Java面试题和答案-有图、包括Mysql、Redis等
最近整理一下面试题、以备不时只需,这些题目来源于网上各位大佬,也有一些是自己的理解,难免有不对的地方,如果有还请各位指正,谢谢
不是一次写完、持续更新
Java基础
1、String类是否可以可以被继承
String类的声明时使用final修饰,所以不能被继承
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
/** use serialVersionUID from JDK 1.0.2 for interoperability */
private static final long serialVersionUID = -6849794470754667710L;
2、String类为什么要使用final修饰
因为字符串是不可变的,所以在它创建的时候Hash Code就被缓存了,不需要重新计算。Map中的键值往往使用这字符串。
因为它能够缓存结果,当你在传参时不需要考虑谁会修改它的值;如果是可变类的话,则有可能需要重新拷贝出来一个新值进行传参,这样在性能上就会有一定的损失
3、final的用法
修饰变量,一旦赋值不可被修改,也就是我们说的常量
修饰方法则表示不可被覆盖
修饰类则不可被继承
注:final不可与abstract一起使用
4、两个对象的equals为true,但却有不同的hashcode,这句话对吗?
不对,equals为true则hashcode则一定相同,而hashcode相同,equals则不一定相同
在Joshua Bloch的大作《Effective Java》中这样介绍equals:首先equals方法必须满足自反性(x.equals(x)必须返回true)、对称性(x.equals(y)返回true 时,y.equals(x)也必须返回true)、传递性(x.equals(y)和y.equals(z)都返回true时,x.equals(z)也必须返回true)和一致性(当x和y引用的对象信息没有被修改时,多次调用x.equals(y)应该得到同样的返回值),而且对于任何非null值的引用x,x.equals(null)必须返回false
5、如何跳出多重嵌套循环
在for前面加关键字,然后在需要跳出的地方 break 关键字
public void breakfor()
{
breakflag: for (int i=0;i<10;i++)
{
for (int j=0;j<10;j++)
{
break breakflag;
}
}
}
6、重载(overload)和重写(override)的区别
重载发生在同一个类中,就是说同一个方法可以有不同的参数,参数的个数顺序不同都可以称为重载
重写发生在两个类中,即子类继承父类的方法,然后可以重新改变这个方法的业务逻辑,但是必须与父类的放回值相同,不能比父类方法声明更多的异常(里氏替换原则)
7、当一个对象被当为参数传递,在方法中改变对象的属性,并返回改变后的结果,那么这里是值传递还是引用传递
是值传递。Java只支持参数的值传递,当一个对象被当作参数传递到方法时,参数的值就是该对象的内存地址。这个值(内存地址)被传递后,同一个内存地址指向堆内存当中的同一个对象,所以通过那个引用去操作这个对象,对象的属性都是改变的
注意:
基本数据类型的值传递,不会改变原值,因为调用后立马会弹栈,而所声明的局部变量则消失
public class test {
public static void main(String[]args){
int a=10;
change(a);
System.out.println(a);//a还是10
}
public static void change(int a)
{
//这个方法完后,栈中值被销毁,也叫弹栈
a=20;
}
}
引用数据类型的值传递,是改变原值的,因为即使方法弹栈,但是堆内存中数组对象还在,还可以通过地址继续访问的
8、抽象类(abstract)接口(interface)的异同
相同
- 不能实例化
- 可以作为引用类型
- 一个类如果继承抽象类
9、char型变量中能不能存储一个中文汉字,为什么?
可以,因为Java中使用的编码是Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号),一个char占2个字节(16比特),所以可以放一个中文
10、break和continue的区别
break用于完全结束一个或多个循环,continue用于跳过本次循环进行下一次循环
11、==和equals的区别
- equals是方法==是运算符
- == 如果比较对象是基本类型,则比较值是否相等。如果比较的是引用类型,则比较引用地址是否相等
- equals默认情况下是引用比较,而一些String、Integer等把它变成了值比较,一般情况下equals比较的是值是否相等
String str1=new String("123");
String str2=new String("123");
System.out.print(str1.equals(str2));//true
System.out.print(str1==str2);//false
String重写了equals
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
12、String s=“Hello”;s=s+" world",原始String对象中的内容变了没有
没有,因为String对象都是不可变对象,所以原始对象中的内容没有变化,我们看到后面s=“Hello World”是因为s指向了另外一个对象
13、String、StringBuffer、StringBuilder的区别
- String每次操作都会生成新的String对象,而其它两个不会都是在原有对象上操作,所以经常改变字符串内容的情况下最好不用String
- StringBuffer是线程安全的,而StringBuilder不是线程安全的,所以StringBuilder的性能却高于StringBuffer,所以单线程下使用StringBuilder,多线程下使用StringBuffer
14、字符串反转
StringBuilder和StringBuffer的reverse()
15、String类的常用方法
- indexOf():返回指定字符串的索引
- equals:字符串比较
- length():返回字符串的长度
- substring():截取字符串
- split():分割字符串,返回字符串数组
- replace():字符串替换
- toLowerCase():将字符串转小写
- 同UpperCase():将字符串转大写
16、抽象类必须有抽象方法吗
不需要,如下代码,没有抽象类但可以正常运行
abstract class test1 {
public static void test()
{
}
}
17、普通类和抽象类的区别
- 普通类不包含抽象方法,抽象类可以包含抽象方法
- 抽象类不能实例化,普通类可以实例化
- 抽象类不能用final修饰,普通类可以
18、抽象类和接口的区别
- 实现:抽象类的子类使用extends来继承,类使用implements来实现接口
- 构造函数:抽象类可以有构造函数,接口没有
- main方法:抽象类有,接口没有
- 实现数量:类只能继承一个抽象类,但可以继承多个接口
- 访问修饰符:Java中Interface方法默认访问修饰符为:public abstract;Interface常量的默认访问修饰符为:public static final;抽象类有任意访问修饰符
19、BIO、NIO、AIO的区别
- BIO:Block IO 同步阻塞IO,传统IO,它的特点是模式简单使用方便,并发处理能力低
- NIO:New IO同步非阻塞IO,传统IO的升级,客户端和服务端通过Channel(通道)通讯,实现多路复用
- AIO:Asynchronous IO 是NIO的升级,也叫NIO2,实现异步非阻塞,异步IO的操作基于事件和回调机制
20、Java中的基本类型
byte、boolean、char、short、int、long、float、double
21、JDK和JRE有什么区别
- JDK:Java Development Kit的简称,Java开发工具包,提供Java的开发环境和运行环境
- JRE:Java Runtime Environment的简称,Java运行环境,为Java的运行提供所需环境
22、封装、继承、多态
- 封装:使用者按照既定的方式调用方法,不需要关心方法的内部实现,便于修改,增强代码的复用和可维护性
- 继承:新类继承已有类的属性和行为,并扩展新的能力。能有效避免多个类对相同特征的重复描述,能使系统模型看上去简单、清晰,比如:猫、够都可以抽象出一个动物类,其包含吃饭、奔跑等行为
- 多态:子类继承父类,存在对父类方法的重写,在调用时父类引用指向子类对象。多态必备的三个要素:继承、重写、父类引用指向子类对象
23、JDK1.8的新特性
- Lambda表达式:可以使代码更具可读性,也能使代码更简单。如对字符串排序
//需要排序的集合
List<String>names= Arrays.asList("zz","dd","ssd");
//没用Lambda表达式
Collections.sort(names, new Comparator<String>() {@Override public int compare(String a,String b){return b.compareTo(a);}
});
//以下是两种用了Lambda表达式的排序
names= Arrays.asList("zz","dd","ssd");
Collections.sort(names,(a,b)->b.compareTo(a));
names= Arrays.asList("zz","dd","ssd");
Collections.sort(names,Comparator.reverseOrder());
- 集合中的Stream接口:java.util.Stream表示能应用在一组元素上一次执行的操作序列。Stream分为中间操作和最终操作两种,最终操作返回一个特定类型的计算结果,中间操作返回Stream本身,这样可以多个操作串起来。Stream需要一个数据源,可以是List和Set,Map不行
- Clock类(时钟类):访问当前日期和时间的方法
Clock clock= Clock.systemDefaultZone();
long millis=clock.millis();
Instant instant=clock.instant();
- Timezones时区:
ZoneId zoneId=ZoneId.of("Brazil/East");
- LocalTime本地时间
ZoneId zoneId=ZoneId.of("Brazil/East");
LocalTime localTime=LocalTime.now();//10:38:44.656
localTime=LocalTime.now(zoneId);//23:39:14.125
- LocalDateTime本地日期时间
LocalDateTime localDateTime=LocalDateTime.of(2011,Month.DECEMBER,31,23,31,31);
int dayOfMonth=localDateTime.getDayOfMonth();
int hour=localDateTime.getHour();
int minute=localDateTime.getMinute();
int second=localDateTime.getSecond();
- 支持多重注解
24、Java异常处理方式

//throws 放在方法的声明处
public void testThrow()throws IOException {
boolean a = false;
try {
//try 需要捕捉错误的代码
} catch (Exception e) {
//catch 出错后处理逻辑
//throw 抛出异常
throw e;
}
finally
{
//finally 不管代码是否异常都会进来,一般释放资源,比如IO流的释放
}
//throw 抛出自定义异常
if (a)
throw new IOException("IO异常");
}
两种异常处理的方式,try一定要有,可以搭配finally或catch,也可以像上面一样两个都搭配
public static void testThrow()
{
try{}
finally {}
try{}
catch (Exception e){}
}
25、雪花算法的组成
- 符号位,占1位
- 时间戳,占41位,可以支持69年的时间跨度
- 机器ID,占用10位
- 序列号,占用12位,一毫秒生成4095个ID

26、分布式锁在项目中的哪些场景用到
- 系统是分布式集群,Java锁不能对集群适用
- 操作共享资源
27、分布式锁有哪些方案
- 使用Redis分布式锁,用setnx、Redisson。
在使用setnx会遇到一个问题,如果程序对它设置锁立马就挂了,然后其它程序就不能访问这个key了,所以用setnx的同时一定要对这个key加过期时间(redis.setnx(key_mutex, 1, 3 * 60));还有一个问题就是加锁时间10秒,执行业务需要20秒,所以需要一个watch dog每5秒看一下然后把锁时间改成10秒,避免业务没完锁就释放掉了,然后其它线程就来访问相同的业务操作
Redisson是Redis官方推荐的Java版客户端,直接有方法进行分布式锁,比如默认的非公平锁
RLock lock=redisson.getLock("anyLock");
//可以指定超时时间
lock.lock(10,TimeVnit.SECONDS);
boolean res=lock.tryLock(10,10,TimeUnit.SECONDS);
if(res)
try{}finally{lock.unlock()}
redis加锁产生死锁的两种情况:加锁没有释放锁(没有delete key)和加锁程序挂了(需要加过期时间)
- Zookeeper,临时节点和顺序节点
- 数据库实现:建一个表,表中包括方法名、主键等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就是用这个方法名向表中插入数据,成功插入则获取锁,执行完后删除对应的行数据以释放锁
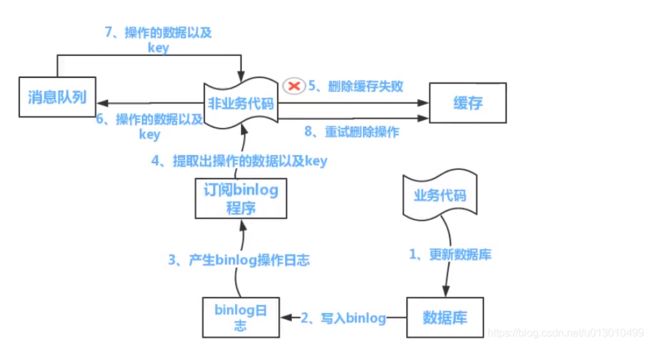
28、Redis和MySQL双写一致性
使用先更新数据库再删除缓存的操作
操作缓存的套路
- 失效:应用 程序先从缓存中取数据,没有则去数据库取,然后放到缓存中
- 命中:应用程序从缓存中取数据,取到返回
- 更新:先把数据更新到数据库中,成功后删除缓存
使用更新数据库再删除缓存的操作也会存在并发问题:
1、缓存刚好失效
2、请求A查询数据库,得到一个旧值
3、请求B将新值写入数据库
4、请求B删除缓存
5、请求A将旧值写入缓存,这里就会出现脏数据
解决方案:1种是给缓存设置过期时间;另一种是异步延迟双删
public void write(String key,Object data){
redis.delKey(key);
Thread.sleep(1000);
redis.delKey(key);
}
还有一个问题就是缓存更新失败,解决方案如下
方案一
方案二
Java集合
Java集合关系

第一代:线程安全集合:Vector、Hashtable,使用synchronized保证线程安全
第二代:非线程安全集合:ArrayList、HashMap,如果要实现线程安全用Collections.synchronizedList(list);Collections.synchronizedMap(m),这里的锁在方法里面,比第一代效率高
第三代:线程安全集合:都在java.util.concurrent.* 包里面有ConcurrentHashMap,使用分块锁比第二代高
1. ArrayList、HashSet、HashMap是线程安全的吗?如果不是怎么获取线程安全的集合?
ArrayList、HashSet、HashMap都不是线程安全的。在集合中只有Vector和HashTable是线程安全的
2. 什么是JAVA集合
java 集合既用来存放对象的容器
- 集合主要分为Collection和Map两个接口
- Collection又分别被List和Set继承
- List被AbstractList实现,又分为ArrayList、LinkList和VectorList
- Set被AbstractSet实现,又分为HashSet和TreeSet
- Map被AbstractMap实现,又分为HashMap和TreeMap
- Map被Hashtable实现
3. 哈希碰撞/哈希冲突是什么,如何解决?
-
在对字符串,文件,甚至目录进行hash取值时,有可能得到的多个一样的hash值,这就是hash碰撞/hash冲突。举个众所周知的Hash函数CRC32,如果你给这个Hash函数“plumless” 和“buckeroo”这2个字符串,它会生成相同的Hash值,这是已知的Hash冲突

解决方法有:
1.开放地址法(再散列法)
开放地执法有一个公式:Hi=(H(key)+di) MOD m i=1,2,…,k(k<=m-1)
其中,m为哈希表的表长。di 是产生冲突的时候的增量序列。如果di值可能为1,2,3,…m-1,称线性探测再散列。如果di取1,则每次冲突之后,向后移动1个位置.如果di取值可能为1,-1,2,-2,4,-4,9,-9,16,-16,…kk,-kk(k<=m/2),称二次探测再散列。如果di取值可能为伪随机数列。称伪随机探测再散列。
2.再哈希法Rehash
当发生冲突时,使用第二个、第三个、哈希函数计算地址,直到无冲突时。缺点:计算时间增加。比如上面第一次按照姓首字母进行哈希,如果产生冲突可以按照姓字母首字母第二位进行哈希,再冲突,第三位,直到不冲突为止.这种方法不易产生聚集,但增加了计算时间。
3.链地址法(拉链法)
将所有关键字为同义词的记录存储在同一线性链表中.基本思想:将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。对比JDK 1.7 hashMap的存储结构是不是很好理解。至于1.8之后链表长度大于6rehash 为树形结构不在此处讨论。
4. ArrayList和LinkedList的不同?
两个都实现List接口,但ArrayList底层是数组而LinkedList是链表
在ArrayList的前面或中间插入数据时,必须将其后所有的数据相应的后移,这会浪费很多时间,当然如果是只在集合后面添加元素,并随机访问其中元素时,使用ArrayList性能还是很出色的。
如果是对集合的前面或者红箭添加或删除数据时,并按照顺序访问其中的元素时,就应该使用LinkedList
总的来说ArrayList的查询效率高,增删效率差,适用于频繁查询和增删少的场景,而LinkedList的查询效率低,但增删效率高,使用与增删动作频繁和查询次数少的场景
5. ArrayList和Vector的区别?
-
同步性
Vector是线程安全的,而ArrayList不是线程安全的,如果是一个线程访问集合最好用ArrayList,因为它不考虑线程安全所以效率会高一些;如果有多个线程访问集合就用Vector,因为不需要再去考虑和编写线程安全的代码
-
数据增长
ArrayList与Vector都有一个初始的容量大小,当存储元素超过本身容量时,Vector默认增长原来的一倍,而ArrayList增加原来的0.5倍。Vector是可以设置增长的空间大小,而ArrayList没有提供设置增长空间的方法
6. HashMap的数据存储和实现原理你了解多少
-
存值
hashmap在存数据的时候是基于hash的原理,当我们调用put(key,value)方法的时候,其实我们会先对键key调用key.hashcode()方法,根据方法返回的hashcode来找到bucket的位置来存Entry对象。
如果出现hashcode相同的情况,这时候就会产生hash碰撞(hashmap的底层存储结构是 数组+链表),这时候根据hashcode找到对应的bucket,然后在链表逐一检查有没有存相同的key,用equals()进行比较,如果有则用新的value取代旧的value,如果没有就在链表的尾部加上这个新的Entry对象
-
取值
当使用get(key)时,会调用key的hashcode方法获得hashcode,然后根据hashcode找到bucket,优于bucket对应的链表中可能存有多个Entry,这个时候会调用key的equals()找到对应的Entry,然后把值返回
7. HashMap的长度为什么是2的幂次方?
- HashMap为了存取高效,要尽量较少碰撞,就是要尽量把数据分配均匀,每个链表长度大致相同,这个实现就在把数据存到哪个链表中的算法;
这个算法实际就是取模,hash%length,计算机中直接求余效率不如位移运算,源码中做了优化hash&(length-1),
hash%length==hash&(length-1)的前提是length是2的n次方;
为什么这样能均匀分布减少碰撞呢?2的n次方实际就是1后面n个0,2的n次方-1 实际就是n个1;
8. HashSet和HashMap的区别与联系
HashSet实际上为(key,null)类型的HashMap,而我们知道,HashSet的key是不能重复的,所以HashSet的值自然也是没有重复的.因为HashMap的key可以为null,所以HashSet的值可以为null
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
9. Collection和Collections有什么区别
- Java.util.Collection是一个集合的顶级接口。它提供了对集合对象进行基本操作的通用接口方法,其直接实现有List和Set
- Collections则是集合类的一个工具类,其中提供了一系列静态方法,用于对集合中元素进行排序、搜索以及线程安全等各种操作
10. Iterator是什么
迭代器是一种设计模式,它可以遍历并选择序列中的对象,在使用时并不需要了解该对象的底层结构。迭代器通常也被称为轻量级对象,因为其创建的代价低
- 集合使用iterator()返回一个Iterator,调用Iterator的next()方法时,返回一个元素,iterator()是java.lang.Iterable接口,被Collection继承
- 使用hashNext()检查序列中给是否还有元素
- 使用remove()将迭代器返回的元素删掉
11. Iterator和List Iterator有什么区别
- Iterator可用来遍历Set和List集合,但是List Iterator只能用来遍历List
- Iterator对集合只能是前向遍历,List Iterator向前、后都可以
- List Iterator实现了Iterator接口,并包含对集合操作的方法,如:增删改查元素
12. HashMap和HashTable的区别
- HashTable是线程同步的,HashMap不是线程同步的
- HashTable key和value不允许有空值,HashMap允许有空值
- HashTable可以使用Enumeration和Iterator,HashMap使用Iterator
- HashTable中hash数组的默认大小是11,增加方式是old*2+1,HashMap中的hash数组的默认大小是16,增长方式是2的指数倍
- HashTable继承Dictionary类,HashMap继承AbstractMap类
Redis
1.Redis的特点
Redis全称Remote Dictionary Server(远程字典服务),用C编写,NoSQL数据库服务器。其本质是一个key-value的内存数据库,类似于memcached,其QPS能达到数十万次,单个value的最大限制1GB,而memcahed只有1MB,其支持的数据结构有: 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)
Redis的缺点就是其是内存数据库,其上限受限于运行的物理内存的大小
2.Redis的性能问题及解决放案
- Redis做内存快照(内存中数据在某一个时刻的转态记录)是有两个命令:
save:在主线程中执行,会导致阻塞
bgsave:创建一个子进程,专门写RDB文件,避免主线程阻塞,这是Redis RDB文件生成的默认配置。但是fork 创建过程中本身会阻塞主线程,主线程内存越大阻塞时间越长
- AOF持久化会导致重启恢复速度变慢
- Redis主从复制的速度和连接的稳定性受网络的影响,Master和Slave最好在一个局域网中
3.Redis使用的场景
● 会话缓存(Session Cache)
● 全页缓存(FPC)
● 队列
● 排行榜/计数器
● 发布/订阅
4.Redis的优缺点
优点
● QPS能达到数十万
● 所有的操作都是原子性的,也就是说一个操作要么成功要么失败,就像关系型数据库中的事务
● 支持丰富的数据类型
缺点
●因为是内存数据库所以受限于机器本身的内存大小,Redis本身可以有过期策略,但内存增长过快时需要定期 删除数据
●在重启Redis时,持久化的数据越大加载越慢,在完成加载之前,Redis将不提供服务
5.Redis的持久化是什么
RDB持久化:Redis默认的持久化方案。在指定的时间间隔内将内存中的数据写入到磁盘中,这些数据写在指定目录下的dump.rdb文件,Redis重启会通过dump.rdp文件恢复数据,因为是定时备份所以会有数据丢失的情况
AOF持久化:Redis默认不开启。它是为了弥补RDB的不足(数据丢失或数据不一致),所以它采用写日志的方式记录所有的写操作,Redis重启会通过日志文件恢复数据,这种情况如果数据量比较大的话,启动就会慢
RDB和AOF同时应用时:当Redis重启的时候,它会优先使用AOF来还原数据,因为数据比较全
6.RDB和AOF优缺点
优点
RDB:RDB是定时备份的,可以随时将数据还原到不同版本,也比较适用于灾难性恢复
AOF:AOF对日志文件进行追加,在日志进行写入过程中关机了或磁盘满了,使用redis-check-aof工具也可以修复这些问题
缺点
RDB:如果对数据完整性有要求的话就不适用于RDB,因为会丢数据。
每次保存RDB时,Redis都要fork()出一个子进程,由子进程进行数据持久化的工作。数据集比较大时,fork()会比较耗时,可能会在一定毫秒内停止处理客户端的请求
AOF:AOF数据量比较大,使用fsync策略,恢复数据速度慢于RDB
7、Redis是单线程的为什么会那么快?
- Redis是内存数据库,所以不需要进行磁盘IO
- 数据操作简单,不需要进行联合查找,读写操作都是O(1)
- 单线程访问数据不需要加锁
- 多路I/O复用模型,多路即多连接、复用就是用同一个线程
8、Redis的过期key删除策略
- 过期精度:0-1毫秒
- 会发生的问题:Keys的过期时间使用Unix时间戳存储(单位毫秒),也就是说你设置key的有效期是1分钟,但是你将电脑时间调到未来的2分钟,这时key就会立即失效。如果将RDB文件放到两个时间不同步的电脑上,有可能发生key加载就过期的事情
- Redis淘汰过期kyes
被动方式:客户端主动访问时发现key过期了,就主动删除
主动方式:很多key是永远都不会访问的,所以Redis没秒会做十次以下事情
1、测试随机20个key进行相关过期检查
2、删除所有已经过期的key
3、如果有多于25%的key过期,重复这些步骤
9、Redis缓存回收
- volatile-lru:从设置了过期时间的数据集中,选择最近最久未使用的数据释放;
- allkeys-lru:从数据集中(包括设置过期时间以及未设置过期时间的数据集中),选择最近最久未使用的数据释放;
- volatile-random:从设置了过期时间的数据集中,随机选择一个数据进行释放;
- allkeys-random:从数据集中(包括了设置过期时间以及未设置过期时间)随机选择一个数据进行入释放;
- volatile-ttl:从设置了过期时间的数据集中,选择马上就要过期的数据进行释放操作;
- noeviction:不删除任意数据(但redis还会根据引用计数器进行释放),这时如果内存不够时,会直接返回错误。
10、Redis集群方案
- 主从复制集群,需要手动切换
- 哨兵模式的主从复制集群,每个节点是全部数据,不需要手动切换
- Redis自身实现的Cluster分片集群,每个节点存部分数据
11、Redis事务时怎么实现的
1.事务开始:MULTI,执行此命令代表事务开始
2.命令入队:QUEUED状态
3.事务执行:EXEC
redis> MULTI
OK
redis> SET "name" "ds"
QUEUED
redis> GET "name"
QUEUED
redis> EXEC
1) OK
2) "ds"
Redis不支持回滚:Redis命令只有因为错误的语法而失败,这些失败的命令在开发中就应该发现,而不是在生产环境中出现,所以不需要考虑
12、缓存雪崩、缓存穿透、缓存击穿在实际中怎么处理
- 缓存穿透:在Redis中查询一个不存在的key,为了容错,在redis中没有查到就会去数据库查,如果每次都去数据库查Redis就没有意义了,而且如果有人故意利用不存在的key去访问数据库,数据库就有可能挂掉
解决方案:采用布隆过滤器,把所有可能存在的数据哈希到一个bitmap中,然后过滤不存在的数据;还有就是把空结果进行缓存,但过期时间设短一点,两三分钟就好 - 缓存击穿:设置过期时间的key,在过期的这个时间点有大量请求来访问它,因为访问不到,而去访问数据库,所以有可能导致数据库挂掉
解决方案:设置热点数据永不过期;加互斥锁(mutex key),就是缓存返回是否为空,其为空就设置mutex key,然后去数据库中拿数据,并把数据放到redis中
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
- 缓存雪崩:很多key同时失效,大量请求同时访问数据库
解决方案:设置热点数据永不过期;在原有失效时间的基础上加一个随机值,1-5分钟随机,这样每一个缓存的过期时间重复率就会降低,不会引起大量key集体失效的事情
穿透:缓存不存在,数据库不存在,高并发,少量key
击穿:缓存不存在,数据库存在,高并发,少量key
雪崩:缓存不存在,数据库存在,高并发,大量key
7.Redis的数据类型
-
字符串(strings):String数据结构是最简单的key-value类型
用法:
192.168.1.167:6379> set name dd OK 192.168.1.167:6379> get name "dd" -
散列(hashes):类似Java中的hash,可以存放对象值,如用户:用户名、年龄等,具体通过
HMSET指令设置 hash 中的多个域,而HGET取回单个域,hgetall取得所有域用法:
192.168.1.167:6379> hset user:1000 username dd birthyear 1999 verified 11 (integer) 3 192.168.1.167:6379> hget user:1000 username "dd" 192.168.1.167:6379> hgetall user:1000 1) "username" 2) "dd" 3) "birthyear" 4) "1999" 5) "verified" 6) "11" 192.168.1.167:6379> -
列表(lists):List其实就是双向链表,rpush 设置一个列表值,lrange 获取一个列表值
用法:
192.168.1.167:6379> rpush list a (integer) 1 192.168.1.167:6379> rpush list b (integer) 2 192.168.1.167:6379> rpush list c (integer) 3 192.168.1.167:6379> lrange list 0 -1 1) "a" 2) "b" 3) "c" 192.168.1.167:6379> -
集合(sets):Set 是 String 的无序排列,就是不根据插入顺序进行排序。集合中不能出现重复数据。set是通过hash实现的,所以增删查的时间复杂度都是o(1)。
SADD指令把新的元素添加到 set 中。对 set 也可做一些其他的操作,比如测试一个给定的元素是否存在,对不同 set 取交集,并集或差,等等用法:
192.168.1.167:6379> sadd myset 2 3 1 (integer) 3 192.168.1.167:6379> smembers myset 1) "1" 2) "2" 3) "3" 192.168.1.167:6379> -
有序集合(sorted sets) :有序集合和集合一样是string类型的集合,但不允许有重复元素。每个元素都有一个double类型的分数,redis通过这个分数从小到大进行排序。因为有序集合也通过hash实现,所以增删查的时间复杂度o(1)
用法:
192.168.1.167:6379> zadd mysortedset 1 b (integer) 1 192.168.1.167:6379> zadd mysortedset 2 a (integer) 1 192.168.1.167:6379> zadd mysortedset 3 c (integer) 1 192.168.1.167:6379> zadd mysortedset 2 d (integer) 1 192.168.1.167:6379> zrange mysortedset 0 10 1) "b" 2) "a" 3) "d" 4) "c" 192.168.1.167:6379> -
范围查询bitmaps:通过一个bit来标识元素对应的值
用法:
192.168.1.167:6379> setbit mybit 1 1 (integer) 0 192.168.1.167:6379> setbit mybit 2 1 (integer) 0 192.168.1.167:6379> setbit mybit 3 1 (integer) 0 192.168.1.167:6379> bitcount mybit (integer) 3 192.168.1.167:6379> -
hyperloglogs :HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素
基数既不重复元素的个数
用法:
192.168.1.167:6379> pfadd myhyperloglog a
(integer) 1
192.168.1.167:6379> pfadd myhyperloglog b
(integer) 1
192.168.1.167:6379> pfadd myhyperloglog c
(integer) 1
192.168.1.167:6379> pfadd myhyperloglog c
(integer) 0
192.168.1.167:6379> pfcount myhyperloglog
(integer) 3
192.168.1.167:6379>
- 地理空间(geospatial) :存储地理位置信息
用法:
192.168.1.167:6379> geoadd point1 13.123 38.133 "name1" 13.223 38.333 "name2"
(integer) 2
192.168.1.167:6379> geopos point1 name1 name2
1) 1) "13.12299996614456177"
2) "38.13300034651486925"
2) 1) "13.22299808263778687"
2) "38.33299998487134985"
192.168.1.167:6379>
Mysql
1、常用的三种存储引擎
存储引擎:不同的数据文件在磁盘的不同组织形式
- InnoDB:数据结构用B+树,.frm为结构文件,.ibd为数据文件(数据和索引)
- MyISAM:数据结构用B+树,.frm为结构文件,.myd为数据文件,.myi为索引文件
- MEMORY:数据结构用hash,.frm为结构文件,所有数据都在内存中,处理速度快,但安全性不高
注意:MySQL8开始删除了原来的frm文件,并采用 Serialized Dictionary Information (SDI), 是MySQL8.0重新设计数据词典后引入的新产物,并开始已经统一使用InnoDB存储引擎来存储表的元数据信息。SDI信息源记录保存在ibd文件中。
如何可以查看表结构信息,官方提供了一个工具叫做ibd2sdi,在安装目录下可以找到,可以离线的将ibd文件中的冗余存储的sdi信息提取出来,并以json的格式输出到终端。
innodb和myisam的区别
- innodb支持事务,myisam不支持
- innodb支持外键,myisam不支持
- innodb支持表锁和行锁,myisam只支持表锁
- innodb索引的叶子节点存放数据,myisam存放地址
- 8.0之后innodb是默认引擎
- 两个的文件构成上不同,innodb有一个结构文件和数据索引文件,myisam有一个结构文件、数据文件和索引文件
2、为什么不用hash、二叉树、红黑树
不用hash的原因
- 利用hash需要将数据放到内存中,比较耗内存
- hash的等值查询快,但不能进行范围查找
不用二叉树和红黑树的原因
- 不管是二叉树还是红黑树,都会因为树的深度过深而造成io次数变多,影响数据读取的速度(两个树的特点就是每个节点只会放一个值,所以层数会很深)
3、为什么用B-树
图片来源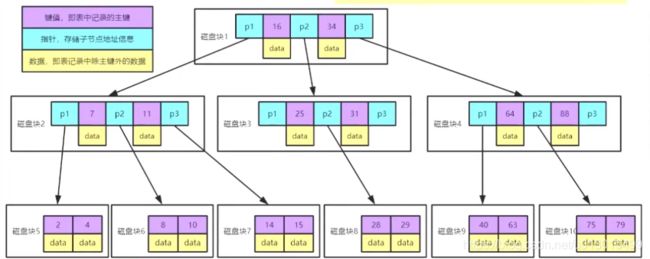
每个磁盘块相当于一页,每页是4*4=16k的数据(总容量16k),如果一页中还存数据(date),那么一页中存的数据条数就十分有限,而我们平常一张表中有百万条或千万条数据,如果用B树会导致层数变多,从而影响io的速度
4、为什么用B+树
图片来源
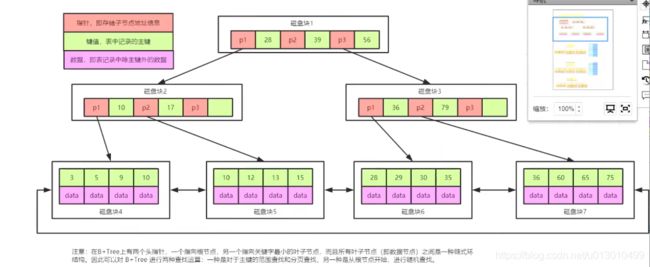
以下两点是B+树和B-树的区别,也是其优势所在
- 从上图可以看出数据(data)全部放在了最下层的叶子节点中,所以根节点(16k)能存更多的key,而我们的表一般三层或四层就可以了,也就是说查一条数据最多io三次或四次就行了(至于表是三层还是四层是根据我们数据量计算出来的)
- 最下层的叶子节点中每一个页有一个双向指针,可以横向范围查找,如果找key大于10就可以把10后面的直接拿出来(从左到右查),如果找key小于36就把36前面的直接拿出来(从右到左查)
5、索引优化的方法有哪些?
- 使用索引列进行查询时尽量不要使用表达式,如 id时索引列,使用查询语句 select id,name from table where id+1=3;
- 尽量使用主键查询,而不是其它索引,因为主键查询不会回表(主键是聚簇索引,索引和数据在一起)
- 使用前缀索引,这是对字符串很长的列作为索引来说的,如BLOB、TEXT、VARCHAR类型的列,对于VARCHAR来说如果字符串不够长可以用整列作为索引,因为其选择性高,可以让MySQL过滤更多的行,如果太长就必须要用前缀索引,以此来降低索引空间,而且MySQL也不允许太长的字符作为索引,需要对其进行限制
- 使用索引来排序,如果是用联合索引进行排序,需要有使用 where + 联合索引列
- 使用or索引会失效。如果单列索引or会使用索引(select
*from table where id=1 or id=3 id是单列索引);如果是联合索引:1、在全部列都是联合索引的情况下,那么会走这些列的联合索引(select name,age from table where name=‘1’ and age=3 其中name和age是联合索引)。2、如果只有部分列是索引,那么不会走索引(select * from table name=‘1’ and age =3) - 范围列可以走索引,但范围列后面的列不能走索引
- 不能进行类型转换,否则不走索引,如 select * from table name=3 这里name是varchar 所以要用 name=‘3’
- 更新十分频繁的数据和识别度不高的数据不要建索引。索引列更新B+树结构也会更新,会降低数据库性能;一百条数据其中一大半都是一样的,那这种识别度不高的就不需要建索引;识别度大于0.8才建索引(count(distinct(列名)/count(*)>0.8 ))
- 进行表连接的时候,最好不要超过三张表,而且需要join的字段,数据类型必须一致,否则不走索引
- 可以使用limit来限制输出(特别大的数据量不宜使用)
- 联合索引字段列不能超过5个
- 索引不能过多,需要根据具体业务建索引
- 创建索引的列不能为null
6、MVCC解决的问题
数据库并发场景有三种
- 读读:不存在任何问题,也不需要并发控制
- 读写:有线程安全问题,可能造成事务隔离性问题,可能遇到脏读、幻读、不可重复读
- 写写:有线程安全问题,可能存在更新丢失问题
MVCC:Multi-Version Concurrency Control,即多版本并发控制,是一种用来解决读写冲突的无锁并发控制,也是为事务分配单项增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库快照,所以MVCC可以为数据库解决以下问题:
- 在并发读写数据库时,可以做到读操作时不用阻塞写操作,写操作不用阻塞读操作,提高了数据库并发读写的性能
- 解决脏读、幻读、不可重复读等事务隔离问题,但是不能解决更新丢失问题
7、MySQL的隔离级别
- Read Uncommitted 读取未提交的内容
在这个隔离级别,所有事务都可以看到未提交事务的执行结果。所以会产生脏读,一般不会用 - Read Committed 读取提交的内容
一个事务只能读取其它事务已提交的内容,支持不可重复读,也就是说用户运行同一个语句两次,看到的结果时不同的 - Repeatable Read 可重复读
Mysql的默认隔离级别。可解决上面不可重复读问题,它保证同一个事务的多个实例咋并发读取时,会看到相同的数据。不过会导致另一个问题”幻读“。InnoDB和Falcon存储引擎通过多版本并发控制机制解决幻读问题 - Serializable 可串行化
是最高隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题。就是读的时候给行加锁,所以会导致大量的超时和锁竞争现象,现实中应该很少用到,但如果用户的应用为了数据的稳定性,需要强制减少并发,也可以选择这种
1、脏读
脏读是指一个事务读取了未提交事务执行过程中的数据
2、不可重复读
不可重复读是指一个事务查询多次相同的sql得到的结果不一致,因为一个事务执行过程中,另一个事务提交并修改了当前事务正在读取的数据
3、幻读
比如去取钱,卡上有100,你全部取出来,然后有人又给你转了100,你会发现卡上还有100,你就会产生一个错觉,是不是有问题了
8、Mysql复制原理
- master服务务器将数据的改变的记录存放在binlog(二进制文件)日志中
- slave服务器会在一定时间间隔内对master二进制文件进行探测,如果发生改变会开始一个IO线程请求master二进制文件数据
- 同时主节点为每个IO线程启动一个dump线程,用于向其发送二进制数据,并保持至从节点本地的中继日志中,从节点将启动sql线程从中级日志中读取二进制日志,在本地存放,使得其数据和主节点的保持一致,最后IO线程和sql线程将进入睡眠状态,等待下一次被唤醒
也就是说:
1、从库有两个线程:IO和sql两个线程
2、IO线程会去请求主库的binlog,主库启动一个dump线程向从库发数据,从库收到后并将其写入relay-log(中继日志)文件中
3、sql线程会读取relay log文件中的日志,并解析成sql语句逐一执行
9、怎么处理慢查询
- 开启慢查询日志,准确定位哪条sql有问题
slow_query_log 慢查询开启状态,ON开启,OFF关闭
slow_query_log_file 慢查询日志存放的位置
long_query_time 查询超过多少秒才记录 - 分析sql语句,查看是否有不需要加载的列
- 分析语句的执行计划,看是否命中索引
- 如果对语句的优化已经是最优的,那就看是否表数据比较大,大了就分库分表
10、什么是MVCC
Mybatis
1、mybatis 中 #{}和 ${}的区别是什么?
#{}是预编译处理,${}是字符串替换;
Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值;
Mybatis在处理 时 , 就 是 把 {}时,就是把 时,就是把{}替换成变量的值;
使用#{}可以有效的防止SQL注入,提高系统安全性。
2、mybatis 有几种分页方式?
数组分页
sql分页
拦截器分页
RowBounds分页
3、mybatis 逻辑分页和物理分页的区别是什么?
物理分页速度上并不一定快于逻辑分页,逻辑分页速度上也并不一定快于物理分页。
物理分页总是优于逻辑分页:没有必要将属于数据库端的压力加诸到应用端来,就算速度上存在优势,然而其它性能上的优点足以弥补这个缺点。
4、 mybatis 是否支持延迟加载?延迟加载的原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
5、说一下 mybatis 的一级缓存和二级缓存?
一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 ;
对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
6、mybatis 和 hibernate 的区别有哪些?
(1)Mybatis和hibernate不同,它不完全是一个ORM框架,因为MyBatis需要程序员自己编写Sql语句。
(2)Mybatis直接编写原生态sql,可以严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发,因为这类软件需求变化频繁,一但需求变化要求迅速输出成果。但是灵活的前提是mybatis无法做到数据库无关性,如果需要实现支持多种数据库的软件,则需要自定义多套sql映射文件,工作量大。
(3)Hibernate对象/关系映射能力强,数据库无关性好,对于关系模型要求高的软件,如果用hibernate开发可以节省很多代码,提高效率。
7、mybatis 有哪些执行器(Executor)?
Mybatis有三种基本的执行器(Executor):
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
ReuseExecutor:执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map内,供下一次使用。简言之,就是重复使用Statement对象。
BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
8、mybatis 分页插件的实现原理是什么?
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
9、mybatis 如何编写一个自定义插件?
Mybatis自定义插件针对Mybatis四大对象(Executor、StatementHandler 、ParameterHandler 、ResultSetHandler )进行拦截,具体拦截方式为:
Executor:拦截执行器的方法(log记录)
StatementHandler :拦截Sql语法构建的处理
ParameterHandler :拦截参数的处理
ResultSetHandler :拦截结果集的处理
Mybatis自定义插件必须实现Interceptor接口:
public interface Interceptor {
Object intercept(Invocation invocation) throws Throwable;
Object plugin(Object target);
void setProperties(Properties properties);
}
intercept方法:拦截器具体处理逻辑方法
plugin方法:根据签名signatureMap生成动态代理对象
setProperties方法:设置Properties属性
自定义插件demo:
// ExamplePlugin.java
@Intercepts({@Signature(
type= Executor.class,
method = "update",
args = {MappedStatement.class,Object.class})})
public class ExamplePlugin implements Interceptor {
public Object intercept(Invocation invocation) throws Throwable {
Object target = invocation.getTarget(); //被代理对象
Method method = invocation.getMethod(); //代理方法
Object[] args = invocation.getArgs(); //方法参数
// do something ...... 方法拦截前执行代码块
Object result = invocation.proceed();
// do something .......方法拦截后执行代码块
return result;
}
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
public void setProperties(Properties properties) {
}
}
一个@Intercepts可以配置多个@Signature,@Signature中的参数定义如下:
type:表示拦截的类,这里是Executor的实现类;
method:表示拦截的方法,这里是拦截Executor的update方法;
args:表示方法参数。