d2l房价预测与pandas文件处理
这一章可以说是干货满满了,有文件处理,也有大量的数据集准备,详细见下文!
目录
1.pandas与csv文件处理
1.1读取文件
1.2处理数值列
1.3处理字符串列
1.4最终输出值
2.训练
2.1定义损失与网络
2.2K折交叉验证
2.3训练
3.预测
1.pandas与csv文件处理
1.1读取文件
使用pd.read_csv读取csv文件,看到train里面比test多一列,即为价格列。
data_file_train = os.path.join("..", 'data', 'kaggle_house_pred_train.csv')
data_file_test = os.path.join("..", 'data', 'kaggle_house_pred_test.csv')
train_data = pd.read_csv(data_file_train)
test_data = pd.read_csv(data_file_test)
train_data.shape,test_data.shape
'''
(1460, 81)
(1459, 80)
'''kaggle里面都有一个id栏,这个无意义,是不能参与训练的,使用iloc命令把它切掉。
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
all_features.shape
'''
(2919, 79)
'''1.2处理数值列
pands里面的object等于py里面的str,表示字符串。在这里是将全都是数字的列名(即index)索引出来,然后对其中的数值进行标准化处理,x=(x-u)/ 。
。
注意第二行里面的这个apply命令,是对每一列的数值进行操作。lambda函数之前讲过.
然后就是将Nan缺失的数字设置为0。
但注意!如果先设置为0的话,0也会参与到后续的标准化操作,但是实际上是不合理的,因为缺失的数据是未知的,不应该参与标准化运算!应该在将实数标准化之后再填补缺失值。
# 若⽆法获得测试数据,则可根据训练数据计算均值和标准差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()))
# 在标准化数据之后,所有均值消失,因此我们可以将缺失值设置为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
all_features['LotFrontage']
'''
0 -0.184443
1 0.458096
2 -0.055935
3 -0.398622
4 0.629439
...
1454 -2.069222
1455 -2.069222
1456 3.884968
1457 -0.312950
1458 0.201080
Name: LotFrontage, Length: 2919, dtype: float64
'''1.3处理字符串列
get_dummies处理之后,原来的列就没有了(如MSZoning),取而代之的是原列名+_features(MSZoning_RL...)!这时这一列为独热向量,原先标记为RL的对应行会显示1,标记其他的则是0。
# “Dummy_na=True”将“na”(缺失值)视为有效的特征值,并为其创建指⽰符特征
all_features = pd.get_dummies(all_features, dummy_na=True)
all_features.shape, all_features['MSZoning_RL']
'''
((2919, 331),
0 1
1 1
2 1
3 1
4 1
..
1454 0
1455 0
1456 1
1457 1
1458 1
Name: MSZoning_RL, Length: 2919, dtype: uint8)
'''使用values,将pandas格式中提取NumPy格式,并转化为张量用于训练。
train_labels是提取的train_data(1460,81),里面选取SalePrice列的数据进行转换
n_train = train_data.shape[0]
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32)
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32)
train_labels = torch.tensor(
train_data['SalePrice'].values.reshape(-1, 1), dtype=torch.float32)
# demo = torch.tensor(train_data['PoolArea'].values, dtype=torch.float32)
train_features.shape, train_labels.shape, test_features.shape
'''
(torch.Size([1460, 331]), torch.Size([1460, 1]), torch.Size([1459, 331]))
'''1.4最终输出值
看一下处理完的最终结果是什么:
得到了train_features(1460,331)用于训练;train_labels(1460,1)训练数据对应的房价;test_features(1459,331)用于预测。
2.训练
2.1定义损失与网络
这里主要跑流程,所以先设置最简单的全连接,也可作为baseline。
这里面的输入维度即为331列参数。
loss = nn.MSELoss()
in_features = train_features.shape[1]
def get_net():
net = nn.Sequential(nn.Linear(in_features,1))
return net
in_features
'''
331
'''
损失这里要注意:
对于房价来讲,应该使用相对误差。在此采取取对数再相减的方法,可以分别用[400,390][12,10]两组数来验证合理性。具体需求为下图公式:
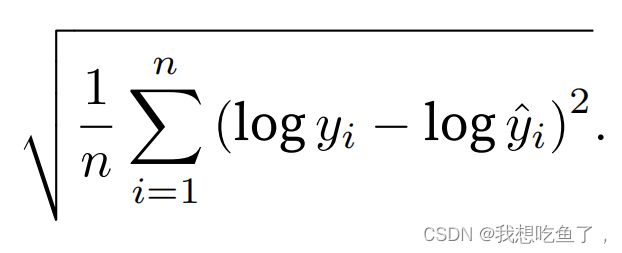
def log_rmse(net, features, labels):
# 为了在取对数时进⼀步稳定该值,将⼩于1的值设置为1,防止log小于1出问题
clipped_preds = torch.clamp(net(features), 1, float('inf'))
rmse = torch.sqrt(loss(torch.log(clipped_preds),
torch.log(labels)))
return rmse.item()def train(net, train_features, train_labels, test_features, test_labels,
num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size)
# 这⾥使⽤的是Adam优化算法
optimizer = torch.optim.Adam(net.parameters(),
lr = learning_rate,
weight_decay = weight_decay)
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad()
l = loss(net(X), y)
l.backward()
optimizer.step()
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls2.2K折交叉验证
基本定义:将数据集均分成K个不同的子集,然后执行K次模型训练和验证,每次再K-1个子集上进行训练,并再剩余的一个子集进行验证,最后通过对K次实验的结果取平均来估计训练和验证误差。
首先来看某单一次折中,数据处理的细节:
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0)
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid这里面X,y对应的是train里面的train_features, train_labels值。
这个assert为判断函数,如果不满足会报错,从而不进行下面的运算。
第五行开始,首先分片,没一片是总数/k个个数。前面得到fold_size=292。
这里针对slice函数进行一个直观讲解:第一个参数默认进行切片,从第2个到第5-1=4个。
x1 = torch.randn(6, 7)
x2 = slice(2, 5)
x1, x2, x1[x2, :].shape, x1[x2, :], x1[x2, x2]
'''
(tensor([[-0.8395, 0.0889, -0.1568, -0.5556, 0.5240, 1.1080, 1.7148],
[-2.9232, -0.0060, -2.1514, -1.1870, 0.8534, -1.6519, 1.6586],
[-1.0398, 0.0369, -1.2592, 0.4807, 0.4048, -0.2949, -0.2115],
[ 0.8220, -0.7045, -0.9553, 0.4993, -0.1584, -0.7187, -1.0840],
[-0.2027, -0.0117, 0.3927, 0.6283, -0.0121, -2.4030, -0.4888],
[ 0.7346, 0.7490, 0.9968, -0.2208, -0.4263, -1.1519, 1.0763]]),
slice(2, 5, None),
torch.Size([3, 7]),
tensor([[-1.0398, 0.0369, -1.2592, 0.4807, 0.4048, -0.2949, -0.2115],
[ 0.8220, -0.7045, -0.9553, 0.4993, -0.1584, -0.7187, -1.0840],
[-0.2027, -0.0117, 0.3927, 0.6283, -0.0121, -2.4030, -0.4888]]),
tensor([[-1.2592, 0.4807, 0.4048],
[-0.9553, 0.4993, -0.1584],
[ 0.3927, 0.6283, -0.0121]]))
'''切片放到循环j里面,在j=1时,切片idx为(282,584)。
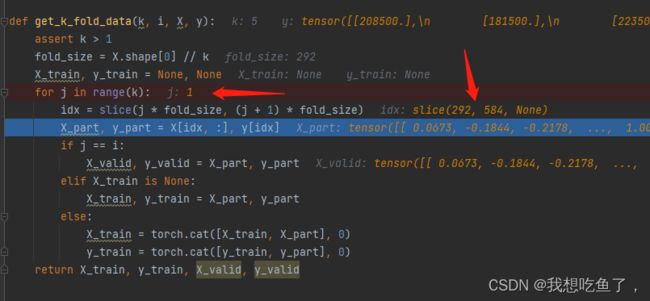
注意比较的另一个参数i:是下面函数的循环,这个函数写在i循环下面,当j=i时,指定此为验证集,part切片得到的数据赋给valid。当j!=i时,此时(设k=5分5份时)其余的四个应该都是这一条,则赋到train数据中。当第一次j!=i时,即第一个elif条件,赋值即可。但当后三次时,应该进行cat拼接起来,这里的0表示按维度0拼接(行)。
单次折最终返回的分别为4/5的训练,1/5的验证。
再来看k次折的流程:
注意这里面的train_ls[-1]为直接取最后一个epoch训练的ls,在之前的epoch损失可以不看了,这里只取最后一轮训练的ls。
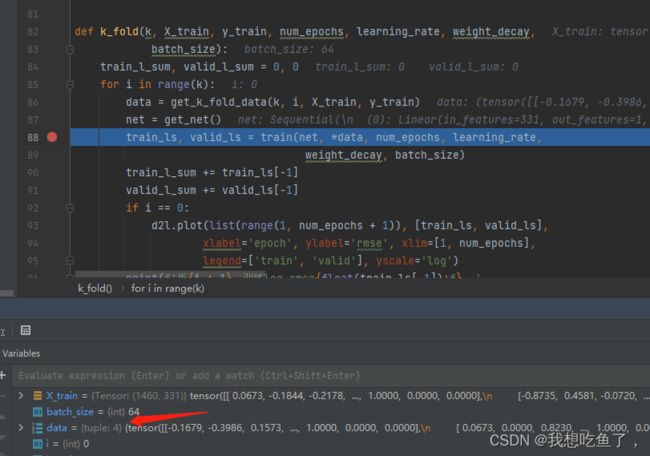
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay,
batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate,
weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls],
xlabel='epoch', ylabel='rmse', xlim=[1, num_epochs],
legend=['train', 'valid'], yscale='log')
print(f'折{i + 1},训练log rmse{float(train_ls[-1]):f}, '
f'验证log rmse{float(valid_ls[-1]):f}')
return train_l_sum / k, valid_l_sum / k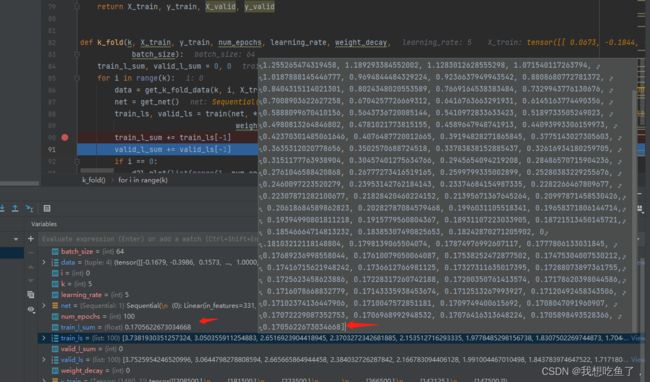
再注意这里面的train里面的*data为解元组操作:data为一个4元素元组,这里把它解开分别赋值。
2.3训练
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr,
weight_decay, batch_size)
print(f'{k}-折验证: 平均训练log rmse: {float(train_l):f}, '
f'平均验证log rmse: {float(valid_l):f}')3.预测
当经过上面的调参后,确认该选择的最有超参数后,则可用全部的数据对其训练
def train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None,
num_epochs, lr, weight_decay, batch_size)
d2l.plot(np.arange(1, num_epochs + 1), [train_ls], xlabel='epoch',
ylabel='log rmse', xlim=[1, num_epochs], yscale='log')
print(f'训练log rmse:{float(train_ls[-1]):f}')
# 将⽹络应⽤于测试集。
preds = net(test_features).detach().numpy()
# 将其重新格式化以导出到Kaggle
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('submission.csv', index=False)注意里面的,得到preds后,它是一个(1459,1)的张量,每一行显示预测价格,要把它添加到csv里面的列中时,要转变一下形状,变成(1459,),然后使用[0]全部读取出来,再concat。
train_and_pred(train_features, test_features, train_labels, test_data,
num_epochs, lr, weight_decay, batch_size)