Hadoop(一)--环境搭建
Hadoop环境搭建
- 一.安装包下载
- 二.创建Linux用户
- 三.解压hadoop软件
- 四.配置JDK
- 五.设置公钥和私钥(ssh免密登录)
- 六.伪分布式环境搭建(单台启动)
-
- 6.1.Hadoop-配置core-site
- 6.2.HSDFS部署(格式化&启动服务)
-
- 6.2.1.格式化:bin/hdfs namenode -format
- 6.2.2.启动dfs:sbin/start-dfs.sh
- 6.2.3.访问web网站 http://XXX:9870
- 6.2.4.创建HDFS的用户文件夹存放MapReduce Job
- 6.2.5.命令帮助
- 6.2.6.workers集群配置
- 6.2.6.在tmp目录下的pid文件【重要】
- 6.2.7.移动pid文件
- 6.2.8.修改hadoop原数据存储目录
- 6.2.9.修改hdfs中datenode数据存储目录
- 6.2.10.修改yarn中nodemanager数据存储目录
- 6.3.Yarn部署
-
- 6.3.1.配置Yarn的参数
- 6.3.2.启动服务
- 6.3.3.访问web网站 http://XXX:8088 (XXX是你机器的IP地址)
- 6.3.4.调整8088端口&重启服务
- 九.集群部署的一些命令
-
- 9.1.scp:复制拷贝
- 9.2.rsync:远程同步工具
- 9.3.配置workers
一.安装包下载
- 可以在浏览器输入地址下载:https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
- 可以在Linux服务器上使用命令下载:
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
二.创建Linux用户
- 创建非root用户【模拟在实际工作中,无root用户权限的时候】
- 如果有非root用户,可跳过此步骤
[root@maggie ~]# useradd hadoop
[root@maggie ~]# cd /home/hadoop/
[root@maggie hadoop]# ll -a
total 20
drwx------ 2 hadoop hadoop 4096 Nov 1 00:00 .
drwxr-xr-x. 4 root root 4096 Nov 1 00:00 ..
-rw-r--r-- 1 hadoop hadoop 18 Aug 8 2019 .bash_logout
-rw-r--r-- 1 hadoop hadoop 193 Aug 8 2019 .bash_profile
-rw-r--r-- 1 hadoop hadoop 231 Aug 8 2019 .bashrc
[root@maggie hadoop]# mkdir software app log data lib tmp source
[root@maggie hadoop]# ll -a
total 48
drwx------ 9 hadoop hadoop 4096 Nov 1 00:01 .
drwxr-xr-x. 4 root root 4096 Nov 1 00:00 ..
drwxr-xr-x 2 root root 4096 Nov 1 00:01 app 【解压后的软件包位置】
-rw-r--r-- 1 hadoop hadoop 18 Aug 8 2019 .bash_logout
-rw-r--r-- 1 hadoop hadoop 193 Aug 8 2019 .bash_profile
-rw-r--r-- 1 hadoop hadoop 231 Aug 8 2019 .bashrc
drwxr-xr-x 2 root root 4096 Nov 1 00:01 data
drwxr-xr-x 2 root root 4096 Nov 1 00:01 lib
drwxr-xr-x 2 root root 4096 Nov 1 00:01 log 【日志文件】
drwxr-xr-x 2 root root 4096 Nov 1 00:01 software【上传的压缩包位置】
drwxr-xr-x 2 root root 4096 Nov 1 00:01 source 【源码】
drwxr-xr-x 2 root root 4096 Nov 1 00:01 tmp
[root@maggie ~]# chown -R hadoop:hadoop /home/hadoop/*
[root@maggie ~]# mv /root/software/hadoop-3.3.4.tar.gz /home/hadoop/software/
[root@maggie ~]# chown -R hadoop:hadoop /home/hadoop/software/
[root@maggie ~]# cd /home/hadoop/software/
[root@maggie software]# chown -R hadoop:hadoop /home/hadoop/software/
[root@maggie software]# ll
total 679164
-rw-r--r-- 1 hadoop hadoop 695457782 Oct 31 11:39 hadoop-3.3.4.tar.gz
三.解压hadoop软件
- 解压hadoop软件:tar -xzvf hadoop-3.3.4.tar.gz -C …/app/
- 设置软连接: ln -s hadoop-3.3.4 hadoop
[hadoop@maggie software]$ tar -xzvf hadoop-3.3.4.tar.gz -C ../app/
......(解压过程省略)
[hadoop@maggie app]$ ln -s hadoop-3.3.4 hadoop 【设置软连接】
[hadoop@maggie app]$ cd hadoop
[hadoop@maggie hadoop]$ ll
total 116
drwxr-xr-x 2 hadoop hadoop 4096 Jul 29 21:44 bin 【脚本,运行命令】
drwxr-xr-x 3 hadoop hadoop 4096 Jul 29 20:35 etc 【配置文件,重要的有hadopp-env.sh; core-site.yml; hdfs-site.yml; yarn-site.yml;等相关文件】
drwxr-xr-x 2 hadoop hadoop 4096 Jul 29 21:44 include
drwxr-xr-x 3 hadoop hadoop 4096 Jul 29 21:44 lib
drwxr-xr-x 4 hadoop hadoop 4096 Jul 29 21:44 libexec
-rw-rw-r-- 1 hadoop hadoop 24707 Jul 29 04:30 LICENSE-binary
drwxr-xr-x 2 hadoop hadoop 4096 Jul 29 21:44 licenses-binary
-rw-rw-r-- 1 hadoop hadoop 15217 Jul 17 02:20 LICENSE.txt
-rw-rw-r-- 1 hadoop hadoop 29473 Jul 17 02:20 NOTICE-binary
-rw-rw-r-- 1 hadoop hadoop 1541 Apr 22 2022 NOTICE.txt
-rw-rw-r-- 1 hadoop hadoop 175 Apr 22 2022 README.txt
drwxr-xr-x 3 hadoop hadoop 4096 Jul 29 20:35 sbin 【脚本,启动,停止; start/stop-dfs.sh; start/stop-all.sh; start/stop-yarn.sh】
drwxr-xr-x 4 hadoop hadoop 4096 Jul 29 22:21 share 【官方提供的jar包,测试使用的案例】
在$HADOOP_HOME/sbin 目录下, 有如下启动和停止的运行命令:
# 启动 hdfs 、启动 yarn
start-dfs.sh
start-yarn.sh
start-all.sh
# 关闭
stop-alll.sh
stop-dfs.sh
stop-yarn.sh
四.配置JDK
根据官网步骤(Single Node Setup)去搭建环境:
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
- 部署的依赖包:JDK(略)
相关JDK版本,推荐查看官网配置:https://cwiki.apache.org/confluence/display/HADOOP/Hadoop+Java+Versions
- 根据官网推荐,即便Linux中配置了JDK配置,仍然需要配置JDK地址:
- vi etc/hadoop/hadoop-env.sh 添加 export JAVA_HOME=/root/app/jdk1.8.0_333【JDK环境变量】
[root@maggie java]# echo $JAVA_HOME
/usr/java/jdk1.8.0_333
[hadoop@maggie ~]$ pwd
/home/hadoop
[hadoop@maggie ~]$ cd app/hadoop/etc/hadoop/
[hadoop@maggie hadoop]$ vi hadoop-env.sh
添加如下配置:
export JAVA_HOME=/usr/java/jdk1.8.0_333
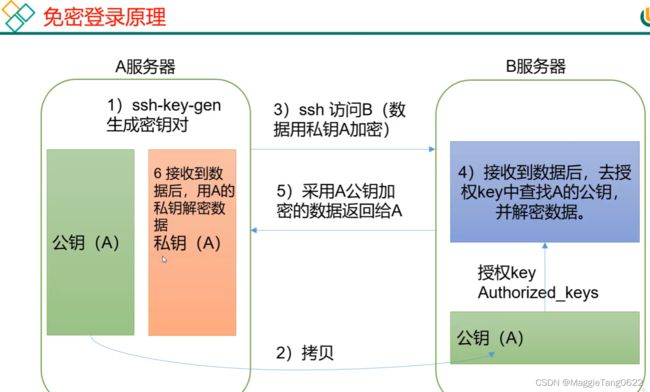
五.设置公钥和私钥(ssh免密登录)
- ssh-keygen 【在家目录下,生成公钥和私钥】
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 【生成一个新的文件】
- chmod 0600 ~/.ssh/authorized_keys 【给新文件赋权】
如果还出现了ssh需要密码的问题,解决方案: 配置ssh免密登录后,依然需要输入密码登录&解决方案
[hadoop@maggie hadoop]$ ssh-keygen 【后面敲入3次回车】
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:jPFg4hiW/TFWxwinZfT4Ly6LU2RWXF6F437lqvoZPMo hadoop@maggie
The key's randomart image is:
+---[RSA 2048]----+
| .o*+... .o.|
| o *.++. .o |
| + o O ... .. . |
| . + = O+. . .|
| . . o+S . . ..|
| . o . o|
| . . = o |
| ...o o +. |
| ...oEo+. |
+----[SHA256]-----+
[hadoop@maggie hadoop]$ cd 【回到家目录,下面有个.ssh的隐藏文件夹】
[hadoop@maggie ~]$ ll -a
total 56
drwx------ 10 hadoop hadoop 4096 Nov 2 12:43 .
drwxr-xr-x. 4 root root 4096 Nov 1 00:00 ..
drwxr-xr-x 3 hadoop hadoop 4096 Nov 1 00:16 app
-rw------- 1 hadoop hadoop 406 Nov 2 01:02 .bash_history
-rw-r--r-- 1 hadoop hadoop 18 Aug 8 2019 .bash_logout
-rw-r--r-- 1 hadoop hadoop 193 Aug 8 2019 .bash_profile
-rw-r--r-- 1 hadoop hadoop 231 Aug 8 2019 .bashrc
drwxr-xr-x 2 hadoop hadoop 4096 Nov 1 00:01 data
drwxr-xr-x 2 hadoop hadoop 4096 Nov 1 00:01 lib
drwxr-xr-x 2 hadoop hadoop 4096 Nov 1 00:01 log
drwxr-xr-x 2 hadoop hadoop 4096 Nov 1 00:06 software
drwxr-xr-x 2 hadoop hadoop 4096 Nov 1 00:01 source
drwx------ 2 hadoop hadoop 4096 Nov 2 12:43 .ssh
drwxr-xr-x 2 hadoop hadoop 4096 Nov 1 00:01 tmp
[hadoop@maggie ~]$ cd .ssh/
[hadoop@maggie .ssh]$ ll -a
total 16
drwx------ 2 hadoop hadoop 4096 Nov 2 12:43 .
drwx------ 10 hadoop hadoop 4096 Nov 2 12:43 ..
-rw------- 1 hadoop hadoop 1679 Nov 2 12:43 id_rsa 【存放的私钥】
-rw-r--r-- 1 hadoop hadoop 395 Nov 2 12:43 id_rsa.pub 【存放的公钥】
[hadoop@maggie .ssh]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 【重要,生成权限文件】
[hadoop@maggie .ssh]$ ll
total 20
-rw-rw-r-- 1 hadoop hadoop 395 Nov 2 15:50 authorized_keys
-rw------- 1 hadoop hadoop 1679 Nov 2 12:43 id_rsa
-rw-r--r-- 1 hadoop hadoop 395 Nov 2 12:43 id_rsa.pub
[hadoop@maggie .ssh]$ cat id_rsa.pub
ssh-rsa AAAAB3Nz......ZfKWN hadoop@maggie 【maggie这台机器,hadoop用户对应的公钥密码】
- 如果想要将公钥拷贝到别的主机
ssh-copy-id XXX (XXX表示目标主机,拷贝以后,就可以ssh免密登录别的主机)
.ssh文件夹下(~/.ssh)的文件功能解释
- known_hosts:记录ssh访问过计算机的公钥(public key)
- id_rsa:生成的私钥
- id_rsa.pub:生成的公钥
- authorized_keys:存放授权过的无密登录服务器公钥
六.伪分布式环境搭建(单台启动)
6.1.Hadoop-配置core-site
- 根据官网推荐,即便Linux中配置了JDK配置,仍然需要配置JDK地址:
- vi etc/hadoop/hadoop-env.sh 添加 export JAVA_HOME=/usr/java/jdk1.8.0_333【JDK环境变量】
- $ vi etc/hadoop/hadoop-env.sh 找到PID默认配置路径并修改为:export HADOOP_PID_DIR=/home/xiaofeng/tmp
编辑hadoop解压包下面的etc/hadoop/core-site.xml:
vi /home/hadoop/app/etc/hadoop/core-site.xml 【添加】
fs.defaultFS
hdfs://maggie101:9000
hadoop.tmp.dir
/home/xiaofeng/tmp
// 访问地址的开头:hdfs dfs -ls hdfs://maggie101:9000/......
etc/hadoop/hdfs-site.xml:
**vi /home/hadoop/app/etc/hadoop/hdfs-site.xml 【添加副本】**
dfs.replication
1
dfs.namenode.http-address
maggie101:9870
dfs.namenode.secondary.http-address
maggie101:9868
- 1台机器,只需要复制1份,value = 1
- 3台及其以上的机器,只需要复制3份,value = 3
- 编辑hadoop解压包下面的etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME
yarn.resourcemanager.hostname
maggie101
yarn.resourcemanager.webapp.address
maggie101:9871
- 编辑hadoop解压包下面的etc/hadoop/mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.application.classpath
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
6.2.HSDFS部署(格式化&启动服务)
6.2.1.格式化:bin/hdfs namenode -format
$ bin/hdfs namenode -format 【在/app/hadoop目录下执行这句】
注意:格式化后,默认路径在/tmp/hadooop-${user}/dfs/name (Linux目录下的tmp目录数据,长时间未使用,会被清理,所以该路径需要替换
6.2.2.启动dfs:sbin/start-dfs.sh
[hadoop@maggie101 ~]$ cd app/hadoop
[hadoop@maggie101 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [maggie101]
Starting datanodes
Starting secondary namenodes [maggie101]
[hadoop@maggie101 hadoop]$ jps
19640 NameNode 【NN:名称节点,管理元数据】
19979 SecondaryNameNode 【SNN:第二名称节点,只备份最近1个小时的备份数据】
20124 Jps
19759 DataNode 【DN:数据节点,存储数据,读取数据】
6.2.3.访问web网站 http://XXX:9870
- 上述服务启动以后,在云服务中打开端口9870,即可访问hadoop网站
- http://60.164.243.116:9870

Safemode is off. 【安全模式】
安全模式状态:off (关),系统正常,正常读写
安全模式状态:on(开)不能写,只能读。需要关注和人工干预。
6.2.4.创建HDFS的用户文件夹存放MapReduce Job
- Make the HDFS directories required to execute MapReduce jobs:
$ bin/hdfs dfs -mkdir /user
$ bin/hdfs dfs -mkdir /user/xiaofeng (hadaoop可以替换成你们实际的用户)
$ bin/hdfs dfs -mkdir input 【创建input文件夹】
[hadoop@maggie101 hadoop]$ bin/hdfs dfs -ls /user/xiaofeng
Found 1 items
drwxr-xr-x - xiaofeng supergroup 0 2022-11-08 16:54 /user/xiaofeng/input
// -put 是上传文件/文件夹
$ bin/hdfs dfs -put etc/hadoop/*.xml input 【将etc/hadoop下面所有xml文件,拷贝复制到input文件夹下】
// 测试语句
$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+'
// -get 是下载文件
$ bin/hdfs dfs -get output output
$ cat output/*
6.2.5.命令帮助
- bin/hdfs --help
- bin/hdfs dfs --help
6.2.6.workers集群配置
- 在hadoop 2.X 版本中,文件系统机器配置文件是:slaves
- 在hadoop 2.X 版本中,文件系统机器配置文件是:workers
[xiaofeng@maggie101 hadoop]$ cat etc/hadoop/workers
localhost【修改为想要配置的集群机器】
$ sbin/start-dfs.sh
6.2.6.在tmp目录下的pid文件【重要】
- pid文件在控制集群启动/停止的关键文件
- 在/tmp目录下存放着pid文件,如果这些文件被删除。这个时候,去修改配置,再重启,配置不会生效。
- 在/tmp目录下存放超过30天,系统就会自动清理掉。日后做维护重启集群,很难发现问题。
// 全部存放的进程号
hadoop-xiaofeng-datanode.pid
hadoop-xiaofeng-namenode.pid
hadoop-xiaofeng-nodemanager.pid
hadoop-xiaofeng-resourcemanager.pid
hadoop-xiaofeng-secondarynamenode.pid
[xiaofeng@maggie101 tmp]$ jps
25698 NameNode
27045 Jps
26327 ResourceManager
26441 NodeManager
25820 DataNode
26045 SecondaryNameNode
[xiaofeng@maggie101 tmp]$ cat hadoop-xiaofeng-datanode.pid
25820
[xiaofeng@maggie101 tmp]$ cat hadoop-xiaofeng-namenode.pid
25698
[xiaofeng@maggie101 tmp]$ cat hadoop-xiaofeng-nodemanager.pid
26441
[xiaofeng@maggie101 tmp]$ cat hadoop-xiaofeng-resourcemanager.pid
26327
[xiaofeng@maggie101 tmp]$ cat hadoop-xiaofeng-secondarynamenode.pid
26045
6.2.7.移动pid文件
- $ vi etc/hadoop/hadoop-env.sh 找到PID默认配置路径并修改
- 重启服务sbin/start-hdfs.sh
在文件末尾输入:冒号斜杠PID,搜索。找到pid配置路径:export HADOOP_PID_DIR=/tmp
修改为:export HADOOP_PID_DIR=/home/xiaofeng/tmp
6.2.8.修改hadoop原数据存储目录
- 修改core-site.xml文件中的配置:hadoop.tmp.dir 原数据存储目录位置
[xiaofeng@maggie101 current]$ pwd
/tmp/hadoop-xiaofeng/dfs/name/current 【原数据存储位置】
[xiaofeng@maggie101 current]$ ll
total 2072
-rw-rw-r-- 1 xiaofeng xiaofeng 117 Nov 8 23:05 edits_0000000000000000001-0000000000000000003
-rw-rw-r-- 1 xiaofeng xiaofeng 1048576 Nov 8 23:06 edits_0000000000000000004-0000000000000000071
-rw-rw-r-- 1 xiaofeng xiaofeng 42 Nov 8 23:22 edits_0000000000000000072-0000000000000000073
-rw-rw-r-- 1 xiaofeng xiaofeng 1048576 Nov 8 23:22 edits_inprogress_0000000000000000074
-rw-rw-r-- 1 xiaofeng xiaofeng 403 Nov 8 23:03 fsimage_0000000000000000000
-rw-rw-r-- 1 xiaofeng xiaofeng 62 Nov 8 23:03 fsimage_0000000000000000000.md5
-rw-rw-r-- 1 xiaofeng xiaofeng 3 Nov 8 23:22 seen_txid
-rw-rw-r-- 1 xiaofeng xiaofeng 217 Nov 8 23:03 VERSION
$ vi etc/hadoop/core-site.xml
hadoop.tmp.dir</name>
/home/xiaofeng/tmp</value>
</property>
$ mv /tmp/hadoop-xiaofeng/* /home/xiaofeng/tmp 【同时迁移相应的数据】
6.2.9.修改hdfs中datenode数据存储目录
- 修改hdfs-site.xml文件中的配置:dfs.datanode.data.dir 数据存储目录位置
$ vi etc/hadoop/hdfs-site.xml
dfs.datanode.data.dir</name>
/data01/datanode,/data02/datanode,/data03/datanode</value>
</property>
6.2.10.修改yarn中nodemanager数据存储目录
- 修改yarn-site.xml文件中的配置:yarn.nodemanager.local-dirs 数据存储目录位置
$ vi etc/hadoop/yarn-site.xml
yarn.nodemanager.local-dirs</name>
/data01/nodemanager,/data02/nodemanager,/data03/nodemanager</value>
</property>
6.3.Yarn部署
6.3.1.配置Yarn的参数
- etc/hadoop/mapred-site.xml:添加配置
etc/hadoop/mapred-site.xml:
mapreduce.framework.name</name>
yarn</value>
</property>
mapreduce.application.classpath</name>
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
- etc/hadoop/yarn-site.xml:中添加配置
etc/hadoop/yarn-site.xml:
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.env-whitelist</name>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
6.3.2.启动服务
- 启动yar服务:sbin/start-yarn.sh
[hadoop@maggie101 hadoop]$ sbin/start-yarn.sh
Starting resourcemanager 【RM:资源节点】
Starting nodemanagers 【NM:节点管理】
[hadoop@maggie101 hadoop]$ jps
22310 Jps
19640 NameNode
21849 ResourceManager
21963 NodeManager
19979 SecondaryNameNode
19759 DataNode
6.3.3.访问web网站 http://XXX:8088 (XXX是你机器的IP地址)
- 默认端口8088(但是建议替换,否则容易被攻击,被挖矿)

6.3.4.调整8088端口&重启服务
- 通过官网配置,修改8088端口:
- tps://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
在etc/hadoop/yarn-site.xml中修改配置
etc/hadoop/yarn-site.xml:
yarn.resourcemanager.webapp.address</name>
maggie101:9871</value>
</property>
</configuration>
$ sbin/stop-yarn.sh
$ sbin/start-yarn.sh
[hadoop@maggie101 hadoop]$ vi etc/hadoop/yarn-site.xml
[hadoop@maggie101 hadoop]$ stop-yarn.sh
Stopping nodemanagers
Stopping resourcemanager
[hadoop@maggie101 hadoop]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[hadoop@maggie101 hadoop]$ jps
26067 ResourceManager
19640 NameNode
26184 NodeManager
26552 Jps
19979 SecondaryNameNode
19759 DataNode
- http://XXX:9871即可正常访问
其中Active Node有数据,才表示服务正常。否则容易导致无法正常提交作业。

九.集群部署的一些命令
9.1.scp:复制拷贝
复制的语法:
① 从A主机推送给B主机(在A主机执行的命令)
scp -r $dir/$name $user@$host:$dir/$name
命令 递归 A主机文件路径/A名称 B用户@B主机:B路径/B名称
② 从A主机拉取信息到B主机(在B主机执行的命令)
scp -r $user@$host:$dir/$name $dir/$name
命令 递归 A用户@A主机:A文件路径/A名称 B路径/B名称
② 从A主机拉取信息到B主机(在C主机执行的命令)
scp -r $user@$host:$dir/$name $user@$host:$dir/$name
命令 递归 A用户@A主机:A文件路径/A名称 B用户@B主机:B路径/B名称
9.2.rsync:远程同步工具
远程同步的语法:
① 从A主机推送给B主机(在A主机执行的命令)
rsync -av $dir/$name $user@$host:$dir/$name
命令 递归 A主机文件路径/A名称 B用户@B主机:B路径/B名称
-a:归档拷贝
-v:显示复制过程
9.3.配置workers
$ vi ~/hadoop/etc/hadoop/workers ( ~/hadoop是我hadoop的解压后路径)
在该文件中增加如下集群的机器配置:
hadoop102
hadoop103
hadoop104注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
- 同步所有节点配置文件
$ xsync /opt/module/hadoop-3.1.3/etc (集群分发)