深入理解Java中的HashMap
目录
前言
1. 什么是HashMap?
2. HashMap的工作机制
3. Hash函数
3.1 整数类型(int)
3.2 字符类型(char)
3.3 浮点类型(float)
3.4 双浮点类型(Double)
3.5 布尔类型(Boolean)
3.6 字符串(String)
4. 根据Hash值来寻址,get(key)函数的工作机制
5. put(key, value) 函数的工作机制
6. 总结
前言
在面试的过程中有一些面试官喜欢问HashMap的相关知识点,这个是一个常见的知识点。但是面试官会问的很深。因此,我想做一个深度的总结。将此总结的过程分享给大家。
1. 什么是HashMap?
菜鸟网站中对HashMap有以下的定义:
在Java中HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。HashMap 是无序的,即不会记录插入的顺序。HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。
简单来说:HashMap就是一个字典,通过Key能够以O(1)的时间复杂度直接获取到Key对应的值(Value)。
2. HashMap的工作机制
通过之前的介绍可以看到,HashMap最主要的特质是可以以O(1)的时间复杂度来获取键值对。那么这是怎么实现的呢?
最朴素的思想是,我通过一个特定的函数,能够直接将健值(Key)转化为存储值(Value)的地址。Java中的这个函数就是hashCode()函数。所以,下面我要介绍一下Java中的hashCode()函数!
3. Hash函数
java中对于不同数据类型的hashCode()函数是有重写的。下面逐一介绍不同数据类型的hash函数
3.1 整数类型(int)
直接看源码,发现整数的hash值就是其本身。

3.2 字符类型(char)

直接看源码,char的hash值就是将其转化为整数的值。也就是对应ASCII值。
3.3 浮点类型(float)

java中的float计算是native方法,也就是这一部分不是java自己实现的。通过注释可以看到,当浮点值为正无穷时返回0x7f800000, 当浮点值为负无穷时返回0xff800000;其符合IEEE 754标准,当为正常浮点数时直接返回其二进制表示;至于浮点数的二进制表示可以参考《计算机组成原理》中的介绍。
3.4 双浮点类型(Double)

和float类型类似,但是有一个不同的地方是hash只能有32位,而Double有64位,所以只能保留前面double的高位中的32位,所以源码中才会无符号的右移32位。
3.5 布尔类型(Boolean)

源码显示,当为true时是1231, 当为false时是1237。 至于为什么取这两个数;有以下几中考虑:
1)这两个数是素数。为了尽量避免hash冲突。 2) 作者个人喜好; 具体分析可以看这一篇博文:
你可能不清楚的Java细节(1)--为什么Boolean的hashCode()方法返回值是1231或1237
3.6 字符串(String)

他的计算方法和以下公式是等价的:
![]()
为什么以31为底,《Effective Java》中给出了以下解释:
之所以使用 31, 是因为他是一个奇素数。如果乘数是偶数,并且乘法溢出的话,信息就会丢失,因为与2相乘等价于移位运算(低位补0)。使用素数的好处并不很明显,但是习惯上使用素数来计算散列结果。 31 有个很好的性能,即用移位和减法来代替乘法,可以得到更好的性能: 31 * i == (i << 5)- i, 现代的 VM 可以自动完成这种优化。这个公式可以很简单的推导出来。
这个和散列函数的工作方式有关。
以上就是我们对于不同数据类型的hash函数的介绍。终结一下核心思想是:将各种数据转化为唯一的整数作为hash值。但是细心的读者已经发现了,有可能key不相同的情况下有可能hash值是相同的。因为从String hashCode计算方式而言,那个方程必定有多组解。Java中的HashMap使用的是拉链法来处理hash冲突的,也就是当不同的key值hash值一致时,就在链表后面或者是红黑树李挂载这个节点。因此在查找时需要遍历查找或者是二分查找。现在我们已经拿到了hash值,那么我怎么来获取存储Value的地址呢?下面我介绍相关方法。
4. 根据Hash值来寻址,get(key)函数的工作机制
在介绍Hash之前先介绍一下HashMap的数据结构:

HashMap的数据结构是数据+链表的形式;
Java的数组(table)的源码如下:

Java的及链表(Node)如下:

注意在Java 1.8之后在特殊的情况下会将链表转化为红黑树,1.8之前是用链表;这一部分主要是加快了在hash冲突下的查询速度;其实核心的思想是没有变的;
现在我们可以进一步看java如何设计get(key)方法;
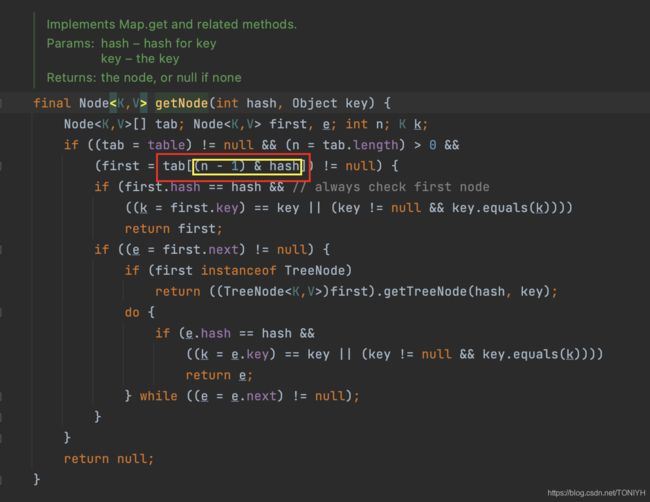
在get()之前需要几种检查 1)数据存不存在 2)数据长度是不是大于0
关键的地方在于图中标红的部分:tab[(n-1)&hash] 根据hash值找到了数组中对应的链表头部; 其中(n-1)&hash 其实等价于 hash%n。 但是满足这个等价是需要一个条件的,条件是n必须为2的整数幂;下面演示下一为啥等价:
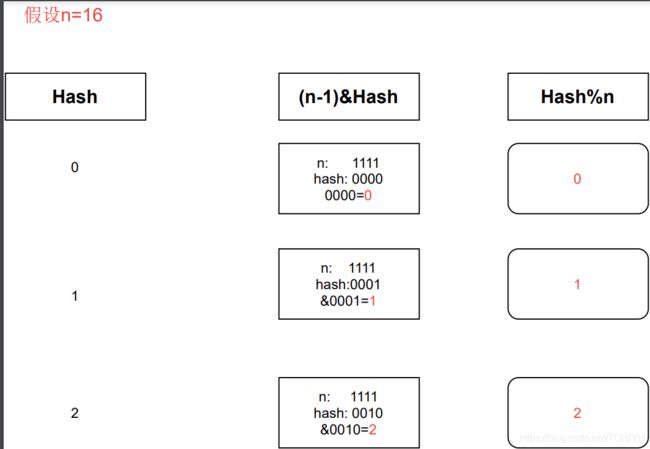
其实这也解释了为什么HashMap的容量一定要为2的整数次幂;之所以要&操作来替代求模运算呢?这是因为计算机的&操作数据最快,而求模和除法是最慢的。
以上仅仅是就计算出数组中的链表头部。
后面的就是查询的问题。在JDK1.8之前后面是用链表来解决hash冲突问题,也就是需要遍历,时间复杂度是O(n),其中n为平均链表长度;JDK1.8之后是使用红黑树来做查询,时间复杂度O(logn), 其中n为树的节点个数。
5. put(key, value) 函数的工作机制
首先我们需要介绍一下HashMap中的几个重要的参数:

java 设置了初始容量=16, 最大容量=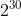 , 负载因子 = 0.75;
, 负载因子 = 0.75;
初始容量:当没有指定Hashmap的容量时,默认的初始容量时16;
最大容量:最大是支持2^30,大约为十亿七千万个
负载因子:当hashmap中的数据超过(n*负载因子)个数时,触发扩容;
之所以要扩容是因为当Hashmap中的数据越来越多的时候,hash冲突会越来越严重,这会严重影响到写入和读取性能。因此java中存在该机制扩充容量,扩充方法为在原来容量的基础上*2;这也保证了之前提到的,容量始终为2的整数幂的值
了解了这些信息,现在我们一行行来读HashMap put()源码:
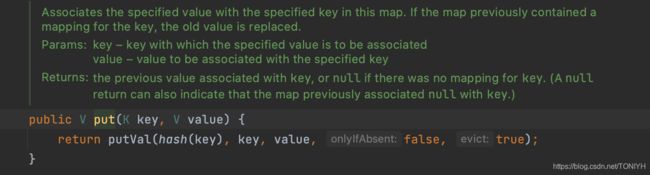
put()中直接调用了putVal()方法, putVal()如下所示:
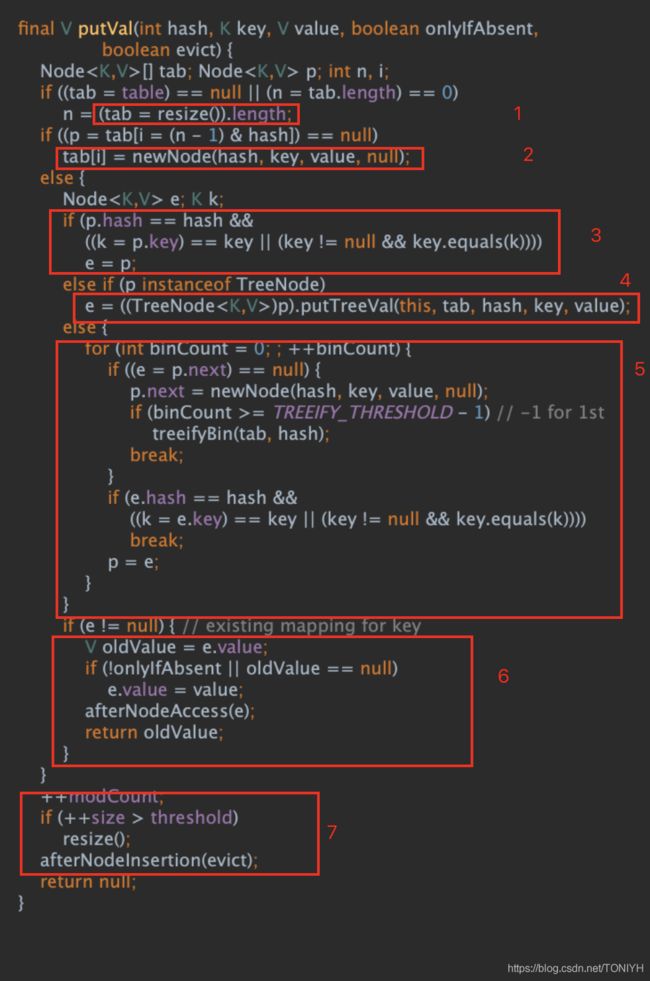
我将关键步骤按照序号编号为1-7;下面会逐一介绍每一步在做什么;
1. 容量检查,初始化,操作并获取容量的值;这个功能主要由resize()函数来完成;

注释已经写的很清楚,如果这个数组(table)为空就生成它初始容量的数组,否则就以2的指数次幂进行扩容;
2. 如果根据hash值找对应数值位置为null,直接在生成node放置在该处;
3. 如果根据hash值找到的数值处存在node(链表头或者是树的根)的key和目标key一致,那么直接更新这个值就行;
4. 如果根据hash值找到的数值处存在node(链表头或者是树的根)的key和目标key不一致并且该节点类型是TreeNode(注意此时节点类型为TreeNode, 而之前是Node, 差别是一个是树的节点,一个是链表的节点), 就将节点挂载在这个树下面。这个树是红黑树。代码的实现方法是putTreeVal();这个就是涉及到红黑树的添加,叶子分裂,旋转只来的操作。这个比较复杂,今天不进行详细的讨论;
5. 如果根据hash值找到的数值处存在node(链表头或者是树的根)的key和目标key不一致该节点的类型Node(其他情况); 就在链表中节点key值从前往后匹配。这里有两种情况:1)当链表中不存在key值,就在链表尾部插入一个new node() ; 2) 如果链表中存在对应的key值,直接更新即可;
在这里java里面有一个重要的参数,TREEIFY_THRESHOLD (默认8); 当前链表的长度超过这个阈值时,就会树形化,将链表转化为红黑树。因为,长度为8的链表已经算是较长链表,此次使用红黑树能够加快访问速度。
6. 第六步就是之前各种情况下存在对应的key值,更新的操作;
7. 最后一步是检查当前Hashmap中的值有没有超过阈值,超过了就进行扩容处理;
以上就是put()的操作流程,对照着源码,还是读的的比较清楚的。通过对源码的阅读,可以看到HashMap put()操作都不是原子操作,所以HashMap不是线程安全。而另外一个HashTable是线程安全的;
6. 总结
这是我第一次写java具体的学习笔记。因为我在面试频频受挫,但是我坚信一个好的学习习惯加上时间的积累,我一定不会一直是java小菜鸟。这篇文章也确实快花了我五六个小时来撰写。我坚信,输出就是最好的学习。我确实从读源码中学习到了很多。朋友们祝福我吧!