SpringCloud面试题大全(Netflix+Alibaba)
SpringCloud面试题大全
Spring cloud 是一个基于 Spring Boot 实现的服务治理工具包,用于微服务架构中管理和协调服务的。Spring Cloud 是一系列框架的有序集合。它利用 Spring Boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、负载均衡、断路器、数据监控等,都可以用 Spring Boot 的开发风格做到一键启动和部署。通过 Spring Boot 风格进行再封装屏蔽掉了复杂的配置和实现原理,最终给开发者留出了一套简单易懂、易部署和易维护的分布式系统开发工具包。有了 Spring Cloud 之后,让微服务架构的落地变得更简单。
微服务的理解
其实和SOA 架构类似,微服务是在 SOA 上做的升华,微服务架构强调的一个重点是“业务需要彻底的组件化和服务化”,原有的单个业务系统会拆分为多个可以独立开发、设计、运行的小应用。这些小应用之间通过服务完成交互和集成。服务做到:单一职责、面向服务,对外暴露RestAPI、服务自治。
Eureka
eureka就是服务注册中心(可以是一个集群),对外暴露自己的地址。服务提供者启动后向eureka注册自己的信息(ip、地址、服务名等)。消费者从eureka拉取注册中心维护的服务列表的副本,通过列表上的服务信息,完成服务调用。服务提供者会定期向eureka发送心跳续约。
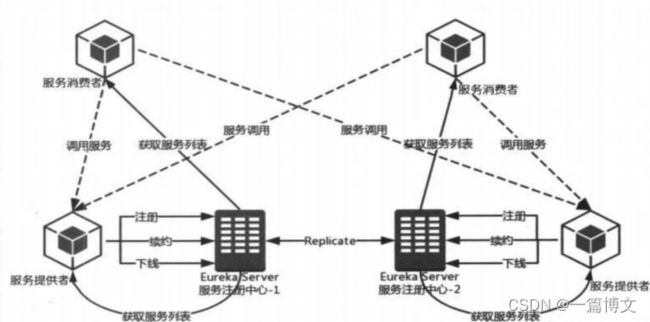
注解:
//标明该服务为Eureka的服务端
@EnableEurekaServer
//标明该服务为Eureka的客户端
@EnableEurekaClient
//标明该服务为Eureka的客户端,替代上
@EnableDiscoveryClient
自我保护机制:默认情况下,如果Eureka Server在一定时间内(默认90秒)没有接收到某个微服务实例的心跳,Eureka Server将会移除该实例。但是当网络分区故障发生时,微服务与Eureka Server之间无法正常通信,而微服务本身是正常运行的,此时不应该移除这个微服务,所以引入了自我保护机制。
自我保护模式正是一种针对网络异常波动的安全保护措施,使用自我保护模式能使Eureka集群更加的健壮、稳定的运行。
自我保护机制的工作机制是如果在15分钟内超过85%的客户端节点都没有正常的心跳,那么Eureka就认为客户端与注册中心出现了网络故障,Eureka Server自动进入自我保护机制。
Ribbon
Ribbon是SpringCloud的负载均衡组件。
我们通过服务名配置好负载均衡算法,就可以直接请求到对应的实例上。底层是通过LoadBalancerInterceptor这个类会在对请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务名。

负载均衡策略
IRule:这是所有负载均衡策略的父接口,里边的核心方法就是choose方法,用来选择一个服务实例。

| 策略 | 说明 |
|---|---|
| com.netflix.loadbalancer.RoundRobinRule 轮询策略 | 启动的服务被循环访问 |
| com.netflix.loadbalancer.RandomRule 随机选择 | 随机从服务器列表中选择一个访问 |
| com.netflix.loadbalancer.RetryRule 重试选择 | 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务 |
| BestAvailableRule 最大可用策略 | 先过滤出故障服务器,再选择一个当前并发请求数最小的服务(nacos是NacosRule(com.alibaba.cloud.nacos.ribbon.NacosRule)) |
| WeightedResponseTimeRule 带有加权的轮询策略 | 对RoundRobinRule的扩展,响应速度越快的实例选择权重越大,越容易被选择 |
| AvailabilityFilteringRule 可用过滤策略 | 先过滤出故障的或并发请求大于阈值的服务实例,再选择并发较小的实例 |
| ZoneAvoidanceRule 区域感知策略 | 默认规则,复合判断server所在区域的性能和server的可用性选择服务器 |
配置文件配置负载进程策略
# 这里使用服务提供者的instanceName
# 通过服务名,来进行不同服务的个性化配置
nacos-producer:
ribbon:
# 代表Ribbon使用的负载均衡策略 (nacos的权重负载策略)
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule #通过配置文件,配置负载均衡策略
# 同一台服务器上的最大重试次数(第一次尝试除外)
MaxAutoRetries: 1
# 重试的下一个服务器的最大数量(不包括第一个服务器)
MaxAutoRetriesNextServer: 1
# 是否可以为此客户端重试所有操作
OkToRetryOnAllOperations: true
# 从源刷新服务器列表的时间间隔
ServerListRefreshInterval: 2000
# Apache HttpClient使用的连接超时
ConnectTimeout: 3000
# Apache HttpClient使用的读取超时
ReadTimeout: 3000
# 另一个服务名
nacos-producer1:
ribbon:
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule #通过配置文件,配置负载均衡策略
懒加载配置
# 预加载配置,默认为懒加载。我们在这里开启预加载。
# 一般在服务多的情况下,懒加载有可能在第一次访问时造成短暂的拥堵,有可能造成生产故障。
ribbon:
eager-load:
enabled: true
clients: nacos-producer #这里添加的是预加载的服务名
OpenFeign
Spring Cloud OpenFeign对Feign进行了增强,是声明式、模板化的HTTP客户端。用于远程服务调用。
OpenFeign可以把Rest的请求进行隐藏,伪装成类似SpringMVC的Controller一样。你不用再自己拼接url,拼接参数等等操作,一切都交给OpenFeign去做。
- 启动类
//开启feign客户端
@EnableFeignClients
- feign接口
- 首先这是一个接口,Feign会通过动态代理,帮我们生成实现类。这点跟mybatis的mapper很像
- @FeignClient ,声明这是一个Feign客户端,同时通过 value 属性指定服务名称
- 接口中的定义方法,完全采用SpringMVC的注解,Feign会根据注解帮我们生成URL,并访问获取结果
//指定接口代理nacos-producer客户端,path为当前服务接口前缀。
@FeignClient(value = "nacos-producer", path = "/product")
public interface ProductFeignService {
}
OpenFeign中本身已经集成了Ribbon依赖和自动配置,因此不需要额外引入依赖,也不需要再注入 RestTemplate 对象。
Hystrix
hystrix是Netlifx开源的一款容错框架,防雪崩利器,具备服务降级,服务熔断,依赖隔离,监控(Hystrix Dashboard)等功能。
- 熔断机制:当失败率达到阀值自动触发熔断(如因网络故障、超时造成的失败率)。熔断的含义是直接忽略该服务,返回兜底数据;
- 降级机制:超时降级、资源不足时(线程或信号量)降级 、运行异常降级等,降级后可以配合降级接口返回托底数据。
单独使用
- 启动类
// 添加断路器支持
@EnableCircuitBreaker
降级Fallback
@RestController
@RequestMapping("h1")
@DefaultProperties(defaultFallback = "classFallBack")
public class HystrixController01 {
@RequestMapping("/method01/{id}")
//添加到方法上,表明该方法开启服务降级、熔断
@HystrixCommand(fallbackMethod = "methodFallBack")
//@HystrixCommand
public String method(@PathVariable String id) {
try {
TimeUnit.SECONDS.sleep(5);//出现sleep interrupted睡眠中断异常
} catch (InterruptedException e) {
e.printStackTrace();
}
return "hello world!";
}
public String methodFallBack(String id) {
return "系统异常,请及时联系客服人员。";
}
/**
* com.netflix.hystrix.contrib.javanica.exception.FallbackDefinitionException:
* fallback method wasn't found: classFallBack([])
* 这里要注意,我们在class的回调方法中,形参列表必须为空。
* 不然会出现以上错误。
* @return
*/
public String classFallBack(/*String id*/) {
return "系统异常,请及时联系客服人员。";
}
}
线程隔离
服务雪崩效应产生与服务堆积在同一个线程池中有关,因为所有的请求都是同一个线程池进行处理,这时候如果在高并发情况下,所有的请求全部访问同一个接口,这时候可能会导致其他服务没有线程进行接受请求,这就是服务雪崩效应。
@RestController
@RequestMapping("h2")
public class HystrixController02 {
@GetMapping("/method01/{id}")
@HystrixCommand(fallbackMethod = "methodFallBack",
//测试thread和semaphore 两种隔离策略的异同
// execution.isolation.strategy 默认为thread
commandProperties = {
//@HystrixProperty(name= HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY, value = "THREAD")}
@HystrixProperty(name= HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY, value = "SEMAPHORE")}
)
public String method01(@PathVariable String id){
//xxxx
}
@GetMapping("/method02/{id}")
@HystrixCommand(fallbackMethod = "methodFallBack",
commandProperties = {
设置超时的时候不中断线程,默认为true
@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_ISOLATION_THREAD_INTERRUPT_ON_TIMEOUT,value="false")}
)
public String method02(@PathVariable String id){
//xxxx
}
@GetMapping("/method03/{id}")
@HystrixCommand(fallbackMethod = "methodFallBack",
commandProperties = {
//设置熔断策略为semaphore,并且最大连接为1 (可以通过该思路来实现,限流)
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY, value = "SEMAPHORE"),
@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS,value="1")}
)
public String method03(@PathVariable String id){
//xxxx
}
@GetMapping("/method04/{id}")
@HystrixCommand(fallbackMethod = "methodFallBack",
commandProperties = {
//设置是否超时,默认为true
@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_TIMEOUT_ENABLED,value="false")}
)
public String method04(@PathVariable String id){
//xxxx
}
@GetMapping("/method05/{id}")
@HystrixCommand(fallbackMethod = "methodFallBack",
commandProperties = {
//设置过期时间,单位:毫秒,默认:1000
@HystrixProperty(name=HystrixPropertiesManager.EXECUTION_ISOLATION_THREAD_TIMEOUT_IN_MILLISECONDS,value="6000")}
)
public String method05(@PathVariable("id")String id){
//xxxx
}
public String methodFallBack(String id) {
return "系统异常,请及时联系客服人员。";
}
}
服务熔断
服务在高并发的情况下出现进程阻塞,导致当前线程不可用,慢慢的全部线程阻塞 ,导致服务器雪崩。这时直接熔断整个服务,而不是一直等到服务器超时。
- 断路器全开时:一段时间内 达到一定的次数无法调用 并且多次监测没有恢复的迹象 断路器完全打开 那么下次请求就不会请求到该服务
- 半开:短时间内有恢复迹象断路器会将部分请求发给该服务,正常调用时断路器关闭
- 关闭:当服务一直处于正常状态能正常调用
/**
* circuitBreaker.enabled :true 打开熔断 默认开启
* circuitBreaker.requestVolumeThreshold: 当在配置时间窗口内达到此数量的失败后,进行短路。默认20个
* circuitBreaker.sleepWindowInMilliseconds:短路多久以后开始尝试是否恢复,默认5s
* circuitBreaker.errorThresholdPercentage:出错百分比阈值,当达到此阈值后,开始短路。默认50%
*/
@GetMapping("/method06/{id}")
@HystrixCommand(fallbackMethod = "methodFallBack",
commandProperties = {
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "10000"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60")}
)
public String method06(@PathVariable String id){
//xxxx
}
整合Feign
- 启动类
@EnableFeignClients
//@SpringBootApplication
//@EnableCircuitBreaker //开启熔断器
//@EnableDiscoveryClient
@SpringCloudApplication //以上三个注解的组合注解
- 配置
feign:
hystrix:
#feign是否开启熔断
enabled: true
-
Fallback类,相比于FallbackFactory,工厂可以用来获取到触发断路器的异常信息。建议使用FallbackFactory。
-
FallbackFactory
- feign接口
/** * fallbackFactory 指定一个fallback工厂,与指定fallback实现类不同, * 此工厂可以用来获取到触发断路器的异常信息, * ProductFeignFallBack需要实现FallbackFactory类 * 指定服务的serviceName */ @FeignClient(value = "rest-template-user",fallbackFactory = ProductFeignFallBack.class) @Component public interface Product02Feign { @GetMapping("/product/getString") public String getString(); }- 回退工厂实现类
@Component @Slf4j /** * 必须实现FallBackFactory,且它的泛型必须是你要指定地点feign的接口。 */ public class ProductFeignFallBack implements FallbackFactory<ProductFeign> { @Override public ProductFeign create(Throwable throwable) { return new ProductFeign() { @Override public String getString() { log.error("fallback reason:{}",throwable.getMessage()); return "我犯错了,我知道。"; } }; } }
Gateway
Spring Cloud Gateway是建立在Spring生态系统之上的API网关,Spring Cloud Gateway旨在提供一种简单而有效的方法来路由到api。所谓的API网关,就是指系统的统一入口,它封装了应用程序的内部结构,为客户端提供统一服务,一些与业务本身功能无关的公共逻辑可以在这里实现,诸如认证、鉴权、监控、路由转发等等。
gateway相当于所有服务的门户,将客户端请求与服务端应用相分离,客户端请求通过gateway后由定义的路由和断言进行转发,路由代表需要转发请求的地址,断言相当于请求这些地址时所满足的条件,只有同时符合路由和断言才给予转发。最后过滤器是对请求的增强。
核心概念
- 路由(route):路由信息的组成是由一个id、一个目的url、一组谓词匹配、一组Filter组成的。如果路由的谓词为真,说明请求url和配置路由匹配。
- 谓词(predicate)(断言): 谓词函数允许开发者去定义匹配来自于Http Requeset中的任何信息比如请求头和参数。
- 过滤器(Filter): 过滤器Filter将会对请求的请求和响应进行修改处理。Filter分为两种类型的Filter,分别是Gateway Filter和Global Filter。
工作流程
- Gateway Client向Gateway Server发送请求
- 请求首先会被HttpWebHandlerAdapter进行提取组装成网关上下文
- 然后网关的上下文会传递到DispatcherHandler,它负责将请求分发给RoutePredicateHandlerMapping
- RoutePredicateHandlerMapping负责路由查找,并根据路由断言判断路由是否可用
- 如果过断言成功,由FilteringWebHandler创建过滤器链并调用
- 请求会一次经过PreFilter–微服务–PostFilter的方法,最终返回响应
应用
spring:
cloud:
gateway:
# 默认全局过滤器,对所有路由生效
default-filters:
# 响应头过滤器,对输出的响应设置其头部属性名称为
# X-Response-Default-MyName,值为 lz
# 如果有多个参数多则重写一行设置不同的参数
- AddResponseHeader=X-Response-Default-MyName, lz
# 路由
routes:
- id: feign-consummer-route
uri: lb://feign-consummer
# 谓词
predicates:
- Path=/**
# 过滤器
filters:
- PrefixPath=/feign
自定义全局过滤器
@Component
public class AuthMyFilter implements GlobalFilter, Ordered {
/**
* @description 过滤器执行方法
* @param exchange 前后端交互信息,包括request与response
* @param chain 过滤器链
* @return 下个过滤器直到过滤器结束或者校验不通过返回结果
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//开始执行鉴权方法
//获取请求参数
String token = exchange.getRequest().getHeaders().getFirst("token");
if (StringUtils.isEmpty(token)) {
ServerHttpResponse response = exchange.getResponse();
response.setStatusCode(HttpStatus.INTERNAL_SERVER_ERROR);
String msg = "token is null!";
DataBuffer wrap = response.bufferFactory().wrap(msg.getBytes());
return response.writeWith(Mono.just(wrap));
}
// 调用下个过滤器(过滤器是基于函数回调)
return chain.filter(exchange);
}
/**
* @description 定义过滤器优先级,数字越小优先级约高,可以为负数
*/
@Override
public int getOrder() {
return 0;
}
}
跨域配置
spring:
cloud:
gateway:
globalcors:
corsConfigurations:
#允许跨域的请求路径
'[/**]':
#允许的来源
allowedOrigins: "*"
#允许的方法
allowedMethods:
- GET
- POST
#是否允许携带cookie
allowCredentials: true
#允许http请求携带的header
allowedHeaders:
- Content-Type
#response应答可以暴露的header
exposedHeaders:
- Content-Type
Config
配置中心。
分布式系统中,由于服务数量非常多,配置文件分散在不同的微服务项目中,config支持配置文件放在远程Git仓库(GitHub、码云),对配置文件集中管理。
Bus是消息总线可以为微服务做监控,也可以实现应用程序之间相互通信。 Spring Cloud Bus可选的消息代理有RabbitMQ和Kafka。对配置文件进行监控和通知。
Nacos
致力于服务发现、配置和管理微服务。
相比于eureka来说,nacos除了可以做服务注册中心。其实它也集成了服务配置的功能,我们可以直接使用它作为服务配置中心。
基本概念
- 服务注册:Nacos Client会通过发送REST请求的方式向Nacos Server注册自己的服务,提供自身的元数据,比如ip地址、端口等信息。Nacos Server接受到注册请求后,就会把这些元数据信息存储在一个双层的内存Map中。
- 服务心跳:在服务注册后,Nacos Client会维护一个定时心跳来持续通知Nacos Server,说明服务一直处于可用状态,防止被剔除。默认5s发送一次心跳。
- 服务同步:Nacos Server集群之间会互相同步服务实例,用来保证服务信息的一致性。
- 服务发现:服务消费者(Nacos Client)在调用服务提供者的服务时,会发送一个REST请求给Nacos Server,获取上面的注册清单,并且缓存在Nacos Client本地, 同时会在Nacos Client本地开启一个定时任务定时拉取服务端最新的注册表信息更新到本地缓存。
- 服务健康检查:Nacos Server会开启一个定时任务用来检查注册服务实例的健康情况,对于超过15s没有收到客户端心跳的实例会将它的healthy属性设置为false(客户端服务发现时不会发现),如果某个实例超过30s没有收到心跳,直接剔除该实例(被剔除的实例如果恢复发送心跳则会重新注册)。
Sentinel
分布式容错机制。Sentinel 以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性。相比于hystrix功能更加丰富,还有可视化配置的控制台。Sentinel 是面向分布式服务架构的流量控制组件,主要以流量为切入点,从限流、流量整形、熔断降级、系统负载保护、热点防护等多个维度来帮助开发者保障微服务的稳定性。
使用时先定义好资源埋点。只要有了资源,我们就可以在任何时候灵活地定义各种流量控制规则。
注解实现流控
- @SentinelResource注解实现
- @SentinelResource 注解用来标识资源是否被限流、降级。
- blockHandler: 定义当资源内部发生了BlockException应该进入的方法(捕获的是Sentinel定义的异常)
- fallback: 定义的是资源内部发生了Throwable应该进入的方法
- exceptionsToIgnore:配置fallback可以忽略的异常
可配置的参数:
- 流控规则配置
- 流控阈值类型
- QPS
- 线程数
- 流控模式
- 直接
- 关联
- 链路
- 流控效果
- 快速失败
- Warm Up(激增流量)
- 排队等待
- 流控阈值类型
- 降级规则配置
- 慢调用比例
- 异常比例
- 异常数
- 热点参数限流
- 授权控制规则(可设置黑名单、白名单)
整合Feign
- yml
#对Feign的支持
feign:
sentinel:
enabled: true # 添加feign对sentinel的支持
- feign
@FeignClient(value = "nacos-producer", path = "/product", fallback = ProductFeignFallback.class)
public interface ProductFeignService {
//xxxxx
}
- fallback
@Component
public class ProductFeignFallback implements ProductFeignService {
//xxxx
}
Seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
CAP定理
- Consistency(一致性):用户访问分布式系统中的任意节点,得到的数据必须一致。
- Availability(可用性):用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝。
- Partition tolerance (分区容错性):因为网络故障或其它原因导致分布式系统中的部分节点与其它节点失去连接,形成独立分区。
在分布式系统中,系统间的网络不能100%保证健康,一定会有故障的时候,而服务有必须对外保证服务。因此Partition Tolerance不可避免。
如果此时要保证一致性,就必须等待网络恢复,完成数据同步后,整个集群才对外提供服务,服务处于阻塞状态,不可用。
如果此时要保证可用性,就不能等待网络恢复,那节点之间就会出现数据不一致。
也就是说,在P一定会出现的情况下,A和C之间只能实现一个。
分布式事务最大的问题是各个子事务的一致性问题,因此可以借鉴CAP定理和BASE理论,有两种解决思路:
- AP模式:各子事务分别执行和提交,允许出现结果不一致,然后采用弥补措施恢复数据即可,实现最终一致。
- CP模式:各个子事务执行后互相等待,同时提交,同时回滚,达成强一致。但事务等待过程中,处于弱可用状态。
BASE理论
BASE理论是对CAP的一种解决思路,包含三个思想:
- Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
Seata中的三大角色
-
TC (Transaction Coordinator) - 事务协调者:维护全局和分支事务的状态,驱动全局事务提交或回滚。这个就是我们的Seata服务器,用于全局控制。
-
TM (Transaction Manager) - 事务管理器:定义全局事务的范围:开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - 资源管理器:管理分支(本地)事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
Seata支持4种事务模式
- AT:本质上就是2PC的升级版,在 AT 模式下,用户只需关心自己的 “业务SQL”,对业务无侵入。
- TCC:和我们上面讲解的思路是一样的。
- XA:同上,但是要求数据库本身支持这种模式才可以。
- Saga:用于处理长事务,每个执行者需要实现事务的正向操作和补偿操作。
AT模式设计思路
AT模式的核心是对业务无侵入,是一种改进后的两阶段提交。
简单总结:
-
一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。提交至数据库。
-
事务管理器:定义全局事务的范围:开始全局事务、提交或回滚全局事务。
-
RM (Resource Manager) - 资源管理器:管理分支(本地)事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其中,TC 为单独部署的 Server 服务端,TM 和 RM 为嵌入到应用中的 Client 客户端。
Seata支持4种事务模式
- AT:本质上就是2PC的升级版,在 AT 模式下,用户只需关心自己的 “业务SQL”,对业务无侵入。
- TCC:和我们上面讲解的思路是一样的。
- XA:同上,但是要求数据库本身支持这种模式才可以。
- Saga:用于处理长事务,每个执行者需要实现事务的正向操作和补偿操作。
AT模式设计思路
AT模式的核心是对业务无侵入,是一种改进后的两阶段提交。
简单总结:
- 一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。提交至数据库。
- 二阶段如果确认提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可,当然如果需要回滚,那么就用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。