' ')
4 9 16 25 36 49 64 81 100 121
字典
字典是无序、可变序列。
定义字典时,每个元素的键和值用冒号分隔,元素之间用逗号分隔,所有的元素放在一对大括号“{}”中。
字典中的键可以为任意不可变数据,比如整数、实数、复数、字符串、元组等等。
globals()返回包含当前作用域内所有全局变量和值的字典
locals()返回包含当前作用域内所有局部变量和值的字典
使用=将一个字典赋值给一个变量
>>> a_dict = {'server': 'db.diveintopython3.org', 'database': 'mysql'}
>>> a_dict
{'database': 'mysql', 'server': 'db.diveintopython3.org'}
>>> x = {} #空字典
>>> x
{}
使用dict利用已有数据创建字典
>>> keys = ['a', 'b', 'c', 'd']
>>> values = [1, 2, 3, 4]
>>> dictionary = dict(zip(keys, values))
>>> dictionary
{'a': 1, 'c': 3, 'b': 2, 'd': 4}
>>> x = dict() #空字典
>>> x
{}
集合
集合是无序、可变序列,使用一对大括号界定,元素不可重复,同一个集合中每个元素都是唯一的。
集合中只能包含数字、字符串、元组等不可变类型(或者说可哈希)的数据,而不能包含列表、字典、集合等可变类型的数据。
使用set将其他类型数据转换为集合
>>> a_set = set(range(8,14))
>>> a_set
{8, 9, 10, 11, 12, 13}
>>> b_set = set([0, 1, 2, 3, 0, 1, 2, 3, 7, 8]) #自动去除重复
>>> b_set
{0, 1, 2, 3, 7, 8}
>>> c_set = set() #空集合
>>> c_set
set()
>>> e={}
>>> type(e)
>>> f={4,}
>>> type(f)
当不再使用某个集合时,删除方法包括:
•可以使用del命令删除整个集合;
•集合对象的pop()方法弹出并删除其中一个元素;
•remove()方法直接删除指定元素;
•clear()方法清空集合。
| S.add(x) | 如果数据项x不在集合S中,将x增加到s |
|---|---|
| S.clear() | 移除S中所有数据项 |
| S.copy() | 返回集合S的一个拷贝 |
| S.pop() | 随机返回集合S中的一个元素,如果S为空,产生KeyError异常 |
| S.discard(x) | 如果x在集合S中,移除该元素;如果x不在,不报错 |
| S.remove(x) | 如果x在集合S中,移除该元素;不在产生KeyError异常 |
| S.isdisjoint(T) | 如果集合S与T没有相同元素(不相交的),返回True |
| len(S) | 返回集合S元素个数 |
| x in S | 如果x是S的元素,返回True,否则返回False |
| x not in S | 如果x不是S的元素,返回True,否则返回False |
| 操作符 | 描述 |
|---|---|
| S – T 或 S.difference(T) | 返回一个新集合,包括在集合S中但不在集合T中的元素 |
| S-=T或S.difference_update(T) | 更新集合S,包括在集合S中但不在集合T中的元素 |
| S & T或S.intersection(T) | 返回一个新集合,包括同时在集合S和T中的元素 |
| S&=T或S.intersection_update(T) | 更新集合S,包括同时在集合S和T中的元素。 |
| S^T或s.symmetric_difference(T) | 返回一个新集合,包括集合S和T中元素,但不包括同时在其中的元素 |
| S=^T或s.symmetric_difference_update(T) | 更新集合S,包括集合S和T中元素,但不包括同时在其中的元素 |
| S|T或S.union(T) | 返回一个新集合,包括集合S和T中所有元素 |
| S=|T或S.update(T) | 更新集合S,包括集合S和T中所有元素 |
| S<=T或S.issubset(T) | 如果S与T相同或S是T的子集,返回True,否则返回False,可以用S |
| S>=T或S.issuperset(T) | 如果S与T相同或S是T的超集,返回True,否则返回False,可以用S>T判断S是否是T的真超集 |
生成不重复随机数
def RandomNumbersBySet(number, start, end):
data = set()
while True:
data.add(random.randint(start, end))
if len(data) == number:
break
return data

使用sorted排序:
>>> persons = [{‘name’:‘Li’, ‘age’:40}, {‘name’:‘Li’, ‘age’:37}, {‘name’:‘Dong’, ‘age’:43}]
>>> print(persons)
[{‘name’: ‘Li’, ‘age’: 40}, {‘name’: ‘Li’, ‘age’: 37}, {‘name’: ‘Dong’, ‘age’: 43}]
#使用key来指定排序依据,先按姓名升序排序,姓名相同的按年龄降序排序
>>> print(sorted(persons, key=lambda x:(x[‘name’], -x[‘age’])))
[{‘name’: ‘Dong’, ‘age’: 43}, {‘name’: ‘Li’, ‘age’: 40}, {‘name’: ‘Li’, ‘age’: 37}]
![]()

其他数据结构:队列 堆栈 二叉树
堆
堆是非线性的树形的数据结构,包括:最大堆与最小堆。
heapq库中的堆默认是最小堆。
>>> import heapq #heapq和random是Python标准库
>>> import random
>>> data = list(range(10))
>>> data
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> random.shuffle(data) #随机打乱顺序
>>> data
[6, 1, 3, 4, 9, 0, 5, 2, 8, 7]
>>> heap=[]
>>> for n in data: #建堆
heapq.heappush(heap,n)
>>> heap
[0, 2, 1, 4, 7, 3, 5, 6, 8, 9]
>>> heapq.heappop(heap)
>>> myheap = [1,2,3,5,7,8,9,4,10,333]
>>> heapq.heapify(myheap) #建堆
>>> myheap
[1, 2, 3, 4, 7, 8, 9, 5, 10, 333]
>>> heapq.heapreplace(myheap,6) #弹出最小元素,
#同时插入新元素
1
>>> myheap
[2, 4, 3, 5, 7, 8, 9, 6, 10, 333]
>>> heapq.nlargest(3, myheap) #返回前3个最大的元素
[333, 10, 9]
>>> heapq.nsmallest(3, myheap) #返回前3个最小的元素
[2, 3, 4]
栈是一种“后进先出(LIFO)”或“先进后出(FILO)”的数据结构。
自定义栈的用法
>>> import Stack
>>> x = Stack.Stack()
>>> x.push(1)
>>> x.push(2)
>>> x.show()
[1, 2]
>>> x.pop()
2
>>> x.show()
[1]
>>> x.showRemainderSpace()
Stack can still PUSH 9 elements.
>>> x.isEmpty()
False
>>> x.isFull()
False
Python列表本身就可以实现栈结构的基本操作。例如,列表对象的append()方法是在列表尾部追加元素,类似于入栈操作;pop()方法默认是弹出并返回列表的最后一个元素,类似于出栈操作。
可以直接使用列表来实现栈结构
>>> myStack = []
>>> myStack.append(3)
>>> myStack.append(5)
>>> myStack.append(7)
>>> myStack
[3, 5, 7]
>>> myStack.pop()
7
>>> myStack.pop()
5
>>> myStack.pop()
3
>>> myStack.pop()
出错
但是直接使用Python列表对象模拟栈操作并不是很方便,例如当列表为空时再执行pop()出栈操作时则会抛出一个不很友好的异常;另外,也无法限制栈的大小。
列表模拟队列:
(将上面的pop改为pop(0)即可)
使用列表来模拟队列结构
>>> x = [1, 2, 3, 4]
>>> x.pop(0)
1
>>> x.pop(0)
2
>>> x.append(5)
>>> x.pop(0)
3
>>> x.pop(0)
4
>>> x.pop(0)
5
>>> x.pop(0)
也可以使用标准库中的Queue
>>> import queue
>>> q = queue.Queue()
>>> q.put(0) #入队
>>> q.put(1)
>>> q.put(2)
>>> q.queue
deque([0, 1, 2])
>>> q.get() #出队
0
>>> q.queue
deque([1, 2])
>>> q.get()
1
>>> q.queue
优先队列(Priority Queue)
>>> from queue import PriorityQueue #优先级队列
>>> q = PriorityQueue() #创建优先级队列对象
>>> q.put(3) #插入元素
>>> q.put(8) #插入元素
>>> q.put(100)
>>> q.queue #查看优先级队列中所有元素
[3, 8, 100]
>>> q.put(1) #插入元素,自动调整优先级队列
>>> q.put(2)
>>> q.queue
[1, 2, 100, 8, 3]
>>> q.get() #返回并删除优先级最低的元素
1
>>> q.get() #请多执行几次该语句并观察返回的数据
2
>>> q.get()
3
>>> q.get()
8
>>> q.get()
100
二叉树:
使用代码中的类BinaryTree创建的对象不仅支持二叉树的创建以及前序遍历、中序遍历与后序遍历等三种常用的二叉树节点遍历方式,还支持二叉树中任意“子树”的遍历。
class BinaryTree:
def __init__(self, value):
self.__left = None
self.__right = None
self.__data = value
def insertLeftChild(self, value): #创建左子树
if self.__left:
print('__left child tree already exists.')
else:
self.__left = BinaryTree(value)
return self.__left
def preOrder(self): #前序遍历
print(self.__data) #输出根节点的值
if self.__left:
self.__left.preOrder() #遍历左子树
if self.__right:
self.__right.preOrder() #遍历右子树
def postOrder(self): #后序遍历
if self.__left:
self.__left.postOrder()
if self.__right:
self.__right.postOrder()
print(self.__data)
def insertRightChild(self, value): #创建右子树
if self.__right:
print('Right child tree already exists.')
else:
self.__right = BinaryTree(value)
return self.__right
def show(self):
print(self.__data)
程序的控制结构
分支与循环结构: 例子: 一年365天,一周5个工作日,如果每个工作日都很努力,可以提高r%,仅在周末放任一下,能力值每天下降r%,效果如何呢?
dayup, r = 1.0, 0.01
for i in range(365):
if i % 7 in [6, 0]:#周六周日
dayup = dayup * (1 - r)
else:
dayup = dayup * (1 + r)
print("向上5天向下2天的力量: {:.2f}.".format(dayup))
在选择和循环结构中,都要使用条件表达式来确定下一步的执行流程。
▶▶▶条件表达式的值只要不是False、0(或0.0、0j等)、空值None、空列表、空元组、空集合、空字典、空字符串、空range对象或其他空迭代对象,Python解释器均认为与True等价。
▶▶▶从这个意义上来讲,几乎所有的Python合法表达式都可以作为条件表达式,包括含有函数调用的表达式。
算术运算符:+、-、*、/、//、%、**
关系运算符:>、<、==、<=、>=、!=
测试运算符:in、not in、is、is not
逻辑运算符:and、or、not
位运算符:~、&、|、 ^、 <<、>>
矩阵乘法运算符:@
逻辑运算符and和or以及关系运算符具有惰性求值特点,只计算必须计算的表达式。
以“and”为例,对于表达式“表达式1 and 表达式2”而言,如果“表达式1”的值为“False”或其他等价值时,不论“表达式2”的值是什么,整个表达式的值都是“False”,此时“表达式2”的值无论是什么都不影响整个表达式的值,因此将不会被计算,从而减少不必要的计算和判断。
应用
用户输入若干个分数,求所有分数的平均分。每输入一个分数后询问是否继续输入下一个分数,回答“yes”就继续输入下一个
分数,回答“no”就停止输入分数。
numbers = [] #使用列表存放临时数据
while True:
x = input('请输入一个成绩:')
try: #异常处理结构
numbers.append(float(x))
except:
print('不是合法成绩')
while True:
flag = input('继续输入吗?(yes/no)').lower()
if flag not in ('yes', 'no'): #限定用户输入内容必须为yes或no
print('只能输入yes或no')
else:
break
if flag=='no':
break
例:编写程序,判断今天是今年的第几天?
>>>import time
>>> date = time.localtime() #获取当前日期时间
time.struct_time(tm_year=2020, tm_mon=12, tm_mday=10, tm_hour=7, tm_min=27, tm_sec=36, tm_wday=3, tm_yday=345, tm_isdst=0)
>>> year, month, day = date[:3]
>>> day_month = [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]
>>> if year % 400 == 0 or (year % 4 == 0 and year % 100 != 0): #判断是否为闰年
day_month[1] = 29
>>> if month==1:
print(day)
else:
print(sum(day_month[:month-1])+day)
例:计算1+2+3+…+100 的值。
#解法一:
s=0
for i in range(1,101):
s = s + i
print('1+2+3+…+100 = ', s)
#解法二:
print('1+2+3+…+100 = ', sum(range(1,101)))
例:输出“水仙花数”。
所谓水仙花数是指1个3位的十进制数,其各位数字的立方和等于该数本身。例如:153是水仙花数,因为153 = 13 + 53 + 33 。
#解法一:
for i in range(100, 1000):
bai, shi, ge = map(int, str(i))
if ge**3 + shi**3 + bai**3 == i:
print(i)
例:判断一个数是否为素数。
import math
n = input('Input an integer:')
n = int(n)
m = math.ceil(math.sqrt(n)+1)
for i in range(2, m):
if n%i == 0 and i<n:
print('No')
break
else:
print('Yes')
“ceil函数定义:将给定的数值转换成大于或等于它的最小整数(取不小于给定值的最小整数)”
例:生成一个含有20个随机数的列表,
要求所有元素不相同,并且每个元素的值介于1到100之间。
import random
x = []
while True:
if len(x)==20:
break
n = random.randint(1, 100)
if n not in x:
x.append(n)
print(x)
print(len(x))
print(sorted(x))
计算百钱买百鸡问题。
假设公鸡5元一只,母鸡3元一只,小鸡1元三只,现在有100块钱,想买100只鸡,问有多少种买法?
#假设能买x只公鸡
for x in range(21):
#假设能买y只母鸡
for y in range(34):
#假设能买z只小鸡
z = 100-x-y
if z%3==0 and 5*x + 3*y + z//3 == 100:
print(x,y,z)
例 编写程序,实现十进制整数到其他任意进制的转换。
编程要点:除基取余,逆序排列
十进制数668转换为八进制数字的过程如下图所示,其中横着向右的箭头表示左边的数字除以8得到的商,而向下的箭头表示上面的数字除以8得到的余数。当商为0时,算法结束,最后把得到的余数4321逆序得到1234。
n, base = eval(input(“n:”)),eval(input(“base:”))
result = []
div = n
while div != 0:
div, mod = divmod(div, base)
result.append(mod)
result.reverse()
result = ''.join(map(str, result))
print(eval(result))
例 计算前n个自然数的阶乘之和1!+2!+3!+…+n!的值。
n = evl(input(“n:”))
result, t = 1, 1
for i in range(2, n+1):
t *= i
result += t
例 判断一个数字是否为丑数。
一个数的因数如果只包含2、3、5,那么这个数是丑数。
n = eval(input(“n:”))
for i in (2, 3, 5):
while True:
m, r = divmod(n, i)
if r != 0:
break
else:
print(m)
n = m
print(n==1)
字符串和正则表达式
多种不同的编码格式,常见的主要有UTF-8、UTF-16、UTF-32、GB2312、GBK、CP936、base64、CP437等;
GB2312是我国制定的中文编码,使用1个字节表示英语,2个字节表示中文;GBK是GB2312的扩充,而CP936是微软在GBK基础上开发的编码方式。GB2312、GBK和CP936都是使用2个字节表示中文;
UTF-8对全世界所有国家需要用到的字符进行了编码,以1个字节表示英语字符(兼容ASCII),以3个字节表示常见汉字,还有些语言的符号使用2个字节(例如俄语和希腊语符号)或4个字节。
Python 3.x完全支持中文字符,默认使用UTF8编码格式,无论是一个数字、英文字母,还是一个汉字,在统计字符串长度时都按一个字符对待和处理。
>>> s = '合肥工业大学'
>>> len(s) #字符串长度,或者包含的字符个数
6
>>> s = '合肥工业大学HFUT' #中文与英文字符同样对待,都算一个字符
>>> len(s)
10
>>> 姓名 = '张三' #使用中文作为变量名
>>> print(姓名) #输出变量的值
张三
字符串常用方法、

find()、rfind()、index()、rindex()、count()
find()和rfind方法分别用来查找一个字符串在另一个字符串指定范围(默认是整个字符串)中首次和最后一次出现的位置,如果不存在则返回-1;
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
语法
find()方法语法:
str.find(str, beg=0, end=len(string))
index()和rindex()方法用来返回一个字符串在另一个字符串指定范围中首次和最后一次出现的位置,如果不存在则抛出异常;
count()方法用来返回一个字符串在当前字符串中出现的次数。
s="apple,peach,banana,peach,pear"
>>> s.find("peach")
6
>>> s.find("peach",7)
19
>>> s.find("peach",7,20)
-1
>>> s.rfind('p')
25
>>> s.index('p')
1
>>> s.index('pe')
6
split()
split()和rsplit()方法如果不指定分隔符,则字符串中的任何空白符号(包括空格、换行符、制表符等)都被认为是分隔符,返回包含最终分隔符的列表
split()和rsplit()方法还允许指定最大分割次数。
>>> s = '\n\nhello\t\t world \n\n\n My name is Python '
>>> s.split(None, 1)
['hello', 'world \n\n\n My name is Python ']
>>> s.rsplit(None, 1)
['\n\nhello\t\t world \n\n\n My name is', 'Python']
>>> s.split(None, 2)
['hello', 'world', 'My name is Python ']
>>> s.rsplit(None, 2)
['\n\nhello\t\t world \n\n\n My name', 'is', 'Python']
>>> s.split(maxsplit=6)
['hello', 'world', 'My', 'name', 'is', 'Python']
>>> s.split(maxsplit=100) #最大分隔次数大于可分隔次数时无效
['hello', 'world', 'My', 'name', 'is', 'Python']
join
字符串连接join()
>>> li = ["apple", "peach", "banana", "pear"]
>>> ','.join(li)
'apple,peach,banana,pear'
>>> '::'.join(li)
'apple::peach::banana::pear'
查找替换replace(),类似于Word中的“全部替换”功能。
>>> s = "中国,中国"
>>> print(s)
中国,中国
>>> s2 = s.replace("中国", "中华人民共和国") #两个参数都作为一个整体
>>> print(s2)
中华人民共和国,中华人民共和国
应用:测试用户输入中是否有敏感词,如果有的话就把敏感词替换为3个星号***。
>>> words = ('测试', '非法', '暴力', '话')
>>> text = '这句话里含有非法内容'
>>> for word in words:
if word in text:
text = text.replace(word, '***')
>>> text
strip()、rstrip()、lstrip()
>>> '\n\nhello world \n\n'.strip() #删除空白字符
'hello world'
>>> "aaaassddf".strip("a") #删除指定字符
'ssddf'
>>> "aaaassddfaaa".rstrip("a") #删除字符串右端指定字符
'aaaassddf'
>>> "aaaassddfaaa".lstrip("a") #删除字符串左端指定字符
'ssddfaaa'
Python字符串支持与整数的乘法运算,表示序列重复,也就是字符串内容的重复,得到新字符串。
>>> 'abcd' * 3
'abcdabcdabcd'
s.startswith(t)、s.endswith(t),判断字符串是否以指定字符串开始或结束
isalnum()【用来判断一个字符是否为英文字母或数字,相当于 isalpha© || isdigit©】、isalpha()、isdigit()、isdecimal()【isdecimal() 方法检查字符串是否只包含十进制字符。】、isnumeric()、isspace()、isupper()、islower(),用来测试字符串是否为数字或字母、是否为字母、是否为数字字符、是否为空白字符、是否为大写字母以及是否为小写字母。
注意:定义一个十进制字符串,只需要在字符串前添加 ‘u’ 前缀即可。
str = u"this2009";
print str.isdecimal();
str = u"23443434";
print str.isdecimal();
以上实例输出结果如下:
False
True
格式化
在Python中,字符串属于不可变序列类型,除了支持序列通用方法(包括分片操作)以外,还支持特有的字符串操作方法。
| 格式字符 | 说明 |
|---|---|
| %s | 字符串 (采用str()的显示) |
| %r | 字符串 (采用repr()的显示)详细 见倒数第2页PPT |
| %c | 单个字符 |
| %d | 十进制整数 |
| %i | 十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数 |
| %e | 指数 (基底写为e) |
| %E | 指数 (基底写为E) |
| %f、%F | 浮点数 |
| %g | 指数(e)或浮点数 (根据显示长度) |
| %G | 指数(E)或浮点数 (根据显示长度) |
| %% | 一个字符"%" |
例子
>>> int('555')
555
>>> '%s'%[1, 2, 3] #直接把对象转换成字符串
'[1, 2, 3]'
>>> str((1,2,3)) #直接把对象转换成字符串
'(1, 2, 3)'
>>> str([1,2,3])
'[1, 2, 3]'
>>> list(str([1, 2, 3])) #字符串中的每个字符都成为列表的元素(特别注意空格哦,英文规范)
['[', '1', ',', ' ', '2', ',', ' ', '3', ']']
>>> eval(str([1, 2, 3])) #eval() 函数用来执行一个字符串表达式,并返回表达式的值。
[1, 2, 3]
>>>x = 7
>>> eval('3 * x')
21
>>> eval('pow(2,2)')
4
>>> eval('2 + 2') 4
>>> n=81
>>> eval("n + 4")
85
.format:
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
>>>"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序
'hello world’
>>> "{0} {1}".format("hello", "world") # 设置指定位置
'hello world’
>>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
'world hello world’
数字格式化:
>>> print("{:.2f}".format(3.1415926));
3.14
一些内置函数也可以操作字符串:
>>> x = 'Hello world.'
>>> len(x) #字符串长度
12
>>> max(x) #最大字符
'w'
>>> min(x)
' '
>>> list(zip(x,x)) #zip()也可以作用于字符串
[('H', 'H'), ('e', 'e'), ('l', 'l'), ('l', 'l'), ('o', 'o'), (' ', ' '), ('w', 'w'), ('o', 'o'), ('r', 'r'), ('l', 'l'), ('d', 'd'), ('.', '.')]
>>> max(['abc', 'ABD'], key=str.upper) #忽略大小写
'ABD'
切片也适用于字符串,但仅限于读取其中的元素,不支持字符串修改。
>>> 'Explicit is better than implicit.'[:8]
'Explicit'
>>> 'Explicit is better than implicit.'[9:23]
'is better than
与字符串处理有关的标准库
#Python标准库string中定义数字字符、标点符号、英文字母、大写字母、小写字母等常量。
>>> import string
>>> string.digits
'0123456789'
>>> string.punctuation
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
>>> string.ascii_letters
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
>>> string.ascii_lowercase
'abcdefghijklmnopqrstuvwxyz'
>>> string.ascii_uppercase
'ABCDEFGHIJKLMNOPQRSTUVWXYZ
应用:随机密码生成原理。
string.ascii_uppercase 所有大写字母
string.ascii_lowercase 所有小写字母
string.ascii_letters 所有字母
>>> import string
>>> characters = string.digits + string.ascii_letters
>>> import random
>>> ''.join([random.choice(characters) for i in range(8)])
'J5Cuofhy'
>>> ''.join([random.choice(characters) for i in range(10)])
'RkHA3K3tNl'
>>> ''.join([random.choice(characters) for i in range(16)])
'zSabpGltJ0X4CCjh'
编写程序,把一个英文句子中的单词倒置
标点符号不倒置,例如 I like python. 经过函数后变为:python. like I
def rev1(s):
return ’ '.join(reversed(s.split()))
def rev2(s):
t = s.split()
t.reverse()
return ’ '.join(t)
def rev5(s):
‘’‘字符串整体逆序,分隔,再各单词逆序’’’
t = ‘’.join(reversed(s)).split()
t = map(lambda x:’’.join(reversed(x)), t)
return ’ '.join(t)
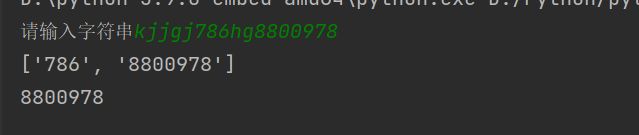
例: 编写程序,查找一个字符串中最长的数字子串。
result = []
temp = []
str = input("请输入字符串")
for character in str:
if '0' <= character <='9':
temp.append(character)
elif temp:
result.append(''.join(temp))
temp = []
if temp: # 用于处理结尾为数字的字符串的情况
result.append(''.join(temp))
if result:
print(result)
print(max(result,key=len)) # 取列表中最大的元素,以元素的长度为条件
else:
print("no")
面向对象程序设计
Python完全采用了面向对象程序设计的思想,是真正面向对象的高级动态编程语言,完全支持面向对象的基本功能,如封装、继承、多态以及对基类方法的覆盖或重写。
Python中对象的概念很广泛,Python中的一切内容都可以称为对象,除了数字、字符串、列表、元组、字典、集合、range对象、zip对象等等,函数也是对象,类也是对象。
创建类时用变量形式表示的对象属性称为数据成员,用函数形式表示的对象行为称为成员方法,成员属性和成员方法统称为类的成员。
Python使用class关键字来定义类
class关键字之后是一个空格,然后是类的名字,再然后是一个冒号,最后换行并定义类的内部实现。
类名的首字母一般要大写
当然也可以按照自己的习惯定义类名,但一般推荐参考惯例来命名,并在整个系统的设计和实现中保持风格一致。
class Car:
def infor(self):
print(" This is a car ")
类定义后,可以用来实例化对象,并通过“对象名.成员”的方式来访问其中的数据成员或成员方法
car = Car()
car.infor()
This is a car
self参数:
▶▶▶类的所有实例方法都必须至少有一个名为self的参数,且必须是方法的第一个形参(如果有多个形参的话),self参数代表将来要创建的对象本身。
▶▶▶在类的实例方法中访问实例属性时需以self为前缀。
▶▶▶在外部通过对象调用对象方法时并不需要传递这个参数,如果在外部通过类调用对象方法则需要显式为self参数传值。
▶▶▶在类中定义实例方法时将第一个参数定义为“self”只是一个习惯,虽不必须使用,仍建议编写代码时仍以self作为方法的第一个参数名字。
▶▶▶属于实例的数据成员一般是指在构造函数__init__()中定义的,定义和使用时必须以self作为前缀;属于类的数据成员是在类中所有方法之外定义的。
▶▶▶在主程序中(或类的外部),实例属性属于实例(对象),只能通过对象名访问;而类属性属于类,可以通过类名或对象名都可以访问。
▶▶▶在实例方法中可以调用该实例的其他方法,也可以访问类属性以及实例属性。

例子:
class Person(object):
def __init__(self, name): # 构造函数
assert isinstance(name, str), 'name must be string'
self.name = name
def walk(self):
print(self.name + ' can walk.')
def eat(self):
print(self.name + ' can eat.')
zhang = Person('zhang')
def sing(self):
print(self.name + ' can sing.')
#
zhang.sing = types.MethodType(sing, zhang) #动态增加一个新行为
zhang.sing()

在Python中,函数和方法是有区别的。
方法一般指与特定实例绑定的函数,通过对象调用方法时,对象本身将被作为第一个参数隐式传递过去,普通函数并不具备这个特点。
私有成员和公有成员
Python并没有对私有成员提供严格的访问保护机制。
在定义类的成员时,如果成员名以两个下划线“__”或更多下划线开头而不以两个或更多下划线结束则表示是私有成员。
私有成员在类的外部不能直接访问,需要通过调用对象的公开成员方法来访问,也可以通过Python支持的特殊方式来访问。
公开成员既可以在类的内部进行访问,也可以在外部程序中使用。
class A:
def __init__(self, value1 = 0, value2 = 0):
self._value1 = value1
self.__value2 = value2
def setValue(self, value1, value2):
self._value1 = value1
self.__value2 = value2
def show(self):
print(self._value1)
print(self.__value2)
a = A()
print(a._value1)
print(a._A__value2) #在外部访问对象的私有数据成员
Python中以下划线开头的变量名和方法名有特殊含义,尤其是在类的定义中。
_xxx:受保护成员,不能用’from module import *'导入;
xxx:系统定义的特殊成员;
__xxx:私有成员,只有类对象自己能访问,子类对象不能直接访问到这个成员,但在对象外部可以通过“对象名._类名__xxx”这样的特殊方式来访问
注意:Python中不存在严格意义上的私有成员。
>>> class Fruit:
def __init__(self):
self.__color = 'Red'
self.price = 1
>>> apple = Fruit()
>>> apple.price #显示对象公开数据成员的值
1
>>> apple.price = 2 #修改对象公开数据成员的值
>>> apple.price
2
>>> print(apple.price, apple._Fruit__color) #显示对象私有数据成员的值
2 Red
>>> apple._Fruit__color = "Blue" #修改对象私有数据成员的值
>>> print(apple.price, apple._Fruit__color)
2 Blue
>>> print(apple.__color)
AttributeError: Fruit instance has no attribute '__color'
类中的方法
在类中定义的方法可以粗略分为四大类:
公有方法、私有方法、静态方法和类方法。
▶▶▶私有方法的名字以两个下划线“__”开始,每个对象都有自己的公有方法和私有方法,在这两类方法中可以访问属于类和对象的成员;
▶▶▶公有方法通过对象名直接调用,私有方法不能通过对象名直接调用,只能在属于对象的方法中通过self调用或在外部通过Python支持的特殊方式来调用。
▶▶▶如果通过类名来调用属于对象的公有方法,需要显式为该方法的self参数传递一个对象名,用来明确指定访问哪个对象的数据成员。
class Root:
__total = 0
def __init__(self, v): #构造方法
self.__value = v
Root.__total += 1
def show(self): #普通实例方法
print('self.__value:', self.__value)
print('Root.__total:', Root.__total)
@classmethod #修饰器,声明类方法
def classShowTotal(cls): #类方法
print(cls.__total)
@staticmethod #修饰器,声明静态方法
def staticShowTotal(): #静态方法
print(Root.__total)
a = Root(8)
a.show()
b= Root(5)
b.show()
Root.show() #试图通过类名直接调用实例方法,失败
r = Root(3)
Root.show(r) #但是可以通过这种方法来调用方法并访问实例成员
self.__value: 8
Root.__total: 1
self.__value: 5
Root.__total: 2
▶▶▶Python中类的构造函数是__init__(),一般用来为数据成员设置初值或进行其他必要的初始化工作,在创建对象时被自动调用和执行。如果用户没有设计构造函数,Python将提供一个默认的构造函数用来进行必要的初始化工作。
▶▶▶Python中类的析构函数是__del__(),一般用来释放对象占用的资源,在Python删除对象和收回对象空间时被自动调用和执行。如果用户没有编写析构函数,Python将提供一个默认的析构函数进行必要的清理工作。

属性
类属性是在类中方法(也就是类中的函数)之外但又在类之中定义的属性;而实例属性是在构造函数中定义的(init),定义时候以self作为前缀。类属性在所有实例之间共享。在类内部和类外部都可以通过“类.类属性” 来访问。
只读属性
class Test:
def __init__(self, value):
self.__value = value
@property
def value(self): #只读,无法修改和删除
return self.__value
可读、可写属性
>>> class Test:
def __init__(self, value):
self.__value = value
def __get(self):
return self.__value
def __set(self, v):
self.__value = v
value = property(__get, __set)
def show(self):
print(self.__value)
继承
构造函数、私有方法以及普通公开方法的继承原理。
父类:
>>> class A(object):
def __init__(self): #构造方法可能会被派生类继承
self.__private()
self.public()
def __private(self): #私有方法在派生类中不能直接访问
print('__private() method in A')
def public(self): #公开方法在派生类中可以直接访问,也可以被覆盖
print('public() method in A')
继承类1:
class B(A): #类B没有构造方法,会继承基类的构造方法
def __private(self): #这不会覆盖基类的私有方法
print('__private() method in B')
def public(self): #覆盖了继承自A类的公开方法public
print('public() method in B')
>>> b = B() #自动调用基类构造方法
__private() method in A
public() method in B
>>> dir(b) #基类和派生类的私有方法访问方式不一样
['_A__private', '_B__private', '__class__', ...]
继承类2:
class C(A):
def __init__(self): #显式定义构造函数
self.__private() #这里调用的是类C的私有方法
self.public()
def __private(self):
print('__private() method in C')
def public(self):
print('public() method in C')
>>> c = C() #调用类C的构造方法
__private() method in C
public() method in C
>>> dir(c)
['_A__private', '_C__private', '__class__', ...]
Python支持多继承(Multiple Inheritance)
多继承下的Method Resolution Order(MRO):
如果父类中有相同的方法名,而在子类中使用时没有指定父类名,则Python解释器将从左向右按顺序进行搜索。
所谓多态(polymorphism),是指基类的同一个方法在不同派生类对象中具有不同的表现和行为。派生类继承了基类行为和属性之后,还会增加某些特定的行为和属性,同时还可能会对继承来的某些行为进行一定的改变,这都是多态的表现形式。
Python大多数运算符可以作用于多种不同类型的操作数,并且对于不同类型的操作数往往有不同的表现,这本身就是多态,是通过特殊方法与运算符重载实现的。