Spark SQL之:概述及操作应用
Spark SQL之:概述及操作应用
文章目录
- Spark SQL之:概述及操作应用
-
- 一、Spark SQL概述
- 二、DataFrame
- 三、RDD转换为DataFrame
- 四、Spark SQL和数据库的应用
一、Spark SQL概述
-
了解Shark
(1) 从shark说起
shark即Hive On Spark,为了实现与Hive的兼容,Shark在HiveQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成Spark作业,通过Hive的HiveQL解析,把HiveQL翻译成Spark上的RDD操作。
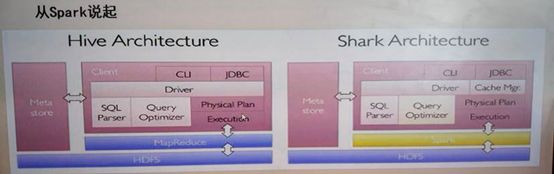
(2) shark的设计导致了两个问题
a. 执行计划优化完全依赖与Hive,不方便添加新的优化策略
b. 因为spark是线程级执行,而MapReduce是进程级执行。 -
Spark SQL设计
(1) Spark SQL的特点
a. 支持使用sql查询分布式的数据;向使用Spark SQL查询分布式数据,先要创建SQLContext
b. Spark SQL底层是DataFrame(即带有Schema信息的RDD),可以对内部和外部各种数据源执行各种关系操作
c. 数据源:RDD、Hive、HDFS以及JSON格式等数据;支持大量的数据源和数据分析算法
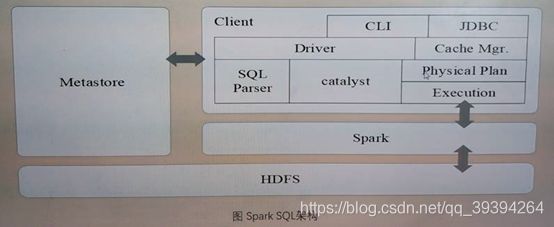
d. spark技术栈中支持结构化数据的组件(2) Spark SQL架构
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据,也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。
-
SparkSQL&Shark
(1) Hive on Spark --shark
Hive 解析优化,存储
Spark 计算引擎(2) Spark on Hive --SparkSQL
Hive 存储
Spark 解析优化,执行引擎(3) Hive->Shark->SparkSQL
SparkSQL支持在Hive中的语法,支持在Shark中的语法
SparkSql可以操作原生RDD
SparkSQL完全脱离Hive
SparkSQL查询出来的DataFrame还可以转换成RDD -
Spark on Hive配置
(1) 在客户端…/conf/hive-site.xml 中配置
hive.metastore.uris
thrift://node1:9083
(2) 启动HDFS,在Hive服务端启动Hive的metaStore服务 :hive --service metastore &
(3) 启动Standalone集群
(4) 在客户端 测试
./spark-shell --master spark://Cloud01:7077,Cloud02:7077
二、DataFrame
-
概述
(1) DataFrame是一种以RDD为基础的分布式数据集,RDD是分布式的 Java对象的集合,但是,对象内部结构对于RDD而言却是不可知的。
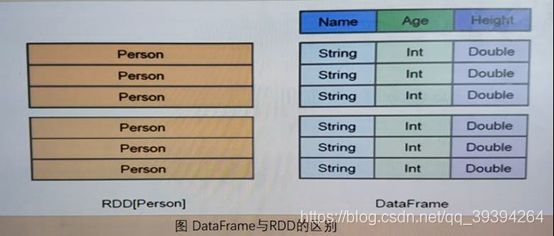
(2) DataFrame多了数据的结构信息,即schema。RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合。(3) DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。
(4) DataFrame是为数据提供了Schema的视图。可以把它当做数据库中的一张表来对待。
(5) DataFrame也是懒执行的。
(6) 性能上比RDD要高,主要有两方面原因:
a. 定制化内存管理:数据以二进制的方式存在于非堆内存,节省了大量空间之外,还 摆脱了GC的限制
b. 查询计划通过Spark catalyst optimiser进行优化 -
创建
(1) 创建SparkSession对象
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().getOrCreate()(2) 创建DataFrame
a. 导包启用隐式转换
import spark.implicits._
b. 从文件中加载数据创建DataFrame
spark.read.format("").load("")
① 从文件中读取

② 读取Mysql中的数据
③ 读取Hive中的数据
要使用HiveContext
hiveContext.sql(可以操作临时表/可以操作hive中的数据表)
hiveContext.table("student_infos"); 将Hive中的某张表加载成DF
-
保存DataFrame
(1) 保存到文件中
df.write.txt"people.txt")
df.write.json("people.json“)
df.write.parquet("people.parquet")
df.write.format("parquet").save("hdfs://Cloud01:9000/people.parquet")
df.write.csv("people.csv")(2) 存入Mysql表中
(3) 存入Hive 中表中
goodStudentsDF.write().mode(SaveMode.Overwrite).saveAsTable("good_student_infos"); -
常用操作
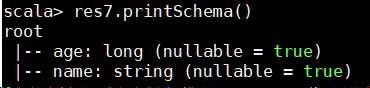
(1) 打印模式信息printSchema()
res.printSchema()查看表结构
(2) 选择多列select()
res.select(res("name"))//查看某个字段
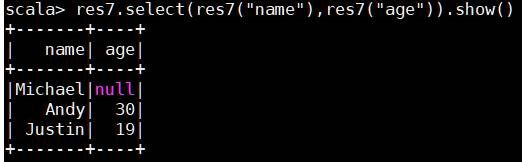
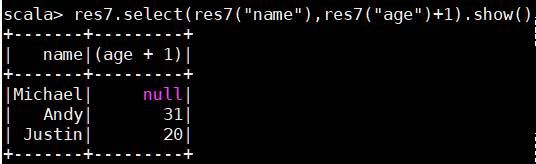
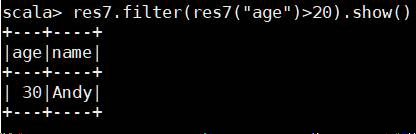
(3) 条件过滤filter()
res7.filter(res7("age")>20).show()
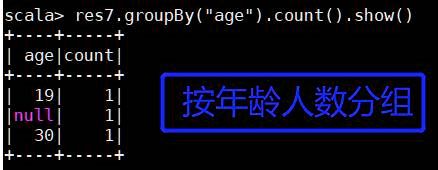
(4) 分组聚合groupBy()
res7.groupBy("age").count().show()
(5) 排序sort()
res7.sort(res7("age").asc).show()
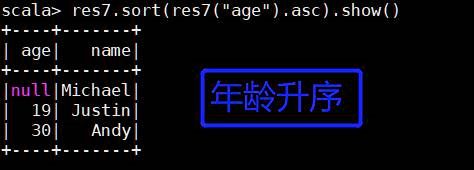
(6) 多个字段排序
res7.sort(res7("age").desc,res7("name").asc).show()
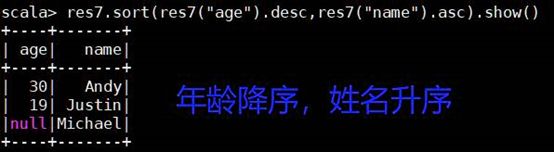
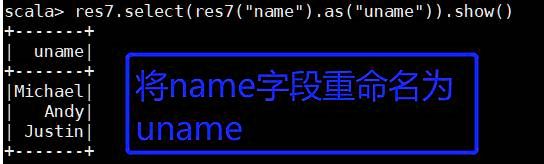
(7) 重命名
res7.select(res7("name").as("uname")).show()
-
DataFrame注册成临时表
生成pepole临时表以后,用 SparkSession对象.sql() 就可以使用sql语句查询
res9.createOrReplaceTempView("people")
spark.sql("select * from people")
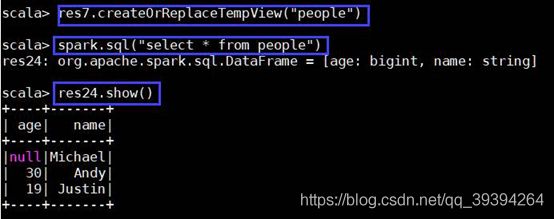
三、RDD转换为DataFrame
-
利用反射机制解析RDD
(1) Spark-Shell操作
开发前要导包:import org.apache.spark.sql.Encoder
import org.apache.spark.sql.catalyse.encoder.ExpressionEncoder
import spark.implicits._a. 创建RDD ① sc.textFile("") ② sc.parellelize(集合) ③ sc.makeRDD(集合) b. 创建样例类 case class People(name:String,age:Int) c. 将整理后的RDD包装成样例类(分割) res0.map(_.split(",")) res1.map(t=>People(t(0),t(1).trim.toInt)) d. 将包装好的样例类转化为DF res2.toDF(2) IDEA操作
a. 依赖配置

b. 代码import org.apache.spark.rdd.RDD import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.spark.{SparkConf, SparkContext} case class People(name: String, age: Int) object SQLlesson01 { def main(args: Array[String]): Unit = { //设置spark val conf = new SparkConf().setMaster("local").setAppName("sparksql01") val sc = new SparkContext(conf) //创建spark sql对象 val sparkSql:SparkSession = SparkSession.builder().config(conf).getOrCreate() //启用隐式转换 import sparkSql.implicits._ //创建RDD val unit: RDD[People] = sc.textFile("./people.txt").map(_.split(",")).map(t=>People(t(0),t(1).trim.toInt)) unit.foreach(println) //转换为DataFrame val df:DataFrame = unit.toDF() //创建临时表 df.createOrReplaceTempView("peopleTemp") //通过临时表查询 sparkSql.sql("select * from peopleTemp").show() } } -
使用编程方式定义RDD
(1) Spark-Shell操作
开发前引包:
import org.apache.spark.sql.type._
import org.apache.spark.sql.Row
a. 通过RDD创建行对象
① sc.textFile("")
② sc.parellelize(集合)
③ sc.makeRDD(集合)
res0.map(_.split(",")).map(t=>Row(t(0),t(1).trim.toInt))
b. 创建表头,把字段封装进表头
`Array(StructField("name",StringType,true),StructField("age",IntegerType,true))
StructType(res2)`
c. 将表头和行拼接形成DataFrame
spark.createDataFrame(res1,res3)
(2) IDEA操作
b. 代码
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
object SQLlesson02 {
def main(args: Array[String]): Unit = {
//设置spark对象
val conf = new SparkConf().setMaster("local").setAppName("sparkSQL02")
val sc = new SparkContext(conf)
//创建spark sql对象
val spark = SparkSession.builder().config(conf).getOrCreate()
//启用隐式转换
import spark.implicits._
//1. 创建表头
val fields = Array(StructField("name",StringType,true),StructField("age",IntegerType,true))
val structType:StructType = StructType(fields)
//2. 创建行对象
val value:RDD[Row] = sc.textFile("./people.txt").map(_.split(",")).map(t=>Row(t(0),t(1).trim.toInt))
//3. 将表头和行对象拼接
val df = spark.createDataFrame(value,structType)
//创建临时表
df.createOrReplaceTempView("people2")
//通过临时表查询
spark.sql("select * from people2").show()
}
}
四、Spark SQL和数据库的应用
数据源支持Parquet、Json、hive等
- 使用Spark SQL读取数据库(MySQL)
(1) Spark-shell操作
a. 启动MySQL数据库
b. spark启动MySQL驱动包(/spark/jars)
./spark-shell \
--jars ~/software/spark/jars/mysql-connector-java-5.1.32-bin.jar \
--driver-class-path ~/software/spark/jars/mysql-connector-java-5.1.32-bin.jar
c. 创建jdbc连接
val jdbcDF = spark.read.format("jdbc").
option("url","jdbc:mysql://Cloud00:3306/test").
option("driver","com.mysql.jdbc.Driver").
option("dbtable","tb1").
option("user","root").
option("password","admin").
load()
(2) IDEA操作
a. 添加jar插件
b. 代码
- 使用Spqrk SQL写入数据库(MySQL)
(1) Spark-shell操作
引包:
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import java.util.Properties
a. 通过RDD创建Row对象,创建表头
val RDD=sc.parallelize(Array("1 haha","2 xixi")).map(_.split(" ")).map(t=>Row(t(0).trim.toInt,t(1)))
val schema=StructType(List(StructField("id",IntegerType,true),StructField("name",StringType,true)))
b. 转换为DataFrame
val df=spark.createDataFrame(RDD,schema)
c. 创建配置对象,设置参数
val prop = new Properties()
prop.put("user","root")
prop.put("password","admin")
prop.put("driver","com.mysql.jdbc.Driver")
d. 写入操作
df.write.mode("append").jdbc("jdbc:mysql://Cloud:3306/test","tb1",prop)
(2) IDEA操作
- 使用Spark SQL写入hive
(1) spark-shell操作
复制hive的配置文件并修改(hive-site.xml)
开启元数据监听 hive --service matestore &
引包
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
a. 通过RDD创建Row对象,创建表头
val RDD=sc.parallelize(Array("1 haha","2 xixi")).map(_.split(" ")).map(t=>Row(t(0).trim.toInt,t(1)))
val schema=StructType(List(StructField("id",IntegerType,true),StructField("name",StringType,true)))
b. 转换为DataFrame
val df=spark.createDataFrame(RDD,schema)
c. 注册临时表
df.createOrReplaceTempView("stu")
d. 写入数据
sql("insert into test.student select * from stu")
(2) IDEA操作
