学习笔记-架构的演进之容器编排-3月day08
文章目录
- 前言
- 容器编排过程会遇到的问题
- Pod
- 总结
- 附
前言
自从 Docker 提出“以封装应用为中心”的容器发展理念,成功取代了“以封装系统为中心”的 LXC 以后,一个容器封装一个单进程应用,已经成为了被广泛认可的最佳实践。
然而当单体时代过去之后,分布式系统里对于应用的概念已经不再等同于进程了,此时的应用需要多个进程共同协作,通过集群的形式对外提供服务,那么以虚拟化方法实现这个目标的过程,就被称为容器编排(Container Orchestration)。
接下来,我们将搞清楚的是:
- “为什么 Kubernetes 会设计成现在这个样子?”
- “为什么以容器构建系统应该这样做?”
容器编排过程会遇到的问题
- 场景一
假设有两个应用,其中一个是 Nginx,另一个是为该 Nginx 收集日志的 Filebeat,你希望将它们封装为容器镜像,以方便日后分发。
最直接的方案就将 Nginx 和 Filebeat 直接编译成同一个容器镜像,这是可以做到的,而且并不复杂。不过这样做其实会埋下很大的隐患:它违背了 Docker 提倡的单个容器封装单进程应用的最佳实践。
- 场景二
假设现在有两个 Docker 镜像,其中一个封装了 HTTP 服务,为便于称呼,叫它 Nginx 容器,另一个封装了日志收集服务,叫它 Filebeat 容器。现在你要求 Filebeat 容器能收集 Nginx 容器产生的日志信息。
场景二的需求依然不难解决,只要在 Nginx 容器和 Filebeat 容器启动时,分别把它们的日志目录和收集目录挂载为宿主机同一个磁盘位置的 Volume 即可,在 Docker 中,这种操作是十分常用的容器间信息交换手段。
尽管共享 IPC 名称空间不如共享 Volume 常见,但 Docker 同样支持了这个功能,也就是通过 docker run 命令提供了 --ipc 参数,用来把多个容器挂载到同一个父容器的 IPC 名称空间之下,以实现容器间共享 IPC 名称空间的需求。类似地,如果要共享 UTS 名称空间,可以使用 --uts 参数;要共享网络名称空间的话,就使用 --net 参数。自动地为多个容器设置好共享名称空间,就是Docker Compose提供的核心能力。
不过,这种针对具体应用需求来共享名称空间的方案,确实可以工作,但并不够优雅,也谈不上有什么扩展性。要知道,容器的本质是对 cgroups 和 namespaces 所提供的隔离能力的一种封装,在 Docker 提倡的单进程封装的理念影响下,容器蕴含的隔离性也多了仅针对于单个进程的额外局限。
与此相对应,Linux 的 cgroups 和 namespaces,原本都是针对进程组而不只是单个进程来设计的,同一个进程组中的多个进程,天然就可以共享相同的访问权限与资源配额。
如果我们将容器与进程在概念上对应起来,那容器编排的第一个扩展点,就是要找到容器领域中与“进程组”相对应的概念,这是实现容器从隔离到协作的第一步。在 Kubernetes 的设计里,这个对应物叫做Pod。
Pod
扮演容器组的角色,满足容器共享名称空间的需求,是 Pod 两大最基本的职责之一,同处于一个 Pod 内的多个容器,相互之间会以超亲密的方式协作。
对于普通非亲密的容器来说,它们一般以网络交互方式(其他的如共享分布式存储来交换信息,也算跨网络)协作;对于亲密协作的容器来说,是指它们被调度到同一个集群节点上,可以通过共享本地磁盘等方式协作;而超亲密的协作,是特指多个容器位于同一个 Pod 这种特殊关系,它们将默认共享以下名称空间:
- UTS 名称空间:所有容器都有相同的主机名和域名。
- 网络名称空间:所有容器都共享一样的网卡、网络栈、IP 地址,等等。因此,同一个 Pod 中不同容器占用的端口不能冲突。
- IPC 名称空间:所有容器都可以通过信号量或者 POSIX 共享内存等方式通信。
- 时间名称空间:所有容器都共享相同的系统时间。
同一个 Pod 的容器,只有** PID 名称空间和文件名称空间默认是隔离的**。
Pod的另一个基本职责是实现原子性调度。这里我们可以先明确一点,就是如果容器编排不跨越集群节点,那是否具有原子性其实都不影响大局。
如果以容器为单位来调度的话,不同容器就有可能被分配到不同机器上。而两台机器之间本来就是物理隔离,依靠网络连接的,所以这时候谈什么名称空间共享、cgroups 配额共享都没有意义了,由此我们就从场景二又演化出了场景三:
- 假设你现在有 Filebeat、Nginx 两个 Docker 镜像,在一个具有多个节点的集群环境下,要求每次调度都必须让 Filebeat 和 Nginx 容器运行于同一个节点上。
如果我们将运行资源的需求声明定义在 Pod 上,直接以 Pod 为最小的原子单位来实现调度的话,由于多个 Pod 之间一定不存在超亲密的协同关系,只会通过网络非亲密地协作,那就根本没有协同的说法,自然也不需要考虑复杂的调度了。
Pod 是隔离与调度的基本单位,也是我们接触的第一种 Kubernetes 资源。Kubernetes 把一切都看作是资源,不同资源之间依靠层级关系相互组合协作,这个思想是贯穿 Kubernetes 整个系统的两大核心设计理念之一,不仅在容器、Pod、主机、集群等计算资源上是这样,在工作负载、持久存储、网络策略、身份权限等其他领域中,也都有着一致的体现。
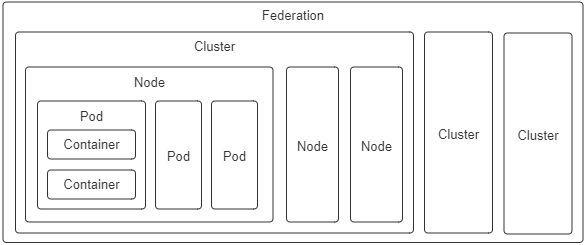
Pod 是 Kubernetes 中最重要的资源,又是资源模型中一种仅在逻辑上存在、没有物理对应的概念(因为对应的“进程组”也只是个逻辑概念),也是其他编排系统没有的概念。
对于 Kubernetes 中的其他计算资源,像 Node、Cluster 等都有切实的物理对应物,很容易就能形成共同的认知,这里只了解下它们的设计意图:
- 容器(Container):延续了自 Docker 以来一个容器封装一个应用进程的理念,是镜像管理的最小单位。
- 生产任务(Pod):补充了容器化后缺失的与进程组对应的“容器组”的概念,Pod 中的容器共享 UTS、IPC、网络等名称空间,是资源调度的最小单位。
- 节点(Node):对应于集群中的单台机器,这里的机器既可以是生产环境中的物理机,也可以是云计算环境中的虚拟节点,节点是处理器和内存等资源的资源池,是硬件单元的最小单位。
- 集群(Cluster):对应于整个集群,Kubernetes 提倡的理念是面向集群来管理应用。当你要部署应用的时候,只需要通过声明式 API 将你的意图写成一份元数据(Manifests),把它提交给集群即可,而无需关心它具体分配到哪个节点(尽管通过标签选择器完全可以控制它分配到哪个节点,但一般不需要这样做)、如何实现 Pod 间通信、如何保证韧性与弹性,等等,所以集群是处理元数据的最小单位。
- 集群联邦(Federation):对应于多个集群,通过联邦可以统一管理多个 Kubernetes 集群,联邦的一种常见应用是支持跨可用区域多活、跨地域容灾的需求。
总结
容器之间顺畅地交互通信是协作的核心需求,但容器协作并不只是通过高速网络来互相连接容器而已。如何调度容器,如何分配资源,如何扩缩规模,如何最大限度地接管系统中的非功能特性,让业务系统尽可能地免受分布式复杂性的困扰,都是容器编排框架必须考虑的问题,只有恰当解决了这一系列问题,云原生应用才有可能获得比传统应用更高的生产力。
附
此文章为3月Day08学习笔记,内容来源于极客时间《周志明的软件架构课》