从贝叶斯滤波到无迹卡尔曼滤波
目录
- 0 引言
- 1 无迹变换
-
- 1.1 什么是无迹变换
- 1.2 一般形式的无迹变换
- 1.3 比例无迹变换
- 2 无迹卡尔曼滤波的假设
-
- 2.1 与卡尔曼滤波相同的假设
- 2.2 与卡尔曼滤波不同的假设
- 3 无迹卡尔曼滤波算法框架
-
- 3.1 可加性噪声条件下的无迹卡尔曼滤波
- 3.2 非可加性噪声条件下的无迹卡尔曼滤波
- 4 应用实例——基于毫米波雷达与无迹卡尔曼滤波的目标跟踪
-
- 4.1 系统分析
-
- 4.1.1 状态转移过程分析
- 4.1.2 观测过程分析
- 4.2 代码实现
- 5 总结
- 参考
0 引言
在此前的文章《从贝叶斯滤波到扩展卡尔曼滤波》中,我们讲述了扩展卡尔曼滤波通过一阶泰勒级数展开将非线性高斯系统的状态转移函数 f ( x ) f(x) f(x) 和(或)观测函数 h ( x ) h(x) h(x) 线性化,然后采用标准卡尔曼滤波框架实现状态量的滤波过程。扩展卡尔曼滤波存在两方面的明显缺点:
- 一阶泰勒级数展开忽略了二阶及以上的高阶项,因此精度一般(通常称为一阶精度),对于高度非线性问题效果较差;
- 雅可比矩阵的计算较为繁琐,容易出错。
为解决强非线性条件下的状态估计问题,1995 年,S. J. Julier 和 J. K. Uhlmann 等人提出了无迹卡尔曼滤波(Unscented Kalman Filter,UKF)算法,并由 E. A. Wan 和 R. Vander Merwe 等人进一步完善。
无迹卡尔曼滤波基于无迹变换(Unscented Transform,UT),无迹变换研究的是如何通过确定的采样点捕获经非线性变换的高斯随机变量的后验分布的问题。通过无迹变换得到相应的统计特性后,再结合标准卡尔曼滤波框架,便得到无迹卡尔曼滤波。标准无迹卡尔曼滤波的计算量与扩展卡尔曼滤波相当,但滤波精度要优于扩展卡尔曼滤波。
1 无迹变换
1.1 什么是无迹变换
无迹变换的核心理念:
近似概率分布比近似任意的非线性函数或变换要相对容易。
无迹变换要解决的问题是:已知某随机变量(多维情形下是随机向量)的概率分布(均值和方差),求其经过某非线性函数 g ( ⋅ ) g(·) g(⋅) 变换后的概率分布。基于上述思想,无迹变换的主要步骤为:
(1) 根据某种规则对随机变量的概率分布进行确定性采样,并为采样点分配权重(均值权重和方差权重),采样点我们通常称之为 sigma 点;
(2) 将每一个 sigma 点进行非线性变换,得到新的 sigma 点;
(3) 对非线性变换后的新的 sigma 点进行加权求和,分别计算加权均值和加权方差,用加权均值和加权方差近似表征随机变量经非线性变换后的概率分布。
如下图所示(《概率机器人》第 3.4 节 P49):
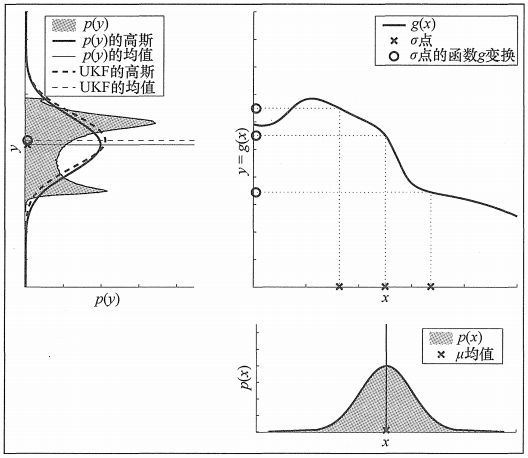
无迹卡尔曼滤波中使用的确定性采样方法是 sigma 点采样方法的一种具体实现,中心差分卡尔曼滤波(Central Difference Kalman Filter,CDKF)使用了 sigma 点采样方法的另一种具体实现,这类滤波算法我们统称为 sigma 点卡尔曼滤波(Sigma-Point Kalman Filter,SPKF)算法。
按照历史发展脉络来讲,无迹变换主要包括两种形式:一般形式的无迹变换和比例无迹变换(Scaled Unscented Transform,SUT)。两种无迹变换的区别主要体现在采样规则和权重计算上,下面将分别进行阐述。
1.2 一般形式的无迹变换
假设存在 n n n 维随机向量 X X X,其服从均值 μ x \mu_x μx 和协方差 Σ x \Sigma_x Σx 的正态分布:
X ∼ N ( μ x , Σ x ) X \sim \mathcal{N}(\mu_x, \Sigma_x) X∼N(μx,Σx)
将 X X X 经过非线性函数 g ( ⋅ ) g(·) g(⋅) 进行变换,得到随机向量 Y Y Y,我们使用一般形式的无迹变换估计 Y Y Y 的概率分布。一般形式的无迹变换最早由 Julier 等人提出,其主要操作流程如下所述:
步骤一:参数选择与权重计算
一般形式的无迹变换只涉及一个外部引入参数 κ \kappa κ,各 sigma 点( 2 n + 1 2n+1 2n+1 个)的权重分配如下:
W ( i ) = { κ n + κ i = 0 1 2 ( n + κ ) i = 1 , ⋅ ⋅ ⋅ , 2 n W^{(i)} = \begin{cases} \frac{\kappa}{n+\kappa} & i = 0 \\ \frac{1}{2(n+\kappa)} & i = 1, ··· , 2n \end{cases} W(i)={n+κκ2(n+κ)1i=0i=1,⋅⋅⋅,2n
其中, κ ∈ R \kappa \in \mathbb{R} κ∈R,表征了 sigma 点相对均值的散布程度, κ \kappa κ 越大,非均值处的 sigma 点距离均值越远(参考步骤二),且所占权重越小,而均值处 sigma 点所占权重则相对越大。对于高斯问题, n + κ = 3 n+\kappa = 3 n+κ=3 是一个比较好的选择,对于非高斯问题(是的,无迹变换也适用于非高斯问题), κ \kappa κ 应该选择其它更恰当的值。
步骤二:确定性采样
通常情况下,siama 点位于均值处及对称分布于主轴的协方差处(每维两个)。按照如下方法采样得到 2 n + 1 2n + 1 2n+1 个 sigma 点,构成 n × ( 2 n + 1 ) n \times (2n + 1) n×(2n+1) 的点集矩阵 X \mathcal{X} X:
X ( i ) = { μ x i = 0 μ x + ( ( n + κ ) Σ x ) ( i − 1 ) i = 1 , ⋅ ⋅ ⋅ , n μ x − ( ( n + κ ) Σ x ) ( i − n − 1 ) i = n + 1 , ⋅ ⋅ ⋅ , 2 n \mathcal{X}^{(i)} = \begin{cases} \mu_x & i = 0 \\ \mu_x + (\sqrt{(n + \kappa)\Sigma_x})^{(i-1)} & i = 1, ··· , n \\ \mu_x - (\sqrt{(n + \kappa)\Sigma_x})^{(i-n-1)} & i = n + 1, ··· , 2n \end{cases} X(i)=⎩⎪⎨⎪⎧μxμx+((n+κ)Σx)(i−1)μx−((n+κ)Σx)(i−n−1)i=0i=1,⋅⋅⋅,ni=n+1,⋅⋅⋅,2n
其中, ( ( n + κ ) Σ x ) ( i − 1 ) (\sqrt{(n + \kappa)\Sigma_x})^{(i-1)} ((n+κ)Σx)(i−1) 表示矩阵 ( n + κ ) Σ x (n + \kappa)\Sigma_x (n+κ)Σx 作 Cholesky 分解后下三角矩阵的第 i − 1 i-1 i−1 列, ( ( n + κ ) Σ x ) ( i − n − 1 ) (\sqrt{(n + \kappa)\Sigma_x})^{(i-n-1)} ((n+κ)Σx)(i−n−1) 同理。
步骤三:sigma 点非线性变换
将每个 sigma 点(即 X \mathcal{X} X 的每一列)进行 g ( ⋅ ) g(·) g(⋅) 的非线性变换,得到变换后的新的点集矩阵 Y \mathcal{Y} Y:
Y ( i ) = g ( X ( i ) ) i = 0 , ⋅ ⋅ ⋅ , 2 n \mathcal{Y}^{(i)} = g(\mathcal{X}^{(i)}) \quad i = 0, ··· , 2n Y(i)=g(X(i))i=0,⋅⋅⋅,2n
步骤四:加权计算近似均值与近似协方差
μ y = ∑ i = 0 i = 2 n W ( i ) Y ( i ) \mu_y = \sum_{i=0}^{i=2n}W^{(i)}\mathcal{Y}^{(i)} μy=i=0∑i=2nW(i)Y(i)
Σ y = ∑ i = 0 i = 2 n W ( i ) [ Y ( i ) − μ y ] [ Y ( i ) − μ y ] T \Sigma_y = \sum_{i=0}^{i=2n}W^{(i)}[\mathcal{Y}^{(i)}-\mu_y][\mathcal{Y}^{(i)}-\mu_y]^T Σy=i=0∑i=2nW(i)[Y(i)−μy][Y(i)−μy]T
1.3 比例无迹变换
从 1.2 节的内容中我们可以发现,当参数 κ < 0 \kappa < 0 κ<0 时,权重 W ( 0 ) = κ n + κ < 0 W^{(0)} = \frac{\kappa}{n+\kappa} < 0 W(0)=n+κκ<0,加权算得的近似协方差可能存在非半正定的情况。为应对该问题,Julier 等人后来提出无迹变换的改进形式——比例无迹变换,并由 Merwe 等人对其进行了简化。比例无迹变换与一般形式的无迹变换的主要区别体现在参数选取与 sigma 点权重计算上,其主要操作流程如下所述:
步骤一:参数选择与权重计算
比例无迹变换引入了四个外部参数: α \alpha α、 β \beta β、 κ \kappa κ 和 λ \lambda λ,各 sigma 点( 2 n + 1 2n+1 2n+1 个)的权重分配如下:
W m ( i ) = { λ n + λ i = 0 1 2 ( n + λ ) i = 1 , ⋅ ⋅ ⋅ , 2 n W_m^{(i)} = \begin{cases} \frac{\lambda}{n+\lambda} & i = 0 \\ \frac{1}{2(n+\lambda)} & i = 1, ··· , 2n \end{cases} Wm(i)={n+λλ2(n+λ)1i=0i=1,⋅⋅⋅,2n
W c ( i ) = { λ n + λ + 1 − α 2 + β i = 0 1 2 ( n + λ ) i = 1 , ⋅ ⋅ ⋅ , 2 n W_c^{(i)} = \begin{cases} \frac{\lambda}{n+\lambda} + 1 -\alpha^2 + \beta & i = 0 \\ \frac{1}{2(n+\lambda)} & i = 1, ··· , 2n \end{cases} Wc(i)={n+λλ+1−α2+β2(n+λ)1i=0i=1,⋅⋅⋅,2n
其中, W m ( i ) W_m^{(i)} Wm(i) 表示计算近似均值时 sigma 点的权重, W c ( i ) W_c^{(i)} Wc(i) 表示计算近似协方差时 sigma 点的权重。参数 λ \lambda λ 满足:
λ = α 2 ( n + κ ) − n \lambda = \alpha^2(n+\kappa)-n λ=α2(n+κ)−n
参数 α \alpha α 和 κ \kappa κ 为确定 sigma 点分布在均值多远的范围内的比例参数。 α \alpha α 满足 1 0 − 4 ≤ α ≤ 1 10^{-4} \le \alpha \le 1 10−4≤α≤1,为避免强非线性系统中的非局部效应问题, α \alpha α 通常取一个较小值; κ \kappa κ 满足 κ ≥ 0 \kappa \ge 0 κ≥0,通常取 κ = 3 − n \kappa = 3-n κ=3−n 或 κ = 0 \kappa = 0 κ=0。
下图呈现了当 α \alpha α 取值分别为 0.3 0.3 0.3 和 1 1 1 时,sigma 点的分布情况,从图中可以发现, α \alpha α 取值越大,非均值处的 sigma 点距离均值越远。

参数 β \beta β 用于引入随机变量概率分布的高阶矩信息,如果分布是精确的高斯分布,则 β = 2 \beta = 2 β=2 是最优选择。
步骤二:确定性采样
通常情况下,siama 点位于均值处及对称分布于主轴的协方差处(每维两个)。按照如下方法采样得到 2 n + 1 2n + 1 2n+1 个 sigma 点,构成 n × ( 2 n + 1 ) n \times (2n + 1) n×(2n+1) 的点集矩阵 X \mathcal{X} X:
X ( i ) = { μ x i = 0 μ x + ( ( n + λ ) Σ x ) ( i − 1 ) i = 1 , ⋅ ⋅ ⋅ , n μ x − ( ( n + λ ) Σ x ) ( i − n − 1 ) i = n + 1 , ⋅ ⋅ ⋅ , 2 n \mathcal{X}^{(i)} = \begin{cases} \mu_x & i = 0 \\ \mu_x + (\sqrt{(n + \lambda)\Sigma_x})^{(i-1)} & i = 1, ··· , n \\ \mu_x - (\sqrt{(n + \lambda)\Sigma_x})^{(i-n-1)} & i = n + 1, ··· , 2n \end{cases} X(i)=⎩⎪⎨⎪⎧μxμx+((n+λ)Σx)(i−1)μx−((n+λ)Σx)(i−n−1)i=0i=1,⋅⋅⋅,ni=n+1,⋅⋅⋅,2n
其中, ( ( n + λ ) Σ x ) ( i − 1 ) (\sqrt{(n + \lambda)\Sigma_x})^{(i-1)} ((n+λ)Σx)(i−1) 表示矩阵 ( n + λ ) Σ x (n + \lambda)\Sigma_x (n+λ)Σx 作 Cholesky 分解后下三角矩阵的第 i − 1 i-1 i−1 列, ( ( n + λ ) Σ x ) ( i − n − 1 ) (\sqrt{(n + \lambda)\Sigma_x})^{(i-n-1)} ((n+λ)Σx)(i−n−1) 同理。
步骤三:sigma 点非线性变换
将每个 sigma 点(即 X \mathcal{X} X 的每一列)进行 g ( ⋅ ) g(·) g(⋅) 的非线性变换,得到变换后的新的点集矩阵 Y \mathcal{Y} Y:
Y ( i ) = g ( X ( i ) ) i = 0 , ⋅ ⋅ ⋅ , 2 n \mathcal{Y}^{(i)} = g(\mathcal{X}^{(i)}) \quad i = 0, ··· , 2n Y(i)=g(X(i))i=0,⋅⋅⋅,2n
步骤四:加权计算近似均值与近似协方差
μ y = ∑ i = 0 i = 2 n W m ( i ) Y ( i ) \mu_y = \sum_{i=0}^{i=2n}W_m^{(i)}\mathcal{Y}^{(i)} μy=i=0∑i=2nWm(i)Y(i)
Σ y = ∑ i = 0 i = 2 n W c ( i ) [ Y ( i ) − μ y ] [ Y ( i ) − μ y ] T \Sigma_y = \sum_{i=0}^{i=2n}W_c^{(i)}[\mathcal{Y}^{(i)}-\mu_y][\mathcal{Y}^{(i)}-\mu_y]^T Σy=i=0∑i=2nWc(i)[Y(i)−μy][Y(i)−μy]T
2 无迹卡尔曼滤波的假设
无迹卡尔曼滤波与扩展卡尔曼滤波具有相同的前提假设。
2.1 与卡尔曼滤波相同的假设
(1) 假设一:状态量服从正态分布
X ∼ N ( μ X , σ X 2 ) X \sim \mathcal{N}(\mu_X, \ \sigma_X^2) X∼N(μX, σX2)
(2) 假设二:观测量服从正态分布
Y ∼ N ( μ Y , σ Y 2 ) Y \sim \mathcal{N}(\mu_Y, \ \sigma_Y^2) Y∼N(μY, σY2)
(3) 假设三:过程噪声服从均值为 0 的正态分布
Q ∼ N ( 0 , σ Q 2 ) Q \sim \mathcal{N}(0, \ \sigma_Q^2) Q∼N(0, σQ2)
(4) 假设四:观测噪声服从均值为 0 的正态分布
R ∼ N ( 0 , σ R 2 ) R \sim \mathcal{N}(0, \ \sigma_R^2) R∼N(0, σR2)
2.2 与卡尔曼滤波不同的假设
(5) 假设五:状态转移函数和(或)观测函数为非线性函数
在卡尔曼滤波的前提假设中,认为状态方程中的状态转移函数 f ( x ) f(x) f(x) 以及观测方程中的观测函数 h ( x ) h(x) h(x) 均为线性函数。基于这种线性假设,存在常数或常矩阵 F F F,使得 f ( x ) f(x) f(x) 可以写成卡尔曼滤波中的线性形式,存在常数或常矩阵 H H H,使得 h ( x ) h(x) h(x) 也可以写成卡尔曼滤波中的线性形式。
不同于标准卡尔曼滤波,无迹卡尔曼滤波处理的是非线性高斯系统,假设系统的状态转移函数和(或)观测函数为非线性函数。
3 无迹卡尔曼滤波算法框架
根据噪声对系统的状态转移过程和观测过程的影响是线性可加的还是非线性不可加的,无迹卡尔曼滤波算法有两种形式:可加性噪声条件下的无迹卡尔曼滤波算法和非可加性噪声条件下的无迹卡尔曼滤波算法。
3.1 可加性噪声条件下的无迹卡尔曼滤波
在此前的文章《从概率到贝叶斯滤波》中,我们曾经这样描述系统的状态方程和观测方程:
{ X k = f ( X k − 1 ) + Q k ⇒ 状 态 方 程 Y k = h ( X k ) + R k ⇒ 观 测 方 程 \begin{cases} X_k=f(X_{k-1})+Q_k & \Rightarrow \color{red}{状态方程} \\ Y_k=h(X_k)+R_k & \Rightarrow \color{red}{观测方程} \end{cases} {Xk=f(Xk−1)+QkYk=h(Xk)+Rk⇒状态方程⇒观测方程
从上式中我们可以发现,过程噪声 Q k Q_k Qk 和观测噪声 R k R_k Rk 是以线性可加项的形式存在于系统状态方程和观测方程中的,这种形式的表述基于这样的前提假设:过程噪声 Q k Q_k Qk 对系统状态转移过程的影响是线性的,观测噪声 R k R_k Rk 对系统观测过程的影响也是线性的。很明显,此种情况下, Q k Q_k Qk 与 X k X_k Xk 是同维的, R k R_k Rk 与 Y k Y_k Yk 是同维的。
由此引申出可加性噪声条件下的无迹卡尔曼滤波算法,《概率机器人》第 3.4 节 P53 对算法流程有着很好的描述。假设有如下已知条件:
- 高斯的状态量随机向量 X X X, n X n_X nX 维,记 n X = n n_X = n nX=n
- k − 1 k - 1 k−1 时刻 X X X 的后验均值与后验协方差: μ X k − 1 + \mu_{X_{k-1}}^+ μXk−1+, Σ X k − 1 + \Sigma_{X_{k-1}}^+ ΣXk−1+
- k k k 时刻的外部控制量输入 u k u_k uk
- 高斯的过程噪声随机向量: Q ∼ N ( 0 , Σ Q ) Q\sim\mathcal{N}(0, \Sigma_Q) Q∼N(0,ΣQ)
- 状态转移函数: f ( X k − 1 , u k ) f(X_{k-1}, u_k) f(Xk−1,uk)
- 高斯的观测量随机向量 Z Z Z, n Z n_Z nZ 维
- k k k 时刻 Z Z Z 的观测取值 z k z_k zk
- 高斯的观测噪声随机向量: R ∼ N ( 0 , Σ R ) R\sim\mathcal{N}(0, \Sigma_R) R∼N(0,ΣR)
- 观测函数: h ( X k ) h(X_k) h(Xk)
基于以上已知条件与符号定义,我们总结一下可加性噪声条件下的无迹卡尔曼滤波算法步骤(使用比例无迹变换)。
步骤一:初始化
初始化步骤需要做三件事:
选定滤波初值
根据观测量初值 z 0 z_0 z0及观测函数 h ( ⋅ ) h(·) h(⋅) 计算对应的状态量初始均值 μ X 0 + \mu_{X_0}^+ μX0+,设定状态量协方差初值 Σ X 0 + \Sigma_{X_0}^+ ΣX0+。
选定无迹变换参数
设定比例无迹变换参数 α \alpha α、 β \beta β、 κ \kappa κ 和 λ \lambda λ 的参数值,若使用一般形式的无迹变换,仅需设定 κ \kappa κ 的取值。
sigma 点权重计算
根据无迹变换参数取值及权重计算公式计算各 sigma 点权重。
W m ( i ) = { λ n + λ i = 0 1 2 ( n + λ ) i = 1 , ⋅ ⋅ ⋅ , 2 n W_m^{(i)} = \begin{cases} \frac{\lambda}{n+\lambda} & i = 0 \\ \frac{1}{2(n+\lambda)} & i = 1, ··· , 2n \end{cases} Wm(i)={n+λλ2(n+λ)1i=0i=1,⋅⋅⋅,2n
W c ( i ) = { λ n + λ + 1 − α 2 + β i = 0 1 2 ( n + λ ) i = 1 , ⋅ ⋅ ⋅ , 2 n W_c^{(i)} = \begin{cases} \frac{\lambda}{n+\lambda} + 1 -\alpha^2 + \beta & i = 0 \\ \frac{1}{2(n+\lambda)} & i = 1, ··· , 2n \end{cases} Wc(i)={n+λλ+1−α2+β2(n+λ)1i=0i=1,⋅⋅⋅,2n
对 k = 1 , 2 , 3 , ⋅ ⋅ ⋅ , k = 1, 2, 3, ··· , k=1,2,3,⋅⋅⋅, 执行:
步骤二:对 k − 1 k-1 k−1 时刻状态量 X k − 1 X_{k-1} Xk−1 的后验概率分布进行 sigma 采样
X k − 1 + ( i ) = { μ X k − 1 + i = 0 μ X k − 1 + + γ ( Σ X k − 1 + ) ( i − 1 ) i = 1 , ⋅ ⋅ ⋅ , n μ X k − 1 + − γ ( Σ X k − 1 + ) ( i − n − 1 ) i = n + 1 , ⋅ ⋅ ⋅ , 2 n \mathcal{X}_{k-1}^{+(i)} = \begin{cases} \mu_{X_{k-1}}^+ & i = 0 \\ \mu_{X_{k-1}}^+ + \gamma(\sqrt{\Sigma_{X_{k-1}}^+})^{(i-1)} & i = 1, ··· , n \\ \mu_{X_{k-1}}^+ - \gamma(\sqrt{\Sigma_{X_{k-1}}^+})^{(i-n-1)} & i = n + 1, ··· , 2n \end{cases} Xk−1+(i)=⎩⎪⎪⎨⎪⎪⎧μXk−1+μXk−1++γ(ΣXk−1+)(i−1)μXk−1+−γ(ΣXk−1+)(i−n−1)i=0i=1,⋅⋅⋅,ni=n+1,⋅⋅⋅,2n
其中, γ = ( n + λ ) \gamma = \sqrt{(n + \lambda)} γ=(n+λ)。
步骤三:状态转移非线性变换
X k − ∗ ( i ) = f ( X k − 1 + ( i ) , u k ) , i = 0 , 1 , 2 , ⋅ ⋅ ⋅ , 2 n \mathcal{X}_k^{-*(i)} = f(\mathcal{X}_{k-1}^{+(i)}, u_k), \quad i = 0, 1, 2, ··· , 2n Xk−∗(i)=f(Xk−1+(i),uk),i=0,1,2,⋅⋅⋅,2n
步骤四:加权计算 k k k 时刻状态量 X k X_k Xk 的先验概率分布
μ X k − = ∑ i = 0 i = 2 n W m ( i ) X k − ∗ ( i ) \mu_{X_k}^- = \sum_{i=0}^{i=2n}W_m^{(i)}\mathcal{X}_k^{-*(i)} μXk−=i=0∑i=2nWm(i)Xk−∗(i)
Σ X k − = ∑ i = 0 i = 2 n W c ( i ) [ X k − ∗ ( i ) − μ X k − ] [ X k − ∗ ( i ) − μ X k − ] T + Σ Q \Sigma_{X_k}^- = \sum_{i=0}^{i=2n}W_c^{(i)}[\mathcal{X}_k^{-*(i)}-\mu_{X_k}^-][\mathcal{X}_k^{-*(i)}-\mu_{X_k}^-]^T+\Sigma_Q ΣXk−=i=0∑i=2nWc(i)[Xk−∗(i)−μXk−][Xk−∗(i)−μXk−]T+ΣQ
由于过程噪声是线性可加的,所以此处 Σ Q \Sigma_Q ΣQ 直接加在了加权协方差的末尾。
步骤五:对 k k k 时刻状态量 X k X_k Xk 的先验概率分布进行 sigma 采样
X k − ( i ) = { μ X k − i = 0 μ X k − + γ ( Σ X k − ) ( i − 1 ) i = 1 , ⋅ ⋅ ⋅ , n μ X k − − γ ( Σ X k − ) ( i − n − 1 ) i = n + 1 , ⋅ ⋅ ⋅ , 2 n \mathcal{X}_k^{-(i)} = \begin{cases} \mu_{X_k}^- & i = 0 \\ \mu_{X_k}^- + \gamma(\sqrt{\Sigma_{X_k}^-})^{(i-1)} & i = 1, ··· , n \\ \mu_{X_k}^- - \gamma(\sqrt{\Sigma_{X_k}^-})^{(i-n-1)} & i = n + 1, ··· , 2n \end{cases} Xk−(i)=⎩⎪⎪⎨⎪⎪⎧μXk−μXk−+γ(ΣXk−)(i−1)μXk−−γ(ΣXk−)(i−n−1)i=0i=1,⋅⋅⋅,ni=n+1,⋅⋅⋅,2n
某些时候,为降低运算量会省略此步,而在下一步骤中直接使用步骤三中的 sigma 点集 X k − ∗ ( i ) \mathcal{X}_k^{-*(i)} Xk−∗(i),这样做在一定程度上会降低精度。
步骤六:观测非线性变换
Z k ( i ) = h ( X k − ( i ) ) , i = 0 , 1 , 2 , ⋅ ⋅ ⋅ , 2 n \mathcal{Z}_k^{(i)} = h(\mathcal{X}_k^{-(i)}), \quad i = 0, 1, 2, ··· , 2n Zk(i)=h(Xk−(i)),i=0,1,2,⋅⋅⋅,2n
步骤七:加权计算 k k k 时刻观测量 Z k Z_k Zk 的概率分布
μ Z k = ∑ i = 0 i = 2 n W m ( i ) Z k ( i ) \mu_{Z_k} = \sum_{i=0}^{i=2n}W_m^{(i)}\mathcal{Z}_k^{(i)} μZk=i=0∑i=2nWm(i)Zk(i)
Σ Z k = ∑ i = 0 i = 2 n W c ( i ) [ Z k ( i ) − μ Z k ] [ Z k ( i ) − μ Z k ] T + Σ R \Sigma_{Z_k} = \sum_{i=0}^{i=2n}W_c^{(i)}[\mathcal{Z}_k^{(i)}-\mu_{Z_k}][\mathcal{Z}_k^{(i)}-\mu_{Z_k}]^T+\Sigma_R ΣZk=i=0∑i=2nWc(i)[Zk(i)−μZk][Zk(i)−μZk]T+ΣR
由于观测噪声是线性可加的,所以此处 Σ R \Sigma_R ΣR 直接加在了加权协方差的末尾。
步骤八:计算状态量与观测量的互协方差
Σ X k Z k = ∑ i = 0 i = 2 n W c ( i ) [ X k − ( i ) − μ X k − ] [ Z k ( i ) − μ Z k ] T \Sigma_{X_kZ_k} = \sum_{i=0}^{i=2n}W_c^{(i)}[\mathcal{X}_k^{-(i)}-\mu_{X_k}^-][\mathcal{Z}_k^{(i)}-\mu_{Z_k}]^T ΣXkZk=i=0∑i=2nWc(i)[Xk−(i)−μXk−][Zk(i)−μZk]T
步骤九:计算卡尔曼增益
K k = Σ X k Z k Σ Z k − 1 K_k = \Sigma_{X_kZ_k}\Sigma_{Z_k}^{-1} Kk=ΣXkZkΣZk−1
步骤十:计算 k k k 时刻状态量 X k X_k Xk 的后验概率分布
μ X k + = μ X k − + K k ( z k − μ Z k ) \mu_{X_k}^+ = \mu_{X_k}^- + K_k(z_k-\mu_{Z_k}) μXk+=μXk−+Kk(zk−μZk)
Σ X k + = Σ X k − − K k Σ Z k K k T \Sigma_{X_k}^+ = \Sigma_{X_k}^- - K_k\Sigma_{Z_k}K_k^T ΣXk+=ΣXk−−KkΣZkKkT
步骤三、四构成了可加性噪声条件下的无迹卡尔曼滤波算法的预测步,步骤六、七、八、九、十则构成了更新步。可加性噪声条件下的无迹卡尔曼滤波算法流程可总结为:

3.2 非可加性噪声条件下的无迹卡尔曼滤波
很多时候,噪声对系统的状态转移和观测的影响并非线性的,此种情况下, Q k Q_k Qk 与 X k X_k Xk 不一定是同维的, R k R_k Rk 与 Y k Y_k Yk 也不一定是同维的。此时,系统的状态方程和观测方程演变为:
{ X k = f ( X k − 1 , Q k ) ⇒ 状 态 方 程 Y k = h ( X k , R k ) ⇒ 观 测 方 程 \begin{cases} X_k=f(X_{k-1}, Q_k) & \Rightarrow \color{red}{状态方程} \\ Y_k=h(X_k, R_k) & \Rightarrow \color{red}{观测方程} \end{cases} {Xk=f(Xk−1,Qk)Yk=h(Xk,Rk)⇒状态方程⇒观测方程
过程噪声协方差和观测噪声协方差便不能像 3.1 节中描述的那样直接加在加权协方差的末尾。非可加性噪声条件下的无迹卡尔曼滤波算法的处理方法是对原始状态量作增广(augment)处理:
μ X k a = [ μ X k 0 0 ] , Σ X k a = [ Σ X k 0 0 0 Σ Q 0 0 0 Σ R ] \mu_{X_k}^a = \begin{bmatrix} \mu_{X_k} \\ \mathbf{0} \\ \mathbf{0} \end{bmatrix}, \quad \Sigma_{X_k}^a = \begin{bmatrix} \Sigma_{X_k} & \mathbf{0} & \mathbf{0} \\ \mathbf{0} & \Sigma_Q & \mathbf{0}\\ \mathbf{0} & \mathbf{0} & \Sigma_R \end{bmatrix} μXka=⎣⎡μXk00⎦⎤,ΣXka=⎣⎡ΣXk000ΣQ000ΣR⎦⎤
注意,上式中的 0 \mathbf{0} 0 表示元素均为 0 0 0 的块向量或块矩阵,故作了粗体显示,应与常值 0 0 0 作区分。增广处理的方式并非只此一种,也可分步增广:在预测步开始前先对上一时刻状态量的后验概率分布作过程噪声增广,再在更新步开始前对当前时刻状态量的先验概率分布作观测噪声增广,《机器人学中的状态估计》一书中使用的便是分步增广的方式,两种增广处理方式实则是等效的。
记过程噪声随机向量 Q Q Q 的维度为 q q q,观测噪声随机向量 R R R 的维度为 r r r,增广状态量 X k a X_k^a Xka 的维度为 L = n + q + r L = n + q + r L=n+q+r。下面我们基于 3.1 节中的已知条件和符号定义,阐述非可加性噪声条件下的无迹卡尔曼滤波算法的流程步骤。
步骤一:初始化
初始化步骤需要做三件事:
选定滤波初值
根据观测量初值 z 0 z_0 z0及观测函数 h ( ⋅ ) h(·) h(⋅) 计算对应的状态量初始均值 μ X 0 + \mu_{X_0}^+ μX0+,设定状态量协方差初值 Σ X 0 + \Sigma_{X_0}^+ ΣX0+。
选定无迹变换参数
设定比例无迹变换参数 α \alpha α、 β \beta β、 κ \kappa κ 和 λ \lambda λ 的参数值,若使用一般形式的无迹变换,仅需设定 κ \kappa κ 的取值。
sigma 点权重计算
根据无迹变换参数取值及权重计算公式计算各 sigma 点权重。
W m ( i ) = { λ L + λ i = 0 1 2 ( L + λ ) i = 1 , ⋅ ⋅ ⋅ , 2 L W_m^{(i)} = \begin{cases} \frac{\lambda}{L+\lambda} & i = 0 \\ \frac{1}{2(L+\lambda)} & i = 1, ··· , 2L \end{cases} Wm(i)={L+λλ2(L+λ)1i=0i=1,⋅⋅⋅,2L
W c ( i ) = { λ L + λ + 1 − α 2 + β i = 0 1 2 ( L + λ ) i = 1 , ⋅ ⋅ ⋅ , 2 L W_c^{(i)} = \begin{cases} \frac{\lambda}{L+\lambda} + 1 -\alpha^2 + \beta & i = 0 \\ \frac{1}{2(L+\lambda)} & i = 1, ··· , 2L \end{cases} Wc(i)={L+λλ+1−α2+β2(L+λ)1i=0i=1,⋅⋅⋅,2L
对 k = 1 , 2 , 3 , ⋅ ⋅ ⋅ , k = 1, 2, 3, ··· , k=1,2,3,⋅⋅⋅, 执行:
步骤二:对 k − 1 k-1 k−1 时刻状态量 X k − 1 X_{k-1} Xk−1 的后验概率分布进行增广处理
μ X k − 1 + a = [ μ X k − 1 + 0 0 ] , Σ X k − 1 + a = [ Σ X k − 1 + 0 0 0 Σ Q 0 0 0 Σ R ] \mu_{X_{k-1}}^{+a} = \begin{bmatrix} \mu_{X_{k-1}}^+ \\ \mathbf{0} \\ \mathbf{0} \end{bmatrix}, \quad \Sigma_{X_{k-1}}^{+a} = \begin{bmatrix} \Sigma_{X_{k-1}}^+ & \mathbf{0} & \mathbf{0} \\ \mathbf{0} & \Sigma_Q & \mathbf{0}\\ \mathbf{0} & \mathbf{0} & \Sigma_R \end{bmatrix} μXk−1+a=⎣⎡μXk−1+00⎦⎤,ΣXk−1+a=⎣⎡ΣXk−1+000ΣQ000ΣR⎦⎤
步骤三:对 k − 1 k-1 k−1 时刻状态量 X k − 1 X_{k-1} Xk−1 增广的后验概率分布进行 sigma 采样
X k − 1 + a ( i ) = { μ X k − 1 + a i = 0 μ X k − 1 + a + γ ( Σ X k − 1 + a ) ( i − 1 ) i = 1 , ⋅ ⋅ ⋅ , L μ X k − 1 + a − γ ( Σ X k − 1 + a ) ( i − L − 1 ) i = L + 1 , ⋅ ⋅ ⋅ , 2 L \mathcal{X}_{k-1}^{+a(i)} = \begin{cases} \mu_{X_{k-1}}^{+a} & i = 0 \\ \mu_{X_{k-1}}^{+a} + \gamma(\sqrt{\Sigma_{X_{k-1}}^{+a}})^{(i-1)} & i = 1, ··· , L \\ \mu_{X_{k-1}}^{+a} - \gamma(\sqrt{\Sigma_{X_{k-1}}^{+a}})^{(i-L-1)} & i = L + 1, ··· , 2L \end{cases} Xk−1+a(i)=⎩⎪⎪⎨⎪⎪⎧μXk−1+aμXk−1+a+γ(ΣXk−1+a)(i−1)μXk−1+a−γ(ΣXk−1+a)(i−L−1)i=0i=1,⋅⋅⋅,Li=L+1,⋅⋅⋅,2L
其中, γ = ( L + λ ) \gamma = \sqrt{(L + \lambda)} γ=(L+λ),且
X k − 1 + a ( i ) = [ X k − 1 + a X ( i ) X k − 1 + a Q ( i ) X k − 1 + a R ( i ) ] , i = 0 , 1 , 2 , ⋅ ⋅ ⋅ , 2 L \mathcal{X}_{k-1}^{+a(i)} = \begin{bmatrix} \mathcal{X}_{k-1}^{+aX(i)} \\ \mathcal{X}_{k-1}^{+aQ(i)} \\ \mathcal{X}_{k-1}^{+aR(i)} \end{bmatrix}, \quad i = 0, 1, 2, ··· , 2L Xk−1+a(i)=⎣⎢⎡Xk−1+aX(i)Xk−1+aQ(i)Xk−1+aR(i)⎦⎥⎤,i=0,1,2,⋅⋅⋅,2L
- X k − 1 + a ( i ) \mathcal{X}_{k-1}^{+a(i)} Xk−1+a(i) 我们读作 k − 1 k-1 k−1 时刻状态量增广的后验概率分布的 sigma 点集的第 i i i 列。 X k − 1 + a \mathcal{X}_{k-1}^{+a} Xk−1+a 的维度为 L × 2 L L \times 2L L×2L
- X k − 1 + a X ( i ) \mathcal{X}_{k-1}^{+aX(i)} Xk−1+aX(i) 我们读作 k − 1 k-1 k−1 时刻状态量增广的后验概率分布的 sigma 点集的状态量分量的第 i i i 列
- X k − 1 + a Q ( i ) \mathcal{X}_{k-1}^{+aQ(i)} Xk−1+aQ(i) 我们读作 k − 1 k-1 k−1 时刻状态量增广的后验概率分布的 sigma 点集的过程噪声分量的第 i i i 列
- X k − 1 + a R ( i ) \mathcal{X}_{k-1}^{+aR(i)} Xk−1+aR(i) 我们读作 k − 1 k-1 k−1 时刻状态量增广的后验概率分布的 sigma 点集的观测噪声分量的第 i i i 列
步骤四:状态转移非线性变换
X k − ( i ) = f ( X k − 1 + a X ( i ) , u k , X k − 1 + a Q ( i ) ) , i = 0 , 1 , 2 , ⋅ ⋅ ⋅ , 2 L \mathcal{X}_k^{-(i)} = f(\mathcal{X}_{k-1}^{+aX(i)}, u_k, \mathcal{X}_{k-1}^{+aQ(i)}), \quad i = 0, 1, 2, ··· , 2L Xk−(i)=f(Xk−1+aX(i),uk,Xk−1+aQ(i)),i=0,1,2,⋅⋅⋅,2L
X k − \mathcal{X}_k^- Xk− 表示 k k k 时刻状态量先验概率分布的 sigma 点集,维度为 n × 2 L n \times 2L n×2L (这一点需要注意)。再计算 X k − \mathcal{X}_k^- Xk− 时,我们只将 X k − 1 + a X \mathcal{X}_{k-1}^{+aX} Xk−1+aX、 u k u_k uk 和 X k − 1 + a Q \mathcal{X}_{k-1}^{+aQ} Xk−1+aQ 传入了状态转移函数 f ( ⋅ ) f(·) f(⋅),因为观测噪声对系统的状态转移过程无影响。
步骤五:加权计算 k k k 时刻状态量 X k X_k Xk 的先验概率分布
μ X k − = ∑ i = 0 i = 2 L W m ( i ) X k − ( i ) \mu_{X_k}^- = \sum_{i=0}^{i=2L}W_m^{(i)}\mathcal{X}_k^{-(i)} μXk−=i=0∑i=2LWm(i)Xk−(i)
Σ X k − = ∑ i = 0 i = 2 L W c ( i ) [ X k − ( i ) − μ X k − ] [ X k − ( i ) − μ X k − ] T \Sigma_{X_k}^- = \sum_{i=0}^{i=2L}W_c^{(i)}[\mathcal{X}_k^{-(i)}-\mu_{X_k}^-][\mathcal{X}_k^{-(i)}-\mu_{X_k}^-]^T ΣXk−=i=0∑i=2LWc(i)[Xk−(i)−μXk−][Xk−(i)−μXk−]T
很明显,步骤四中得到的 X k − \mathcal{X}_k^- Xk− 中已包含过程噪声信息,故此处在计算 Σ X k − \Sigma_{X_k}^- ΣXk− 时并未像 3.1 节中那样在等式末尾添加了 Σ Q \Sigma_Q ΣQ 项。
步骤六:观测非线性变换
Z k ( i ) = h ( X k − ( i ) , X k − 1 + a R ( i ) ) , i = 0 , 1 , 2 , ⋅ ⋅ ⋅ , 2 L \mathcal{Z}_k^{(i)} = h(\mathcal{X}_k^{-(i)}, \mathcal{X}_{k-1}^{+aR(i)}), \quad i = 0, 1, 2, ··· , 2L Zk(i)=h(Xk−(i),Xk−1+aR(i)),i=0,1,2,⋅⋅⋅,2L
正如步骤五中所说的, X k − \mathcal{X}_k^- Xk− 中已包含过程噪声信息,所以此处我们直接将 X k − \mathcal{X}_k^- Xk− 和 X k − 1 + a R ( i ) \mathcal{X}_{k-1}^{+aR(i)} Xk−1+aR(i) 传入了观测函数 h ( ⋅ ) h(·) h(⋅) 来计算 k k k 时刻观测量 Z k Z_k Zk 的概率分布对应的 sigma 点集 Z k \mathcal{Z}_k Zk,而未像 3.1 节中那样对 X k X_k Xk 的先验概率分布进行了单独的采样。
步骤七:加权计算 k k k 时刻观测量 Z k Z_k Zk 的概率分布
μ Z k = ∑ i = 0 i = 2 L W m ( i ) Z k ( i ) \mu_{Z_k} = \sum_{i=0}^{i=2L}W_m^{(i)}\mathcal{Z}_k^{(i)} μZk=i=0∑i=2LWm(i)Zk(i)
Σ Z k = ∑ i = 0 i = 2 L W c ( i ) [ Z k ( i ) − μ Z k ] [ Z k ( i ) − μ Z k ] T \Sigma_{Z_k} = \sum_{i=0}^{i=2L}W_c^{(i)}[\mathcal{Z}_k^{(i)}-\mu_{Z_k}][\mathcal{Z}_k^{(i)}-\mu_{Z_k}]^T ΣZk=i=0∑i=2LWc(i)[Zk(i)−μZk][Zk(i)−μZk]T
很明显,步骤六中得到的 Z k \mathcal{Z}_k Zk 中已包含观测噪声信息,故此处在计算 Σ Z k \Sigma_{Z_k} ΣZk 时并未像 3.1 节中那样在等式末尾添加了 Σ R \Sigma_R ΣR 项。
步骤八:计算状态量与观测量的互协方差
Σ X k Z k = ∑ i = 0 i = 2 L W c ( i ) [ X k − ( i ) − μ X k − ] [ Z k ( i ) − μ Z k ] T \Sigma_{X_kZ_k} = \sum_{i=0}^{i=2L}W_c^{(i)}[\mathcal{X}_k^{-(i)}-\mu_{X_k}^-][\mathcal{Z}_k^{(i)}-\mu_{Z_k}]^T ΣXkZk=i=0∑i=2LWc(i)[Xk−(i)−μXk−][Zk(i)−μZk]T
步骤九:计算卡尔曼增益
K k = Σ X k Z k Σ Z k − 1 K_k = \Sigma_{X_kZ_k}\Sigma_{Z_k}^{-1} Kk=ΣXkZkΣZk−1
步骤十:计算 k k k 时刻状态量 X k X_k Xk 的后验概率分布
μ X k + = μ X k − + K k ( z k − μ Z k ) \mu_{X_k}^+ = \mu_{X_k}^- + K_k(z_k-\mu_{Z_k}) μXk+=μXk−+Kk(zk−μZk)
Σ X k + = Σ X k − − K k Σ Z k K k T \Sigma_{X_k}^+ = \Sigma_{X_k}^- - K_k\Sigma_{Z_k}K_k^T ΣXk+=ΣXk−−KkΣZkKkT
步骤四、五构成了非可加性噪声条件下的无迹卡尔曼滤波算法的预测步,步骤六、七、八、九、十则构成了更新步。非可加性噪声条件下的无迹卡尔曼滤波算法流程可总结为:

在某些系统中,过程噪声和观测噪声可能其中一个对系统的影响是线性的(可加性噪声),而另一个对系统的影响是非线性的(非可加性噪声),这时需要结合 3.1 节与 3.2 节的方法来进行无迹卡尔曼滤波算法的设计,在下面的应用示例中你会看到具体是如何做的。
4 应用实例——基于毫米波雷达与无迹卡尔曼滤波的目标跟踪
4.1 系统分析
4.1.1 状态转移过程分析
在《从贝叶斯滤波到扩展卡尔曼滤波》中,我们讲解了毫米波雷达的检测原理,并基于扩展卡尔曼滤波算法实现了 CV 运动模型下的目标跟踪。此处,我们仍以毫米波雷达传感器为例,来讲解基于无迹卡尔曼滤波算法的目标跟踪过程。
不同的是,此次我们假设被跟踪目标近似地作匀速圆周运动,即运动模型为恒定转率和速度模型(Constant Turn Rate and Velocity,CTRV),如下图所示(图片来自 Udacity)。

在 CTRV 模型中,我们通常对目标在笛卡尔坐标系内的横坐标 p x p_x px、纵坐标 p y p_y py、线速率 v v v、航向角 ψ \psi ψ 和航向角速率 ω \omega ω 进行跟踪,其中 ω = ψ ˙ \omega = \dot{\psi} ω=ψ˙。状态量可设为:
X = [ p x p y v ψ ω ] X= \begin{bmatrix} p_x \\ p_y \\ v \\ \psi \\ \omega \end{bmatrix} X=⎣⎢⎢⎢⎢⎡pxpyvψω⎦⎥⎥⎥⎥⎤
我们先暂不考虑过程噪声的影响,则系统的状态方程(未计入噪声的)可表示为:
X k = X k − 1 + ∫ t k − 1 t k [ p x ˙ ( t ) p y ˙ ( t ) v ˙ ( t ) ψ ˙ ( t ) ω ˙ ( t ) ] d t = X k − 1 + [ ∫ t k − 1 t k v ⋅ c o s ( ψ ( t ) ) d t ∫ t k − 1 t k v ⋅ s i n ( ψ ( t ) ) d t 0 ω Δ t 0 ] = X k − 1 + [ v ∫ t k − 1 t k c o s ( ψ k − 1 + ω ⋅ ( t − t k − 1 ) ) d t v ∫ t k − 1 t k s i n ( ψ k − 1 + ω ⋅ ( t − t k − 1 ) ) d t 0 ω Δ t 0 ] \begin{aligned} X_k & = X_{k-1} + \int_{t_{k-1}}^{t_k} \begin{bmatrix} \dot{p_x}(t) \\ \dot{p_y}(t) \\ \dot{v}(t) \\ \dot{\psi}(t) \\ \dot{\omega}(t) \end{bmatrix}\mathrm{d}t \\ & = X_{k-1} + \begin{bmatrix} \int_{t_{k-1}}^{t_k}v·\mathrm{cos}(\psi(t))\mathrm{d}t \\ \int_{t_{k-1}}^{t_k}v·\mathrm{sin}(\psi(t))\mathrm{d}t \\ 0 \\ \omega \Delta t \\ 0 \end{bmatrix} \\ & = X_{k-1} + \begin{bmatrix} v\int_{t_{k-1}}^{t_k}\mathrm{cos}(\psi_{k-1}+\omega·(t-t_{k-1}))\mathrm{d}t \\ v\int_{t_{k-1}}^{t_k}\mathrm{sin}(\psi_{k-1}+\omega·(t-t_{k-1}))\mathrm{d}t \\ 0 \\ \omega \Delta t \\ 0 \end{bmatrix} \\ \end{aligned} Xk=Xk−1+∫tk−1tk⎣⎢⎢⎢⎢⎡px˙(t)py˙(t)v˙(t)ψ˙(t)ω˙(t)⎦⎥⎥⎥⎥⎤dt=Xk−1+⎣⎢⎢⎢⎢⎢⎡∫tk−1tkv⋅cos(ψ(t))dt∫tk−1tkv⋅sin(ψ(t))dt0ωΔt0⎦⎥⎥⎥⎥⎥⎤=Xk−1+⎣⎢⎢⎢⎢⎢⎡v∫tk−1tkcos(ψk−1+ω⋅(t−tk−1))dtv∫tk−1tksin(ψk−1+ω⋅(t−tk−1))dt0ωΔt0⎦⎥⎥⎥⎥⎥⎤
由换元法求复合函数定积分,容易得到:
∫ t k − 1 t k c o s ( ψ k − 1 + ω ⋅ ( t − t k − 1 ) ) d t = s i n ( ψ k − 1 + ω Δ t ) − s i n ( ψ k − 1 ) ω , ω ≠ 0 \int_{t_{k-1}}^{t_k}\mathrm{cos}(\psi_{k-1}+\omega·(t-t_{k-1}))\mathrm{d}t = \frac{\mathrm{sin}(\psi_{k-1}+\omega\Delta t)-\mathrm{sin}(\psi_{k-1})}{\omega}, \quad \omega \neq 0 ∫tk−1tkcos(ψk−1+ω⋅(t−tk−1))dt=ωsin(ψk−1+ωΔt)−sin(ψk−1),ω=0
∫ t k − 1 t k s i n ( ψ k − 1 + ω ⋅ ( t − t k − 1 ) ) d t = − c o s ( ψ k − 1 + ω Δ t ) + c o s ( ψ k − 1 ) ω , ω ≠ 0 \int_{t_{k-1}}^{t_k}\mathrm{sin}(\psi_{k-1}+\omega·(t-t_{k-1}))\mathrm{d}t = \frac{-\mathrm{cos}(\psi_{k-1}+\omega\Delta t)+\mathrm{cos}(\psi_{k-1})}{\omega}, \quad \omega \neq 0 ∫tk−1tksin(ψk−1+ω⋅(t−tk−1))dt=ω−cos(ψk−1+ωΔt)+cos(ψk−1),ω=0
故,求得系统的状态方程(未计入噪声的)为:
X k = X k − 1 + [ v ω ( s i n ( ψ k − 1 + ω Δ t ) − s i n ( ψ k − 1 ) ) v ω ( − c o s ( ψ k − 1 + ω Δ t ) + c o s ( ψ k − 1 ) ) 0 ω Δ t 0 ] , ω ≠ 0 X_k = X_{k-1} + \begin{bmatrix} \frac{v}{\omega} \bigl(\mathrm{sin}(\psi_{k-1}+\omega\Delta t)-\mathrm{sin}(\psi_{k-1}) \bigr) \\ \frac{v}{\omega} \bigl(-\mathrm{cos}(\psi_{k-1}+\omega\Delta t)+\mathrm{cos}(\psi_{k-1}) \bigr) \\ 0 \\ \omega \Delta t \\ 0 \end{bmatrix}, \quad \omega \neq 0 Xk=Xk−1+⎣⎢⎢⎢⎢⎡ωv(sin(ψk−1+ωΔt)−sin(ψk−1))ωv(−cos(ψk−1+ωΔt)+cos(ψk−1))0ωΔt0⎦⎥⎥⎥⎥⎤,ω=0
CTRV 是 CV 的一般形式,当 ω = 0 \omega = 0 ω=0 时,CTRV 便退化为 CV:
X k = X k − 1 + [ v ⋅ c o s ( ψ k − 1 ) Δ t v ⋅ s i n ( ψ k − 1 ) Δ t 0 0 0 ] , ω ≠ 0 X_k = X_{k-1} + \begin{bmatrix} v·\mathrm{cos}(\psi_{k-1})\Delta t \\ v·\mathrm{sin}(\psi_{k-1})\Delta t \\ 0 \\ 0 \\ 0 \end{bmatrix}, \quad \omega \neq 0 Xk=Xk−1+⎣⎢⎢⎢⎢⎡v⋅cos(ψk−1)Δtv⋅sin(ψk−1)Δt000⎦⎥⎥⎥⎥⎤,ω=0
在上面的推导中,我们暂时忽略了过程噪声的干扰,但现实情况是,系统状态转移的过程中,目标的线速率 v v v 和航向角速率 ω \omega ω 并非一成不变,都存在微小扰动。假设 v v v 受线加速度噪声 q a q_a qa 的影响, ω \omega ω 受角加速度噪声 q ω ˙ q_{\dot{\omega}} qω˙ 的影响, q a q_a qa 和 q ω ˙ q_{\dot{\omega}} qω˙ 均为零均值的高斯白噪声:
q a ∼ N ( 0 , σ a 2 ) q_a \sim \mathcal{N} (0, \sigma_a^2) qa∼N(0,σa2)
q ω ˙ ∼ N ( 0 , σ ω ˙ 2 ) q_{\dot{\omega}} \sim \mathcal{N} (0, \sigma_{\dot{\omega}}^2) qω˙∼N(0,σω˙2)
则系统状态转移过程中总的过程噪声 Q Q Q 可表示为:
Q = [ q a q ω ˙ ] Q = \begin{bmatrix} q_a \\ q_{\dot{\omega}} \end{bmatrix} Q=[qaqω˙]
Q Q Q 的协方差 Σ Q \Sigma_Q ΣQ 为:
Σ Q = [ σ a 2 0 0 σ ω ˙ 2 ] \Sigma_Q = \begin{bmatrix} \sigma_a^2 & 0 \\ 0 & \sigma_{\dot{\omega}}^2 \end{bmatrix} ΣQ=[σa200σω˙2]
q a q_a qa 和 q ω ˙ q_{\dot{\omega}} qω˙ 都对 p x p_x px 和 p y p_y py 存在影响,但此处我们忽略 q ω ˙ q_{\dot{\omega}} qω˙ 对位移的影响,由运动学公式容易得到系统最终的状态方程:
X k = f ( X k − 1 , Q k ) = X k − 1 + [ v k − 1 ω k − 1 ( s i n ( ψ k − 1 + ω k − 1 Δ t ) − s i n ( ψ k − 1 ) ) v k − 1 ω k − 1 ( − c o s ( ψ k − 1 + ω k − 1 Δ t ) + c o s ( ψ k − 1 ) ) 0 ω k − 1 Δ t 0 ] + [ 1 2 ( Δ t ) 2 ⋅ q a , k ⋅ c o s ( ψ k − 1 ) 1 2 ( Δ t ) 2 ⋅ q a , k ⋅ s i n ( ψ k − 1 ) Δ t ⋅ q a , k 1 2 ( Δ t ) 2 ⋅ q ω ˙ , k Δ t ⋅ q ω ˙ , k ] \begin{aligned} X_k & = f(X_{k-1}, Q_k) \\ & = X_{k-1} + \begin{bmatrix} \frac{v_{k-1} }{\omega_{k-1} } \bigl(\mathrm{sin}(\psi_{k-1}+\omega_{k-1}\Delta t)-\mathrm{sin}(\psi_{k-1}) \bigr) \\ \frac{v_{k-1} }{\omega_{k-1} } \bigl(-\mathrm{cos}(\psi_{k-1}+\omega_{k-1}\Delta t)+\mathrm{cos}(\psi_{k-1}) \bigr) \\ 0 \\ \omega_{k-1} \Delta t \\ 0 \end{bmatrix} + \begin{bmatrix} \frac{1}{2} (\Delta t)^2 · q_{a, k} · \mathrm{cos}(\psi_{k-1}) \\ \frac{1}{2} (\Delta t)^2 · q_{a, k} · \mathrm{sin}(\psi_{k-1}) \\ \Delta t · q_{a, k} \\ \frac{1}{2} (\Delta t)^2 · q_{\dot{\omega}, k} \\ \Delta t · q_{\dot{\omega}, k} \end{bmatrix} \end{aligned} Xk=f(Xk−1,Qk)=Xk−1+⎣⎢⎢⎢⎢⎡ωk−1vk−1(sin(ψk−1+ωk−1Δt)−sin(ψk−1))ωk−1vk−1(−cos(ψk−1+ωk−1Δt)+cos(ψk−1))0ωk−1Δt0⎦⎥⎥⎥⎥⎤+⎣⎢⎢⎢⎢⎡21(Δt)2⋅qa,k⋅cos(ψk−1)21(Δt)2⋅qa,k⋅sin(ψk−1)Δt⋅qa,k21(Δt)2⋅qω˙,kΔt⋅qω˙,k⎦⎥⎥⎥⎥⎤
4.1.2 观测过程分析
观测量仍然是毫米波雷达极坐标系下目标的径向距离 ρ \rho ρ、方向角 φ \varphi φ 和径向距离变化率(径向速度) ρ ˙ \dot{\rho} ρ˙:
Z = [ ρ φ ρ ˙ ] Z= \begin{bmatrix} \rho \\ \varphi \\ \dot{\rho} \end{bmatrix} Z=⎣⎡ρφρ˙⎦⎤
各观测量分量 ρ \rho ρ、 φ \varphi φ、 φ ˙ \dot{\varphi} φ˙ 对应的观测噪声分别为 r ρ r_{\rho} rρ、 r φ r_{\varphi} rφ、 r φ ˙ r_{\dot{\varphi}} rφ˙,同样都是零均值的高斯白噪声:
r ρ ∼ N ( 0 , σ ρ 2 ) r_{\rho} \sim \mathcal{N} (0, \sigma_{\rho}^2) rρ∼N(0,σρ2)
r φ ∼ N ( 0 , σ φ 2 ) r_{\varphi} \sim \mathcal{N} (0, \sigma_{\varphi}^2) rφ∼N(0,σφ2)
r φ ˙ ∼ N ( 0 , σ φ ˙ 2 ) r_{\dot{\varphi}} \sim \mathcal{N} (0, \sigma_{\dot{\varphi}}^2) rφ˙∼N(0,σφ˙2)
则观测过程中总的观测噪声 R R R 可表示为:
R = [ r ρ r φ r φ ˙ ] R = \begin{bmatrix} r_{\rho} \\ r_{\varphi} \\ r_{\dot{\varphi}} \end{bmatrix} R=⎣⎡rρrφrφ˙⎦⎤
R R R 的协方差 Σ R \Sigma_R ΣR 为:
Σ R = [ σ ρ 2 0 0 0 σ φ 2 0 0 0 σ φ ˙ 2 ] \Sigma_R = \begin{bmatrix} \sigma_{\rho}^2 & 0 & 0 \\ 0 & \sigma_{\varphi}^2 & 0 \\ 0 & 0 & \sigma_{\dot{\varphi}}^2 \end{bmatrix} ΣR=⎣⎡σρ2000σφ2000σφ˙2⎦⎤
观测方程与《从贝叶斯滤波到扩展卡尔曼滤波》中相似,我们直接给出:
Z k = h ( X k ) + R k = [ p x , k 2 + p y , k 2 a r c t a n ( p y , k p x , k ) v k ⋅ c o s ( ψ k ) ⋅ p x , k + v k ⋅ s i n ( ψ k ) ⋅ p y , k p x , k 2 + p y , k 2 ] + [ r ρ , k r φ , k r φ ˙ , k ] \begin{aligned} Z_k & = h(X_k) + R_k \\ & = \begin{bmatrix} \sqrt{p_{x,k}^2+p_{y,k}^2} \\ \mathrm{arctan}(\frac{p_{y,k} }{p_{x,k} }) \\ \frac{v_k·\mathrm{cos}(\psi_k)·p_{x,k}+v_k·\mathrm{sin}(\psi_k)·p_{y,k} }{\sqrt{p_{x,k}^2+p_{y,k}^2} } \end{bmatrix} + \begin{bmatrix} r_{\rho,k} \\ r_{\varphi,k} \\ r_{\dot{\varphi},k} \end{bmatrix} \end{aligned} Zk=h(Xk)+Rk=⎣⎢⎢⎡px,k2+py,k2arctan(px,kpy,k)px,k2+py,k2vk⋅cos(ψk)⋅px,k+vk⋅sin(ψk)⋅py,k⎦⎥⎥⎤+⎣⎡rρ,krφ,krφ˙,k⎦⎤
4.2 代码实现
从上面的分析中我们可以知道,过程噪声对系统的状态转移过程具有非线性影响,而观测噪声对系统的观测过程具有线性影响,因此需要结合 3.1 节与 3.2 节的内容进行无迹卡尔曼滤波算法的设计:
- 实现 3.2 节的步骤二时,只需将过程噪声 Q Q Q 增广到 X k − 1 X_{k-1} Xk−1 的后验概率分布
μ X k − 1 + a = [ μ X k − 1 + 0 ] , Σ X k − 1 + a = [ Σ X k − 1 + 0 0 Σ Q ] \mu_{X_{k-1}}^{+a} = \begin{bmatrix} \mu_{X_{k-1}}^+ \\ \mathbf{0} \end{bmatrix}, \quad \Sigma_{X_{k-1}}^{+a} = \begin{bmatrix} \Sigma_{X_{k-1}}^+ & \mathbf{0} \\ \mathbf{0} & \Sigma_Q \end{bmatrix} μXk−1+a=[μXk−1+0],ΣXk−1+a=[ΣXk−1+00ΣQ]
- 实现 3.2 节的步骤六时,只需将预测步 sigma 点集 X k − \mathcal{X}_k^- Xk− 传入观测函数 h ( ⋅ ) h(·) h(⋅)
Z k ( i ) = h ( X k − ( i ) ) , i = 0 , 1 , 2 , ⋅ ⋅ ⋅ , 2 L \mathcal{Z}_k^{(i)} = h(\mathcal{X}_k^{-(i)}), \quad i = 0, 1, 2, ··· , 2L Zk(i)=h(Xk−(i)),i=0,1,2,⋅⋅⋅,2L
- 实现 3.2 节的步骤七时,直接将观测噪声 R R R 协方差 Σ R \Sigma_R ΣR 添加至 Z k Z_k Zk 协方差 Σ Z k \Sigma_{Z_k} ΣZk 的末尾
Σ Z k = ∑ i = 0 i = 2 L W c ( i ) [ Z k ( i ) − μ Z k ] [ Z k ( i ) − μ Z k ] T + Σ R \Sigma_{Z_k} = \sum_{i=0}^{i=2L}W_c^{(i)}[\mathcal{Z}_k^{(i)}-\mu_{Z_k}][\mathcal{Z}_k^{(i)}-\mu_{Z_k}]^T+\Sigma_R ΣZk=i=0∑i=2LWc(i)[Zk(i)−μZk][Zk(i)−μZk]T+ΣR
下面给出具体的 C++ 代码实现,为简便起见,实现过程中使用的无迹变换为一般形式的无迹变换,UT 参数只有 κ \kappa κ。代码框架比较清晰,完全遵循了 3.2 节的算法流程图,但没有去跑数据看仿真效果,工程实践中需要调节噪声协方差以及 UT 参数来获得较好的滤波结果。
UnscentedKalmanFilter.h
#ifndef UNSCENTED_KALMAN_FILTER_
#define UNSCENTED_KALMAN_FILTER_
#include "Eigen/Dense"
class UnscentedKalmanFilter
{
private:
bool is_inited; // flag of initialization
bool just_begin_filt; // flag of just begining filt data
uint64_t timestamp_last; // timestamp of last frame: us
double dt; // delta time: s
int n_x; // dimension of state vector X
int n_x_aug; // dimension of augmented state vector X
int n_z; // dimension of measurement vector Z
double std_a; // standard deviation of longitudinal acceleration process noise: m/s^2
double std_omega_dot; // standard deviation of yaw acceleration process noise: rad/s^2
Eigen::MatrixXd Q; // process noise covariance matrix
double std_rho; // standard deviation of range measurement noise: m
double std_phi; // standard deviation of bearing measurement noise: rad
double std_rho_dot; // standard deviation of range rate measurement noise: m/s
Eigen::MatrixXd R; // measurement noise covariance matrix
double kappa; // unscented transform parameter κ
Eigen::VectorXd weights; // weights vector of sigma points
Eigen