Java开发编码规范
注:部分规范参考阿里巴巴代码规范,checkstyle等
目录
注:部分规范参考阿里巴巴代码规范,checkstyle等
1.命名风格
2.代码格式
3.代码注释
4.代码设计规范
5.异常的捕获
6.异常的优化
7.异常的避免
8.日志输入规范
logback日志级别
日志级别
级别等级
总结
1.命名风格
1. 【强制】代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。
反例:_name / __name / $Object / name_ / name$ / Object$2. 【强制】代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。
说明:正确的英文拼写和语法可以让阅读者易于理解,避免歧义。注意,即使纯拼音命名方式
也要避免采用。
正例:alibaba / taobao / youku / hangzhou 等国际通用的名称,可视同英文。
反例:DaZhePromotion [打折] / getPingfenByName() [评分] / int 某变量 = 33. 【强制】类名使用 UpperCamelCase 风格,必须遵从驼峰形式,但以下情形例外:DO / BO /
DTO / VO / AO
正例:MarcoPolo / UserDO / XmlService / TcpUdpDeal / TaPromotion
反例:macroPolo / UserDo / XMLService / TCPUDPDeal / TAPromotion4. 【强制】方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格,必须遵从
驼峰形式。严禁使用拼音与英文混合的方式类名使用。
正例: localValue / getHttpMessage() / inputUserId5. 【强制】常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例:MAX_STOCK_COUNT
反例:MAX_COUNT6. 【强制】抽象类命名使用 Abstract 或 Base 开头;异常类命名使用 Exception 结尾;测试类
命名以它要测试的类的名称开始,以 Test 结尾。
7. 【强制】中括号是数组类型的一部分,数组定义如下:String[] args;
反例:使用 String args[]的方式来定义。
8. 【强制】POJO 类中布尔类型的变量,都不要加 is,否则部分框架解析会引起序列化错误。
反例:定义为基本数据类型 Boolean isDeleted;的属性,它的方法也是 isDeleted(),RPC
框架在反向解析的时候,“以为”对应的属性名称是 deleted,导致属性获取不到,进而抛出异
常。9. 【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用
单数形式,但是类名如果有复数含义,类名可以使用复数形式。文件夹命名 以26个字母小写命名,少用数字和中文或拼音,禁止使用特殊符号.避免文件夹中有空格和大写字母或大小写混用的情况(在linux和window中对于大小写和部分程序对于空格的处理会出现找不到目录的情况)
正例: 应用工具类包名为 com.alibaba.open.util、类名为 MessageUtils(此规则参考
spring 的框架结构)
10. 【强制】杜绝完全不规范的缩写,避免望文不知义。对于无法容易歧义的命名应该加以注释辅助说明
反例:AbstractClass“缩写”命名成 AbsClass;condition“缩写”命名成 condi,此类随
意缩写严重降低了代码的可阅读性。
11. 【推荐】为了达到代码自解释的目标,任何自定义编程元素在命名时,使用尽量完整的单词
组合来表达其意。
正例:从远程仓库拉取代码的类命名为 PullCodeFromRemoteRepository。
反例:变量 int a; 的随意命名方式。
12. 【推荐】如果模块、接口、类、方法使用了设计模式,在命名时体现出具体模式。
说明:将设计模式体现在名字中,有利于阅读者快速理解架构设计理念。
正例:public class OrderFactory;
public class LoginProxy;
public class ResourceObserver;
13. 【推荐】接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁
性,并加上有效的 Javadoc 注释。尽量不要在接口里定义变量,如果一定要定义变量,肯定是
与接口方法相关,并且是整个应用的基础常量。
正例:接口方法签名:void f();
接口基础常量表示:String COMPANY = "alibaba";
反例:接口方法定义:public abstract void f();
说明:JDK8 中接口允许有默认实现,那么这个 default 方法,是对所有实现类都有价值的默
认实现。
14. 接口和实现类的命名有两套规则:
1)【强制】对于 Service 和 DAO 类,基于 SOA 的理念,暴露出来的服务一定是接口,内部
的实现类用 Impl 的后缀与接口区别。
正例:CacheServiceImpl 实现 CacheService 接口。
2)【推荐】如果是形容能力的接口名称,取对应的形容词做接口名(通常是–able 的形式)。
正例:AbstractTranslator 实现 Translatable。阿里巴巴 Java 开发手册
15. 【参考】枚举类名建议带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。
说明:枚举其实就是特殊的常量类,且构造方法被默认强制是私有。
正例:枚举名字为 ProcessStatusEnum 的成员名称:SUCCESS / UNKOWN_REASON。
16. 【参考】各层命名规约:
A) Service/DAO 层方法命名规约
1) 获取单个对象的方法用 get 做前缀。//例如getUserInfoByMobile,getByUserId
2) 获取多个对象的方法用 list/findList/findXXXList 做前缀。
3) 获取统计值的方法用 count 做前缀。
4) 插入的方法用 save/insert/add 做前缀。
5) 删除的方法用 remove/delete 做前缀。
6) 修改的方法用 update/modify 做前缀。
7) 分页查询的方法建议带有page关键字,例如pageXXX/findPage。
8) 批量操作的接口应该带有batch关键字命名方法,例如batchInsertXXX,batchUpdateXXX。
9) 检查数据是否存在的方法用check/exist,isExist做前缀。
10) 修改的方法用 update 做前缀。
11)带条件的查询方法,如果字段较少,建议方法中带有字段名,以by关键字连接,byXXX,例如getUserInfoById(long id),getUserInfoByMobile(String mobile),两个字段时,可以使用And连接,byXXXAndXXX,例如getUserInfoByNameAndAge(String name),三个以上字段时,建议使用bean对象作为入参,建议使用ByParam,ByCondition关键字,例如findUserInfoListByParam
12).条件查询的方法也可以使用queryXXX,searchXX来定义方法名
B) 领域模型命名规约
1) 数据对象:xxxDO,xxx 即为数据表名。
2) 数据传输对象:xxxDTO,xxx 为业务领域相关的名称。
3) 展示对象:xxxVO,xxx 一般为网页名称。
4) POJO 是 DO/DTO/BO/VO 的统称,禁止命名成 xxxPOJO。
17.【推荐】常用包命名规则
(1) 业务模块使用modules下以模块名命名
(2) 公共类目录common
(3) 服务类目录service
(4) 实体类目录entity或domain
(5) ORM交互类dao或者mapper
(6) 工具类utils,
(7) 切面类aop或aspect
(8) 常量类const或constant
(9) 配置类config或configuration
18.声明规范
(1)一行声明一个变量。
(2)不要将不同类型变量的声明放在同一行。
(3)只在代码块的开始处声明变量。
(4)所有的变量必须在声明时初始化。
(5)避免声明的局部变量覆盖上一级声明的变量。
(6)方法与方法之间以空行分隔。
19. POJO类中,尽量避免使用基本类型定义变量,因为基本类型有默认值,应是否其对应的封装类来定义入参
例如 将一个接口接口文档提供给第三方,因为某个字段没有传值,而且代码中带有默认值,导致接口能调的通,而且有结果,当某个条件下刚好这个默认值导致了结果不匹配,而且再调试接口没有及时发现这个问题,从而导致了bug
20.【强制】除了循环体的变量外,禁止使用a,b,c,a1,a2等来表示参数和有意义的变量
21.【强制】不允许任何魔法值(即未经定义的常量)直接出现在代码中。
反例:String key = "Id#taobao_" + tradeId;
cache.put(key, value);
2. 【强制】long 或者 Long 初始赋值时,使用大写的 L,不能是小写的 l,小写容易跟数字 1 混
淆,造成误解。
说明:Long a = 2l; 写的是数字的 21,还是 Long 型的 2?
3. 【推荐】不要使用一个常量类维护所有常量,按常量功能进行归类,分开维护。
说明:大而全的常量类,非得使用查找功能才能定位到修改的常量,不利于理解和维护。
正例:缓存相关常量放在类 CacheConsts 下;系统配置相关常量放在类 ConfigConsts 下。
4. 【推荐】常量的复用层次有五层:跨应用共享常量、应用内共享常量、子工程内共享常量、包
内共享常量、类内共享常量。
1) 跨应用共享常量:放置在二方库中,通常是 client.jar 中的 constant 目录下。
2) 应用内共享常量:放置在一方库中,通常是 modules 中的 constant 目录下。
反例:易懂变量也要统一定义成应用内共享常量,两位攻城师在两个类中分别定义了表示
“是”的变量:
类 A 中:public static final String YES = "yes";
类 B 中:public static final String YES = "y";
A.YES.equals(B.YES),预期是 true,但实际返回为 false,导致线上问题。
3) 子工程内部共享常量:即在当前子工程的 constant 目录下。
4) 包内共享常量:即在当前包下单独的 constant 目录下。
5) 类内共享常量:直接在类内部 private static final 定义。
5. 【推荐】如果变量值仅在一个范围内变化,且带有名称之外的延伸属性,定义为枚举类。下面
正例中的数字就是延伸信息,表示星期几。
public Enum {
MONDAY(1),
TUESDAY(2),
WEDNESDAY(3),
THURSDAY(4),
FRIDAY(5),
SATURDAY(6),
SUNDAY(7);
}2.代码格式
1.【推荐】要注意代码前后空格和tab缩进,编写的代码要格式化处理,idea使用Ctrl+Alt+L格式化,单行字符数限制不超过 120 个,超出需要换行
2.【强制】if/else/for/while/do 语句中必须使用大括号。即使只有一行代码,避免采用单行的编码方式:if (condition) satements;
3.【强制】没有特殊要求,新建文件或类都使用UTF-8格式
4.【强制】所有的覆写方法,必须加@Override 注解。
因为0和O比较相似,如果不使用Override,对于继承类重写父方法时,如果写错了单词,则重写不生效,例如父方法中getUserInfo,子类重写写错为getUserInf0时,就会无法重写父类的方法
5.【强制】出入参尽量避免使用map和Object作为出入参数.尽量使用POJO类作为出入参
6.【强制】禁止使用==来比较引用类型,对应集合类要使用ConllectUtils.isEmpty类判断空,字符串类使用StringUtils.isBlank类判断空,引用类型equal比较时,有可能出现空值的放在equal中,空对象没有equal方法
7.【强制】避免条件判断中使用复杂的表达式,对于比较条件还可以根据匹配度类调整比较条件的位置
8.方法的代码长度过长,再idea中可以选中部门代码,右键>refactor>extract Method分离出来
9.【推荐】要控制一个类的圈复杂度,尽量不要超过20.
检查代码圈复杂度 可以减少判断语句和提出方法来减少圈复杂度
增加圈复杂度的语句:在代码中的表现形式:在一段代码中含有很多的 if / else 语句或者其他的判定语句(if / else , switch / case , for , while , | | , ? , …)
see https://blog.csdn.net/u010684134/article/details/94410027
通常使用的计算公式是V(G) = e – n + 2 , e 代表在控制流图中的边的数量(对应代码中顺序结构的部分),n 代表在控制流图中的节点数量,包括起点和终点(1、所有终点只计算一次,即便有多个return或者throw;2、节点对应代码中的分支语句)
圈复杂度 V(G)与代码质量的关系如下:
V(G) ∈ [ 0 , 10 ]:代码质量不错;
V(G) ∈ [ 11 , 15 ]:可能存在需要拆分的代码,应当尽可能想措施重构;
V(G) ∈ [ 16 , ∞ ):必须进行重构;
10.【推荐】import引入其他类,除了java内置的包之外,尽量不要使用import *引用(加快编译速度和避免命名冲突)
11.【强制】不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator方式,如果并发操作,需要对 Iterator 对象加锁
12.【推荐】对于比较耗时的数据,如果不需要获取返回值等,应优先考虑异步线程或线程池处理
13【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
14.【推荐】方法中避免使用超过3个return类结束方法,循环语句中禁止嵌套循环3个即以上
15.【推荐】如果一个变量获取的值在一个方法中多次使用,应定义一个变量来接受处理,避免多次使用get方法来获取值,例如user.getUserId();
16.【推荐】变量的定义尽量采用懒加载的策略,即在需要的时候才创建
局部变量的定义和初始化要考虑使用的位置来调整,避免产生过多的垃圾对象,例如在if(y==1)的时候才用到这个变量,应该在判断条件内部定义,不应该在if外部定义例如:
String str = "aaa"; if (i == 1) { list.add(str); }
建议替换为:
if (i == 1)
{
String str = "aaa";
list.add(str);
}
17.【强制】禁止在代码上写死一些外部请求的域名接口和密钥之类的值,应该用配置文件,使用spring @value等方式注入
18.对于重复率较高的代码应提取为公共类或公共方法类使用,降低代码的耦合度
19.【强制】接口类避免使用多余修饰符
接口中的变量和注解默认就是public、static、final的,因此,这些修饰符也是多余的。
因为注解是接口的一种形式,所以它们的字段默认也是public、static、final的,正如它们的注解字段默认是public和abstract的。
定义为final的类是不能被继承的,因此,final类的方法的final修饰符也是多余的。
20.【推荐】代码中应注意变量和方法等的定义顺序
根据Java语言的代码约定,类或接口声明部分按照指定顺序出现。
1. 类(静态)变量。首先是public类变量,然后是protected,然后是package level(没有修饰符)最后是private。
2. 实例变量。首先是public类的变量,然后是protected,然后是package level(没有修饰符)最后是private。
3. 构造方法。
3.代码注释
1.对于类的注释要携带author,创建时间和作用描述,例如
/**
* @program: XXX项目
* @description: 过滤拦截器
* @author: moodincode
* @create: 2020/8/28
**/
public class XXX
2.对于方法的注释要方法描述,参数说明,返回值说明,异常说明,如果返回的对象出现空值的情况要说明,list返回时要说明是否返回null还是size=0的空对象,防止其他调用者调用时出现空指针异常
/**
* 加密数据 RSA
* @param text 要加密的文本
* @param defaultValue 加密失败默认返回的文本,可以为null
* @return 加密后的字符串 base64格式
*/
public static String encryptByRSA(String text, String defaultValue) {
....
}
3.类的变量使用多行注释,方法中变量的注释使用单行或多行注释,避免使用行尾注释
4.已废弃的方法或类要加@Deprecated注释标识,如果要新的代替方法要使用@link或@see注释来指明替代的方法
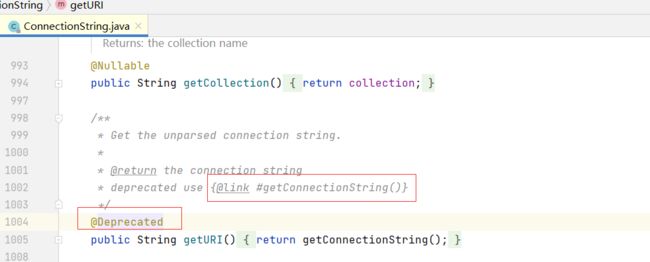
5.对于使用枚举类来表示业务代码的字段,应使用@link或@see来指明对于的枚举类的位置
6.要及时清理注释掉的方法避免影响代码的可读性
7.对于有特殊意义的逻辑判断要写注释并且描述判断逻辑的业务,增加代码的可读性
8.在方法中调用别的方法也要写注释,除了getById,findPage等可以很容易阅读的方法之外
9.注释要简洁明了,可阅读性高,不能使用拼音或者半吊子的英文
10. 对于特殊业务逻辑的复杂判断条件,增加对应的注释辅助说明情况,以免产生歧义
4.代码设计规范
1.【推荐】对于list,set,map的初始化时要制定容量大小。
2.【推荐】对于多线程共享的变量要考虑线程安全性
3.【推荐】对于比较耗时的任务应使用线程池或消息队列等方式异步处理
4.【推荐】对于多线程操作的字段或者数据库值例如订单状态等,要使用加锁或者利用CAS原则处理
5.【强制】对于DAO层和数据库的交互,避免写死的字段名的魔法值
例如mybatis plus的QueryWrapper查询,不应该写死query.eq("name","张三""),应该改用
LambdaQueryWrapper构建器或者使用lambda方法使用,例如 query.lambda().eq(UserVO::getName,"张三")
6.【强制】service层只能调用其他service,不能直接调用其他模块或其他业务的DAO层或Mapper接口.
接口设计必须保持接口的隔离原则,其他service层,直接操作其他DAO层的insert,deleted等方法或者直接调用其他mapper的增删改查方法,会导致逻辑混乱,无法统一管理insert等方法的权限控制,比如后期增加一个拦截insert的方法,新增校验重复等操作时,发现其他方法直接调用数据库的SQL,则无法做到统一管理
7.【推荐】方法的入参,出参在明确的结构时,应该定义java对象来作为入参或出参,禁止使用map,Object,JsonObject,String代表JSON字符串等无法推断类型和字段名的参数的对象
1).使用map
2)使用这些万能的入参,可能导致内存泄露.比如requestBody中使用了Map
8.使用mybatis plus单表查询尽量是否queryWapper构建器查询,相同的查询不要编写过多的SQL语句到mapper.xml中
表结构改动时,我们习惯使用代码生成器重新生成代码替换,mapper.xml可能被覆盖
9.禁止在DAO层的方法从request或session中获取登录对象,service层如果是前后端共用的方法或者是可能使用异步线程使用的方法,不可以在此类方法中通过request或session获取登录对象,尽量使用controller获取到登录对象,除非使用request作为参数传入的限制作用域的方法
1)request对象在异步线程无法生效
2)在前后端使用的登录对象不一致时,service获取登录对象,后端人写死为获取后端登录对象,前端的接口调用了这个方法将导致异常.,使用明确的登录对象作为参数,则调用方可以提前规避这个风险,例如调整参数或获取对象的方法,转换为统一的登录对象作为入参
10.【推荐】方法入参参中的泛型返回值在明确T的类型是必须指定T的对象
1) 返回值没有指定T,会导致不明确T的具体对象 例如List findUserList();应该改为List
2)不知道泛型具体对象,在其他方法需要解析时会造成不必要的强制转换 操作
3)对于controller返回参数中,没有指定泛型对象,swagger等文档无法生成完整的返回参数
例如
public Result getUserInfo(){
}
应该改为
public Result
}
11.【推荐】尽量减少对变量的重复计算
明确一个概念,对方法的调用,即使方法中只有一句语句,也是有消耗的,包括创建栈帧、调用方法时保护现场、调用方法完毕时恢复现场等。所以例如下面的操作:
for (int i = 0; i < list.size(); i++){
...
}
//建议替换为:
for (int i = 0, length = list.size(); i < length; i++){
...
}这样,在list.size()很大的时候,就减少了很多的消耗,其他的例如在循环里面调用循环外的对象获取某个值也应该定义变量来处理
12.【推荐】频繁调用 Collection.contains 方法请使用 Set
在 java 集合类库中,List 的 contains 方法普遍时间复杂度是 O ( n ) ,如果在代码中需要频繁调用 contains 方法查找数据,可以先将 list 转换成 HashSet 实现,将 O ( n ) 的时间复杂度降为 O ( 1 ) 。
13. 【推荐】工具类应该屏蔽构造函数
工具类是一堆静态字段和函数的集合,不应该被实例化。但是,Java 为每个没有明确定义构造函数的类添加了一个隐式公有构造函数。所以,为了避免 java "小白"使用有误,应该显式定义私有构造函数来屏蔽这个隐式公有构造函数。
public class MathUtils {
public static final double PI = 3.1415926D;
private MathUtils() {}
public static int sum(int a, int b) {
return a + b;
}
}14.【推荐】String.split(String regex)方法的注意事项和String.format中包含正常%的问题
反例:
"a.ab.abc".split("."); // 结果为[]
"a|ab|abc".split("|"); // 结果为["a", "|", "a", "b", "|", "a", "b", "c"]
正例:
"a.ab.abc".split("\\."); // 结果为["a", "ab", "abc"]
"a|ab|abc".split("\\|"); // 结果为["a", "ab", "abc"]在String.format内容中如果包含正常的%,例如 html标签中style='height:100%',则在使用String.format时会抛出异常,应该改为双百分号,%%才正常输出单个%
15.【推荐】Controller,Service,Dao/Mapper的方法代码编写要符合设计规范,只能完成各自规定边界上的功能处理,不能胡乱混用
1.controller层作为视图交互的入口职责.可以用来校验用户登录对象,验证权限,校验参数格式,封装返回值等简单的操作,禁止编写业务操作的逻辑
2.禁止controller层直接调用DAO/Mapper层的接口,更不能编写一些建立数据库连接等属于其他模块负责的方法.
3.禁止controller层的被指定为@requestMapping的方法被其他方法调用,私有的方法只能被同一个controller中的方法调用,禁止将controller的方法给其他controller或其他service/dao等接口调用
4.service层负责业务逻辑的处理,不能直接编写建立数据库连接等的方法,不能调用controller层的代码,不同业务的service应该按 业务边界拆分设计,避免在一个service的方法中处理其他业务边界逻辑的业务代码
5.dao层作为和数据交互的层,只能负责操作数据库,禁止编写业务方法,禁止在dao成调用其他的Dao/service/controller或第三方接口等接口和方法,参数的校验等应该在调用之前校验完毕再传入,避免在dao层抛出和SQL无关的异常,例如数据不存在应该返回null,例如一个调用方需要抛出异常,一个调用方不需要抛出异常,如果直接抛出异常,则不需要抛出异常的调用方不得不加try...catch来兼容或者不得不编写一个相似的方法
6.dao层入参的组装必须在调用前进行处理,禁止在dao上编写一大堆为入参赋值的方法,必填的参数要在调用的方法中注明,防止空指针异常
7.DAO的方法设计保持通用性,非通用性的方法必须注明功能并且重写一个新的方法,防止被其他人引用导致出错.禁止更改原有通用的接口变更为不通用的方法,例如save方法,例如加入了一些权限校验,判断数据库是否存在相同的值等等的操作
16.【强制】方法的拆分避免不合理的拆分,拆分必须符合设计理念,操作相同业务属性的调用必须保持在同一个方法内
反例1:
一个组装机器人的方法,方法内调用获取头的方法,调用获取身体的方法,然而获取腿部的方法却在编写在调用其他方法中,甚至是方法嵌套方法再嵌套的方法中
反例2:
一个通过ThreadLocal缓存的变量,推送到mq的例子,调用为ThreadLocal赋值的方法和触发推送到mq的方法不在同一个方法内,被编写散落到各种不同的service上,通过find use查找发现这个方法被很多service调用,只能从这个触发mq的方法内查找所有的被调用的service方法,一层一层的排查才找到在那里为这个触发mq所用到的theadLocal调用的位置,不符合设计理念,增加了出现问题时的排查困难
17.【强制】对于用户上传文件的存储,必须按分类归档,上传的文件的记录必须记录到数据库或其他存储,保证有根可循,防止产生过多的垃圾数据无法根据索引或分类删除,尤其是不需要登录状态的上传的数据.
反例:某某文件服务器因为内存沾满,由于项目没有建立数据库来保存文件信息,导致后期删除掉某些文件时无从下手,不知道哪些数据是有用的,哪些是无用的数据
18.【推荐】对于mvc的项目,入参避免直接使用request对象获取参数(cookie和请求头参数除外),返回参数避免使用使用response对象输出结果(文件下载除外)
不规范的获取参数和设置返回参数不利于代码阅读,并且容易导致其他接手人员得知参数的类型,参数的格式,也不利于swagger文档生成器输出接口文档
5.异常的捕获
1.异常分运行时异常和一般异常,受检查异常(checked exception):在编译时被强制检查的异常,在方法的声明中声明的异常.运行时异常(RuntimeException):不受检查的异常通常是编码中可以避免的逻辑错误.根据需求来判断如何处理, 不需要编译期强制处理(try catch或往外层抛出)
常见的运行时异常
例如 IndexOutOfBoundsException(下标越界异常),IllegalArgumentException(不合逻辑异常),
NumberFormatException(数字转换异常),
NullPointerException(空指针异常),ClassCastException(类转换异常),
NegativeArraySizeException(数组大小为负数异常)
SecurityException(安全异常),BufferOverFlowException(缓冲区溢出异常)
2.异常的声明要使用明确的类型,不能直接使用Throw或Exception大范围的类
3.不应该大范围的try catch异常
4.不能生吞异常,捕获的异常必须添加日志或者及时处理,不能try catch后不作任何输出
5.禁止使用 e.printStackTrace();打印异常
6.有 try 块放到了事务代码中,catch 异常后,如果需要回滚事务,一定要注意手动回
滚事务
7.finally 块必须对资源对象、流对象进行关闭,有异常也要做 try-catch。说明:如果 JDK7 及以上,可以使用 try-with-resources 方式。
8.对于可能产生运行时异常的方法,应该在方法注释中备注可能产生的运行时异常的说明
例如一个根据mobile获取数据库一条数据的接口,查不到数据返回异常,而有些地方也用到这个接口,以为查不到数据返回的是空,从而在调用方只判断是否为空,为空插入数据,而此接口返回了异常,导致处理逻辑出现偏差.
6.异常的优化
1:慎用异常
异常对性能不利。抛出异常首先要创建一个新的对象,Throwable接口的构造函数调用名为 fillInStackTrace()的本地同步方法,fillInStackTrace()方法检查堆栈,收集调用跟踪信息。只要有异常被抛出,Java虚拟机就必须调整调用堆栈,因为在处理过程中创建了一个新的对象。异常只能用于错误处理,不应该用来控制程序流程。e.PrintStackTrace(),我们可以查看该对象缓存了异常时前的很多方法栈
2.减少异常的范围
try...catch... 会产生额外的性能开销,降低JVM对代码的优化,所以在使用过程中尽量只捕获必要的代码段, 而不是使用特别大的try catch包含大范围的代码.
3.尽量是否条件判断(if或switch)来替代抛出异常
我们要减少用异常来控制流程代码,比如用户登录的使用,用户不存在 用户名错误,密码不正确等,我们可以返回空,或一个类型或字段来标识几种情况,而不是通过抛出错误的方式来控制流程. 在实际使用过程中,使用if else,switch来控制流程比抛出异常快一些
4.非特殊情况处理下,禁止在循环中使用try..catch...应该把其放在最外层
7.异常的避免
1.对于集合类,不能直接使用isEmpty判断,字符串类null值和空字符串的考虑
2.对于对象中的对象的取值判断,应使用optional类来处理,避免编写过多嵌套的if判断
3.对于远程调用的接口,要处理接口调用失败情况导致的异常和返回数据格式的异常,例如期望返回json格式,被网关拦截或者ngix出问题返回了页面文件
4.流程控制语句要避免死循环,边界值的处理问题
5.注意Integer类型的值映射string类型的问题,避免java.lang.Integer cannot be cast to java.lang.String
6.对于泛型的List,Map等需要注意类型类型强转后,尤其是泛型中参数类型是否匹配的问题,典型的是java.lang.Integer cannot be cast to java.lang.String错误
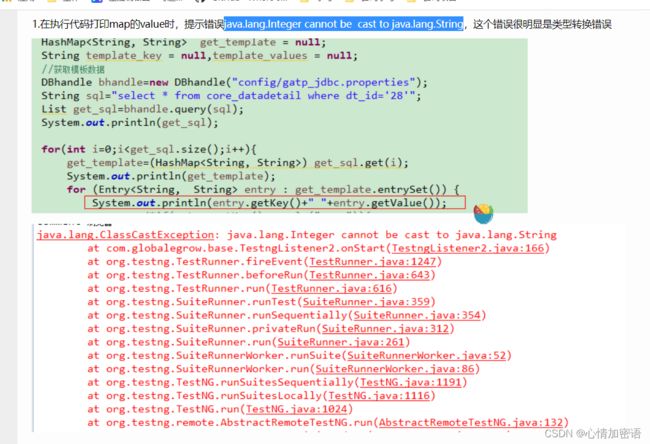

参考链接:https://www.cnblogs.com/chongyou/p/9052834.html
7.【注意】引用sdk中的方法,要注意以下几点:
1).需要注意入参是否允许为空的情况,尤其是参数中不包含@nullable注解的字段
例如 String.replace(),来替换url的参数,被替换值为空的情况会出现报错
2).注意引用的方法中是否有运行时异常,结合自身场景进行选择正确的处理方式,通常在使用类的注释中都会抛出异常的说明
3).注意调用他们的方法入参的值条件限制
例如String.replaceAll()和String.replace()的区别,前者接收的是正则表达式,如果替换的值里面包含特殊字符,会造成正则表达式格式错误等情况而抛出的异常,尤其是发送包含特殊符号的密码给客户手机,使用replaceAll替换短信模板的情况
4)注意spring.split()使用竖线分割的切割.参数接收的是正则表达式,写成"|"将造成分割为每个字符,正确应该使用"\\|",string.split("\\|"))
8.日志输入规范
logback日志级别
logback有5种级别,分别是TRACE < DEBUG < INFO < WARN < ERROR,定义于ch.qos.logback.classic.Level类中。
日志级别
Trace:是追踪,就是程序推进以下,你就可以写个trace输出,所以trace应该会特别多,不过没关系,我们可以设置最低日志级别不让他输出.
Debug:指出细粒度信息事件对调试应用程序是非常有帮助的.
Info:消息在粗粒度级别上突出强调应用程序的运行过程.
Warn:输出警告及warn以下级别的日志.
Error:输出错误信息日志.
此外OFF表示关闭全部日志,ALL表示开启全部日志。
级别等级
等级从低到高分别是TRACE < DEBUG < INFO < WARN < ERROR
总结
1. 如果logger没有被分配级别,name它将从有被分配级别的最近的父类那里继承级别,root logger默认级别是DEBUG。
2. 日志输出的时候,级别大的会输出,根据当前ROOT 级别,日志输出时,级别高于root默认的级别时会输出,比如如果root的级别是info,那么会输出info以及info级别以上的日志。
1.建议在调用第三方接口出入参都加日志,容易出现问题的地方要增加日志
2.日志要添加业务描述关键字,能够快速的定位的问题
3.日志输出,必须使用条件输出形式或者使用占位符的方式。禁止使用字符串拼接方式打印异常
log.info("这个一个占位符的日志,id={},name={}",id,name);
4.日志输出要考虑输出字段的空指针异常情况
例如log.info("打印用户名,userName={}",user.getUserName());要注意user对象是否为空
5.错误日志输出,对于不易排查问题的方法应该打印异常对象
log.error("这里出现错误,内容为:{}",e.getMessage())//不会输出栈
log.error("这里出现错误,内容为:{}",e)//默认调用toString,不会打印栈
log.error("这里出现错误,错误信息:",e)//输出错误栈,注意打印e,e参数不能使用栈位符,实际调用void error(String var1, Throwable var2);的方法
log.error("这里出现错误,用户ID为:{},错误信息:",id,e)//可以输出错误栈6. 【强制】应用中不可直接使用日志系统(Log4j、Logback)中的 API,而应依赖使用日志框架
SLF4J 中的 API,使用门面模式的日志框架,有利于维护和各个类的日志处理方式统一。
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
private static final Logger logger = LoggerFactory.getLogger(Abc.class);7. 【强制】日志文件推荐至少保存 15 天,因为有些异常具备以“周”为频次发生的特点。
8. 【强制】应用中的扩展日志(如打点、临时监控、访问日志等)命名方式:
appName_logType_logName.log。logType:日志类型,推荐分类有
stats/desc/monitor/visit 等;logName:日志描述。这种命名的好处:通过文件名就可知
道日志文件属于什么应用,什么类型,什么目的,也有利于归类查找。
正例:mppserver 应用中单独监控时区转换异常,如:
mppserver_monitor_timeZoneConvert.log
说明:推荐对日志进行分类,如将错误日志和业务日志分开存放,便于开发人员查看,也便于
通过日志对系统进行及时监控。
9. 【强制】对 trace/debug/info 级别的日志输出,必须使用条件输出形式或者使用占位符的方
式。
说明:logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);
如果日志级别是 warn,上述日志不会打印,但是会执行字符串拼接操作,如果 symbol 是对象,
会执行 toString()方法,浪费了系统资源,执行了上述操作,最终日志却没有打印。
正例:(条件)
if (logger.isDebugEnabled()) {
logger.debug("Processing trade with id: " + id + " and symbol: " + symbol);
}
正例:(占位符)
logger.debug("Processing trade with id: {} and symbol : {} ", id, symbol);10. 【强制】避免重复打印日志,浪费磁盘空间,务必在 log4j.xml 中设置 additivity=false。
正例:11. 【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过
关键字 throws 往上抛出。
正例:logger.error(各类参数或者对象 toString + "_" + e.getMessage(), e);12. 【推荐】谨慎地记录日志。生产环境禁止输出 debug 日志;有选择地输出 info 日志;如果使
用 warn 来记录刚上线时的业务行为信息,一定要注意日志输出量的问题,避免把服务器磁盘
撑爆,并记得及时删除这些观察日志。
说明:大量地输出无效日志,不利于系统性能提升,也不利于快速定位错误点。记录日志时请
思考:这些日志真的有人看吗?看到这条日志你能做什么?能不能给问题排查带来好处?
13. 【参考】可以使用 warn 日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适
从。注意日志输出的级别,error 级别只记录系统逻辑出错、异常等重要的错误信息。如非必
要,请不要在此场景打出 error 级别
14.【强制】必须正确的使用日志级别,对于关键的错误日志必须使用error级别输出,禁止正常的打印日志使用error级别输出,对于开发调试排查问题的日志使用debug输出,重要业务日志使用info