【JVM篇1】认识JVM,内存区域划分,类加载机制
目录
一、JVM运行时内存区域划分
①程序计数器(每个线程都有一个)
②栈:保存了局部变量和方法调用的信息(每一个线程都有一个栈)
如果不停地调用方法却没有返回值,会产生什么结果
③堆(每一个进程都有一个堆,线程共享一个堆)
如何区分一个变量是处于栈上还是堆上呢?
④方法区(线程共享)
类对象是什么
运行时常量池
⑤本地方法栈(线程私有)
总结一下:JVM内存分区
二、类加载机制
步骤1:Loading
步骤2:Linking(验证、准备、解析)
①验证:验证Class文件是否符合规范
②准备:给静态变量分配内存
③解析:初始化类的常量池当中的一些常量
步骤3:初始化(初始化对象,为静态属性赋值)
类加载顺序
双亲委派模型
JVM类加载器是什么(3个类加载器)
标准库的String类是怎样被加载的
自定义的Test类是怎加加载的
双亲委派模型的好处
类加载一定要双亲委派模型吗
为什么Tomcat不使用默认的JVM内置的类加载器
Tomcat是怎样隔离各个webapps目录的?
一、JVM运行时内存区域划分
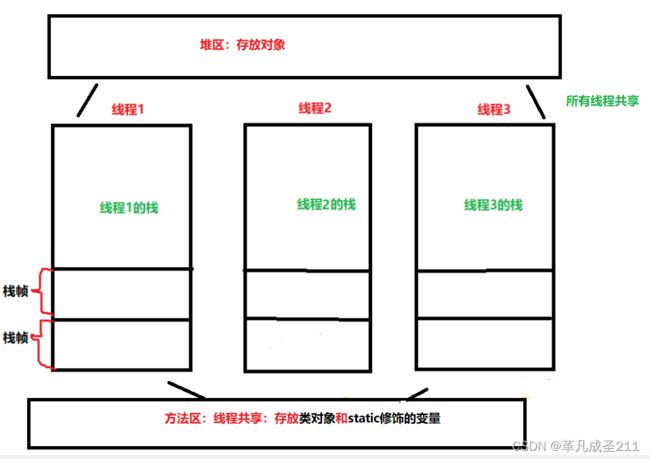
JVM的内存区域被划分为了以下4个部分:
程序计数器、栈、堆、方法区。
下面,将分别介绍这几个区是干什么的。
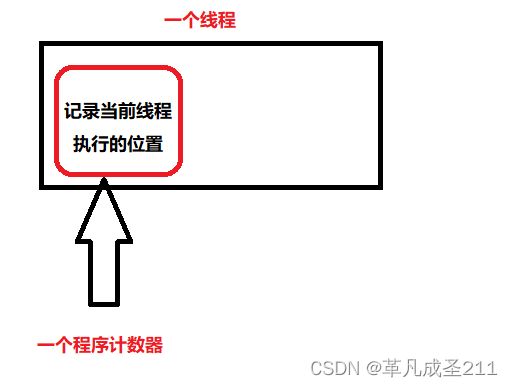
①程序计数器(每个线程都有一个)
这一个区域是内存当中最小的区域。保存了下一条要执行的指令的地址在哪里。
指令:就是字节码。程序要运行,JVM就得把字节码加载起来,存放到内存当中。
当程序把一条条指令从内存当中取出来,放到CPU上面执行的时候,也需要随时记住执行到哪一条了(因为CPU是并发执行命令的,不是只给一个进程提供服务的)
每一个线程都会有一个程序计数器。(因为操作系统是以线程为单位进行调度的)每一个线程都需要记录自己执行的位置。
②栈:保存了局部变量和方法调用的信息(每一个线程都有一个栈)
当每调用一个新的方法的时候,都会涉及到"入栈"操作。每执行完一个方法的时候,就会把这一个方法从内存栈当中移除。
当A方法内部调用B方法,然后在B方法内调用C方法的结果是怎样的呢?
首先,会在内存栈当中存放A方法的有关信息。然后,调用B方法的时候,在栈中存放B方法的信息。最后调用C方法的时候,会在栈当中存放C方法有关的信息。
此处,"有关的信息"有:方法的局部变量、方法传入的参数(形参)、调用的位置、返回的位置等等信息。
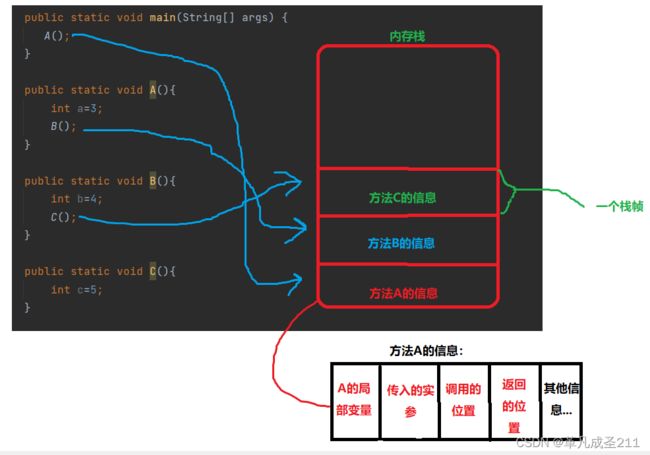
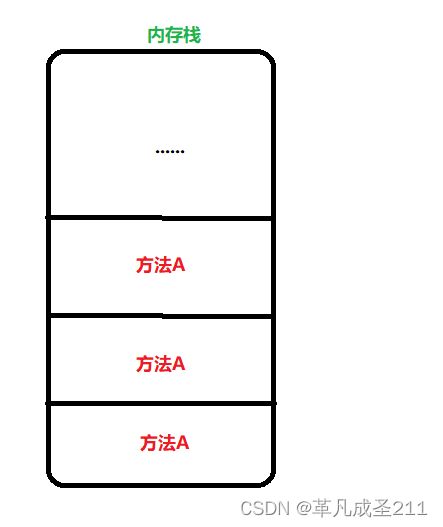
当方法执行完毕(或者return)之后,方法对应的信息也会随之从内存栈上面消失。每一个存放方法的区域被称为一个"栈帧"。
如果不停地调用方法却没有返回值,会产生什么结果

运行一下程序,可以发现:
此处抛出了一个错误信息:StackOverflowError
JVM的栈空间是比较小的,但是也就一般几M或者几十M,因此在上述的调用过程当中栈很有可能会满了的。
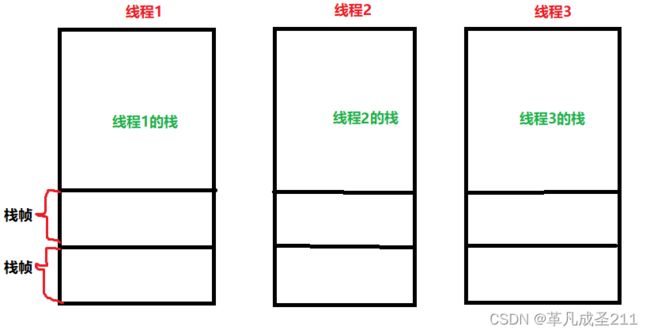
对于栈来说,每一个线程都有一个栈。不同的线程有不同的栈
③堆(每一个进程都有一个堆,线程共享一个堆)
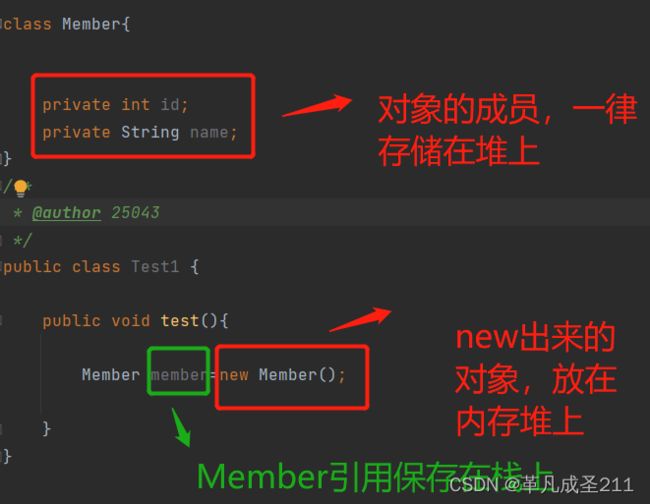
堆是内存内存空间当中最大的区域。new出来的对象,就是在堆当中的。那么也就意味着,对象的成员变量也是存储在堆当中的。
如何区分一个变量是处于栈上还是堆上呢?
局部变量(也就是方法内部创建的基本数据类型变量)都存储在调用这个方法的线程的栈上。
成员变量和new出来的对象,都存放在堆上面。但是方法内部对于对象的引用是保存在栈上面的。
④方法区(线程共享)
方法区当中,存放的是一个类的.class对象(二进制字节码)。
这里的这个class对象,就是保存在方法区当中的。
同时,方法区当中还保存了这个类的静态属性。
类对象是什么
类对象描述的就是它对应类当中的属性、方法、以及各自的权限描述符。
此外,一个类当中的static方法、static属性也是属于类对象的。这些方法、属性又被称为"类方法"、"类属性"。
运行时常量池
在1.7版本之前,运行时常量池是在方法区中的,在1.7及以后的版本中,将运行时常量池移到了堆中。
下图来源于网站:从内存角度理解static与final关键字 - 简书
⑤本地方法栈(线程私有)
用于存放native修饰的方法。
总结一下:JVM内存分区
| 名称 | 描述 | 线程私有or线程共享 |
| 程序计数器 | 用于记录线程执行的下一条指令是什么(记录上下文) | 私有 |
| 栈区 | 用于存放局部变量和new出来对象的引用。 | 私有 |
| 堆区 | 存放实例对象和对象的属性 | 共享 |
| 方法区 | 存放类对象(.class对象)和static修饰的变量 | 共享 |
| 本地方法栈 | 提供native方法服务 | 私有 |
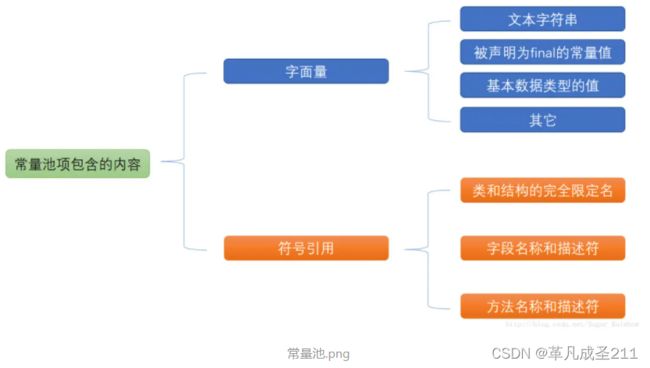
| 运行时常量池 | 存放字面量&符号引用; 1.7:方法区; 1.8:堆区。 |
共享 |
二、类加载机制
简单来说,就是把.class文件,加载到内存当中,构建类对象。
类加载分为3个步骤:
步骤1:Loading
步骤2:Linking
步骤3:Initialization
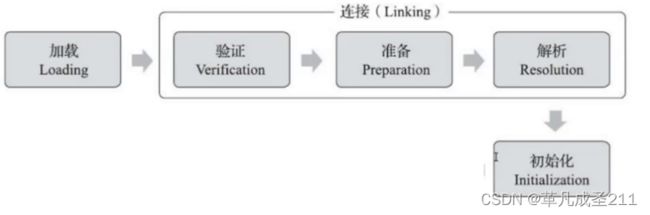
下面,详细说明一下每一个步骤是干什么的:
步骤1:Loading
先找到对应的.class文件,然后打开并且读取.class文件。同时初步生成一个类对象(但是不是真正使用的对象)。
1)通过一个类的全限定名来获取此类的二进制字节流;
2)将这个字节流所代表的静态存储结构转化为方法运行时候的数据结构;
3)在内存当中生成一个代表此类的java.lang.Class对象。然后把这个Class对象,放入到方法区当中,作为方法区这个类的各种数据的访问入口。

下面,来看一下这个二进制的.class文件究竟包含了什么。
下图就是一个ClassFile的图示。
其中,左边的u4代表的就是,u2等信息代表的是占了多少个字节。
u4就是4个字节的unsigned int。u2就是2个字节的unsigned int。

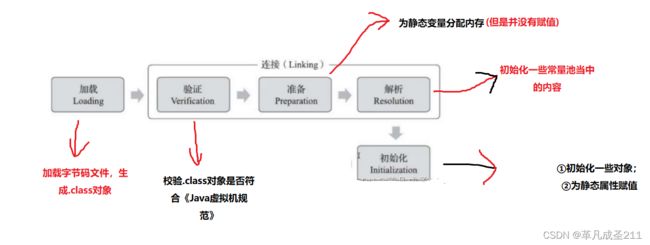
步骤2:Linking(验证、准备、解析)
由上图,也可以看到在连接部分分为了三个步骤:验证、准备、解析;
首先,看一下"验证"这个部分是做什么的
①验证:验证Class文件是否符合规范
确保Class文件的字节流中包含的信息符合《Java虚拟机规范》的全部约束要求。如果想读取Class文件的内容,就需要先验证一下是否符合规范。验证的内容有:
文件格式验证;
字节码验证;
符号引用验证。
②准备:给静态变量分配内存
例如,给static修饰的变量分配内存,并且设置上初始的值:也就是默认值。
例如下面的代码当中,有一个属性为id,它被static修饰,并且它的值为123。
但是在现在这个阶段,它真实的值还是0。
class Member{
private static int id=123;
private String name;
}③解析:初始化类的常量池当中的一些常量
在前面我们也提到了,.class文件当中包含了一些常量,每一个常量都有一个编号。那么这个时候,就是初始化一些常量的时候了。
步骤3:初始化(初始化对象,为静态属性赋值)
此时,就是针对对象进行初始化的操作,在这一步的基础上产生对象。
同时,在这一个步骤上,会把静态的变量给赋值上它对应的值。
例如在前面的时候,提到了在准备阶段,为一个静态的变量赋上默认的值。但是并没有为它赋值上真正的值。那么就是在初始化的阶段为它赋值上真正的值。
类加载顺序
让一个类B继承自A。然后在A这个类当中包含以下几个内容:
A的构造方法、一个构造代码块、一个静态代码块。
然后,让B继承自A,在B这个类的内部,包含以下的几个内容:
B的构造方法、B的构造代码块、B的静态代码块。
最后,令一个Test类继承自B类,并且在Test类当中包含一个mian方法。main方法当中连续两次调用new Test()。
class A {
public A() {
System.out.println("A的构造方法");
}
{
System.out.println("A的构造代码块");
}
static {
System.out.println("A的静态代码块");
}
}
class B extends A {
public B() {
System.out.println("B的构造方法");
}
{
System.out.println("B的构造代码块");
}
static {
System.out.println("B的静态代码块");
}
}
/**
* @author 25043
*/
public class Test1 extends B {
public static void main(String[] args) {
System.out.println("第一次new");
new Test1();
System.out.println("第二次new");
new Test1();
}
}
运行之后,结果是:
根据以上的特点,可以得出来,加载类实例的几个原则:
1、类加载首先需要加载静态的代码块:先父类静态代码块,然后子类静态代码块;
2、静态代码块只会在类加载的时候执行1次。若重复加载(重复new对象)那么只会执行一次。
3、构造代码块和构造方法每一次new都会执行。并且构造代码块一定优先于构造方法执行。
4、无论是静态还是实例代码块,一定都是父类在子类之前。
总结一下,那就是:
静态优先且唯一、父类优先、代码块优先。
为什么在输出"第一次new"之前,先输出了"第一次加载A"和"第一次加载B"呢?
因为:如果想要执行main方法,首先需要加载Test类。但是由于Test继承于B类,然后B类又继承于A类。因此,会首先加载顶级父类A的静态代码块,然后再加载下一级父类的静态代码块。
双亲委派模型
在上面的文章当中,我们提到了,类的加载分为3个阶段:
第一阶段:Loading阶段;
第二阶段:Linking阶段;
第三阶段:Initialing阶段。
Loading阶段,主要负责的就是加载一个类的字节码文件,并生成一个Class对象。
而双亲委派模型,描述的是JVM当中的类加载器,如何根据全限定名:类名+包名(例如Java.lang.String)找到.class文件的过程,这个过程属于Loading阶段当中比较靠前的阶段。
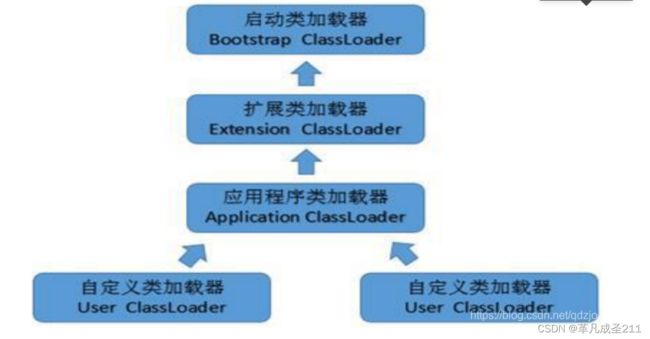
JVM类加载器是什么(3个类加载器)
JVM的类加载器主要是以下的3个:
1、BootStarpClassLoader:负责加载标准库当中的类(例如String、List等等)
2、ExtensionClassLoader:负责加载JDK当中的扩展类
3、ApplicationClassLoader:负责加载当前目录当中的类。
当然,也有一个用户自定义的类加载器(User-Defined ClassLoader)。如果没有自定义的类加载器,那么默认就是上面的3个。
每一个类加载器负责加载自己对应的目录。
下图来源于博客JVM类加载器(详解)_jvm中类加载器的作用是什么_glenzhang(ty)的博客-CSDN博客
而上述的双亲委派模型,就描述了找目录的过程,上述3个类加载器/4个是怎样进行配合的。
下面,举一个例子:(假设没有用户自定义类加载器)
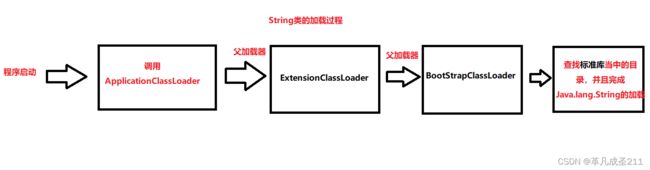
标准库的String类是怎样被加载的
第一步:程序启动,先进入ApplicationClassLoader类加载器。
第二步:然后在ApplicationClassLoader当中检查一下,它的父加载器(ExtensionClassLoader)是否已经加载过了。如果没有加载过,那么就调用ExtensionClassLoader来进行加载。
第三步:ExtensionClassLoader也会检查一下,它的父加载器(BootStarpClassLoader),是否加载过。如果没有,那么就调用最高的父加载器(BootStarpClassLoader)来进行加载。
然后查找标准库的目录:Java.lang.String,并且完成Java.lang.String的加载。
自定义的Test类是怎加加载的
自定义的Test类,也会经过上述
由ApplicationClassLoader==>ExtensionClassLoader==>BootStrapClassLoader的三个加载过程。
但是,由于BootStrapClassLoader负责的目录是标准库的目录,那么肯定找不到Test类,于是回到下一级的目录:ExtensionClassLoader进行加载。同样,也找不到Test类。最后,回到ApplicationClassLoader负责的目录,也就是当前项目的目录进行加载,最终找到了Test类,进行加载。
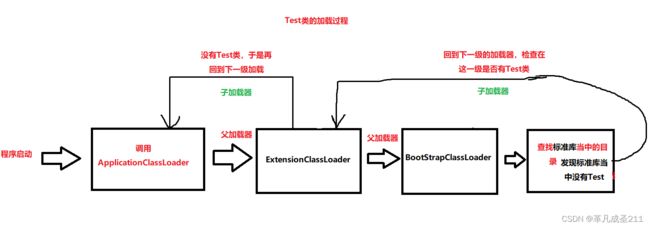
如果在最后的阶段,也没有找到Test类,那么就会抛出一个异常:ClassNotFoundException
双亲委派模型的好处
当用户自定义的类如果和派生类/标准库当中的类如果全限定名(类名称+包名称)重复了,仍然可以准确地加载标准库当中的类,而不是加载用户自定义的类 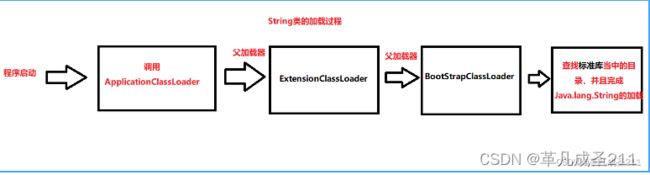
在上述过程当中,如果查找到标准库当中有Java.lang.String这个类,就不会再回去加载了。
此处,我自定义一个类(java.lang.String)
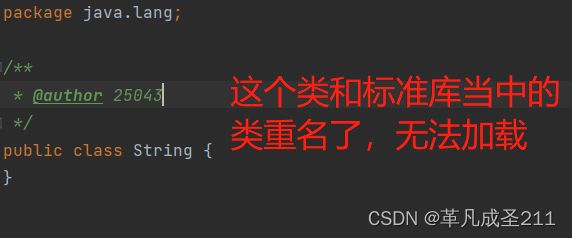
但是,如果在其他的地方进行new,发现new的是标准库当中的类。 
类加载一定要双亲委派模型吗
不一定,双亲委派模型只是JVM内部实现的一个类加载机制。
例如Tomcat加载webapps当中的类就没有使用双亲委派模型。
为什么Tomcat不使用默认的JVM内置的类加载器
我们都知道,Tomcat的一个webapps目录下面一般可以部署多个Web应用程序。
原因1:隔离性:为了保证每一个的应用程序之间是相互隔离的,以便不同的Web应用程序可以独立地加载和销毁类,不会因为不同的web应用程序因为重名/版本等原因而造成冲突。
原因2:方便动态重新加载已经加载过的类,使得开发和部署效率更高。
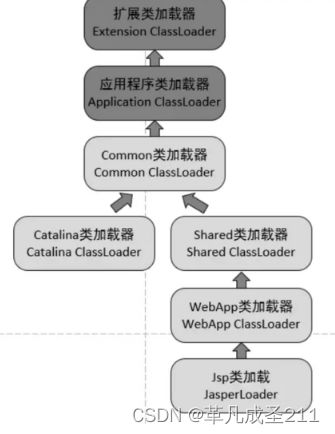
Tomcat是怎样隔离各个webapps目录的?
在上图当中,tomcat自定义了一个类加载器Webapp类加载器,并且给每一个Web应用程序都创建一个类加载器。那么也就意味着不同的类加载器加载的就是不同的类了。