机器学习作业一:使用k-近邻算法实现手写数字识别(1)+(2)
文章目录
-
- 一、k-近邻算法
- 二、k值的选取及归一化的重要性
- 三、k近邻算法的一般流程
- 四、使用KNN进行手写数字识别的步骤
- 五、主要代码
- 六、算法缺点
- 七、使用sklearn库实现简单的KNN算法实例
- 八、参考
一、k-近邻算法
K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。
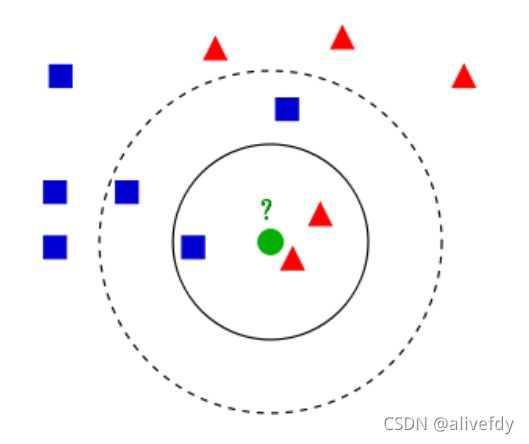
举个例子。如上图所示,假设图中绿色圆形为待分类目标,当K=3时,绿色圆形的最邻近的3个点是2个红色三角形和1个蓝色正方形,因此我们判定绿色的这个待分类点属于红色的三角形一类;当K=5时,绿色圆形的最邻近的5个点是2个红色三角形和3个蓝色正方形,所以在这个条件下我们判定绿色的这个待分类点属于蓝色正方形一类。
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
使用数据范围:数值型和标称型
工作原理:
1.存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。
2.输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前 k 个最相似的数据,这就是 K 近邻算法中 k 的出处,通常 k 是不大于 20 的整数。最后,选择 k 个最相似数据中出现次数最多的分类,作为新数据的分类。
二、k值的选取及归一化的重要性
1.k值的选取
k值选取过小,则容易发生过拟合,此时我们很容易学习到噪声,也就非常容易判定为噪声类别;k值选取过大,就相当于用较大范围中的训练数据进行预测,这时与待分类目标较远的(不那么相似)训练实例也会起到预测的作用,但这样会使预测发生错误(完全忽略训练数据实例中的大量有用信息)。
2.归一化的重要性
假设有多个特征值时,其中某个特征数量级比较大(如身高/cm),其他特征较小时(鞋码),此时会导致距离的错误计算,分类结果会被特征值所主导,而弱化了其他特征的影响,从而带来错误的预测结果,所以需要对数据进行归一化。
三、k近邻算法的一般流程
1.收集数据:可以使用任何方法
2.准备数据:距离计算所需要的数值,最好是结构化的数据格式(数据量纲不统一时)
3.分析数据:可以使用任何方法(可用python内的Matplotlib库将数据可视化)
4.训练算法:此步骤不适用于 K 近邻算法
5.测试算法:计算错误率
6.使用算法:首先需要输入样本数据和结构化的输出结果,然后运行K 近邻算法判定输入数据分别属于哪个分类,最后应用对计算出的分类执行后续的处理
四、使用KNN进行手写数字识别的步骤
1.收集数据:提供文本文件
2.准备数据:编写函数classify0(),将图像格式转换为分类器使用的list格式
3.分析数据:在python命令提示符中检查数据,确保符合要求
4.训练算法:KNN不适用这步
5.测试算法:编写函数使用提供的部分数据集(已经分类好的数据)作为测试样本,如果预测的结果不同,则标记错误
6.使用算法:本题没有使用
五、主要代码
数据的准备:
将训练数据和测试数据分别以txt文件的形式保存在trainingDigits和testDigits文件夹中,目录trainingDigits中包含了大约2000个例子,每个例子的内容如下图所示,每个数字大约有200个样本;目录testDigits中包含了大约900个测试数据。
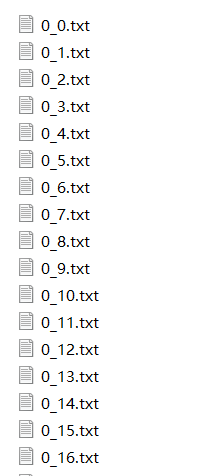
转换图片格式(32X32的二进制矩阵转成1X1024的向量)
def img2vector(filename)
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32): #32行
lineStr = fr.readline() #一次读一行
for j in range(32): #32列
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect``
k-近邻算法
`def classify0(inX, dataSet, labels, k):
"""
-inX :输入变量
-dataSet: 训练样本集
-labels: 标签
-k:选择最相近数据的数目
"""
# 获取样本数据数量
dataSetSize = dataSet.shape[0]
# 计算目标点和数据集之间的距离(默认用欧氏距离),并升序排列
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDisIndicies = distances.argsort()
classCount = {}
# 确定前k个距离最小元素所在的主要分类
for i in range(k):
# 记录该样本数据所属的类别
voteIlabel = labels[sortedDisIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
# 对类别进行降序排列
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
# 返回出现频次最高的类别
return sortedClassCount[0][0]
测试算法
def handwritingClassTest():
# 获取目录内容
hwLabels = []
trainingFileList = listdir('trainingDigits')
#计算样本数量并初始化样本数据矩阵
m= len(trainingFileList)
trainingMat = zeros((m,1024))
# 从文件名解析分类数据
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
# 读取测试数据并计算测试集的列表长
testFileList = listdir('testDigits')
errorCount = 0.0
mTest = len(testFileList)
# 循环测试每个测试数据文件
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
# 提取数据向量
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
# 进行分类操作并打印
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print ("the classifier came back with: %d the real answer is: %d" % (classifierResult,classNumStr))
# 判断算法结果是否准确并打印错误率
if classifierResult != classNumStr : errorCount += 1.0
print("total number of errors is: %d" %errorCount)
print("total error rate is: %f" %(errorCount/float(mTest)))
实验结果
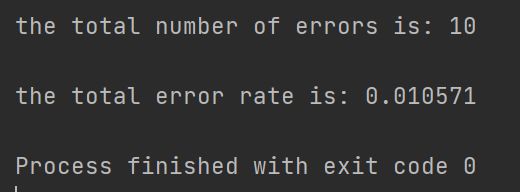
当k=3时,经过测试,有10个像素点分类错误,错误率为0.010571。
六、算法缺点
执行效率并不高,需要大量的空间(优化:K决策树)
七、使用sklearn库实现简单的KNN算法实例
sklearn中用于实现knn的分类器:
from sklearn.neighbors import KNeighborsClassifier
主要参数:
neigh = KNeighborsClassifier(n_neighbors= 3, weights = 'uniform', algorithm = 'auto') #设置最近的3个邻居作为分类的依据
n_ neighbors:用于指定分类器中K的大小(默认值为5)。
weights:设置选中的K个点对分类结果影响的权重(默认值为平均权重“uniform”,可以选择“distance"代表越近的点权重越高,或者传入自己编写的以距离为参数的权重计算函数)。
algorithm:设置用于计算临近点的方法,因为当数据量很大的情况下计算当前点和所有点的距离再选出最近的k各点,这个计算量是很费时的,所以选项中有ball tree、kd_ tree和brute,分别代表不同的寻找邻居的优化算法,默认值为auto,根据训练数据自动选择。
代码
import numpy as np
from sklearn.neighbors import KNeighborsClassifier #knn算法分类模型
#此处我们手动创建训练数据集
feature = np.array([[170,65,40],[167,51,38],[177,80,39],[179,80,43],[170,60,40],[170,60,38],[180,70,42],[170,70,42],[160,50,36],[173,60,38]])
target = np.array(['男','女','女','男','女','女','男','男','女','女'])
#实例knn,此处指定k=3
knn = KNeighborsClassifier(n_neighbors=3)
#训练数据
knn.fit(feature,target)
#模型评分
knn.score(feature,target)
#预测
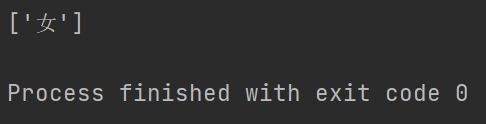
print(knn.predict(np.array([[167,52,39]])))
实验结果如下:
八、参考
https://zhuanlan.zhihu.com/p/25994179
https://www.cnblogs.com/shuai-long/p/11183251.html
Perer Harrington 《机器学习》
https://blog.csdn.net/qq_41709378/article/details/105386111