4万字【Python高级编程】保姆式教学,Python大厂高频面试题解析
[](
)4.自定义模块
每个人都能生成自定义模块来进行调用,自定义模块就是Python文件,我们写代码时创建的Python文件就相当于1个模块。
注意点:被调用的模块尽量放在当前Python文件相同目录下,否则导入时要声明所在文件夹才能导入。
例子:自定义1个模块,在另一个Python文件中进行调用。
新建1个名为module1的Python文件,代码如下:
def fun1(a,b) : #实现a+b并输出结果
print(a+b)
相同目录下新建另一个Python文件,调用module1.py这个模块:
import module1
module1.fun1(20,30)
运行当前Python文件结果:
50
[](
)5.模块的测试
每个模块导入的时候都默认被执行一遍,但同时在模块内部又存在着很多的内部测试代码,为了避免导入模块时执行了模块内部的测试代码,于是就牵扯到一个方法:
很多模块在内部都有测试方法:
if name == “main”:
代码1
这个方法能够实现一个功能,在模块中执行的话,就会执行代码1的代码,在其他文件导入该模块的时候,则不会执行代码1的代码,所以一般模块内部的测试都放在了代码1当中。
为什么?神奇的点就在于__name__,它在当前文件中执行的结果是__main__,在其他文件导入时执行的结果是模块名,所以利用这一点,用上if语句就能判断模块执行到底是在当前文件执行还是被导入执行。
举例:
新建1个Python叫module1,作为模块,代码如下:
print(name) #打印__name__
执行结果:
main
再新建1个Python文件,导入刚才建好的module1.py模块:
import module1
执行结果:
module1
在当前文件的执行和被导入时执行,结果是不一样的,所以它成为了模块的内部测试方法。
注意点:在自定义的模块中,不建议写while循坏,不然导入的过程中一直在执行模块里面的while循坏,可能会跳不出来,也就是一直在导入模块,其他代码执行不到。
[](
)(二)包
[](
)1.定义
包就是将有联系的模块放在同一个文件夹下,并且该文件夹里有“init.py”这个文件,这个文件夹就叫做包。
包的特征:
1.包也是对象
2.必须有__init__.py文件
3.init.py文件是包的构造方法,控制着包的导入行为,一般是个空包
4.包里面不仅可以有模块,还可以有子包
[](
)2.包的创建
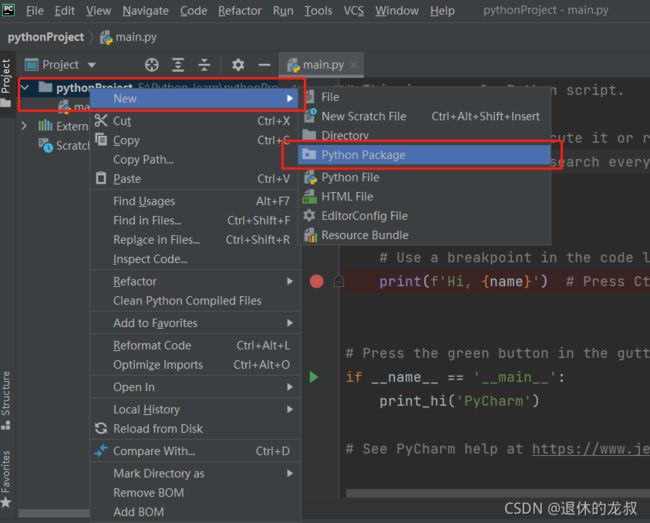
在Pycharm软件中新建1个项目文件,创建完成后,打开Pycharm创建1个项目文件夹→点击文件夹→右键弹出选项→New→Python Package→完成创建,创建的新文件夹就是包,里面自动创建了init文件。
[](
)3.包的导入
常规导入方法主要有2种。
方法1:import 包名.模块名.目标
方法2:import 包名.子包.模块名.目标
这里所说的目标可以是变量、函数等等对象,具体的在下面会讲到。
[](
)4.包的使用
使用形式1:常规使用1
import 包名.模块名
包名.模块名.功能
举例:创建1个包,在另一个.py文件中使用,要求.py文件不包含在创建的包内。
步骤1,打开Pycharm新建一个项目,创建1个包,命名为demo,包里面新建1个.py文件,命名为my_module,代码如下:
a = 100
def fun1():
print(“这是1个包”)
步骤2,打开另1个.py文件,导入已创建的包
import demo.my_module
print(demo.my_module.a)
demo.my_module.fun1()
执行结果:
100
这是1个包
使用形式2:常规使用2
from 包名 import 模块名
模块名.功能
模块名.变量
举例:我沿用上面已经创建好的demo包,直接在步骤2中修改代码,用这个新方式去导入包并使用。
from demo import my_module
print(my_module.a)
my_module.fun1()
执行结果是一样的:
100
这是1个包
使用形式3:另起别名并使用
import 包名.模块名 as 别名
别名.功能
别名.变量
上面使用形式1中可能有人会发现,导入模块后的使用不太方便,又要包名又要模块名的,能不能简单点?当然可以,直接给包里的模块另起1个缩短的别名,后面直接用别名就可以了。
沿用上面的使用形式1的例子,这里我就不改动步骤1了,我直接在步骤2中进行另起别名。
import demo.my_module as n1 #另起别名为n1
print(n1.a)
n1.fun1()
执行结果:
100
这是1个包
结果是一样的,但如果代码比较长的话,使用别名会方便很多。
当然了,这里也可以用使用形式2的方式导入包并另起别名,使用时用别名就可以了,这个方式我就不举例了,你们自己可以去试试。
使用方式4:导入某个功能
from 包名.模块名 import 功能1
功能1
这里我也沿用已创建好的包,直接在另一个.py文件中进行使用。
from demo.my_module import fun1
fun1()
执行结果:
这是1个包
使用方式5:导入所有功能
在模块导入的时候我们介绍了import * 这个方式去导入模块里面的所有功能,在这里也可以这么入导入包里面的模块的所有功能。
举例,名叫“demo”包里面有1个模块叫“hhhh”,模块的代码如下:
def fun1():
print(“这是功能1”)
def fun2():
print(“这是功能2”)
然后我们在另一个.py文件中调用一下;
from demo.hhhh import *
fun1()
fun2()
执行结果:
这是功能1
这是功能2
6.关于all的使用
关于__all__的使用在模块的时候有介绍过,那是控制可以被导入的功能列表,但在包里面,__all__是控制可以被导入的模块列表,即声明哪些模块可以被导入。
包里面的__all__是在__init__文件中声明的,而不是在哪个模块中写的。
举例:一个包里面有多个模块,其中被all声明的模块可以被导入,不声明的不可以被导入。
步骤1,在名为demo的包里面有hhhh和my_module两个模块,但在int文件中被all声明只有hhhh文件可以使用,int文件的代码如下:
all = [
“hhhh” # hhhh模块允许被导入
]
步骤2,在新的.py文件中导入demo包里面的hhhh和my_module两个模块:
from demo import * #导入包里面的所有模块
hhhh.fun1() #调用hhhh模块的fun1功能,输出“这是功能1”
my_module.fun1() #调用my_module模块的fun1功能,输出“这是1个包”
执行结果:

很明显,虽然用 * 导入了所有模块,但被all声明可导入的hhhh模块是可以被使用的,没被all声明的my_module模块是不能使用的,系统无

法识别。
[](
)(三)模块与包的作用
1.提高代码的可重用性。好用的代码不止你1个人可以用,很多人都可以重复使用它。
2.提高代码的可读性。如果所有的代码都放在1个.py文件中,那代码就太长了,增加了理解和维护难度,所以可以把一些常用的代码封装成包和模块,起1个望文生义的名字,需要的时候直接用就行,减少了代码的数量,提高了可读性。
3.减少代码的冗余。模块里面封装的一些方法,我们直接给参数去使用就可以了,不用把方法再写一遍,占用内存,也就减少了代码的冗余。
[](
)(四)第三方库的安装
Python虽然有很多自带的模块和包,简称内置模块,但只会使用内置模块还不够,毕竟内置模块有限,我们经常会用到第三方的库,这个时候学习怎么安装第三方的库(包)是很必要的。
今天来介绍3种第三方模块与包的安装方法。
[](
)1.通过pip安装
可以通过包管理命令pip去进行第三模块与包的下载和安装,前提是你安装的Python是照着我前面在【Python基础入门】那篇文章所讲的方式去安装,所有的选项都勾选了,这样你就不用配置环境变量了,首先查看一下你的pip是否能用。
方法:WIN+R调出运行窗口→输入cmd→如果出现下面的pip信息则是可以使用pip
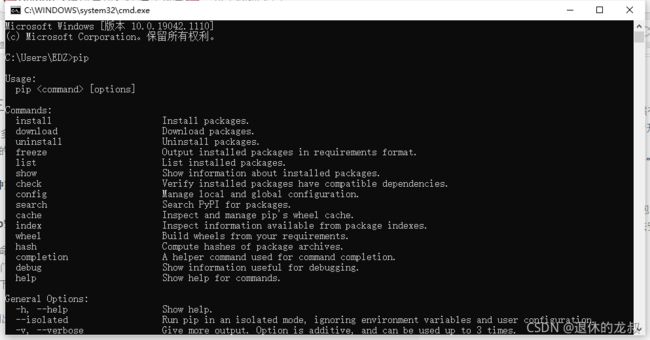
如果出现红字提示“cmd中 ’pip‘不是内部或外部命令,也不是可运行的程序或批处理文件”,那么你就手动配置一下环境变量吧,实在不行就回过头跟着我说的安装Python的步骤去重新装吧。
回到pip如何安装第三方模块与包的问题,首先我们得知道我们要安装的第三方模块与包是叫什么名字,比如Pillow这个第三方库,这是Python下非常强大的处理图像的工具库,安装方法是:
1.WIN+R调出运行窗口
2.输入cmd
3.输入 pip install Pillow
4.等待下载和安装的完成

有时候会出现很多红字提示下载失败,这个很正常,原因可能是:
(1).pip版本过低,升级一下pip版本,在黑窗口输入:python -m pip install -U pip
(2)网络不好,多下载几遍就可以了
[](
)2.通过Pycharm安装
通过pip安装是不需要打开软件的,但我们也可以通过Pycharm进行安装,方法如下:
点击左上角的 File → Settings → Project:项目名 → Python interpreter → 点击 + →
输入你想安装的包名,选择你看上的 → 点击 Install Package → 等待下载和安装



[](
)3.通过渠道下载.whl文件安装
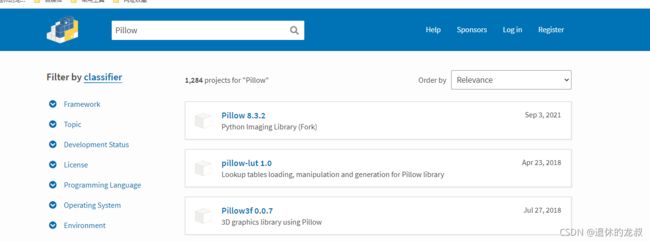
可以通过官网等渠道去搜索和下载你想要的包,官网:https://pypi.org/ ,搜索你要下载的第三方库,比如说Pillow这个库,直接搜就可以了:
然后选择你要下载的文件,比如Pillow8.3.2这个版本,进入下载页面,点击 Download files。
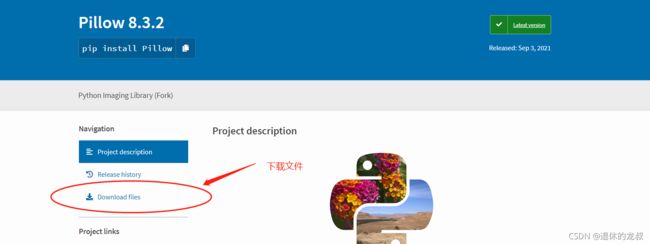
进去之后有很多的版本型号,建议选择与你符合的版本,否则可能装不了,这里要注意Python版本、系统和电脑的位数。

比如说我的Python装的是3.9.6的,所以我下的是cp39里面的,电脑是64位,用的是Windows系统,所以我下的版本是 Pillow-8.3.2-cp39-cp39-win_amd64.whl 这个文件。

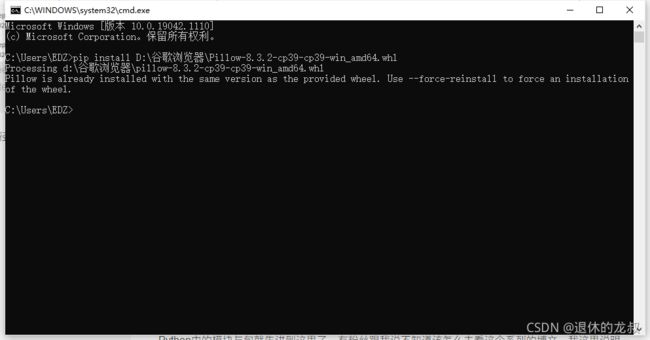
下载好之后,WIN+R 打开命令行输入CMD,在黑窗口中输入 pip install 文件路径下的文件名,比如我下载后存放的路径是D:\谷歌浏览器,所以我在黑窗口输入的代码是:
pip install D:\谷歌浏览器\Pillow-8.3.2-cp39-cp39-win_amd64.whl
然后回车进行安装,等待安装完成。
[](
)三、文件处理
================================================================
[](
)(一)文件的定义和操作
计算机中的文件通常是指计算机硬盘为载体的、存储在计算机中的信息集合,主要的表现形式为视频、音频、图片以及文档四类,比如执行性文件.exe、文档文件.txt、网页文件.html等等。

[](
)(二)文件的基本操作
在现实中,我们对文件进行操作可以大致总结为“打开→操作(阅读、删除、修改等)→保存→关闭”,在Python当中依然是如此,在用Python开始文件操作之前,我们先学几个方法。
1.open(name,mode) ----打开文件
这是Python打开文件的方法,用于打开一个文件,返回的是一个文件对象。
name指的是文件名,一定要写全,何为写全?就是要写清楚 存储路径+文件名+后缀 。
为何要写这么全?因为就算是相同的存储路径下,文件名相同的文件也可能不止一个,只要后缀不一样,计算机是允许存在同名文件,所以不写全的话,计算机是不知道你指的是谁
mode是打开文件的模式,默认是r,也就是只读的方式。mode的方式有很多,比如读、写等等,后面我们会讲到。
2.write(“内容") ------写
顾名思义,就是向文件对象中写入内容。
3.read() -------读
向文件中写入内容,括号里面可以写数字也可以不写,不写的话默认是读取全部内容,写数字则表示读取X个字符,比如说read(6)则读取文件对象的6个字符。
4.close() ------关闭文件
关闭文件的方法,如果你在进行文件操作之后不进行关闭文件,则文件一直处于打开和操作的状态,会占用内存。
5.案例
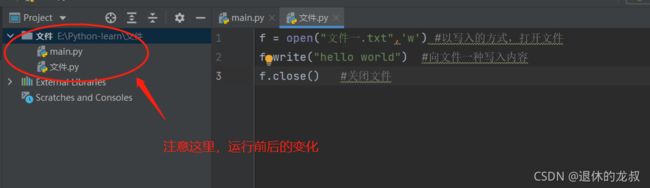
在了解了这4个基本方法之后,我们来开始做1个小案例:新建一个项目,然后新建一个名为“文件”的Python文件用于写代码,然后我们用写的方式向1个叫“文件1”的.txt文件写入“hello world”,代码如下:
f = open(“文件一.txt”,‘w’) #以写入的方式,打开文件
f.write(“hello world”) #向文件一中写入内容
f.close() #关闭文件
前面讲过 open() 这个方法返回的是一个文件对象,所以我们用f进行接收一下,这是没有运行前的界面:
运行后:
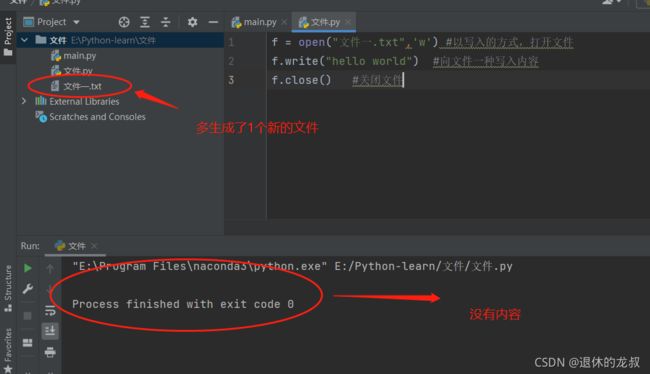
运行后生成了一个新的名为“文件一.txt”文件,打开它之后就能看到我们输入的内容。进行写操作时,如果文件不存在,则默认会创建一个。
同样的,我们也可以对这个文件进行读的操作:
f = open(“文件一.txt”,‘r’) #以写入的方式,打开文件
print(f.read()) #读文件
f.close() #关闭文件
运行结果:
hello world
这就是一个最基本的文件操作流程。
在这里要注意一点,open(name,mode)在一开始写的时候,mode就已经决定了你能做什么操作,也就是说如果你在开始写代码的时候写的是:
f = open(“文件一.txt”,‘r’) #只读的方式打开文件
那么后面你想进行write()的写操作是会报错的,因为mode里面声明了r只读模式,所以你没有写的权限,这一点要注意一下。
6.mode的其他操作模式
mode中有很多的操作模式,我们以表格的方式来看看:
| 模式 | 描述 |
| — | — |
| r | 以只读的形式打开文件,文件的指针在开头 |
| r+ | 读写,文件指针在开头 |
| rb | 以二进制的形式,只读文件指针在开头 |
| w | 只写,文件不存在,则创建新的,存在则覆盖,指针在开头 |
| w+ | 读写,文件不存在,则创建新的,存在则覆盖,指针在开头 |
| wb | 只写,以二进制的形式 |
| a | 追加模式,文件指针在结尾 |
| a+ | 读写,不存在则创建,存在直接追加 |
| ab | 以二进制形式追加 |
指针在这里可以理解为光标,它在哪里,你的操作就从哪里开始。
举例:新建1个名为 “test” 的.txt文件,第一次向里面写入aaa,第二次向里面写入bbb。
f = open(“test.txt”, ‘a+’)
f.write(“aaa”)
f.close()
f = open(“test.txt”) # 默认只读模式
print(f.read()) # 打印内容
f = open(“test.txt”, ‘a+’)
f.write(“bbb”)
f.close()
f = open(“test.txt”) # 默认只读模式
print(f.read()) # 再次打印内容
运行结果:
aaa
aaabbb
[](
)(三)文件的方法与属性
1.file的对象属性
有三个常用的方法可用于查看文件对象的属性:
- closed
如果文件对象已关闭,返回True,否则返回False
- mode
返回文件对象的访问模式
- name
返回文件的名称
案例:对文件进行操作(随意),查看被操作的文件名、操作模式和是否关闭。
f = open(“test.txt”, ‘a+’)
f.write(“aaa”)
f.close()
print(f.closed) #查看是否关闭
print(f.name) #查看文件名字
print(f.mode) #查看操作模式
运行结果:
True
test.txt
a+
2.file的对象方法
文件的方法有很多,前面我们已经讲过一点,比如read()和write(),但还有一些常用的方法需要掌握的,比如下面的:
- close()
关闭文件—非常重要
- read([count])
读取文件中的内容
count:字节数量
- readlines()
读取所有内容,打包成列表
- readline()
读取一行数据,追加读取,读取过的不能再次读取
- seek(offset,[from])
修改指针的位置:从from位置移动了offset个字节
from:0则表示从起始位置,1则表示从当前位置开始,2则表示从末尾开始
oofset:要移动的字节数
- write()
向文件中写入内容
举例:向test.txt文件中写入aaabbbccc,将文件中的内容输出为列表。
f = open(“test.txt”, ‘a+’)
f.write(“aaabbbccc”)
f.close()
f = open(“test.txt”)
print(f.readlines())
f.close()
运行结果:
[‘aaabbbcccaaabbbccc’]
[](
)(四)os模块
os模块是一个用于访问操作系统的模块,在进行文件操作的时候常会用到它。模块在使用之前要进行导入。
import os
1.关于文件的功能
1.os.rename(原文件名,新的文件名) ——文件重命名
2.os.remove(文件名) ——删除文件
如果不说明路径,则在源代码所在文件夹下寻找,寻找不到会报错。
若想删除指定文件夹下的文件,文件名则需要具体路径,例如 os.remove(r"D:\test_1\文件名"),r防止斜杠发生转义
举例:已有文件test1.txt,将其修改成test20.txt。
import os
os.rename(“test1.txt”,“test20.txt”)
运行结果:

2.文件夹的功能
1.os.mkdir(文件夹名) ——创建文件夹
2.os.rmdir(文件夹名) ——删除文件夹
3.os.getced() ——获取当前目录
4.os.chdir(目录) ——切换目录
5.os.listdir(目录) ——获取当前文件夹下所有的文件或者文件夹,返回一个列表
os.listdir(“aa”) #获取aa文件夹下的所有文件或文件夹,返回一个列表
举例:在现有文件夹venv里面新建一个新建文件夹。
import os
os.chdir(r"D:\文件\venv") #切换到venv文件夹下,r是防止转义
os.mkdir(“新建文件夹”) #在venv文件夹下创建一个新建文件夹
print(os.getcwd()) #输出当前目录位置
运行结果:

[](
)四、异常
==============================================================
[](
)⚡(一)异常的定义
异常是一个事件,该事件在程序执行过程中发生,影响程序的正常执行。一般情况下,Python无法正常处理程序时就会发生一个异常。
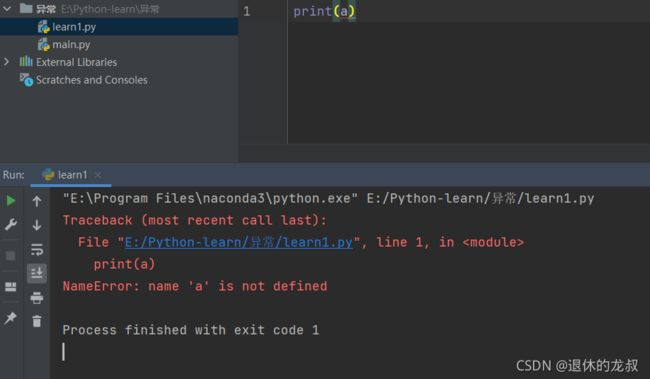
例如我在代码中只写了一个变量a,运行程序,pycharm无法识别这个变量,所以报错,便是出现了异常。

[](
)⚡(二)异常的处理
所以我们需要掌握处理异常的方法,处理异常的方法有很多种,接下来我们一个个来看。
[](
)1.try-except
它能够将可能出错的代码进行处理,处理后报错的红色字体将会转换成简短的、正常的字体,用法如下:
try:
有可能出现异常的代码
except 异常类型 as 变量
处理后的代码
举例:直接打印变量a会报错。
经过tyr-except处理过一下:
try:
print(a)
except NameError as s:
print(s)
再次运行看效果:
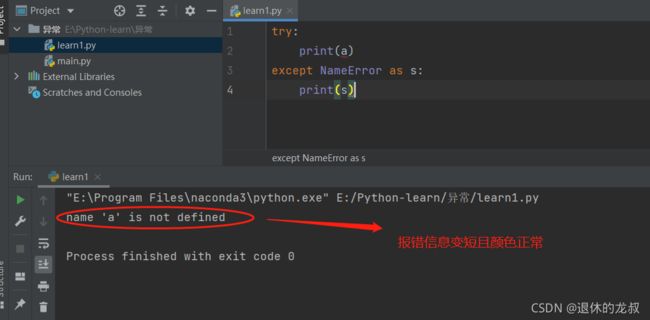
飘红的报错信息变得简短且颜色正常,看起来这个异常是不是显得舒服多了?
这里的tyr-except并不影响代码的运行,如果你的代码没有报错,你就算是写了tyr-except,它也只会执行try那行代码,那行代码没有错误,那就不会执行except里面的代码。
例如我们来一个正常的:

[](
)2.try-except-except
这种方法和前面的try-except写法是差不多的,只是后面再增加了一个except,可用于判断多种可能报错的情况。
例如:有两行代码可能会报错,两种不同类型的异常,但不想让它飘红。
try:
1 / 0
print(a)
except NameError as s: # 第一种写法,用as+变量
print(s)
except ZeroDivisionError: # 第二种写法,自定义输出内容
print(“除数不能为0”) # 自定义输出的内容
运行结果:
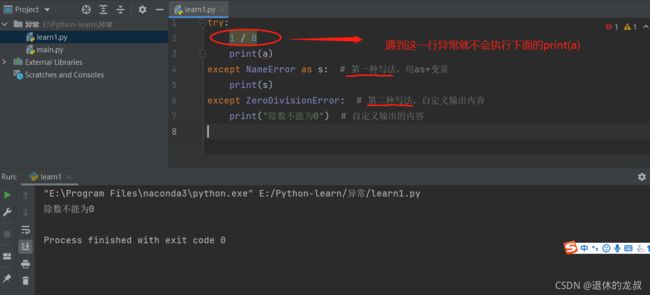
虽然报错,但没有飘红,这里注意一下except的两种写法。
try-except的写法很灵活的,我们同样可以用元组把可能报错的异常类型囊括进去,避免写多行except,例如:

[](
)3.try-except-else
如果没有异常,则执行else里面的代码,例如:
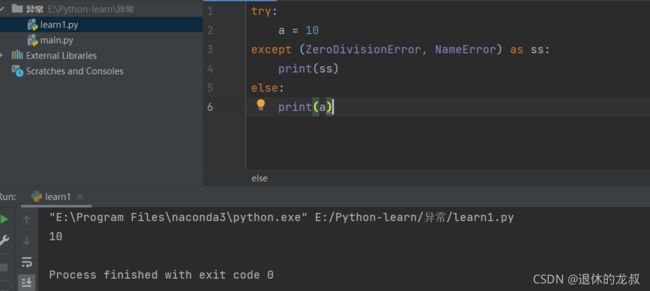
[](
)4.try-except-finally
不管代码是否有异常,最后都会执行finally里面的代码。例如:

[](
)5.顶层类Exception
except后面其实可以不加错误类型,因为系统会默认认为后面的错误是类型是Exception,这是1个顶层类,包含了所有的出错类型。
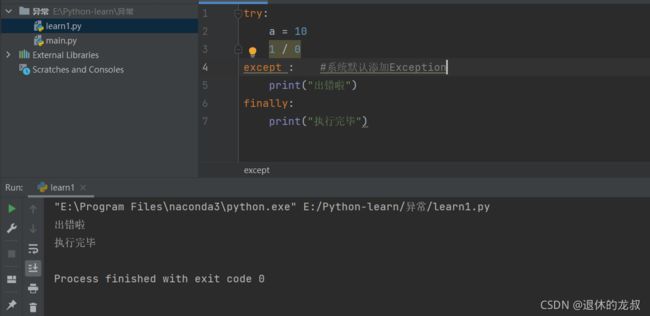
[](
)⚡(三)自定义异常
有没有发现,前面我们去做基本的异常捕获时,每次可能出错的地方就得写一个try-except,如果有多个地方可能会出错呢?是否我们需要写多个try-except?又或者理论上代码可以运行,但我想定一下规矩,凡是不符合我规矩的行为,我都让它出现异常,比如密码长度超出我规定的长度,我想让程序出现异常。
自定义异常可用于引发一个异常(抛出一个异常),由关键字raise引发。
举例:模拟用户输入密码的情景,用户输入的密码不能低于6位数,自定义一个异常,用于检测用户输入的密码是否符合规定,不符合则引发异常,提示当前输入的密码长度和最小密码长度不能低于6位数。
class MyError(Exception): # 异常捕获的类
def init(self, length, min_len): # length为用户输入的密码长度,min_len为规定的最小长度
self.length = length
self.min_len = min_len
设置抛出异常的描述信息
def str(self):
return “你输入的长度是%s,不能少于%s” % (self.length, self.min_len)
def main():
try:
con = input(“请输入密码:”) # 获取用户输入的密码
l = len(con) # 获取用户输入的密码长度
if l < 6:
raise MyError(l, 6) # 长度低于设定的6位数则引发异常
except Exception as ss: # 有错误则提示
print(ss)
else:
print(“您的密码输入完毕”) # 没有错误则执行
main()
运行结果:
从上面的代码中我们又用到了之前面向对象板块里面的类和实例对象的知识,忘记的赶紧去复习吧,除此之外,这里还结合了前面的try-except,还有我们的关键字raise引起异常捕获。
[](
)五、正则表达式
=================================================================
[](
)✈️(一)re模块
在讲正则表达式之前,我们首先得知道哪里用得到正则表达式。正则表达式是用在findall()方法当中,大多数的字符串检索都可以通过findall()来完成。
1.导入re模块
在使用正则表达式之前,需要导入re模块。
import re
2.findall()的语法:
导入了re模块之后就可以使用findall()方法了,那么我们必须要清楚findall()的语法是怎么规定的。
findall(正则表达式,目标字符串)
不难看出findall()的是由正则表达式和目标字符串组成,目标字符串就是你要检索的东西,那么如何检索则是通过正则表达式来进行操作,也就是我们今天的重点。
使用findall()之后返回的结果是一个列表,列表中是符合正则要求的字符串
[](
)✈️(二)正则表达式
[](
)1.字符串的匹配
(1)普通字符
大多数的字母和字符都可以进行自身匹配。
import re
a = “abc123±*”
b = re.findall(‘abc’,a)
print(b)
输出结果:
[‘abc’]
(2)元字符
元字符指的是. ^ $ ? + {} \ []之类的特殊字符,通过它们我们可以对目标字符串进行个性化检索,返回我们要的结果。
这里我给大家介绍10个常用的元字符以及它们的用法,这里我先给大家做1个简单的汇总,便于记忆,下面会挨个讲解每一个元字符的使用。
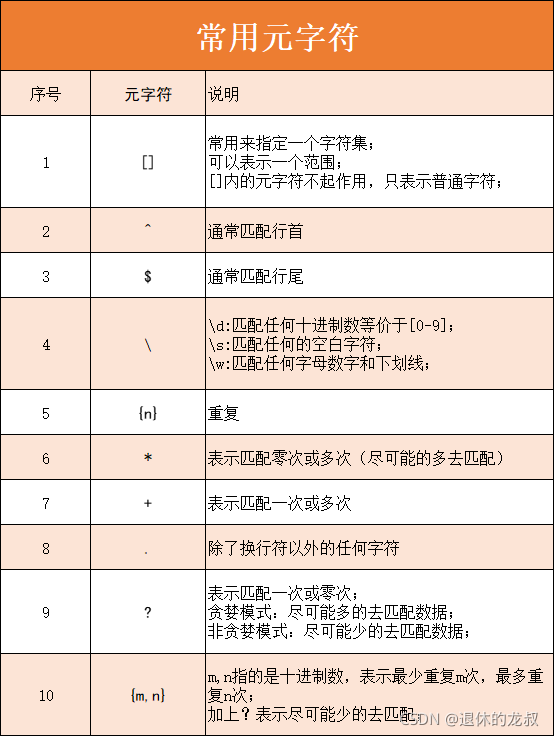
** 1️⃣ []**
[] 的使用方式主要有以下三种:
- 常用来指定一个字符集。
s = “a123456b”
rule = “a[0-9][1-6][1-6][1-6][1-6][1-6]b” #这里暂时先用这种麻烦点的方法,后面有更容易的,不用敲这么多[1-6]
l = re.findall(rule,s)
print(l)
输出结果为:
[‘a123456b’]
- 可以表示一个范围。
例如要在字符串"abcabcaccaac"中选出abc元素:
s = “abcabcaccaac”
rule = “a[a,b,c]c” # rule = “a[a-z0-9][a-z0-9][a-z0-9][a-z0-9]c”
l = re.findall(rule, s)
print(l)
输出结果为:
[‘abc’, ‘abc’, ‘acc’, ‘aac’]
- [] 内的元字符不起作用,只表示普通字符。
例如要在字符串“caabcabcaabc”中选出“caa”:
print(re.findall(“caa[a,^]”, “caa^bcabcaabc”))
输出结果为:
[‘caa^’]
注意点:当在[]的第一个位置时,表示除了a以外的都进行匹配,例如把[]中的和a换一下位置:
print(re.findall(“caa[^,a]”, “caa^bcabcaabc”))
输出:
[‘caa^’, ‘caab’]
2️⃣^
^ 通常用来匹配行首,例如:
print(re.findall("^abca", “abcabcabc”))
输出结果:
[‘abca’]
3️⃣ $
$ 通常用来匹配行尾,例如:
print(re.findall(“abc$”, “accabcabc”))
输出结果:
[‘abc’]
4️⃣ \
反斜杠后面可以加不同的字符表示不同的特殊含义,常见的有以下3种。
- \d:匹配任何十进制数等价于[0-9]
print(re.findall(“c\d\d\da”, “abc123abc”))
输出结果为:
[‘c123a’]
\可以转义成普通字符,例如:
print(re.findall("^abc", “abcabc”))
输出结果:
[’^abc’, ‘^abc’]
5️⃣ s
匹配任何的空白字符例如:
print(re.findall("\s\s", “a c”))
输出结果:
[’ ', ’ ']
6️⃣ \w
匹配任何字母数字和下划线,等价于[a-zA-Z0-9_],例如:
print(re.findall("\w\w\w", “abc12_”))
输出:
[‘abc’, ‘12_’]
7️⃣ {n}
{n}可以避免重复写,比如前面我们用\w时写了3次\w,而这里我们这需要用用上{n}就可以,n表示匹配的次数,例如:
print(re.findall("\w{2}", “abc12_”))
输出结果:
[‘ab’, ‘c1’, ‘2_’]
8️⃣ *
*表示匹配零次或多次(尽可能的多去匹配),例如:
print(re.findall(“010-\d*”, “010-123456789”))
输出:
[‘010-123456789’]
9️⃣ +
+表示匹配一次或多次,例如
print(re.findall(“010-\d+”, “010-123456789”))
输出:
[‘010-123456789’]
.
.是个点,这里不是很明显,它用来操作除了换行符以外的任何字符,例如:
print(re.findall(".", “010\n?!”))
输出:
[‘0’, ‘1’, ‘0’, ‘?’, ‘!’]
1️⃣ 1️⃣ ?
?表示匹配一次或零次
print(re.findall(“010-\d?”, “010-123456789”))
输出:
[‘010-1’]
这里要注意一下贪婪模式和非贪婪模式。
贪婪模式:尽可能多的去匹配数据,表现为\d后面加某个元字符,例如\d*:
print(re.findall(“010-\d*”, “010-123456789”))
输出:
[‘010-123456789’]
非贪婪模式:尽可能少的去匹配数据,表现为\d后面加?,例如\d?
print(re.findall(“010-\d*?”, “010-123456789”))
输出为:
[‘010-’]
1️⃣2️⃣{m,n}
m,n指的是十进制数,表示最少重复m次,最多重复n次,例如:
print(re.findall(“010-\d{3,5}”, “010-123456789”))
输出:
[‘010-12345’]
加上?表示尽可能少的去匹配
print(re.findall(“010-\d{3,5}?”, “010-123456789”))
输出:
[‘010-123’]
{m,n}还有其他的一些灵活的写法,比如:
-
{1,} 相当于前面提过的 + 的效果
-
{0,1} 相当于前面提过的 ? 的效果
-
{0,} 相当于前面提过的 * 的效果
关于常用的元字符以及使用方法就先到这里,我们再来看看正则的其他知识。
[](
)✈️(三)正则的使用
[](
)1.编译正则
在Python中,re模块可通过compile() 方法来编译正则,re.compile(正则表达式),例如:
s = “010-123456789”
rule = “010-\d*”
rule_compile = re.compile(rule) #返回一个对象
print(rule_compile)
s_compile = rule_compile.findall(s)
print(s_compile) #打印compile()返回的对象是什么
输出结果:
[‘010-123456789’]
[](
)2.正则对象的使用方法
正则对象的使用方法不仅仅是通过我们前面所介绍的 findall() 来使用,还可以通过其他的方法进行使用,效果是不一样的,这里我做个简单的总结:
(1)findall()
找到re匹配的所有字符串,返回一个列表
(2)search()
扫描字符串,找到这个re匹配的位置(仅仅是第一个查到的)
(3)match()
决定re是否在字符串刚开始的位置(匹配行首)
就拿上面的 compile()编译正则之后返回的对象来做举例,我们这里不用 findall() ,用 match() 来看一下结果如何:
s = “010-123456789”
rule = “010-\d*”
rule_compile = re.compile(rule) # 返回一个对象
print(rule_compile)
s_compile = rule_compile.match(s)
print(s_compile) # 打印compile()返回的对象是什么
输出:
可以看出结果是1个match 对象,开始下标位置为0~13,match为 010-123456789 。既然返回的是对象,那么接下来我们来讲讲这个match 对象的一些操作方法。
[](
)3.Match object 的操作方法
这里先介绍一下方法,后面我再举例,Match对象常见的使用方法有以下几个:
(1)group()
返回re匹配的字符串
(2)start()
返回匹配开始的位置
(3)end()
返回匹配结束的位置
(4)span()
返回一个元组:(开始,结束)的位置
举例:用span()来对search()返回的对象进行操作:
s = “010-123456789”
rule = “010-\d*”
rule_compile = re.compile(rule) # 返回一个对象
s_compile = rule_compile.match(s)
print(s_compile.span()) #用span()处理返回的对象
结果为:
(0, 13)
[](
)4.re模块的函数
re模块中除了上面介绍的findall()函数之外,还有其他的函数,来做一个介绍:
(1)findall()
根据正则表达式返回匹配到的所有字符串,这个我就不多说了,前面都是在介绍它。
(2)sub(正则,新字符串,原字符串)
sub() 函数的功能是替换字符串,例如:
s = “abcabcacc” #原字符串
l = re.sub(“abc”,“ddd”,s) #通过sub()处理过的字符串
print(l)
输出:
ddddddacc #把abc全部替换成ddd
(3)subn(正则,新字符串,原字符串)
subn()的作用是替换字符串,并返回替换的次数
s = “abcabcacc” #原字符串
l = re.subn(“abc”,“ddd”,s) #通过sub()处理过的字符串
print(l)
输出:
(‘ddddddacc’, 2)
(4)split()
split()分割字符串,例如:
s = “abcabcacc”
l = re.split(“b”,s)
print(l)
输出结果:
[‘a’, ‘ca’, ‘cacc’]
[](
)六、进程线程
================================================================
[](
)(一)多任务操作系统
操作系统可以执行多个任务,比如我们的Windows系统,除了目前在执行的、你能看得到的几个任务,还有很多后台正在执行的任务,可以用Ctrl+Alt+Del键调出任务管理器看一下就知道了。

我的电脑配置经常会看到有几核处理器的属性,例如我的电脑是12核的,也就是说电脑最多能同时执行12个任务,最多运行12个进程同时进行。

但为什么我们的电脑却能够同时运行几百个任务呢?

其实这得益于于操作系统的任务调度,大部分的操作系统是采用抢占时间片的形式进行调度。系统在极其微小的时间内,在多个任务之间进行极快速的切换,比如说8核的操作系统理论上1秒钟之内只能同时执行8个任务,但是系统在1秒钟之内可能在上百个任务之间进行切换,A任务执行一下、B任务执行一下、C任务执行一下…结果1秒钟之内很多任务都能被执行到,造成了肉眼可见的几百个任务在一直执行。
术语叫“宏观并行,微观串行”,实际上电脑在极端的时间内只能执行不超过配置核数的任务数,8核还是只能执行8个任务。

[](
)1.何为进程?
既然讲到了任务,那么进程就是任务,1个进程就相当于1个任务,是操作系统分配资源的最小单位。在python中,想要实现多任务可以使用进程来完成,进程是实现多任务的一种方式。
[](
)2.何为线程?
进程的多个子任务就称之为线程,线程是进程的最小执行单位, 一个进程可以有很多线程,每个线程执行的任务都不一样。

Python既支持多进程又支持多线程,接下来我们就开始进入Python的进程与线程的学习。
[](
) (二)Python的多进程multiprocessing(包)
如果你利用多进程,你的Python代码是从头到尾逐行执行的,这其实就是在执行1个进程,这一点应该很好理解。
要想更多利用CPU资源,我们可以利用多进程,这里介绍一个Python多进程时常用的包multiprocessing,它拥有很多的功能,比如子进程、通讯、共享、执行不同的形式等等,我们来了解一些常用的。
[](
)1.Process——进程类
Process是multiprocessing里面的一个进程类,通过它就能实现多进程。我们先来看一下它的用法,后面我们会有实际的例子去讲述。
Process(target,name,args,kwargs)
-
target是目标,在哪里新开进程让系统去执行?得给系统一个目标。
-
name是进程的名字,你可以设置也可以不设置,默认是Process-N,N是从1,2,3…N,系统默认从小到大取名。
-
args和kwargs是参数,可用于传递到目标。
Process里面有很多方法,其中最常用的就是start()启动进程的方法。
进程名.start() #开始进程
举例:写好的代码如下,我想看看开启和没开启多进程调用函数的效果。
import time
#2个要同时执行的函数
def music() :
for i in range(5): #执行5次
print(“听音乐中…”)
time.sleep(0.2) #延迟0.2s,目的是让效果对比更明显一些
def movie():
for i in range(5):
print(“看视频中…”)
time.sleep(0.2) #延迟0.2s
music()
movie()
print(“主进程执行完毕”)
在没有开启多进程时,执行效果如下:
可以看到,这是很正常的运行情况,程序从上运行到下,逐行运行,music()里面的三次循环没有执行完毕就不会执行movie()里面,以及这两个函数如果没有执行完毕,就不会执行最后一行的print(“主进程执行完毕”)。
我们再来看在上面案例的代码中加入多进程:
import time
import multiprocessing
2个要同时执行的函数
def music():
for i in range(5): # 执行5次
print(“听音乐中…”)
time.sleep(0.2) # 延迟0.2s,目的是让效果对比更明显一些
def movie():
for i in range(5):
print(“看视频中…”)
time.sleep(0.2) # 延迟0.2s
if name == “main”: # 解决Windows系统下调用包时的递归问题
创建子进程
music_process = multiprocessing.Process(target=music)
movie_process = multiprocessing.Process(target=movie)
启用进程
music_process.start()
movie_process.start()
print(“主进程执行完毕”)
代码中我加入了一个if语句来判断__name__这个,为什么?因为在Windows系统下, multiprocessing这个包会发生递归现象,就是会在“导入模块—调用模块”之间反复执行,不信你可以把if语句去掉,把里面的代码全部放到外面来执行就会报错,这是Windows系统下会发生的一个现象,mac、linux等系统是不用加ifl来做判断的。
关于__name__ = "main"这个知识点我在模块与包的初始化时候有讲过,不懂的可以回去看一下。
运行效果:
可以看出来,这开启进程之后,代码运行时是有3个进程同时进行的,一个是从上往下执行的主进程,执行到下面输出“主进程执行完毕”,另外两个子进程去执行music()和movie()进程,从他们的执行速度来看,它们是同时在进行的,所以没有像刚才那样非要等其中一个函数里面的代码执行3遍才开始第2个函数。
同样的代码,你们的执行效果可能会跟我有所差异,因为效果是根据系统当前的状况去随机分配的,但并不影响你能看出来它的结果是多线程在进行。
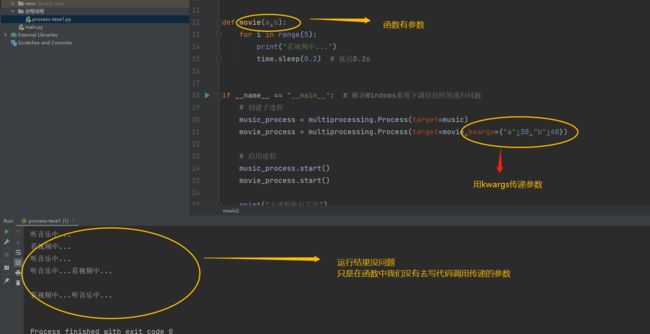
最后补充一下,前面我们讲过Process里面有args和kwargs可进行参数传递,args是普遍参数的传递,kwargs是以字典的形式进行参数传递,我们还是以上面的代码为例,进行一下有参数传递的多进行。
[](
)2.获取当前进程的编号
前面我们讲到了代码执行时有多个进程在同时进行任务,那么怎么样查看当前进程的编号来得知目前有哪些进程在运行呢?哪些是主进程哪些是子进程呢?3个方法,我们先来看一下方法,后面再结合例子一起使用。
(1)获取当前进程的编号:
需要用到一个os模块里面的getpid()方法,用法如下:
os.getpid()
(2)获取当前进程的名字
这里用的还是multiprocessing包,里面有个current_process()的方法,用法如下:
multiprocessing.current_process()
(3)获取当前父进程(主进程)的编号
子进程是属于哪个父进程的?这个用的是os模块里面的getppid() ,用法如下:
os.getppid()

那么方法都看到了,我们来在刚才的例子的基础上,获取并打印一下当前进程的名字、编号以及父进程的编号。
import time
import multiprocessing
import os
2个要同时执行的函数
def music():
print(“music子进程名字:”, multiprocessing.current_process())
print(“music子进程编号:”, os.getpid())
print(“music所属主进程的编号:”, os.getppid())
for i in range(5): # 执行5次
print(“听音乐中…”)
time.sleep(0.2) # 延迟0.2s,目的是让效果对比更明显一些
def movie(a, b):
print(“movie子进程名字:”, multiprocessing.current_process())
print(“movie子进程编号:”, os.getpid())
print(“movie所属主进程的编号:”, os.getppid())
for i in range(5):
print(“看视频中…”)
time.sleep(0.2) # 延迟0.2s
if name == “main”: # 解决Windows系统下调用包时的递归问题
创建子进程
music_process = multiprocessing.Process(target=music)
movie_process = multiprocessing.Process(target=movie, kwargs={“a”: 30, “b”: 40})
启用进程
music_process.start()
movie_process.start()
print(“主进程编号:”,os.getpid())
运行结果:
可以只要我们使用获取线程的方法的线程,都能被打印出来编号和名字。
[](
) (三)多线程Threading模块
多进程能同时运行几个任务,前面我们讲过进程的最小单位是线程,那么线程也同样可以进行多个任务。如果一个进程只有1个任务(主进程),那么也可以说是只有1个线程,就比如我们不使用多进程运行代码的时候,这时候就可以说1个主进程或1个主线程。
[](
)1.多线程的类Thread类
多线程常用的一个模块是threading,里面有个教Thread的类,跟前面我们将多进程时用到的Process类差不多,我们先来看看用法:
Thread(target=None,name=None,args=(),kwargs=None)
-
target:可执行目标
-
name:线程的名字默认Thread-N
-
args/kwargs:目标参数
同样的,多线程也要有开启的方法,跟前面的也差不多:
start()
还有获取线程名字的方法:
threading.current_thread()
知道了这些知识点,我们开始举例:用跟上面差不多的例子去使用一下我们的多线程。
import threading,time
def music(name,loop):
for i in range(loop):
print(“听音乐 %s , 第%s次”%(name,i))
time.sleep(0.2)
def movie(name,loop):
for i in range(loop):
print(“看电影%s , 第%s次”%(name,i))
time.sleep(0.2)
if name ==“main”:
music_thread = threading.Thread(target=music,args=(“最亲的人”,3))
movie_thread = threading.Thread(target=movie,args=(“唐探2”,3))
music_thread.start()
movie_thread.start()
print(“主线程执行完毕”)
运行结果:
听音乐 最亲的人 , 第0次
看电影唐探2 , 第0次
主线程执行完毕
听音乐 最亲的人 , 第1次看电影唐探2 , 第1次
看电影唐探2 , 第2次听音乐 最亲的人 , 第2次
可以看出来,我们的多线程其实是跟多进程差不多的,同样可以运行多个任务,这里我们还增加了参数的使用。

[](
)2.继承Thread类
我们除了用上面的方法实现多线程任务,还可以用继承类的方式去实现多线程。
举例:通过多线程的方式,去打印“凉凉”和“头发没了"。
import threading,time
#多线程的创建
class MyThread(threading.Thread):
def init(self,name): #初始化
super().init() #调用父类Thread的初始化方法
self.name = name #name变成实例属性
def run(self):
#线程要做的事情
for i in range(5):
print(self.name)
time.sleep(0.2)
#实例化子线程
t1 = MyThread(“凉凉”)
t2 = MyThread(“头发没了”)
t1.start()
t2.start()
MyThread这个类是我们自己创建的,它是继承于父类threading.Thread ,同时我们需要写上MyThread的初始化方法,每当被调用的时候把准备工作做好,super().int() 这个我们也讲过了,在前面的面向对象时有讲过,不懂的可以去看看面向对象那篇文章的内容。
运行结果:
凉凉
头发没了
凉凉
头发没了
凉凉头发没了
凉凉头发没了
凉凉
头发没了
随机效果是有的,你们的效果和我的可能会不一样,每台电脑在运行多线程代码时,哪个线程能够抢到时间片谁就先执行。
通过类Thread继承一样可以实现多线程。
[](
)七、容器/迭代对象/生成器
=======================================================================
[](
) (一)容器
在Python中,容器是把多种元素组织在一起的数据结构,容器中的元素就可以逐个迭代获取。说白了,它的作用就像它的名字一样:用来存放东西(数据)。
容器实际上是不存在的,它并不是一种数据类型,只是人为的一种概念,只是为了方便学习所创造的一个概念词,它可以用成员关系操作符(in或not in)来判断对象是否在容器里面。
当然了,它不是我创造的,我没有那么大本事哈,是官方创造的好吧,你也不用担心我是在教你一些奇奇怪怪的名词,说出去别人都听不懂…python中都是这么叫的。

常见的容器类型有列表(list)、元组(tuple)、字符串(str)、字典(dict)以及集合(set )。
既然容器里面的数据是可以迭代获取的,那么我们又得来学一个新概念:可迭代对象。
[](
) (二)可迭代对象
什么是可迭代对象?
在python中,可迭代对象并不是指某种具体的数据类型,它是指存储了元素的一个容器对象。
也就是说,如果容器里面没有存储数据,那它就不是可迭代对象,并不是所有的容器都是可迭代对象,容器包含但并不仅限于可迭代对象。
注意两个点:
1.很多容器都是可迭代对象(容器包含了可迭代对象)。
2.一个可迭代对象是不能独立的进行迭代的,迭代是通过for来完成的,凡是可迭代对象都可以直接使用for循环进行访问。
for循环大家应该不陌生吧?有没有想过,for循环内部是怎么实现的?比如说这个for循环的例子,为什么能输出列表里的每一个元素?它的内部是怎么实现的?

其实for循环做了两件事情:
1.使用 iter() 返回1个迭代器,迭代器在下面会讲,这里先知道有这么个东西。
2.使用 next() 获取迭代器中的每一个元素。
那么我们不用for循环来输出列表里的每一个元素,
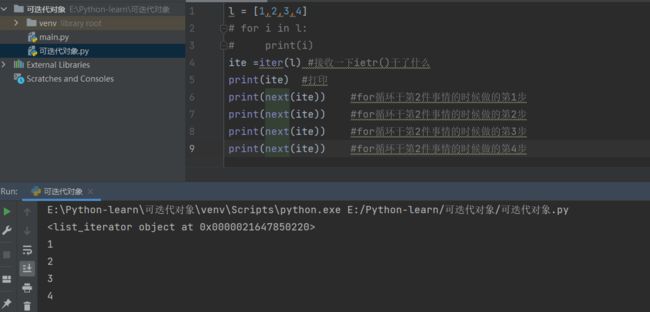
l = [1,2,3,4]
for i in l:
print(i)
ite =l.iter() #接收一下ietr()干了什么
print(ite) #打印
print(ite.next()) #for循环干第2件事情的时候做的第1步
print(ite.next()) #for循环干第2件事情的时候做的第2步
print(ite.next()) #for循环干第2件事情的时候做的第3步
print(ite.next()) #for循环干第2件事情的时候做的第4步
输出结果:
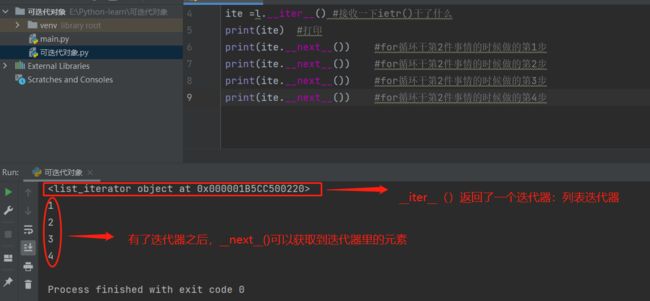
可以看出来,如果我们去掉哪行打印ite的代码,执行效果就是跟for循环输出列表里面的每一个元素是一样的,for循环里面限定了范围是4次,实际上就执行了1次__iter__()和4次__next__(),也就是说for循环访问迭代对象的本质就是通过这么去实现的。
而且,for循环本质上干的那两件事情,缺一不可,也就是说如果没有__iter__()先返回了迭代器,__next()__也无法获取到元素,恰恰说明了前面说要注意的两点中的第2点:一个可迭代对象是不能独立的进行迭代的。
有两个内置函数跟它们原理是一样的,本质相同,一般要用的话用内置函数要方便一些,起码不用写那么多下划线:
内置函数 iter() 的本质是 inter() ,也是返回一个迭代器。
内置函数 next() 的本质是 next(),也是有了迭代器之后获取元素。
可以看出来结果也是一模一样的,既然讲到了迭代器,那么就来看看什么是迭代器。

[](
) (三)迭代器
通过上面的for循环例子我们大概也能看得出来,
只要是实现了__iter__()和__next__()的对象,就是迭代器,迭代器是一个可迭代对象。
总之,迭代器是有__iter__()生成,可以通过__next__()进行调用。
既然如此,我们在学Python基础的时候讲过range()是一个可迭代对象,那么它也是可以通过__iter__()生成一个迭代器的。

[](
) (四)序列
序列在【赋值语句】那个专题文章中我有提过,这里再讲一下,序列也是一个抽象的概念,它包含了列表、元组和字符串,它本身是不存在的,也是便于学习所创造的一个概念词。
可迭代对象包含序列,既然序列包含了列表、元组和字符串,前面我们的例子中也涉及到 了,所以说序列可以被iter()和next()使用。
序列可以分为有限序列和无限序列。有限序列就是有范围的,比如说range(10)就已经限定了范围,相反的,无限序列也就是没有限定范围的序列。
我们来生成一个无限序列,这里需要用到1个新模块itertools,itertools用于高效循环的迭代函数集合,它下面有一个方法count(),可生成迭代器且无范围,可以理解为无限迭代器。
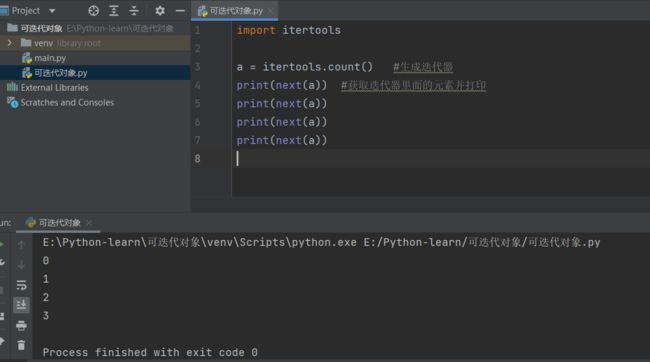
通过这个例子我们可以看出来,只要执行一次,next()就会获取一次迭代器里面的内容并逐次获取,我这里只写了4个next(),你多写几次就会多输出几次。
像next()这种什么时候需要就什么时候调用的机制叫做懒加载机制,也叫懒汉式加载;
相反地就有饿汉式加载。比如for循环这种的,只要一执行就会把可迭代器里面的所有对象都获取。
[](
) (五)列表推导式
列表推导式跟生成器有关,在讲生成器之前,需要先知道什么是列表推导式,列表推导式就是生成列表的一种方法,语法是这样的:
l = [i for i in 可迭代对象]
i表示要放进列表里的对象,for循环是一个式子。
比如我们用列表推导式来生成一个列表试试:
l = [i for i in range(5)]
print(l)
运行结果:
[0, 1, 2, 3, 4]
运用列表推导式可以很方便地生成我们想要的列表。
同时它也有很多灵活的用法,比如在后面加上条件判断
l = [i for i in range(5) if 4<5]
print(l)
运行结果:
[0, 1, 2, 3, 4]
if后面的条件判断为真,则可以正常生成列表,如果为假,则列表推导式是无效的,此时的l将是一个空列表。
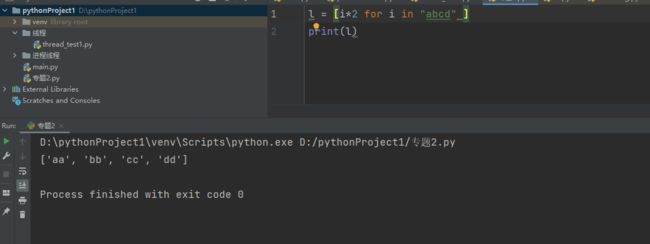
还有其他灵活的用法,比如操作前面的i,比如让i的数值全都翻2倍:

我们把迭代对象换一下,换成字符串,也同样可以输出,只是*在字符串里面表示重复操作符,所以效果变成了这样:
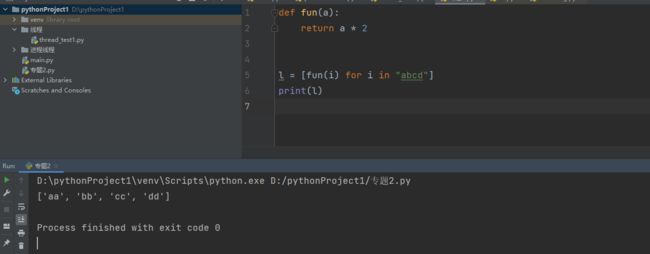
不仅如此,前面的i*2我们还可以用函数来进行操作,比如:
总而言之,列表推导式就是用来快速和自定义生成列表的一种方法,很灵活。
那么有人可能会举一反三了,列表推导式都是用 [] 来进行操作的,那如果用()来操作行吗?它会不会生成一个元组?我们来看看:
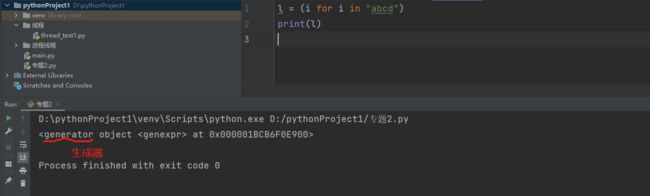
[] 换成()之后,返回的是一个生成器generrator ,那么下面我们再来讲讲生成器:
[](
) (六)生成器
生成器是真实存在于Python中的对象,与容器这种概念词是不同的,它是可以直接通过next()进行调用的。
[](
)1.生成器的第一种创建方法:生成器表达式
第一种创建方法跟列表推导式是差不多的,就是 [] 换成了():
l = (i for i in 可迭代对象)
比如我们来生成一个生成器,看看能不能用next()直接调用:
l = (i for i in “abcd”)
print(next(l))
运行结果:
a
可以看出,生成器是可以直接调用的。那么既然生成器可以被next()调用,那么生成器就是一个特殊的迭代器,是一个可迭代对象。
[](
)2.生成器的第二种创建方法:yield
除了用上面那种方法创建生成器,还可以用yield来创建,方法如下:
yield 关键字
比如说我们用一个函数中包含yield来创建生成器:
def fun():
a = 10
while 1:
a += 1
yield a
b = fun()
print(b)
运行结果:
最后
硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
xt__(),也就是说for循环访问迭代对象的本质就是通过这么去实现的。
而且,for循环本质上干的那两件事情,缺一不可,也就是说如果没有__iter__()先返回了迭代器,__next()__也无法获取到元素,恰恰说明了前面说要注意的两点中的第2点:一个可迭代对象是不能独立的进行迭代的。
有两个内置函数跟它们原理是一样的,本质相同,一般要用的话用内置函数要方便一些,起码不用写那么多下划线:
内置函数 iter() 的本质是 inter() ,也是返回一个迭代器。
内置函数 next() 的本质是 next(),也是有了迭代器之后获取元素。
可以看出来结果也是一模一样的,既然讲到了迭代器,那么就来看看什么是迭代器。
[](
) (三)迭代器
通过上面的for循环例子我们大概也能看得出来,
只要是实现了__iter__()和__next__()的对象,就是迭代器,迭代器是一个可迭代对象。
总之,迭代器是有__iter__()生成,可以通过__next__()进行调用。
既然如此,我们在学Python基础的时候讲过range()是一个可迭代对象,那么它也是可以通过__iter__()生成一个迭代器的。
[](
) (四)序列
序列在【赋值语句】那个专题文章中我有提过,这里再讲一下,序列也是一个抽象的概念,它包含了列表、元组和字符串,它本身是不存在的,也是便于学习所创造的一个概念词。
可迭代对象包含序列,既然序列包含了列表、元组和字符串,前面我们的例子中也涉及到 了,所以说序列可以被iter()和next()使用。
序列可以分为有限序列和无限序列。有限序列就是有范围的,比如说range(10)就已经限定了范围,相反的,无限序列也就是没有限定范围的序列。
我们来生成一个无限序列,这里需要用到1个新模块itertools,itertools用于高效循环的迭代函数集合,它下面有一个方法count(),可生成迭代器且无范围,可以理解为无限迭代器。
通过这个例子我们可以看出来,只要执行一次,next()就会获取一次迭代器里面的内容并逐次获取,我这里只写了4个next(),你多写几次就会多输出几次。
像next()这种什么时候需要就什么时候调用的机制叫做懒加载机制,也叫懒汉式加载;
相反地就有饿汉式加载。比如for循环这种的,只要一执行就会把可迭代器里面的所有对象都获取。
[](
) (五)列表推导式
列表推导式跟生成器有关,在讲生成器之前,需要先知道什么是列表推导式,列表推导式就是生成列表的一种方法,语法是这样的:
l = [i for i in 可迭代对象]
i表示要放进列表里的对象,for循环是一个式子。
比如我们用列表推导式来生成一个列表试试:
l = [i for i in range(5)]
print(l)
运行结果:
[0, 1, 2, 3, 4]
运用列表推导式可以很方便地生成我们想要的列表。
同时它也有很多灵活的用法,比如在后面加上条件判断
l = [i for i in range(5) if 4<5]
print(l)
运行结果:
[0, 1, 2, 3, 4]
if后面的条件判断为真,则可以正常生成列表,如果为假,则列表推导式是无效的,此时的l将是一个空列表。
还有其他灵活的用法,比如操作前面的i,比如让i的数值全都翻2倍:
我们把迭代对象换一下,换成字符串,也同样可以输出,只是*在字符串里面表示重复操作符,所以效果变成了这样:
不仅如此,前面的i*2我们还可以用函数来进行操作,比如:
总而言之,列表推导式就是用来快速和自定义生成列表的一种方法,很灵活。
那么有人可能会举一反三了,列表推导式都是用 [] 来进行操作的,那如果用()来操作行吗?它会不会生成一个元组?我们来看看:
[] 换成()之后,返回的是一个生成器generrator ,那么下面我们再来讲讲生成器:
[](
) (六)生成器
生成器是真实存在于Python中的对象,与容器这种概念词是不同的,它是可以直接通过next()进行调用的。
[](
)1.生成器的第一种创建方法:生成器表达式
第一种创建方法跟列表推导式是差不多的,就是 [] 换成了():
l = (i for i in 可迭代对象)
比如我们来生成一个生成器,看看能不能用next()直接调用:
l = (i for i in “abcd”)
print(next(l))
运行结果:
a
可以看出,生成器是可以直接调用的。那么既然生成器可以被next()调用,那么生成器就是一个特殊的迭代器,是一个可迭代对象。
[](
)2.生成器的第二种创建方法:yield
除了用上面那种方法创建生成器,还可以用yield来创建,方法如下:
yield 关键字
比如说我们用一个函数中包含yield来创建生成器:
def fun():
a = 10
while 1:
a += 1
yield a
b = fun()
print(b)
运行结果:
最后
硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。