3.网络爬虫——Requests模块get请求与实战
Requests模块get请求与实战
-
- requests简介:
- 检查数据
- 请求数据
- 保存数据
前言: 前两章我们介绍了爬虫和HTML的组成,方便我们后续爬虫学习,今天就教大家怎么去爬取一个网站的源代码(后面学习中就能从源码中找到我们想要的数据)。
此专栏文章是专门针对Python零基础爬虫,欢迎免费订阅!
第一篇文章获得全站热搜第一,python领域热搜第一,欢迎阅读!
欢迎大家一起学习,一起成长!!

urllib模块:
urllib是python的内置HTTP请求库,包含4个模块
request: http的请求模块,传入UPL及额外的参数,就模拟发送请求
error 异常处理模块,确保程序不会意外终止
parse : 一个工具模块,提供了许多URL处理方法。
robotparser : 用来识别robots.txt文件,判断那些网站可以爬
pycharm外部库的urilib下:

requests简介:
requests是一个Python第三方库,用于发送HTTP请求。它提供了一种简单而优雅的方式来发送HTTP/1.1请求,并且可以自动处理连接池和重定向等问题。requests库可以在Python 2.7和Python 3中使用,支持HTTP和HTTPS请求,支持Cookie、代理、SSL证书验证等功能。
使用requests库可以方便地发送GET、POST、PUT、DELETE等请求,并且支持上传文件和发送JSON数据等操作。通过requests库,我们可以轻松地与Web服务进行交互,获取数据或提交数据。requests库已经成为Python中最常用的HTTP客户端库之一,被广泛应用于Web开发、数据分析、爬虫等领域。
安装requests库:
点击终端,输入pip install requests
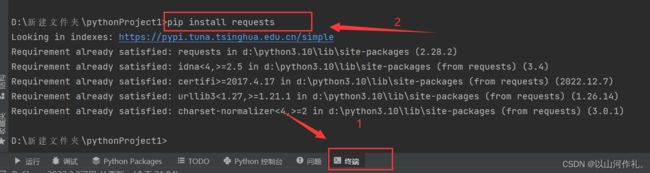
上面这就表示安装成功。
然后接下来安装requests镜像源:
如图所示,在终端输入代码,出现下面情况就代表安装完成。

检查数据
检查数据是否在链接里
1.数据不在链接中:
打开网页,右键点击检查,然后点击网络,刷新,接着选择第一个文档,点击预览,这个时候我们发现,左边的照片或者其他信息不在预览里面,这个时候我们就无法获得想要的数据了。这种数据就属于客户端渲染,
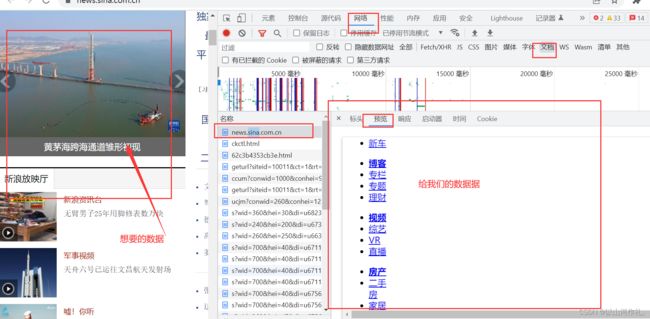
2.数据在链接中:
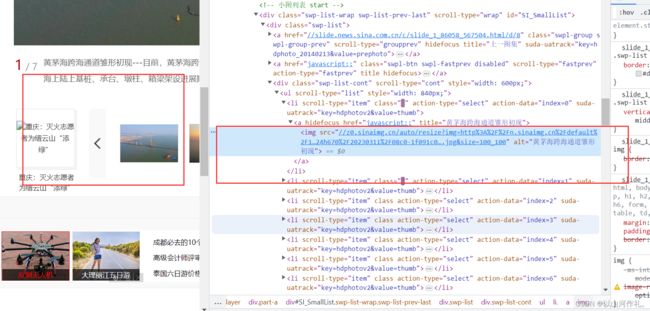
打开网页,点击右键,点击检查,然后点击左上角的小箭头,移动到左边我们需要的数据上面,如果右边代码中出现相应的代码,就说明数据就在代码中,接着我们就开始后面的操作,方便获取我们需要的数据。
请求数据
浏览器页面的网址一定是qet请求
举个栗子:(如何查看请求头,请求体,以及响应体,在第二节里面有详细介绍,此处以及后面就不在过多介绍,以免让文章太繁琐)
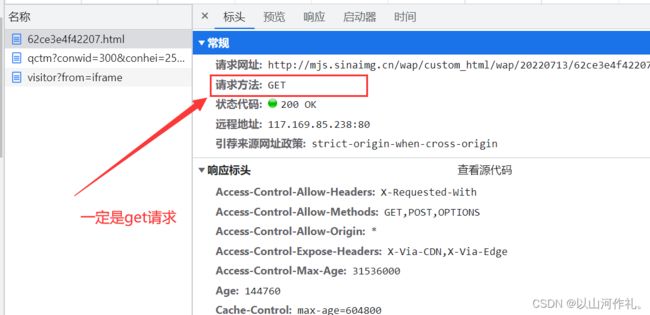
现在我们知道数据在链接中,我们就要通过链接去获取他:
import requests
url = 'http://slide.news.sina.com.cn' # 我们需要数据的链接(就是我们需要爬取的链接,因为数据就在链接里面)
# 确认请求,get请求
html = requests.get(url)
print(html.text) # 打印网页源代码
print(html.status_code) # 状态码
if html.status_code == 200:
print('数据访问成功')
else:
print('请求失败了')
这段代码使用了Python第三方库requests,发送了一个HTTP GET请求,并获取了HTTP响应的正文和状态码,并根据状态码判断请求是否成功。其中,url是一个字符串类型的参数,表示要发送HTTP请求的URL地址。
使用requests.get()函数发送HTTP GET请求,并将HTTP响应对象赋值给变量html。
使用text属性获取HTTP响应正文,并将其打印出来。此外,使用status_code属性获取HTTP响应状态码,并将其打印出来。
根据HTTP响应状态码判断请求是否成功,如果状态码为200,则表示请求成功,否则表示请求失败。(状态码详情可查阅第二节,html页面组成)

import requests
url = 'http://slide.news.sina.com.cn' # 我们需要数据的链接(就是我们需要爬取的链接,因为数据就在链接里面)
# 确认请求,get请求
html = requests.get(url)
print(html.text) # 打印网页源代码
print(html.status_code) # 状态码
if html.status_code == 200:
print('数据访问成功')
else:
print('请求失败了')
print(html.url) # 访问的网址
print(html.request.headers) # 输出请求头信息
使用url属性获取HTTP请求的URL地址,并将其打印出来。
然后,使用request.headers属性获取HTTP请求的请求头信息,并将其打印出来。request属性是HTTP响应对象的一个属性,表示该HTTP响应对象对应的HTTP请求对象。因此,html.request.headers表示HTTP请求的请求头信息。

在网页源代码中也能查看请求头,但是没有代码运行来的方便快捷。
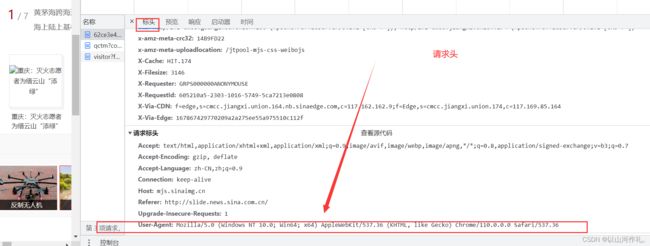
请求头的作用
请求头是HTTP协议中的一个重要部分,它包含了HTTP请求的一些元信息,比如请求方法、请求地址、协议版本、请求头、请求体等。请求头可以帮助服务器理解客户端发送的HTTP请求,以便正确处理HTTP请求。
请求头的作用主要有以下几点:
-
指定请求方法和请求地址:请求头中包含了HTTP请求的方法(GET、POST、PUT、DELETE等)和请求地址,告诉服务器要执行哪种操作。
-
指定请求体和请求参数:请求头中还可以包含请求体和请求参数,用于向服务器传递数据。
-
指定请求头信息:请求头中还包含了一些元信息,比如用户代理、Cookie、Referer等,用于告诉服务器一些附加信息,以便服务器做出更好的响应。
-
安全性:请求头中可以包含一些安全相关的信息,比如身份验证、防止跨站点请求伪造(CSRF)等。
请求头对爬虫来说,就好像一个面具,去模仿人去浏览网站,就不会被网站发现,也可以理解为打开网站的钥匙,上面我们知道,数据在链接中,但是我们申请后,返回状态码是418,请求失败,所有我们现在戴上面具,或者说,拿着钥匙再去申请,看看能不能成功打开。
import requests
import chardet
url = 'http://slide.news.sina.com.cn/c/slide_1_86058_567500.html#p=1'
headers = {
'User-Agent': 'python-requests/2.28.2',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive'
}
html = requests.get(url, headers=headers).content
encoding = chardet.detect(html)['encoding']
html = html.decode(encoding)
# 将网页内容写入文件中
with open('example.html', 'w', encoding='utf-8') as f:
f.write(html)
现在就好比我们成功的进入到别人家里面,然后我们将要拿数据,现在先看一下代码里面的东西。
运行成功后,我们大概看一下,数据较多,不做过多展示,截取部分内容:
接着我们在里搜索我们想要的数据,例如:
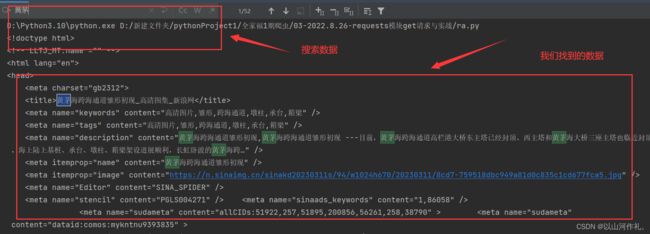
红色方框里面就是我们需要的东西,我们可以点击查看一下:

现在我们找到了我们需要的数据,因为我们还没有学会数据解析,暂时不能提取,无法精确的获取想要的东西,今天就不在这里讲解,后面章节会讲怎么精确的拿取我们想要的数据
保存数据
输入文件保存的代码:
import requests
import chardet
url = 'http://slide.news.sina.com.cn/c/slide_1_86058_567500.html#p=1'
headers = {
'User-Agent': 'python-requests/2.28.2',
'Accept-Encoding': 'gzip, deflate',
'Accept': '*/*',
'Connection': 'keep-alive'
}
html = requests.get(url, headers=headers).content
encoding = chardet.detect(html)['encoding']
html = html.decode(encoding)
print(html)
# 将网页内容写入文件中
with open('example.html', 'w', encoding='utf-8') as f:
f.write(html)
这段代码可以将
html变量中的网页内容写入到名为example.html的文件中。具体来说,open()函数用于打开文件,'w'参数表示以写入模式打开文件,encoding='utf-8'参数表示指定编码格式为 UTF-8。然后使用write()方法将网页内容写入文件中。with语句用于自动关闭文件。
需要注意的是,如果该文件不存在,则会自动创建该文件;如果该文件已经存在,则会覆盖原文件中的内容。如果要在已经存在的文件中追加内容,可以将
'w'参数改为'a'。
我们的文件就会保存到文件中(仅展示部分代码):
今天知识分享就到此结束,欲知后续如何,请听下回分析。

悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。