探秘MySQL——排查与调优
文章目录
- 一、问题排查一:SQL执行出错
- 二、问题排查二:慢查询
-
- 0.几个重要参数
- 1.配置慢查询日志
-
- 命令行配置(重启失效)
- 修改配置文件(永久生效)
- 2.查看慢查询日志
- 3.问题排查1:Look_time耗时
- 4.问题排查2:索引
- 5.问题排查3:拆解复杂SQL
- 三、常见优化问题
-
- Q1.解决大SQL文件无法导入的问题
- Q2.大量执行update语句的优化
- Q3.分页的实现及优化
- Q4.回表查询优化
- 参考
一、问题排查一:SQL执行出错
使用工具: Navicat for MySQL
当执行了一条错误的SQL语句,会显示错误信息,包含了错误码、错误详情。
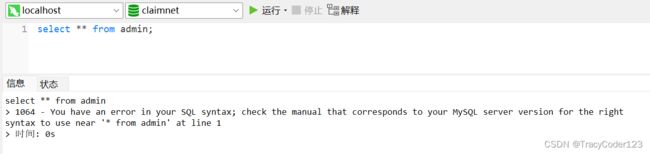
错误详情中会显示出错的原因和具体位置,方便我们进行位置的定位和排查。
1064 - You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near '* from admin' at line 1
一般来说,根据错误详情就能直接判断出错原因,但有时候,可能会出现一些我们从来没遇到过的问题,此时,借助互联网,对问题进行一个检索,并且还要甄别网络上提供的解决方式是否靠谱,可以多多尝试。
二、问题排查二:慢查询
使用工具: 慢查询日志
0.几个重要参数
# 是否开启慢查询日志,默认OFF,开启则设置为 ON
slow_query_log
# 慢查询日志文件存储位置
slow_query_log_file
# 是否把没有使用到索引的SQL记录到日志中,默认OFF,开启则设置为 ON
log_queries_not_using_indexes
# 超过多少秒的查询才会记录到日志中,注意单位是秒
long_query_time
1.配置慢查询日志
命令行配置(重启失效)
在数据库中执行以下语句:
SET GLOBAL slow_query_log_file = 'D:/setup/mysql8.0.27/log/slow.log';
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL log_queries_not_using_indexes = 'ON';
SET GLOBAL long_query_time = 0.001;
通过查询看看是否配置成功:
SELECT @@global.slow_query_log_file;
修改配置文件(永久生效)
【先留个坑在这】
2.查看慢查询日志
打开慢查询日志,查看里面的一条记录:
# Time: 2023-03-12T09:32:24.818300Z
# User@Host: root[root] @ localhost [::1] Id: 11
# Query_time: 0.003975 Lock_time: 0.000116 Rows_sent: 393 Rows_examined: 786
SET timestamp=1678613544;
select * from text
order by application_no;
- 可以看到以下信息:
查询用户User
查询耗费时间Query_time
锁等待时间Lock_time
结果集行数Rows_sent
累积扫描行数Rows_examined
具体的SQL语句
这些信息可以协助我们排查慢查询问题。
3.问题排查1:Look_time耗时
Look_time耗时反映了事务的并发性能,如果慢查询日志中出现了很多这样的记录,说明是事务的并发性能出现了问题。
- 执行命令查询MySQL整体的锁状态:
show status like 'innodb_row_lock_%';
如果查询出来的值比较大,就意味着你当前MySQL服务器承载的并发压力过高,此时就急需进行系统的高并发优化。
4.问题排查2:索引
如果不是事务并发问题,那么很有可能是SQL本身有问题,比如可能是索引方面需要优化。
这个问题参考我的另一篇博客:这里
5.问题排查3:拆解复杂SQL
如果一条复杂的SQL出现效率问题,为了准确地定位问题所在,可以采取分解SQL子句的方式进行问题排查。
- 用explain检查每个SQL子句,初步定位问题;
- SQL子句逐条合并,每合并一次用explain检查一次。
三、常见优化问题
Q1.解决大SQL文件无法导入的问题
修改max_allowed_packet参数设置,可以通过命令行设置,也可以通过修改配置文件设置,二者的生效时间不同。
Q2.大量执行update语句的优化
优化方向:减少commit次数,每次commit会产生两次磁盘同步(写redo log和写bin log)
- 优化1:拼接多个update语句为一条语句
通过case when可以从一定程度上将update语句合并成一句。语句的减少会导致commit次数减少。 - 优化2:尽可能地把多个update语句放在一个事务中
一个事务仅commit一次。
Q3.分页的实现及优化
需求:某一页需要查询的记录为表中的第300-350条数据。
优化思路:聚集索引
- 使用limit:
explain select * from text limit 300,350;
用explain分析一下,会发现,type=all表示全表扫描。效率贼低。

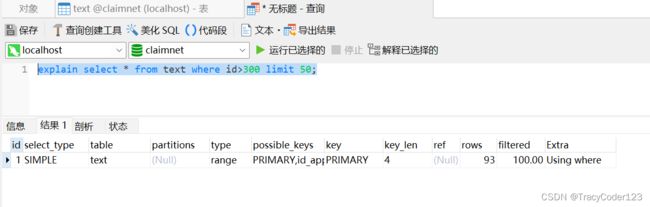
- 走聚集索引:
explain select * from text where id>300 limit 50;
type=range表示只检索给定范围的行,因为加入了where子句,其中使用了主键,导致走了聚集索引,效率有所提升。
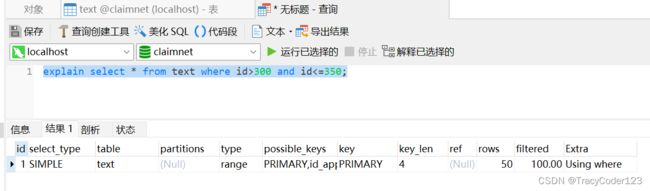
- 放弃limit,全部依靠聚集索引:
explain select * from text where id>300 and id<=350;
这种实现方式有一个问题就是,由于被删除了一部分记录,导致自增主键不连续,这时候就会出现页与页间有记录重叠的情况。
Q4.回表查询优化
优化思路:联合索引、索引覆盖
看下面一个语句:
explain SELECT date FROM text where application_no>'EP2567834';
在没有设置联合索引的时候,好家伙,直接全表扫描。

- 设置非聚集索引再执行:
ALTER TABLE text ADD INDEX(`application_no`);
可以用非聚集索引,为啥没用呢?因为 要回表查询 啊,比全表扫描还慢,要这索引有何用?

- 添加联合索引,成功解决回表问题:
ALTER TABLE text ADD INDEX union_index(application_no,date);
这次终于命中了,既不用全表扫描,也不用回表查询,嘿嘿。

参考
博客
慢查询
mysql配置文件
博客
update优化
分页优化