MySql 百万级数量查询优化总结
1、前言
最近所在项目接触到了百万级人口数据的功能开发,就这次开发也就准备记录下MySql的百万级别数量查询的设计和优化方案,技术能力受限,分享出来和大家一起讨论讨论。
2、数据准备
网上也有很多快速创建大量数据的方式,我这边提供一种可供大家参考:
#创建内存表
CREATE TABLE `t_user_memory` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c_user_id` varchar(36) NOT NULL DEFAULT '',
`c_name` varchar(22) NOT NULL DEFAULT '',
`c_province_id` int(11) NOT NULL,
`c_city_id` int(11) NOT NULL,
`create_time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_user_id` (`c_user_id`)
) ENGINE=MEMORY DEFAULT CHARSET=utf8mb4;
#创建普通表
CREATE TABLE `t_user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c_user_id` varchar(36) NOT NULL DEFAULT '',
`c_name` varchar(22) NOT NULL DEFAULT '',
`c_province_id` int(11) NOT NULL,
`c_city_id` int(11) NOT NULL,
`create_time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `idx_user_id` (`c_user_id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8mb4;
#创建随机字符串
CREATE FUNCTION `randStr` ( n INT ) RETURNS VARCHAR ( 255 ) CHARSET utf8mb4 DETERMINISTIC BEGIN
DECLARE
chars_str VARCHAR ( 100 ) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
DECLARE
return_str VARCHAR ( 255 ) DEFAULT '';
DECLARE
i INT DEFAULT 0;
WHILE
i < n DO
SET return_str = concat(
return_str,
substring( chars_str, FLOOR( 1 + RAND() * 62 ), 1 ));
SET i = i + 1;
END WHILE;
RETURN return_str;
END;
#创建插入数据存储过程
CREATE PROCEDURE `add_t_user_memory` ( IN n INT ) BEGIN
DECLARE
i INT DEFAULT 1;
WHILE
( i <= n ) DO
INSERT INTO t_user_memory ( c_user_id, c_name, c_province_id, c_city_id, create_time )
VALUES
(
uuid(),
randStr ( 20 ),
FLOOR( RAND() * 1000 ),
FLOOR( RAND() * 100 ),
NOW());
SET i = i + 1;
END WHILE;
END;
#循环从内存表获取数据插入普通表
CREATE PROCEDURE `add_t_user_memory_to_outside`(IN n int, IN count int)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i <= n) DO
CALL add_t_user_memory(count);
INSERT INTO t_user SELECT * FROM t_user_memory;
delete from t_user_memory;
SET i = i + 1;
END WHILE;
END;调用:
#循环400次,每次生成10000条数据 总共生成四百万条数据
CALL add_t_user_memory_to_outside(400,10000);由于我们的数据结构比较简单,我们把数据量往上调调
3、问题及解决方案
对于百万级别数据处理,通常会遇到以下几个问题:
1、分页-分页到后面的页数会越来越慢
2、分页-分页的总数conut(*)如何高效率查询
3、模糊查询如何实现双‘%’还能让索引不失效
3.1 分页-分页到后面的页数会越来越慢
我直接就上结果给大家看了:
[SQL]select * from t_user limit 0,20;
受影响的行: 0
时间: 0.002s
[SQL]
select * from t_user limit 10,20;
受影响的行: 0
时间: 0.001s
[SQL]
select * from t_user limit 100,20;
受影响的行: 0
时间: 0.002s
[SQL]
select * from t_user limit 1000,20;
受影响的行: 0
时间: 0.001s
[SQL]
select * from t_user limit 10000,20;
受影响的行: 0
时间: 0.014s
[SQL]
select * from t_user limit 100000,20;
受影响的行: 0
时间: 0.057s
[SQL]
select * from t_user limit 1000000,20;
受影响的行: 0
时间: 0.500s
[SQL]
select * from t_user limit 3000000,20;
受影响的行: 0
时间: 1.533s解决方式的总体思路就是把索引用上,用子查询/连接+索引快速定位数据位置
[SQL]
SELECT * FROM t_user WHERE id >=(select id from t_user limit 3000000, 1) limit 20;
受影响的行: 0
时间: 1.124s
[SQL]
select * from t_user a join (select id from t_user limit 3000000,20) b on a.id = b.id;
受影响的行: 0
时间: 1.125s3.2 分页-分页的总数conut(*)如何高效率查询
我们平时分页都是需要查询总数的,当数量级一上来,就会发现查询速率的大大降低:

ps:当时我跑生成测试数据的时候没有跑完,所以总数没有达到400w,不过并不影响优化效果
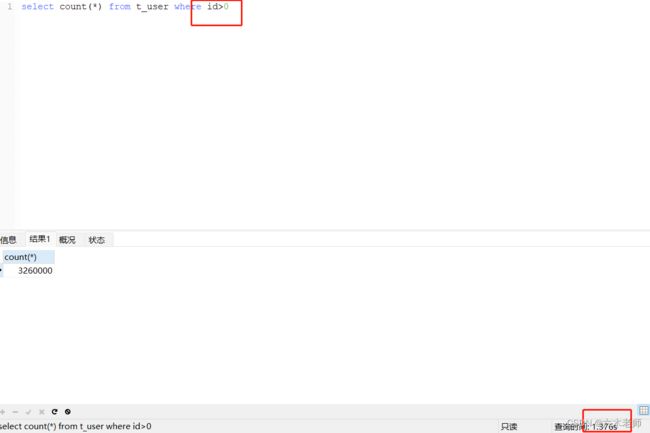 我们进行一个简单的优化速率就大大提升了,后面有查询条件继续往后面加就是了
我们进行一个简单的优化速率就大大提升了,后面有查询条件继续往后面加就是了
这次优化的重点是将原本需要分开执行的两个SQL合并,通过SQL_CALC_FOUND_ROWS函数实现:
select SQL_CALC_FOUND_ROWS
*
from t_user
WHERE id > 0
LIMIT 0,20;
SELECT FOUND_ROWS() as total_num;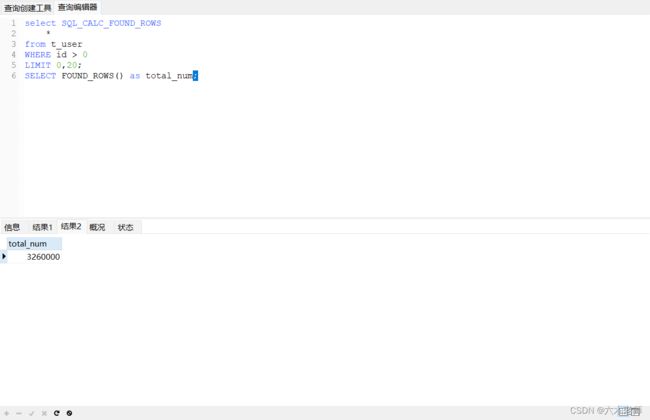
FOUND_ROWS()返回一个数字,指示了在没有LIMIT子句的情况下,第一个SELECT返回了多少行。
在项目中:
这里面涉及到多条结果返回,需要在配置文件application.yml的数据源加上
&allowMultiQueries=true项目代码需要注意的点
#返回类型
List getUserList();
#取值
Integer totalNum = ((List) listData.get(1)).get(0);
List userList= (List)listData.get(0); 3.3 模糊查询如何实现双‘%’还能让索引不失效
大家都知道,通过like '%xxx%'模糊查询会使索引失效,大数据量的情况下,会使得查询非常的缓慢,这个时候我们就可以通过全文索引(Full-Text Search)进行优化。
创建全文索引:
create fulltext index fulltext_c_name on t_user(c_name);
#可能会出现The used table type doesn't support FULLTEXT indexes报错,
查看创建表时用的哪种引擎,如果是InnoDB,改为MyISAM,在MySQL 5.6版本以前,
只有MyISAM存储引擎支持全文引擎,InnoDB不支持FULLTEXT类型的索引使用效果:
select * from t_user where c_name like '%test%';
select * from t_user where MATCH ( c_name ) AGAINST ( '*test*' IN BOOLEAN MODE );
[SQL]select * from t_user where c_name like '%test%';
受影响的行: 0
时间: 0.860s
[SQL]
select * from t_user where MATCH ( c_name ) AGAINST ( '*test*' IN BOOLEAN MODE );
受影响的行: 0
时间: 0.001s
全文索引的使用和类型我就不在这边一一赘述了,这边只是给大家一个思路,同时此全文索引并不支持中文。
在MySQL 5.6版本以前,只有MyISAM存储引擎支持全文引擎,
在5.6版本中,InnoDB加入了对全文索引的支持,但是不支持中文全文索引,
在5.7.6版本,MySQL内置了ngram全文解析器,用来支持亚洲语种的分词,
在使用前请确认自己的mysql版本, 可以使用 select version() 查看mysql的版本
本次的MySql百万级数量查询优化的分享就到这里了,后续有补充我会继续更新。