【Redis】6. Redis缓存设计与性能优化
目录
缓存穿透
缓存击穿(缓存失效)
缓存雪崩
热点缓存key重建问题
缓存与数据库双写不一致问题
开发规范与性能优化
bigkey的危害:
bigkey的产生原因:
优化bigkey的方案:
Redis连接池配置优化方案:
Redis对于过期键有三种清除策略:
Redis运维工具:略
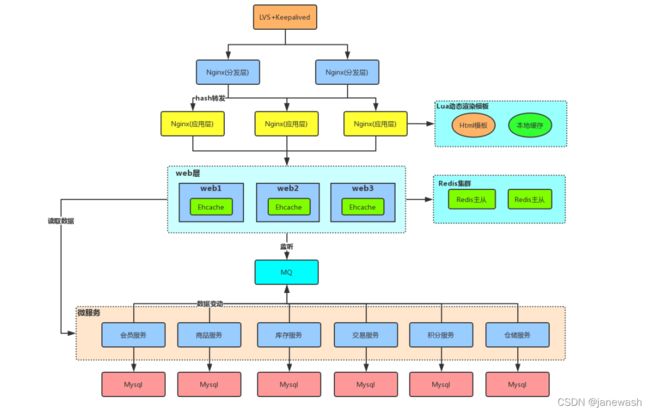
互联网公司多级缓存架构:
Nginx(负载均衡设备)缓存:例如存放热点数据(容量最小)
web缓存(JVM级别):Ehcache 、Map等(容量稍大)
Redis缓存:容量最大
缓存访问顺序:
Nginx缓存,有则返回 -> 本地内存(JVM)缓存,有则返回 -> Redis缓存,有则返回 -> 应用服务,访问数据库
缓存存在的问题:
1. Redis缓存穿透,缓存击穿,缓存雪崩
2. 热点缓存key重建问题
3. 缓存与数据库双写不一致问题
缓存穿透
定义:查询一个根本不存在的数据, 缓存层和存储层都不会命中
结果:导致不存在的数据每次请求都要到存储层去查询, 失去了缓存保护后端存储的意义。高并发情况下造成服务崩溃。
解决方案:
1. 缓存空对象
if productid不存在,set key null缓存;
思考:若后期上架了productid一样的产品,会有什么结果?
Answer:可能会导致后上架的产品一直查不到数据
方案:缓存空对象时,设置超时时间
2. 布隆过滤器
布隆过滤器:实现了一种bitMap的过滤器,对于不存在的key数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。(当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在)
这种方法适用于数据命中不高、 数据相对固定、 实时性低(通常是数据集较大) 的应用场景, 代码维护较为 复杂, 但是缓存空间占用很少。
布隆过滤器不能修改其中的数据,例如key删除以后,布隆过滤器中数据还在。优化:定期重建布隆过滤器。
实现 redisson
缓存击穿(缓存失效)
定义:由于大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库
结果:会造成数据库瞬间压力过大甚至挂掉
解决方案:在批量增加缓存时最好将这一批数据的缓存过期时间设置为一个时间段内的不同时间(random)
缓存雪崩
定义:是缓存层支撑不住或宕掉后,流量会打向后端存储层(原因:大并发访问,redis设计不合理)
结果:存储层的调用量会暴增,造成存储层也会级联宕机
解决方案:
1. 改良Redis缓存设计:保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster
2. 在服务中使用隔离组件为后端服务限流/熔断并降级(微服务相关内容Spring Cloud),比如使用Sentinel或Hystrix限流降级组件
例如:非核心数据查询:产品标签,收藏数等,采用服务降级,返回预设定信息或空值或错误提示;暂停从缓存中查询这些数据
核心数据查询:产品库存,价格等,允许查询缓存,如果缓存缺失,也可以继续通过数据库读取
3. 组织进行故障演练,测试环境/生产环境。关键:流量预估,预案设定
热点缓存key重建问题
定义:在缓存失效的瞬间, 有大量线程来重建缓存(例如:京东抢购板蓝根,“板蓝根”无缓存/缓存失效。冷数据->热点数据:热点数据的缓存重建)
结果:造成后端负载加大, 甚至可能会让应用崩溃
原因:
1. 访问并发量非常大
2. 重建缓存不能在短时间完成, 可能是一个复杂计算,例如复杂的SQL、多次IO、多个依赖等。
解决方案:要避免大量线程同时重建缓存
设置“互斥锁”,同一时间只允许1个线程进行缓存重建,其他线程等待
缓存与数据库双写不一致问题
定义:在大并发下,同时操作数据库与缓存会存在数据不一致性问题
例如:1. 在update产品时,都会更新缓存;并发情况下,由于执行过程不一致卡顿等原因,导致缓存时效性有问题
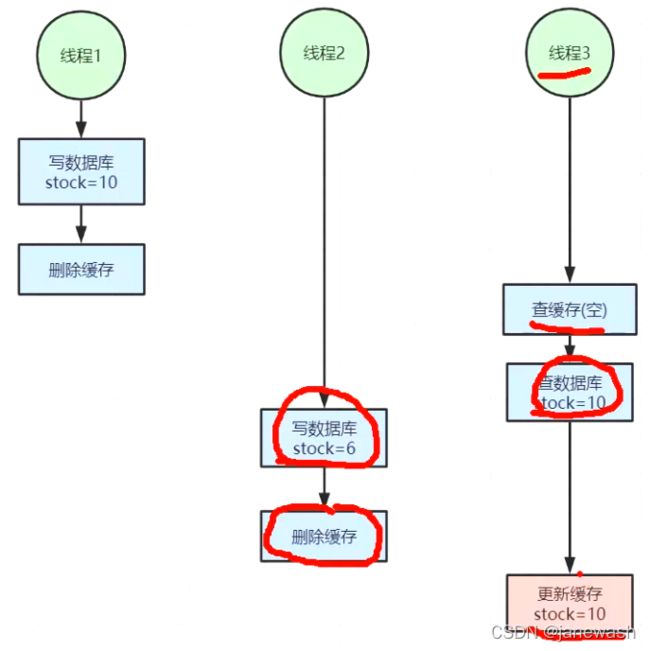
解决方案:根据具体的场景进行优化,读写不一致较难优化到理想
| 并发 | 场景举例 | 发生读写不一致的概率 | 优化方案 |
| 概率小 | 个人维度的信息(订单数据,用户数据) | 很少 | 给缓存key加上过期时间,每隔一段时间触发读的主动更新 |
| 并发高 | 商品信息(商品名称,商品分类菜单) | 能容忍不一致 | 缓存加上过期时间,依旧可以解决大多数业务场景对缓存的要求 |
| 并发高 | 商品库存 | 不能容忍不一致 | 1. 放在内存队列中串行化执行(效率低。不符合并发的初衷) 4. 阿里canal中间件,通过监听数据库的binlog日志,及时修改缓存。不需要通过web服务来修改缓存,这种情况下,缓存更新是有序的,串行的。(略增加系统复杂度) |
Tips:对于读多写多,又对一致性要求较高的场景,不要使用redis,直接读写数据库(eg: mysql从库用来读,mysql主库用来写)
放入缓存的数据应该是对实时性、一致性要求不是很高的数据。切记不要为了用缓存,同时又要保证绝对的一致性做大量的过度设计和控制,增加系统复杂性!
开发规范与性能优化
1. key 规范:略
2. value规范:
【强制】:拒绝bigkey(防止网卡流量、慢查询)(value的数据结构可以是hash,集合,list等等),几十兆的大value禁止使用缓存
a. 字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
b. 非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。 一般来说元素个数不要超过5000。
bigkey的危害:
a.导致redis阻塞
b.网络拥塞:bigkey也就意味着每次获取要产生的网络流量较大,假设一个bigkey为1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量;甚至在服务中,有嵌套场景时,会使服务崩溃。千兆网卡的带宽是128MB/s
c. 过期删除:如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
bigkey的产生原因:
bigkey的产生都是由于程序设计不当
对于数据规模预料不清楚造成的
举例:
(1) 社交类:粉丝列表,大V的粉丝链表不精心设计下,必是bigkey。
(2) 统计类:例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
(3) 缓存类:将数据从数据库load出来序列化放到Redis里,这个方式非常常用,但有两个地方需 要注意,第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据,有的同学为了 图方便把相关数据都存一个key下,产生bigkey。
优化bigkey的方案:
1. 拆分:blig list:list1,list2……listN
big hash:分段存储,大key拆成小key
2. 如果bigkey不可避免,尽量使用批量命令hmget替代hgetall,同理删除也是
3. 【推荐】选择合适的数据结构:eg: hash替代String
4. 【推荐】设置key的生命周期
5. 命令操作中:
a. 使用轮询遍历操作(hscan, sscan, zscan)替代集合操作(hgetall, Irange, smembers,zrange,sinter等),如果使用,要明确N的值
b. 禁用命令:keys, flushall, flushdb等
6. 【推荐】使用批量操作提高效率(注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)
a. 原生命令:mget,mset
b. 非原生命令:可以使用pipeline提高效率(pipeline非原子操作)
7. 不推荐使用redis的db,事务功能
Redis连接池配置优化方案:
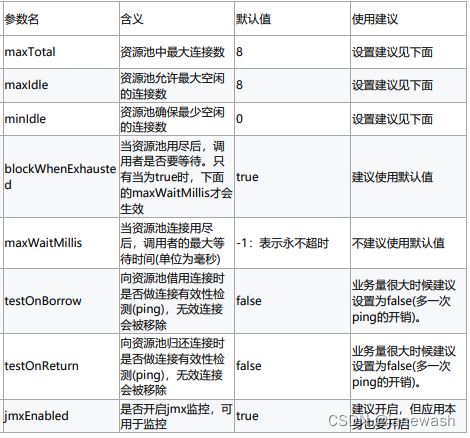
maxTotal:一次命令时间(borrow|return resource + Jedis执行命令(含网络) )的平均耗时约为 1ms,一个连接的QPS大约是1000。业务期望的QPS是50000,那么理论上需要的资源池大小是50000 / 1000 = 50个。但事实上这是个理论值,还要考虑到要 比理论值预留一些资源,通常来讲maxTotal可以比理论值大一些
连接池的最佳性能是maxTotal = maxIdle,这样就避免连接池伸缩带来的性能干扰。
连接池预热(Jedis):
List minIdleJedisList = new ArrayList(jedisPoolConfig.getMinIdle());
for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {
Jedis jedis = null;
try {
jedis = pool.getResource();
minIdleJedisList.add(jedis);
jedis.ping();
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {
//注意,这里不能马上close将连接还回连接池,否则最后连接池里只会建立1个连接。。
//jedis.close();
}
}
//统一将预热的连接还回连接池
for (int i = 0; i < jedisPoolConfig.getMinIdle(); i++) {
Jedis jedis = null;
try {
jedis = minIdleJedisList.get(i);
//将连接归还回连接池
jedis.close();
} catch (Exception e) {
logger.error(e.getMessage(), e);
} finally {}
} Redis对于过期键有三种清除策略:
1. 被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期 key
2. 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一 批已过期的key
3. 当前已用内存超过maxmemory限定时,触发主动清理策略 主动清理策略在Redis 4.0 之前一共实现了 6 种内存淘汰策略,在 4.0 之后,又增加了 2 种策 略,总共8种:
a) 针对设置了过期时间的key做处理:
1. volatile-ttl:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删 除,越早过期的越先被删除。
2. volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
3. volatile-lru:会使用 LRU 算法筛选设置了过期时间的键值对删除。
4. volatile-lfu:会使用 LFU 算法筛选设置了过期时间的键值对删除。
b) 针对所有的key做处理:
5. allkeys-random:从所有键值对中随机选择并删除数据。
6. allkeys-lru:使用 LRU 算法在所有数据中进行筛选删除。
7. allkeys-lfu:使用 LFU 算法在所有数据中进行筛选删除。
c) 不处理:
8. noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowed when used memory",此时Redis只响应读操作。
Redis运维工具:略
通过运维工具可以知道Redis线上并发量,Redis连接数
监控工具—Prometheus—监控Redis_sanmi8276的博客-CSDN博客_prometheus监控redis
redis-cli中输入INFO命令进行查看Redis服务器中的redis关键信息