提取mdx字典文件中的数据
1.使用GetDict将.mdx文件转换为.txt文件
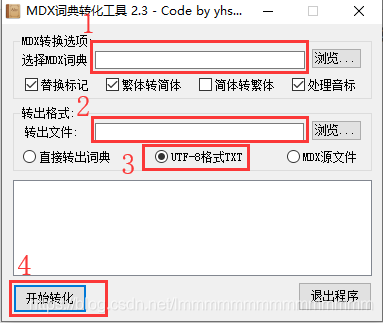
得到的文件:
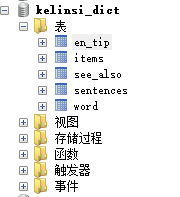
2.数据库设计

CREATE TABLE `word` (
`wid` int(11) NOT NULL AUTO_INCREMENT,
`word_en` varchar(255) DEFAULT NULL,
`star` varchar(255) DEFAULT NULL,
PRIMARY KEY (`wid`)
) ENGINE=InnoDB AUTO_INCREMENT=34415 DEFAULT CHARSET=utf8
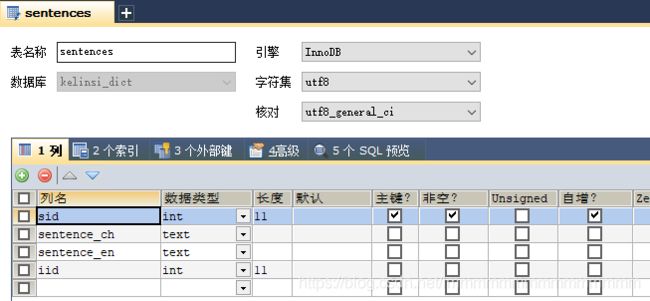
CREATE TABLE `sentences` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`sentence_ch` text,
`sentence_en` text,
`iid` int(11) DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=90608 DEFAULT CHARSET=utf8

CREATE TABLE `see_also` (
`sid` int(11) NOT NULL AUTO_INCREMENT,
`number` varchar(255) DEFAULT NULL,
`word_en` varchar(255) DEFAULT NULL,
`wid` varchar(255) DEFAULT NULL,
PRIMARY KEY (`sid`)
) ENGINE=InnoDB AUTO_INCREMENT=2159 DEFAULT CHARSET=utf8

CREATE TABLE `items` (
`iid` int(11) NOT NULL AUTO_INCREMENT,
`number` int(11) DEFAULT NULL,
`label` varchar(255) DEFAULT NULL,
`word_ch` varchar(255) DEFAULT NULL,
`explanation` text,
`gram` varchar(255) DEFAULT NULL,
`wid` int(11) DEFAULT NULL,
PRIMARY KEY (`iid`)
) ENGINE=InnoDB AUTO_INCREMENT=64250 DEFAULT CHARSET=utf8
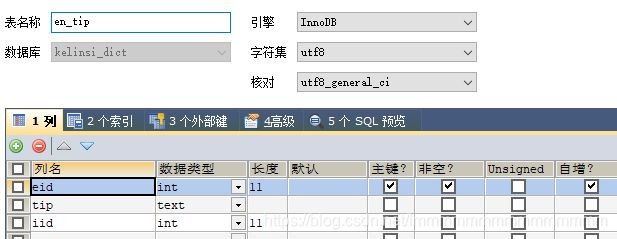
CREATE TABLE `en_tip` (
`eid` int(11) NOT NULL AUTO_INCREMENT,
`tip` text,
`iid` int(11) DEFAULT NULL,
PRIMARY KEY (`eid`)
) ENGINE=InnoDB AUTO_INCREMENT=2460 DEFAULT CHARSET=utf8
3.使用Python提取其中的数据,并存入数据库
# -*- coding:utf-8 -*-
import pymysql
import json
from lxml import etree
word_list = []
def getdata(filename):
num = 0
f = open(filename, 'r', encoding='utf-8')
s = f.readline()
while s != "":
word = {}
object = etree.HTML(s)
word_en = object.xpath('//span[@class="C1_word_header_word"]/text()')[0]
print("正在解析:", word_en)
word.update({"word_en": word_en})
star = object.xpath('//span[@class="C1_word_header_star"]/text()')
if len(star) == 0:
word.update({"star": ""})
else:
word.update({"star": star[0]})
explanation_items = object.xpath('//div[@class="C1_explanation_item"]')
items = []
for explanation_item in explanation_items:
item = {}
explanation_box = explanation_item.xpath('div[@class="C1_explanation_box"]')
if len(explanation_box) == 0:
continue
explanation_box = explanation_box[0]
# 解释编号
item_number = explanation_box.xpath('span[@class="C1_item_number"]//text()')
if len(item_number) == 0:
item.update({"number": ""})
else:
item.update({"number": item_number[0]})
# 标签 list
explanation_label_list = explanation_box.xpath('span[@class="C1_explanation_label"]/text()')
if len(explanation_label_list) != 0: # 正常的item
# 标签
explanation_label = explanation_label_list[0]
item.update({"label": explanation_label})
# 单词的中文意思
if len(explanation_box.xpath('span[@class="C1_text_blue"]/text()')) != 0:
word_ch = explanation_box.xpath('span[@class="C1_text_blue"]/text()')[0]
item.update({"word_ch": word_ch})
else:
item.update({"word_ch": ""})
# 单词的解释
explanation = ''.join(explanation_box.xpath('text()|span[@class="C1_inline_word"]/text()'))
item.update({"explanation": explanation})
# 单词语法
word_gram = explanation_box.xpath('span[@class="C1_word_gram"]/text()')
if len(word_gram) == 0:
item.update({"word_gram": ""})
else:
item.update({"word_gram": word_gram[0]})
# 例句
sentences = explanation_item.xpath('ul/li')
sentence_list = []
en_tip_list = []
for sentence in sentences:
# en_tip
if len(sentence.xpath('p')) == 0:
en_tip = ''.join(sentence.xpath('.//text()'))
en_tip_list.append(en_tip)
elif len(sentence.xpath('p')) == 2:
sentence_dict = {}
# 英文例句
sentence_en = ''.join(sentence.xpath('p[@class="C1_sentence_en"]//text()'))
sentence_dict.update({"sentence_en": sentence_en})
# 中文翻译
if len(sentence.xpath('p[2]//text()')) != 0:
sentence_ch = sentence.xpath('p[2]//text()')[0]
sentence_dict.update({"sentence_ch": sentence_ch})
else:
sentence_dict.update({"sentence_ch": ""})
sentence_list.append(sentence_dict)
item.update({"sentences": sentence_list})
item.update({"en_tip": en_tip_list})
else: # See also
see_also = explanation_box.xpath('b[@class="C1_text_blue"]//text()')
item.update({"see_also": see_also})
items.append(item)
word.update({"items": items})
num = num + 1
print("已解析:", num)
word_list.append(word)
s = f.readline()
def import_data():
# 连接数据库,获取游标
con = pymysql.connect(host='localhost', port=3306, user='root', password='root', db='kelinsi_dict', charset='utf8')
cur = con.cursor()
num2 = 0
for word in word_list:
print("正在存入:", word.get("word_en"))
sql = "insert into word(word_en, star)values(\"%s\",\"%s\")" % (pymysql.escape_string(word.get("word_en")), pymysql.escape_string(word.get("star")))
cur.execute(sql)
con.commit()
last_wid = cur.lastrowid
for item in word.get("items"):
if item.get("see_also"):
for see_word in item.get("see_also"):
sql = "insert into see_also(number,word_en,wid)VALUES(\"%s\", \"%s\", %d)" % (pymysql.escape_string(item.get("number")), pymysql.escape_string(see_word), last_wid)
cur.execute(sql)
con.commit()
elif item.get("word_ch"):
sql = "insert into items(number,label,word_ch,explanation,gram,wid)VALUES(\"%s\", \"%s\", \"%s\", \"%s\", \"%s\", %d) " % (pymysql.escape_string(item.get("number")), pymysql.escape_string(item.get("label")), pymysql.escape_string(item.get("word_ch")), pymysql.escape_string(item.get("explanation")), pymysql.escape_string(item.get("word_gram")), last_wid)
cur.execute(sql)
con.commit()
last_iid = cur.lastrowid
# sentence
for sentence in item.get("sentences"):
sql = "insert into sentences(sentence_ch, sentence_en, iid)VALUES(\"%s\", \"%s\", %d)" % (pymysql.escape_string(sentence.get("sentence_ch")), pymysql.escape_string(sentence.get("sentence_en")), last_iid)
cur.execute(sql)
con.commit()
for en_tip in item.get("en_tip"):
sql = "insert into en_tip(tip, iid)VALUES(\"%s\", %d)" % (pymysql.escape_string(en_tip), last_iid)
cur.execute(sql)
con.commit()
num2 = num2 + 1
print("已存入:", num2)
cur.close()
con.close()
if __name__ == '__main__':
getdata("kelinsi.txt")
import_data()
4.字典文件及数据库文件
链接:https://pan.baidu.com/s/1e4TwCAwcioBGzYP2j76AXg
提取码:128q