Hudi原理 | 一文彻底弄懂Apache Hudi不同表类型

1. 摘要
Apache Hudi提供了不同的表类型供根据不同的需求进行选择,提供了两种类型的表
•Copy On Write(COW)•Merge On Read(MOR)
2. 术语介绍
在深入研究 COW 和 MOR 之前,让我们先了解一下 Hudi 中使用的一些术语,以便更好地理解以下部分。
2.1 数据文件/基础文件
Hudi将数据以列存格式(Parquet/ORC)存放,称为数据文件/基础文件,该列出格式是非常高效的并在整个行业中广泛使用,数据文件和基本文件通常可以互换使用,但两者的含义相同。
2.2 增量日志文件
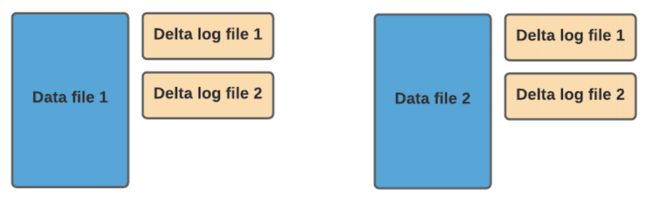
在 MOR 表格式中,更新被写入到增量日志文件中,该文件以 avro 格式存储。这些增量日志文件始终与基本文件相关联。假设有一个名为 data_file_1 的数据文件,对 data_file_1 中记录的任何更新都将写入到新的增量日志文件。在服务读取查询时,Hudi 将实时合并基础文件及其相应的增量日志文件中的记录。
2.3 文件组(FileGroup)
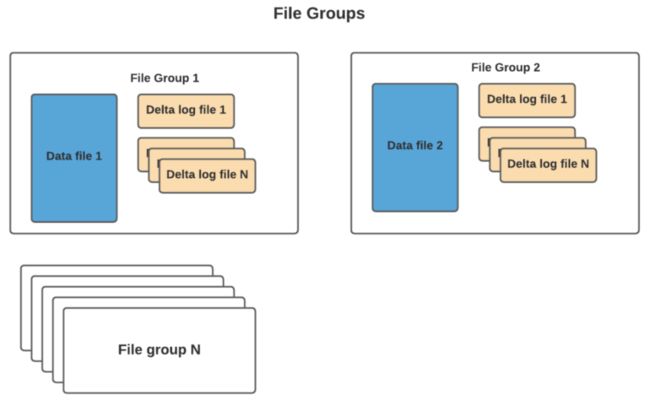
通常根据存储的数据量,可能会有很多数据文件。每个数据文件及其对应的增量日志文件形成一个文件组。在 COW 的情况下,它要简单得多,因为只有基本文件。
2.4 文件版本
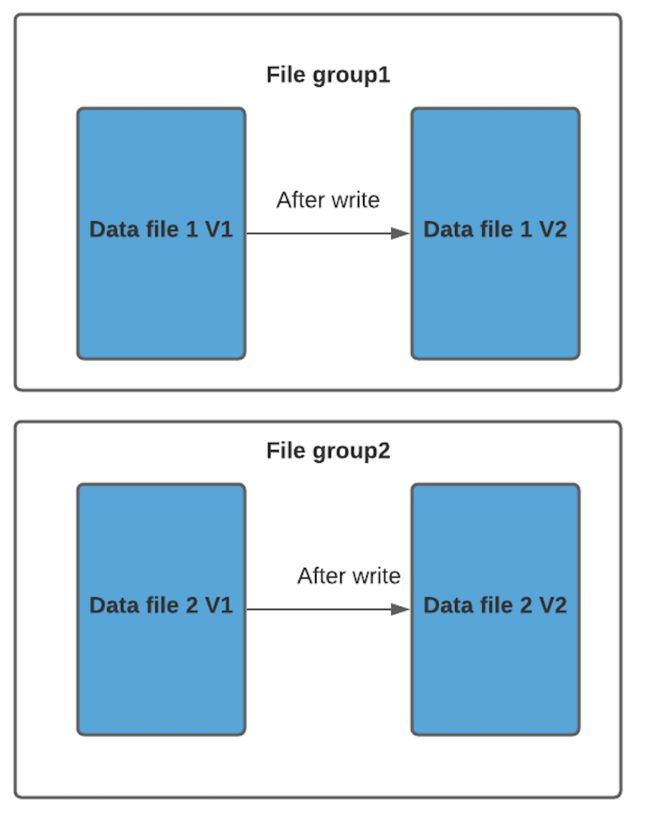
我们以 COW 格式表为例来解释文件版本。每当数据文件发生更新时,将创建数据文件的较新版本,其中包含来自较旧数据文件和较新传入记录的合并记录。
2.5 文件切片(FileSlice)
对于每个文件组,可能有不同的文件版本。因此文件切片由特定版本的数据文件及其增量日志文件组成。对于 COW,最新的文件切片是指所有文件组的最新数据/基础文件。对于 MOR,最新文件切片是指所有文件组的最新数据/基础文件及其关联的增量日志文件。
有了这些上下文,让我们看看 COW 和 MOR 表类型。
3. COW表
顾名思义,对 Hudi 的每一个新批次写入都将创建相应数据文件的新版本,新版本文件包括旧版本文件的记录以及来自传入批次的记录。接下来我们用一个示例进行说明。
假设我们有 3 个文件组,其中包含如下数据文件。
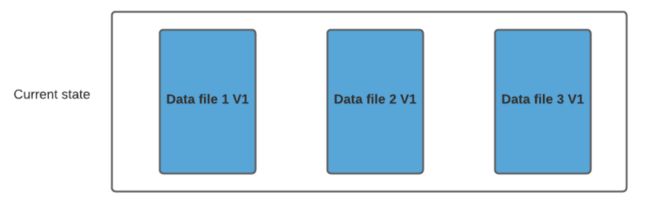
我们进行一批新的写入,在索引后,我们发现这些记录与File group 1 和File group 2 匹配,然后有新的插入,我们将为其创建一个新的文件组(File group 4)。
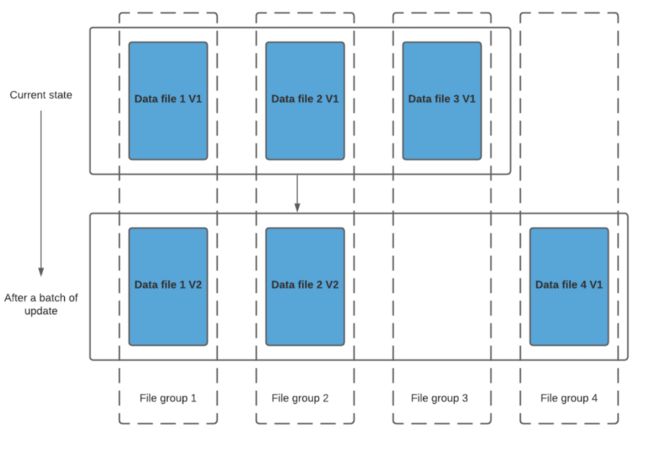
因此data_file1 和 data_file2 都将创建更新的版本,数据文件 1 V2 是数据文件 1 V1 的内容与数据文件 1 中传入批次匹配记录的记录合并。
由于在写入期间进行合并,COW 会产生一些写入延迟。但是COW 的优势在于它的简单性,不需要其他表服务(如压缩),也相对容易调试。
4. MOR表
顾名思义,合并成本从写入端转移到读取端。因此在写入期间我们不会合并或创建较新的数据文件版本。标记/索引完成后,对于具有要更新记录的现有数据文件,Hudi 创建增量日志文件并适当命名它们,以便它们都属于一个文件组。
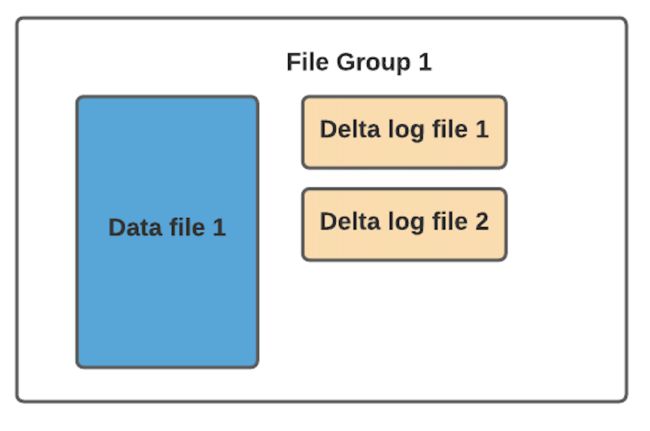
读取端将实时合并基本文件及其各自的增量日志文件。你可能会想到这种方式,每次的读取延迟都比较高(因为查询时进行合并),所 以 Hudi 使用压缩机制来将数据文件和日志文件合并在一起并创建更新版本的数据文件。
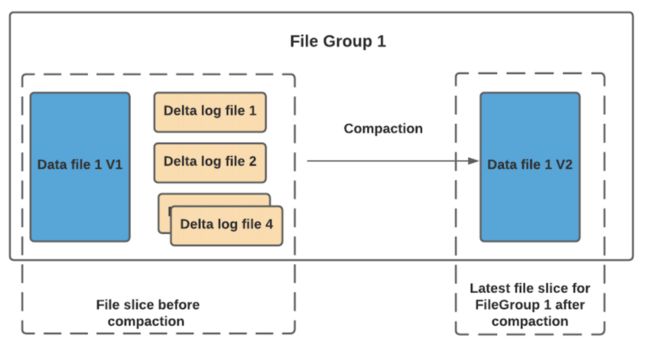
用户可以选择内联或异步模式运行压缩。Hudi也提供了不同的压缩策略供用户选择,最常用的一种是基于提交的数量。例如您可以将压缩的最大增量日志配置为 4。这意味着在进行 4 次增量写入后,将对数据文件进行压缩并创建更新版本的数据文件。压缩完成后,读取端只需要读取最新的数据文件,而不必关心旧版本文件。
让我们根据某些重要标准比较 COW 与 MOR。
5. 对比
5.1 写入延迟
正如我们之前所讨论,由于写入期间发生同步合并,与 MOR 相比COW 具有更高的写入延迟。
5.2 读取延迟
由于我们在 MOR 中进行实时合并,因此与 COW 相比MOR 往往具有更高的读取延迟。但是如果根据需求配置了合适的压缩策略,MOR 可以很好地发挥作用。
5.3 更新代价
由于我们为每批写入创建更新的数据文件,因此 COW 的 I/O 成本将更高。由于更新进入增量日志文件,MOR 的 I/O 成本非常低。
5.4 写放大
同样当我们创建更新版本的数据文件时,COW 会更高。假设您有一个大小为 100Mb 的数据文件,并且每次更新 10% 的记录进行 4 批写入,4 次写入后,Hudi 将拥有 5 个大小为 100Mb 的 COW 数据文件。你可以配置你的清理器(将在后面的博客中讨论)清理旧版本文件,但如果没有进行清理,最终会有 5 个版本的数据文件,总大小约500Mb。MOR 的情况并非如此,由于更新进入日志文件,写入放大保持在最低限度。对于上面的例子,假设压缩还没有开始,在 4 次写入后,我们将有 1x100Mb 的文件和 4 个增量日志文件(10Mb) 的大小约140Mb。
6. 结论
尽管 MOR 似乎有一些缺点,但它提供了不同的查询功能,例如读优化查询(将在后面的博客中讨论),这可能不会产生额外的合并成本。如果有一个具有适当配置的异步压缩作业,那么就可以获得 MOR 的所有好处,而无需在延迟上进行大量权衡。