流媒体学习-WebRTC全面入门学习-1
一、初始WebRTC
1、WebRTC
就是音视频处理+即时通讯的开源库
音视频处理中ffmpeg和WebRTC是两个很重要的一部分,ffmpeg注重与数据音视频的编解码,文件的后处理、WebRTC整个网络,网络的传输、回音消除、降噪。
2、WebRTC能做什么
音视频实时互动、
游戏、即时通讯、文件传输等等
它是一个百宝箱,传输音视频处理(回音消除、降噪等)可以放到demo中做不同的组合。
能够学到什么
音视频设备的访问与管理;WebRTC是跨平台的,在各个平台上面他们的音频设备 视频设备是怎么管理的,如何访问的,不同平台是不一样的,而WebRTC就很好的支持了,学习他就可以了解到各个平台上是如何管理访问的。
音视频数据的采集;采集音频数据 视频数据 桌面数据
数据的传输与实时互动;可以了解到p2p的建立过程 怎么分类 p2p如何进行实时传输的、p2p传输网络出现问题网络如何恢复。
我们实现互动 都是要先建立一个房间,然后都到这个房间来就可以互相互动了。
谷歌提供的一个案例;https://appr.tc 创建房间进行视频互动
3、WebRTC架构初识
图1
4、WebRTC的目录结构
因为是有需求要修改WebRTC的源代码的,而WebRTC代码量也是非常庞大的,因此知晓他常用的目录结构文件位置及作用是对快速定位文件和修改点十分有必要的。
api;就是WebRTC的web层接口,浏览器,自己写的应用程序大多数都是直接调用webrtc直接提供的api调用,如果我们想增加或者调整webrtc的web端的接口就在api目录下找相应文件
call;对数据流的管理,音频流 视频流。当我与对端连接之后、那么同一个端的数据流的管理由一个Call进行管理,一个Call代表同一个端点的所有数据的流入流出,如果与多个端进行沟通那么就有多个Call。
video;与视频相关的逻辑,注意是逻辑代码 ,啥时候编码,啥时候解码这种逻辑关系在这个文件夹下的文件控制
audio;与音频相关的逻辑,注意是逻辑代码 ,啥时候编码,啥时候解码这种逻辑关系在这个文件夹下的文件控制
common_audio; 音频算法相关的
common_video;视频算法相关的
media;与多媒体相关的逻辑处理,如编解码的逻辑处理 编解码的逻辑处理,解码之后需要再做什么处理就在这里。
logging;日志相关的
module;特别重要的一个文件夹
----audio_codinf;音频编解码器相关代码,具体的编码器相关的如ACC ILBC
----audio_devic;设备相关的(音频采集播放具体硬件设备相关的),之前是安卓IOS都是放置这里的,现在改了
----audio_mixer;混音相关代码,如多人视频互动,多个人都在说话这个时候就需要把他们的音频数据混在一起发送比较方便,减少了音频流。
—-Audio_procesing;音频的前后处理,如回音消除,降噪 增益等,又分很多子目录表示对应功能实现
----Bitrate_controller;码流码率控制相关的代码,如控制视频的码流在多大内,码率是如何控制的都是在这里查看
----Congestion_controller;流控相关的,当我们检测到网络流量较高的时候我们需要做一些网络控制,防止整个网络包把带宽打死。具体如何控制就在当前文件夹下查看
----Destop_capture;桌面采集相关的代码,
----Pacing;码率的侦测和平滑处理,就是首先检测到音频视频的码率是什么样子,再做一个平滑的处理,不能一下子就直接发送应该做一些平滑,比如平均10k或者500k,不能一下高一下低的码率发送。
----Remote_bitrate_estimator;远端码率评估,就是估算我远端的带宽是多少,一个是我本地端的带宽 和远端带宽 因为不仅要看我能发多少还要看远方能接收多少。
----Rtp_rtcp;rtp/rtcp协议相关的代码
----Video_capture;视频捕获的相关代码,
----Video_coding;视频的编解码器相关代码 h264、mpeg
----Video_processing;视频前后处理相关的,如视频帧的增强,检测,人脸视频可以放在这里。
pc;Peer Connection表示我与对端的一个连接,这是上层的一个连接概念,是一个很重要的层次,是上层统一的一个接口层。注意在这个连接下面就有很多东西了、
流(流里面又有串,轨(音频轨、视频轨、录屏轨))、【轨的意思(两个平行的线就是两个轨,存储永远是不会相交的,分开存储的,音频视频永远是分开存储的)】
所有的统计信息(媒体流的统计信息,传输的统计信息等等)
p2p;端对端的进行传输的时候首先要看p2p能不能打通,p2p是有很多种类型的,具体你是哪一种类型(如stun协议、turn协议),这种类型能不能打通,相应的监测工具都是放在p2p这个文件夹下。
rtc_base;一些基础的东西,如锁线程,但是因为webrtc是跨平台的,不同平台实现这些基础东西都是大不一样的,因此这个相当于是一个统一的接口代码。
Rtc_tool;包括一些音频视频的分析工具,如对h264进行分析如I帧P帧NALU头信息都可以在rtc_tool下找到对应的工具
Tool_webrtc;是webrtc测试相关的工具,如单元测试 网络测试 音频视频的测试相关的都是在Tool_webrtc
System_warppers;这就是与具体平台相关的实现代码,如CPU特性,原子操作 锁线程的具体实现,大致是每个系统一个文件来自己实现的那种,
Stats;存放各种统计数据的,如丢包率,抖动时长,
Sdk;主要存放Android和IOS的代码层,如他们的音视频采集音频渲染等,
5、webRtc运行机制
5.1、两个概念Track & MediaStream
Track轨;一路音频是一路轨、一路视频也是一路轨,这里的轨就采用了轨道的概念两条轨之间是永远不相交的,则音频视频两路轨则是单独存放的永不相交的。
MediaStream流;借鉴传统媒体流的概念,流里面包括音频轨,视频轨,字幕轨。
从而可以得出MediaStream媒体流里面包含了很多Track轨,存在包含层级关系。
5.2、WebRTC重要的类
MediaStram;就是把媒体流在webrtc里面单独实现了一个类来表示
RTCPeerConnection;是整个webrtc当中最重要的一个类 大而全 里面包含了很多的功能,这样的设计对应上层的应用层十分方便,只需要创建一个RTCPeerConnection对象类连接,然后把MediaStram流扔进去就不用管了,包括底层传输,寻路,都由RTCPeerConnection在内部去执行了。但是在底层将RTCPeerConnection设计这么全面就需要做很多工作的,因为webrtc是p2p的传输,那么包括p2p类型的检测,p2p是否能够穿透打通,如果p2p穿透不成功那么我们还需要使用tun服务器进行中转,这些很多动作都是在RTCPeerConnection内部进行了完成,因此查看RTCPeerConnection源码是十分复杂的。但是对于我们写应用层的而言开发一个简单的视频会议demo就可以是十分简单的了。因此RTCPeerConnection是一个很重要的类,对于应用层而言我们需要知道他提供了哪些功能,我们可以使用哪些方法来增加应用的功能。分析webrtc源代码的时候也是需要根据他,因为他是一个很重要的点,涉及十分全面。
RTCDataChannel;非音视频的数据都是通过RTCDataChannel进行传输的,但是实际上RTCDataChannel是通过RTCPeerConnection类进行获取的。他们两者是存在关系的,因此我只要将RTCDataChannel数据拿到扔给RTCPeerConnection他,上层应用也就完成了。
总结;
RTCPeerConnection是一个核心,
对于音视频数据传输;MediaStram里面包含了很多轨,将这些轨添加到MediaStram之后,然后将MediaStram添加到RTCPeerConnection中去,这样就数据就会传输到对端去了。
对于非音视频数;首先根据RTCPeerConnection获取RTCDataChannel,然后将二进制数据设置到RTCDataChannel里面去,那么非媒体数据也就可以传输到对端了。
5.3、RTCPeerConnection的调用过程

图2
5.4、RTCPeerConnection的调用时序图
Offer sdb这些描述信息包含哪些信息;有哪些音频视频,音频视频格式是什么,传输地址是什么
信令的传输(TCP传输)和媒体流的传输(UDP传输)实际是两条路,
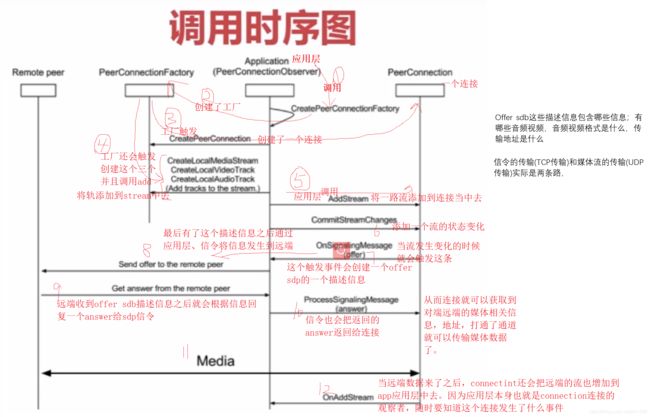
图3
6、Web服务器
6.1、Web服务器的概述
为什么要引入Web服务器,因为有很多应用程序,例子都是由JavaScript编写的,由于安全的原因很多浏览器如chrome他是不允许直接调用本地的JavaScript文件的,所以只能将JavaScript文件放到web服务器端,然后通过web服务器下载到本地,然后再运行这些程序。还有就是因为后面要编写信令服务器,也是采用web服务器的再加上一些库如socketIO来构建信令服务器的。因为这两个原因因此需要引入web服务器介绍。
Web服务器的选择,如今外界有很多类型的web服务器如Nodejs(特殊的,可以由JavaScript开发程序,那么就会存在由JavaScript写的服务器,将也是JavaScript写的应用程序也是放在服务端,这样浏览器发送一个html请求给服务器,将服务端的JavaScript应用程序代码下载到本地去执行,这样就是有两个JavaScript程序一个是控制服务器的,一个是下载到客服端去运行的,由技术的发展以后的一个趋势所有的代码都是JavaScript编写放到服务器当中去执行了,那么Nodejs就是很有未来发展的一个web服务器了,因为前端后端都是JavaScript)、Nginx(如今已经开始替代Apache,各个方面都要优于Apache)、Apache(比较老了)
6.2、Web服务器的工作原理
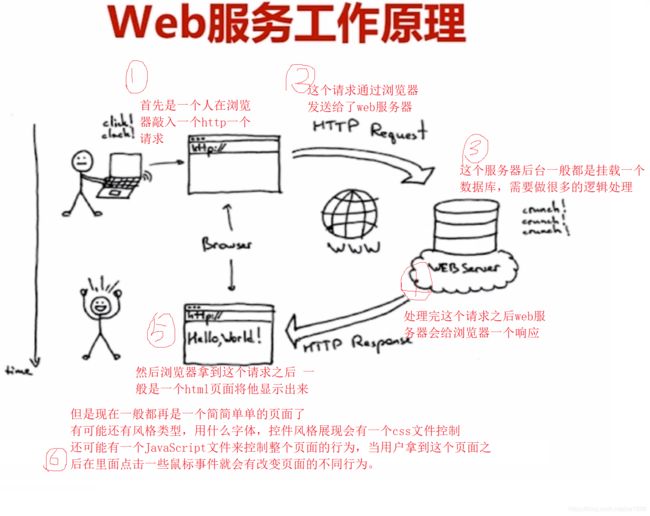
图4
6.3、Nodejs工作原理

图5
6.3、JavaScript解析流程
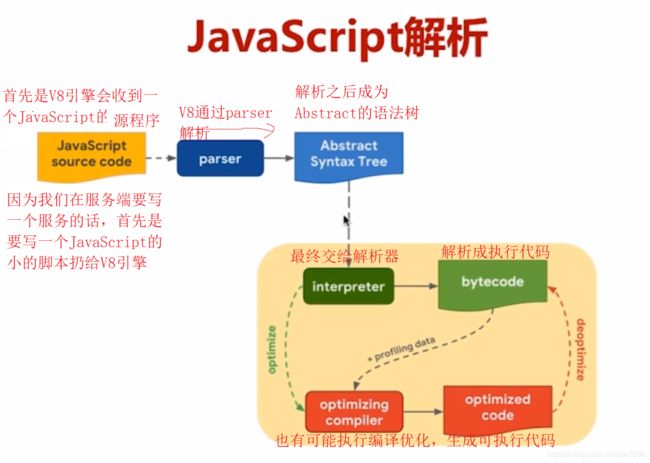
图6
6.4、nodejs事件处理

图7
6.5、两个V8引擎

图8
二、实战前准备
1、Nodejs安装
二进制库安装;更方便,只要通过对应系统的安装工具,敲一条命令就可以了,但是安装不能指定下载安装目录的
源码安装;下载nodejs的源码,生成makefile,进行编译最后安装
以centos下为例使用yum,mac下使用brew,Ubuntu使用apt
1.1、centos下二进制库安装 暂时失败
yum -y update 更新yum
yum search XXX 搜索云上nodejs库版本
yum -y install nodejs
yum install npm (npm是开发nodejs时所用的依赖库下载工具,依赖库都放在云上可以通过npm工具就可以将依赖库进行下载)
(但是我自己这边下载不了提示No package nodejs available.)
安装过程中网上链接
使用yum 安装时出现 : Loaded plugins: fastestmirror
https://blog.csdn.net/weixin_37282478/article/details/82152239
yum安装出现No package nodejs available解决办法
https://cloud.tencent.com/developer/article/1024124
1.2、centos下源码安装 暂时失败
http://nodejs.cn/download/ 官网地址
可以直接下载最小的gz包到共享文件夹的方式,也可以使用直接在命令行使用wget -c 链接的方式 -c的意思是断网后连接会接着继续下载。

图9
报错 C++ compiler (CXX=g++, 4.8.5) too old, need g++ 6.3.0
在nodejs源码编译时用到了gcc升级,由于源码使用到了c++,gcc版本太低,大于6.3即可
https://blog.csdn.net/w345731923/article/details/107204098
centos的源码安装也出现问题C++配置下载下载不了,暂时就切换到Ubuntu去实践了。
1.3、Ubuntu下二进制库下载
apt-cache search nodejs 查找源上库的版本和名字 其中nodejs - evented I/O for V8 javascript这个就是我们需要的
apt-get install nodejs 安装即可、注意安装是否出问题 可以nodejs -v 验证一下
apt-get install npm 安装依赖库npm,又出现以下问题
提示npm : Depends: node-gyp (>= 0.10.9) but it is not going to be installed 然后百度去下载这个又报错提示E: Couldn’t find any package by glob 'libssl1.0-dev’然后一直出错无法下载,后来想起百度突然看到aptitude选择源下载的方式,进行下载依赖库
aptitude install nodejs-dev node-gyp libssl1.0-dev (选择的时候选择N-Y-Y-Y即可选择下载成功)
然后再下载apt install npm 就成功了。
2、Nodejs 服务端demo开发
Nodejs开发服务端相比c/c++开发要简单很多,因为Nodejs相当于是更高级的语言一样,集成了很多强大的功能模块可以直接调用,就可以开发出很多功能程序、还有就是很多第三方的库我们也是可以直接导入加载进来直接使用的,就是nodejs的整个生态链发展得都很好了。
2.1、实现最简单的http服务
Nodejs搭建http服务的步骤;
require加载http模块 (require相当于java中的import关键字一样导入作用)
创建http服务;通过引入的http模块调用里面的接口创建服务
指定要侦听的端口 如8080
实操
1)具体代码解释
// use strict 表示使用strict最严格的语法 防止语法漏洞
'use strict'
// 引入http模块 因为nodejs本身支持的可以直接引入
var http = require('http');
// 通过http模块的API createServer 创建服务
// createServer里面是一个回调函数 req请求 res响应
// listen打开侦听,侦听端口8080,ip地址0就是表示监听所有的任意网卡
var app = http.createServer(function(req, res){
// http是分开包头和尾的 200表示响应成功 返回内容是txt文本
res.writeHead(200, {'Context-Type':'text/plain'});
// 响应结束返回一个字符串
res.end('Hello World\n');
}).listen(8080, '0.0.0.0');
还需要将该程序变成守护进程形式后台运行,
nodejs app.js 直接运行
nohub nodejs app.js & 这种方式是可以实现的只是日志输出有问题
forever start app.js 使用forever工具将服务变成后台(npm install forever -g 安装(-g表示配置该工具的环境变量))
forever stop app.js 表示暂停
npm安装forever 报错;Error: EACCES: permission denied
解决方法;(1条消息) 解决-安装node.js后,使用npm命令时报没有权限的错误Error: EACCES: permission denied_HuangLin的博客-CSDN博客 需要配置一下npm的环境
2)搭建本地测试
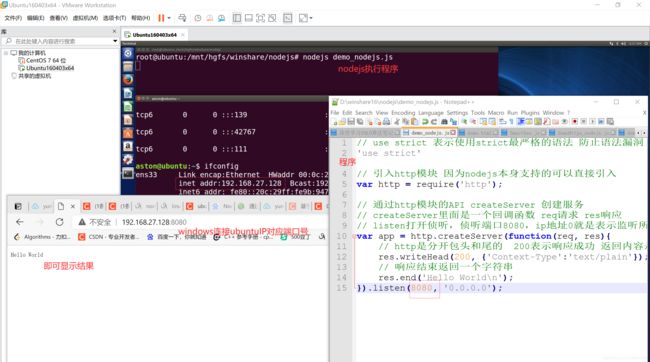
图10
2.2、创建https服务
因为音频视频设备都是涉及到个人的隐私问题,如何不使用https加密的服务访问去试图调用设备的音频摄像头是不允许的,因此只能使用https服务来调用。并且https也是未来的趋势,HTTPS = HTTP(明文) +TLS/SSL (加密算法) 其实https还包括证书认证,公钥私钥这些的。客户端需要拿到服务器的公钥将其进行加密,对与服务端来说需要私钥将客户端加密的内容进行解密。
Nodejs搭建https服务具体步骤
生成HTTPS证书(私有的(自己产生的,对于浏览器来说一般不认可),认证证书(对于浏览器来说需要第三方机构认证的证书,需要专门做网络安全的可以颁发证书))。
引入https模块(也是nodejs本身自带的)
指定证书位置,并且创建https服务
代码
// use strict 表示使用strict最严格的语法 防止语法漏洞
'use strict'
// 引入http模块 因为nodejs本身支持的可以直接引入
var http = require('http');
//给引入证书使用的模块
var fs = require('fs');
// 通过http模块的API createServer 创建服务
// createServer里面是一个回调函数 options主要用来传入认证证书的 req请求 res响应
// listen打开侦听,侦听端口8080,ip地址0就是表示监听所有的任意网卡
//json格式的
var options = {
key : fs.readFileSync('xxxx填证书key文件全路径'),
cert : fs.readFileSync('xxxx填证书cert文件全路径');
}
var app = http.createServer(options, function(req, res){
// http是分开包头和尾的 200表示响应成功 返回内容是txt文本
res.writeHead(200, {'Context-Type':'text/plain'});
// 响应结束返回一个字符串
res.end('HTTPS:Hello World\n');
}).listen(443, '0.0.0.0');
实操
需要证书暂不实现
2.3、实现本地https访问
如何在本地启动https服务_Lucky_Q的博客-CSDN博客
具体流程为
下载openssl
sudo apt-get install openssl
sudo apt-get install libssl-dev
生成本地证书
openssl genrsa -out privatekey.pem 1024
openssl req -new -key privatekey.pem -out certrequest.csr
openssl x509 -req -in certrequest.csr -signkey privatekey.pem -out certificate.pem
则会在当前文件下生成key;privatekey.pem 及证书certificate.pem
再实现js代码进行访问
// use strict 表示使用strict最严格的语法 防止语法漏洞
'use strict'
// 引入http模块 因为nodejs本身支持的可以直接引入
var https = require('https');
//给引入证书使用的模块
var fs = require('fs');
// 通过http模块的API createServer 创建服务
// createServer里面是一个回调函数 options主要用来传入认证证书的 req请求 res响应
// listen打开侦听,侦听端口8080,ip地址0就是表示监听所有的任意网卡
//json格式的
var options = {
key : fs.readFileSync('./privatekey.pem'),
cert : fs.readFileSync('./certificate.pem')
}
var app = https.createServer(options, function(req, res){
// http是分开包头和尾的 200表示响应成功 返回内容是txt文本
res.writeHead(200, {'Context-Type':'text/plain'});
// 响应结束返回一个字符串
res.end('HTTPS:Hello World\n');
}).listen(443, '0.0.0.0');
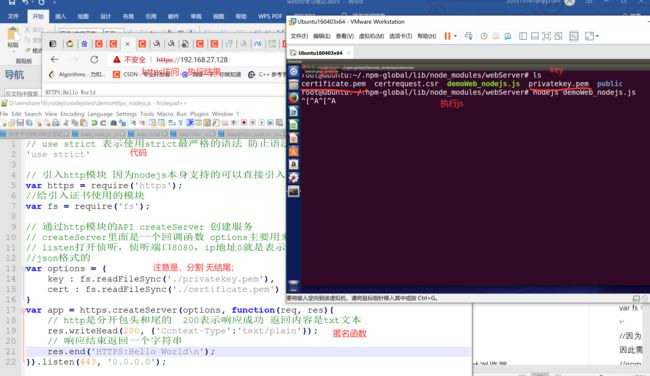
图23
2.4、实现真正的web服务实现访问目录
引入express模块 该模块是nodejs里面专门用于处理web服务的
引入serve-index模块 可以发布整个目录的,则这个目录下的所有文件都可以通过浏览器进行浏览
指定发布目录
注意;express、serve-index这两个模块不是nodejs自带的,需要npm下载;npm install serve-index -g、npm install express -g
代码
'use strict'
// 引入http模块 因为nodejs本身支持的可以直接引入
var http = require('http');
var https = require('https');
var fs = require('fs');
//因为express、serve-index不是nodejs自带的,因此需要npm安装一下
//npm install express serve-index 下载依赖模块
//用于web服务的专门模块
var express = require('express');
//用于导出目录文件的模块
var serveIndex = require('serve-index');
//创建http服务
//都传入express实例,之后回调的时候所有的请求都会传给express,让他帮我们处理
var app = express();
app.use(serveIndex('./public'))//到出这个目录
app.use(express.static('./public'))//使用发布的静态目录
var http_server = http.createServer(app);
http_server.listen(80, '0.0.0.0');
//创建https服务
var options = {
key : fs.readFileSync('./privatekey.pem'),
cert : fs.readFileSync('./certificate.pem')
}
var http_servers = https.createServer(options, app);
http_servers.listen(443, '0.0.0.0');
实践
图11
3、JavaScript基础学习
Webrtc的愿景就是希望大家使用开发浏览器的程序实现是音视频的应用,因此使用JavaScript学习webrtc是最快捷简便的方式。则可以通过webrct官方的先从应用层了解API及相关逻辑再往里面进行学习内核他是如何完成在不同平台设备去采集音频视频,音视频编解码,带宽评估及发送这些知识。
3.1、JavaScript的调试方法
主要是chrome自带的调试工具在具体网页右键点击检查就可以出来了。具体详情
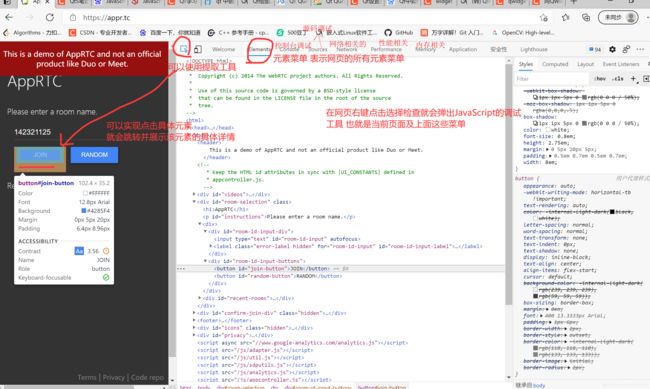
图12

图13

图14
3.2、JavaScript基础知识
快速入门是可以进行与一门擅长语言对比学习即可,但是要精通还是需要去系统了解看源码并经历大型项目的。
1) 变量与类型

图15
2) 基本运算
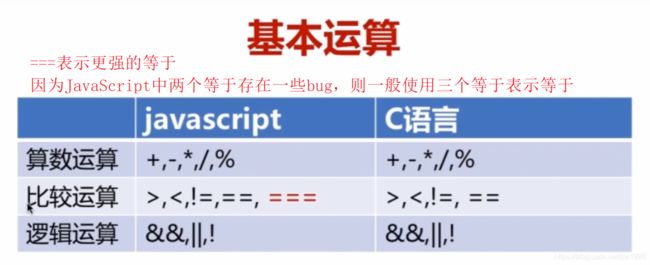
图16
实践

图17
3) if/else

图18
4) for循环

图19
5) 函数

图20
6)日志打印
console.log();打印
7) JavaScript几种存储数据的方式
字符串;
Blob;相当于一个非常高效的存储区域,其他类型的buffer是可以放到Blob里面的,从而可以将整个缓冲区写到文件里面十分方便,因此在实践中会把写文件之前把数据放到Blob里面再去写入。
ArrayBuffer;存储各种各样的数据,(Blob是对ArrayBuffer的封装,使得其更高效)
ArrayBufferView;
这些类型都可以作为Blob的一个参数,使用Blob进行高效管理。
4、webRtc相关内容
4.1、webRtc设备管理
通过enumerateDevices接口获取电脑中的音频和视频设备
var ePromise = navigator.mediaDevices. enumerateDevices();
ePromise类型中存在一个MediaDevicesInfo类(这个类中有device ID设备ID,label设备名字,kind设备种类(音频输入设备 输出设备 视频输入输出设备),groupID两个设备group ID相同则说明是同一个物理设备,如有的摄像头集成了摄像头和麦克风,则他们两个就是属于统一物理设备)
首先要知道JavaScript是使用单线程去执行的,因此在JavaScript当中大量的使用了异步调用的方式如handle。
总结就是首先需要自己创建一个handle传入到promis里面,并且handle里面需要两个回调函数,在执行完结果后会自动根据结果跳转成功or失败函数并设定状态机状态,并且promis可以根据then和catch创建函数,这两个函数根据执行handle的状态机结果进行自动执行的。
下面案例就是promis使用then和catch创建函数根据enumerateDevices结果状态机状态自动执行的
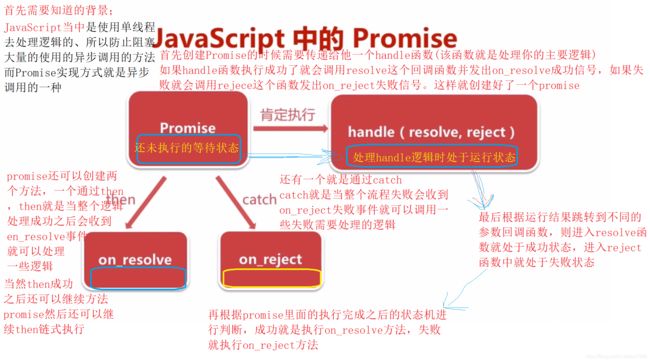
图21
Web实践输出音视频设备
// use strict 表示使用strict最严格的语法 防止语法漏洞
'use strict'
if(!navigator.mediaDevices ||
!navigator.mediaDevices.enumerateDevices){
console.log('emdiaDevices.enumerateDevices is not support!');
} else {
navigator.mediaDevices.enumerateDevices()
.then(gotDevices)
.catch(handleErroe);
}
function gotDevices(deviceInfos){
deviceInfos.forEach( function(deviceInfo){
console.log(deviceInfo.kind + ": label = "
+ deviceInfo.label + ": id = "
+ deviceInfo.deviceID + ": groupID = "
+ deviceInfo.groupID);
});
}
function handleErroe(err){
console.log(err.name + ":" + err.message);
}
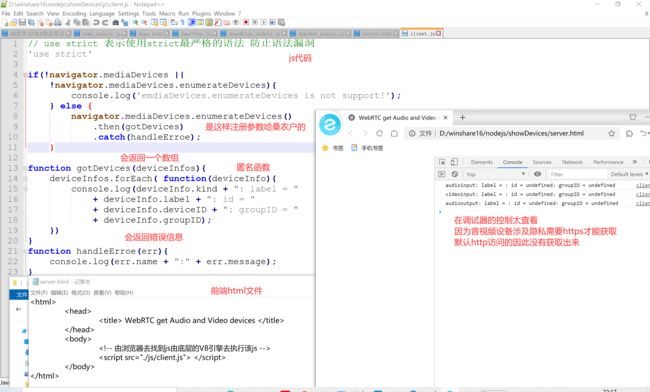
图22
本地https环境部署读取音视频设备号,还需要在浏览器设置将该IP的的访问权限都打开才能正常读取到各个设备的名称和ID

图24
界面展示电脑音视频设备名
html
<html>
<head>
<title> WebRTC get Audio and Video devices </title>
</head>
<body>
<!-- 由浏览器去找到js由底层的V8引擎去执行该js -->
<!-- 用选择框元素的方法展示音视频设备-->
<!-- 用div包含 后续可以做美化处理 -->
<div>
<label>audio input device:</label>
<select id="audioinput"></select>
</div>
<div>
<label>audio output device:</label>
<select id="audiooutput"></select>
</div>
<div>
<label>video input device:</label>
<select id="videoinput"></select>
</div>
<script src="./js/client.js"> </script>
</body>
</html>
JavaScript
// use strict 表示使用strict最严格的语法 防止语法漏洞
'use strict'
//获取html中的select元素 使用querySelector方法可以获取html中的指定元素
var audioinput = document.querySelector("select#audioinput");//select中的ID为daudioinput的元素
var audiooutput = document.querySelector("select#audiooutput");
var videoinput = document.querySelector("select#videoinput");
if(!navigator.mediaDevices ||
!navigator.mediaDevices.enumerateDevices){
console.log('emdiaDevices.enumerateDevices is not support!');
} else {
navigator.mediaDevices.enumerateDevices()
.then(gotDevices)
.catch(handleErroe);
}
function gotDevices(deviceInfos){
deviceInfos.forEach( function(deviceInfo){
console.log(deviceInfo.kind + ": label = "
+ deviceInfo.label + ": id = "
+ deviceInfo.deviceId + ": groupId= "
+ deviceInfo.groupId);
//在遍历每个设备的时候根据kind做判断
var option = document.createElement('option');//创建一个html的单元项
option.text = deviceInfo.label;
option.value = deviceInfo.deviceId;
if(deviceInfo.kind === 'audioinput'){
audioinput.appendChild(option);//上面获取的元素添加子元素
}else if(deviceInfo.kind === 'audiooutput'){
audiooutput.appendChild(option);
}else if(deviceInfo.kind === 'videoinput'){
videoinput.appendChild(option);
}
});
}
function handleErroe(err){
console.log(err.name + ":" + err.message);
}

图25
4.2、音视频采集
相关API的基本格式
var promise = navigator.mediaDevices.getUserMedia(constraints);
与获取设备的enumerateDevices的API类似也是返回promise类型的变量。这里采集音视频数据就是通过navigator下面的mediaDevices下面的getUserMedia方法、注意constraints参数(是MediaStreamConstraints类型的变量)
dictionary MediaStreamConstraints
{
(boolean or MediaTrackConstraints) video = false;
(boolean or MediaTrackConstraints) audio = false;
}
注意这个类型里面有两个元素,一个是video和audio,那就是说这个类型就是对视频,音频做一些限制。并且他们既可以是bool类型也可以是复杂的MediaTrackConstraints类型,如果是bool类型那么就是通知采集的数据是否包含音频,视频,如都为true那么他采集的数据就既有音频也有视频,如果是复杂类型MediaTrackConstraints那么就是设置具体的采集的参数设置,如音频的单双通道延迟音量大小,视频的分辨率帧率等。
html
<html>
<head>
<title>WebRTC capture video and audio</title>
</head>
<body>
<!-- video标签 可以显示捕捉的音视频数据 有几个属性 autoplay 表示拿到之后自动播放 playsinline 表示在浏览器页面播放不调用三方库 -->
<!-- 增加ID是为了在JavaScript中更好的捕获这个标签 -->
<video autoplay playsinline id="player"></video>
<!-- 加载JavaScript源码 -->
<script src="./js/client.js"></script>
</body>
</html>
JavaScript
//使用严格的检查语法
'use strict'
//获取html标签
var videoplay = document.querySelector('video#player');
//实现getUserMedia执行成功then绑定的回调函数 gotMediaStream
//会返回一个stream流其中包括了音频轨 视频轨 等多个轨,因为下面constraints设置采集音频 视频 则有两路轨
function gotMediaStream(stream){
videoplay.srcObject = stream;//将流赋值给video标签
}
function handleErroe(err){
console.log('getUserMedia error', err);
}
if(!navigator.mediaDevices ||
!navigator.mediaDevices.getUserMedia){
console.log('getUserMedia is not supported!');
}else{
//constraints 这个函数需要传参 then函数表示成功就执行gotMediaStream catch函数表示失败就自动执行handleErroe
// js格式的
var constraints = {
video : true,
audio : true
}
navigator.mediaDevices.getUserMedia(constraints)
.then(gotMediaStream)
.catch(handleErroe)
}
图26
4.3、WebRTC的API适配
在WebRTC规范出来之前,各个浏览器厂商都在按照自己的方法使用WEBRTC推动自己的API,那么就造成各个浏览器厂商使用的getUserMedia的具体名字是不一样的,都增加了自己的名称,如在规范里是规定使用getUserMedia来采集音视频数据,而谷歌里面是使用webKitGetUserMedia、如其他的有mozGetUserMedia。因此如果自己要实现适配分开都能调用的话就要这样使用
Var getUserMedia = navigator. getUserMedia || navigator.webKitGetUserMedia || navigator. mozGetUserMedia
根据||短路原则确定适配的,但是也是十分麻烦的。从而谷歌开发了一个开源库来适配这种问题就是adapter.js来适配各个不同的API。目前在我们开发应用程序的时候最好还是使用一些adapter进行一下适配,省去一些麻烦。
使用方法就是在html中增加一个script的js文件包含,真正使用的时候其实最好使用直接的版本号,而不是使用adapter-latest.js最新的,最新的可能之后会不支持旧版本的浏览器。
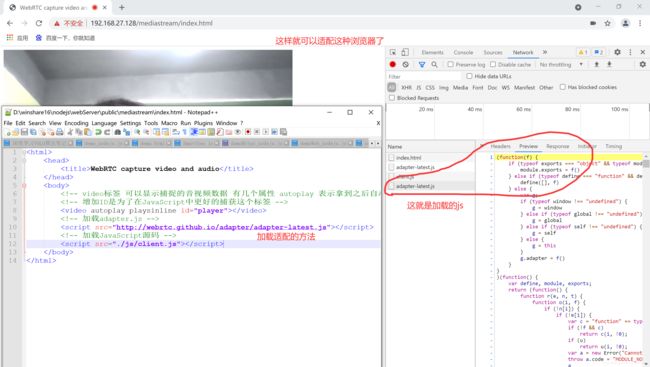
图27
4.4、根据视频流之后获取音视频设备,绕过权限访问
该案例主要是对于一些获取音视频设备有权限设置的
不能直接获取到而现在就是通过获取音视频流之后再获取音视频设备
效果图
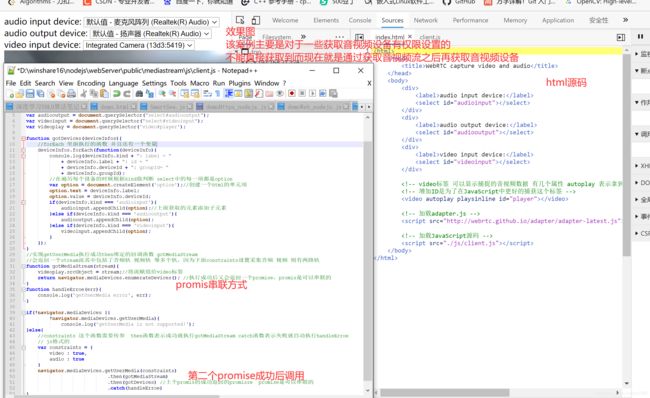
图28
4.5、音视频参数的约束
通过对音视频参数的约束那么我们就可以精确的控制音视频的采集数据。这里的设置就是设置前面说到的getUserMedia(constraints)里面的constraints类型的变量,以json格式设置
视频相关的
width 视频的宽度,height 高度 就是分辨率的大小,视频的宽高一般是两种比例4:3(要方一些如640480)、16:9(1080720 显示得更长一些,但是注意对于手机而言有需要翻过来了)。
aspectRatio;就是宽高的比例(宽除以高),一般不需要设置的,会根据宽高计算的,是一个小数。
frameRate 帧率 可以通过帧率的多少控制码流,帧率低则观看视频不够平滑会有卡顿的感觉,帧率高就视频平滑,帧率就是表示1s钟有多少帧(有多少张图片转换),帧率越大当然码流也会越大,因为1s钟采集的数据也变多了。
facingMode 控制摄像头的翻转的,对于手机特别合适,其中有几个参数表示(user表示前置摄像头、environment表示后置摄像头、left表示前置左侧摄像头、right表示前置右侧摄像头)对于PC端因为没有前后摄像头这一说法则pc端会忽略掉这一参数。
resizeMode 表示你采集的画面要不要裁剪,可以设置为null就是不改变,还可以进行裁剪设置。
注意width、height、frameRate不仅可以设置固定值还可以设定min,max这个时候浏览器会自动在范围内选择一个合适的进行设置。Width:{min:300,max:480}
音频相关的
volume 音量相关的,注意设置是从0-1.0,0表示静音,1表示最大声音
sampleRate 采样率 音频中有48000,32000,12000,8000等等很多
sampleSize 采样大小 就是每个采样由多少位表示 一般都是16表示 注意一般麦克风硬件不支持8位的,所以音视频采集时需要音频重采样转换。
echoCancellation 回音消除,就是采集数据后是否需要开启回音消除,在实时通讯回音消除是很有必要的, 是设置true和false
autoGainControl 自动增益,就是在原有录音音频的基础上进行增加音量,增加有一定范围的,也是设置true和false
noiseSuppression 降噪 就是采集数据的时候是否需要采集降噪功能
latency 延迟大小,当我们直播视频过程中延迟大小,这里设置小的话那么在视频实时传输的时候延迟就小,延迟小的后果就是当网络不好的情况时候就会出现卡顿花屏的现象引出质量问题,但是好处就是双方可以进行实时通讯,延迟很小。Latency延迟设置大的话那么好处就是音频视频更加平滑,但是及时性不好。
channelCount 单双通道,进行通话一般都是单通道,但是演奏乐器的时候采用双通道这样音质更好。
音视频共同有的参数
deviceID 设备ID 当有多个摄像头或者音频设备的时候可以根据deviceID进行切换采集对象。
groupID 同一个物理设备groupID是一致的。
案例;实现根据html的select选择不同的视频采集设备进行播放
html
<html>
<head>
<title> WebRTC get Audio and Video devices </title>
</head>
<body>
<!-- 由浏览器去找到js由底层的V8引擎去执行该js -->
<!-- 用选择框元素的方法展示音视频设备-->
<!-- 用div包含 后续可以做美化处理 -->
<div>
<label>audio input device:</label>
<select id="audioinput"></select>
</div>
<div>
<label>audio output device:</label>
<select id="audiooutput"></select>
</div>
<div>
<label>video input device:</label>
<select id="videoinput"></select>
</div>
<script src="./js/client.js"> </script>
</body>
</html>
javasript
//使用严格的检查语法
'use strict'
//获取html标签
var audioinput = document.querySelector("select#audioinput");//select中的ID为daudioinput的元素
var audiooutput = document.querySelector("select#audiooutput");
var videoinput = document.querySelector("select#videoinput");
var videoplay = document.querySelector('video#player');
function gotDevices(deviceInfos){
//forEach 里面执行的函数 并且还有一个变量
deviceInfos.forEach(function(deviceInfo){
console.log(deviceInfo.kind + ": label = "
+ deviceInfo.label + ": id = "
+ deviceInfo.deviceId + ": groupId= "
+ deviceInfo.groupId);
//在遍历每个设备的时候根据kind做判断 select中的每一项都是option
var option = document.createElement('option');//创建一个html的单元项
option.text = deviceInfo.label;
option.value = deviceInfo.deviceId;
if(deviceInfo.kind === 'audioinput'){
audioinput.appendChild(option);//上面获取的元素添加子元素
}else if(deviceInfo.kind === 'audiooutput'){
audiooutput.appendChild(option);
}else if(deviceInfo.kind === 'videoinput'){
videoinput.appendChild(option);
}
});
}
//实现getUserMedia执行成功then绑定的回调函数 gotMediaStream
//会返回一个stream流其中包括了音频轨 视频轨 等多个轨,因为下面constraints设置采集音频 视频 则有两路轨
function gotMediaStream(stream){
videoplay.srcObject = stream;//将流赋值给video标签
return navigator.mediaDevices.enumerateDevices(); //执行成功后又会返回一个promise,promis是可以串联的
}
function handleErroe(err){
console.log('getUserMedia error', err);
}
function start(){
if(!navigator.mediaDevices ||
!navigator.mediaDevices.getUserMedia){
console.log('getUserMedia is not supported!');
}else{
//constraints 这个函数需要传参 then函数表示成功就执行gotMediaStream catch函数表示失败就自动执行handleErroe
// js格式的
var deviceId = videoinput.value;
var constraints = {
video : {
width:320,
height:240,
frameRate:30,
facingMode:'user',
deviceId : deviceId ? deviceId : undefined
},
audio : {
noiseSuppression:true,
echoCanccellation:true
}
}
navigator.mediaDevices.getUserMedia(constraints)
.then(gotMediaStream)
.then(gotDevices) //上个promis的成功返回的promisze promise是可以串联的
.catch(handleErroe)
}
}
//以执行js文件就是从这里开始 没有main函数的那种入口
start();
//指定 html的select选择变化 事件
videoinput.onchange = start();
4.6、视频渲染特效
注意在webrct中对视频进行特效采用的是CSS fiter,在不同的浏览器中使用的fiter名称还有点不一样,如还有-webkit-fiter、filter。
如何将视频video和filter进行关联,
我们通过CSS渲染实践在浏览器的底层最终调用的还是opengl或者metal这种基础的图形数据库通过GPU进行渲染绘制。
支持的特性种类有;grayscale灰度、opacity透明的、sepia褐色、brightness亮度、saturate饱和度、contrast对比度、hue-rotate色相旋转、blur模糊、invert反色、drop-shadow阴影
实践
在select里面选择对应的filter,然后视频显示的CSS类就绑定选择的filter,最后使用的就是在style里面的具体CSS特效了。
图29
4.7、从视频流中获取图片
可以在直播或者通话或共享桌面的时候就可以在这些视频流里面某一帧的视频帧(也就是一张图片),从而还可以对这些图片进行编辑。
通过html中的canvas这个标签来显示图片,整体就是从视频流里面获取某一帧图片然后显示,实际的整体流程就是先拿到视频流再借助两个元素button(用于截取点击时机的那一帧)、canvas具体将那一帧获取到后输出成我们想要的图片。
图30
4.8、只有音视频数据播放
只有音频数据进行播放需求还是比较大的,如语音通话等等都是没有视频的。
Html中的audio标签的controls属性表示把音频播放暂停的按钮显示出来,autoplay属性表示已进入就自动播。

图31
4.9、MediaStream里面的一些方法事件
相关API
MediaStream.addTrack();就是想stream流里面添加轨,之前讲了webrtc里面就是一端通信就是表示一条媒体流,而媒体流里面就包括很多轨,音频轨,视频轨,字幕轨都是一条条轨组成需要addTrack();来进行添加。
MediaStream.removeTrack();将不想要的媒体轨移除。
MediaStream.getVideoTracks();获取当前流的所有视频轨,从而根据需求去关注自己关心的视频轨。
MediaStream.getAudioTracks();获取媒体流当中所有的音频轨
MediaStream.stop();可以将媒体流关闭掉,就是调用媒体流当中每个轨的stop进行关闭的。
相关事件
MediaStream.onaddTrack();就是增加一条媒体轨到媒体流当中的时候会触发这个事件。
MediaStream.onremoveTrack();
MediaStream.onended();当流 结束的时候会触发流结束的事件
案例;打印出视频的约束条件参数
图32
4.10、MediaRecoder 媒体流的录制
基本格式;
Var mediaRecorder = new MediaRecorder(stream[,options]);
stream ;媒体流可以从getUserMedia、<video>标签或<audio>、<canvas>标签获得。
Options;限制选项
mimeType指定录制的是音频还是视频,录制的封装格式及编码进行设置。
audioBitsPerSecond 音频码率,
videoBitsPerSecond 视频码率(设置越高清晰度越高),
bitsPerSecond 整体码率。
常用API;
MediaRecoeder.start(timeslice);开始录制媒体,timeslice可选的,如果没有选择那么录制的文件都会存储到一个大的buffer里面,如果设置了那么就会按照时间切片进行存储数据。
MediaRecoeder.stop();停止录制,此时会触发包括最终Blob数据的dataavilable事件就是最后一帧的数据也会录制进去。
MediaRecoeder.pause();暂停录制
MediaRecoeder.resume();恢复录制
MediaRecoeder.isTypeSupported();查看录制支持的封装格式如mp4,mp3
常见事件;
MediaRecoeder.ondataavilable 当数据有效的时候会触发该事件,可以监听这个事件当事件有效了,
就可以直接把数据存储到存储区里(会传过来一个event里面有个data,就是真正的录制的数据,就是拿到这个数据后进行存储)。
每次记录一定时间的数据时(如果没有指定时间片,则记录整个数据时)会定期触发。
MediaRecoeder.onerror 当发生错误的时候,会触发该事件,并录制会被终止。
实践;实现媒体流的录像播放及下载
图33
代码
---------------------------html
<html>
<head>
<title>WebRTC capture video and audio</title>
<!-- 在style里面写一些CSS的控制 与选项filter是一一对应的-->
<style>
.none {
-webkit-filter: none;
}
.blur {
-webkit-filter: blur(3px);
}
.grayscale {
-webkit-filter: grayscale(1);
}
.invert {
-webkit-filter: invert(1);
}
.sepia {
-webkit-filter: sepia(1);
}
</style>
</head>
<body>
<section>
<!-- 音视频设备的显示及选择控件 -->
<div>
<label>audio input device:</label>
<select id="audioinput"></select>
</div>
<div>
<label>audio output device:</label>
<select id="audiooutput"></select>
</div>
<div>
<label>video input device:</label>
<select id="videoinput"></select>
</div>
<div>
<!-- 建一个表来选择视频特效,与视频进行关联起来-->
<label>Filters:</label>
<select id="filter">
<option value="none">None</option>
<option value="blur">blur</option>
<option value="grayscale">grayscale</option>
<option value="invert">invert</option>
<option value="sepia">sepia</option>
</select>
</div>
</section>
<!-- video标签 可以显示捕捉的音视频数据 有几个属性 autoplay 表示拿到之后自动播放 playsinline 表示在浏览器页面播放不调用三方库 -->
<!-- 增加ID是为了在JavaScript中更好的捕获这个标签 -->
<!-- 用一个表 tr表示行 td表示列 建立一个一行两列(一列显示视频 一列显示参数信息)-->
<section>
<table>
<tr>
<td>
<video autoplay playsinline id="player"></video>
</td>
<td>
<video playsinline id="recplayer"></video>
</td>
<td>
<!-- class是指定CSS样式 -->
<div id='constraints' class='output'></div>
</td>
</tr>
<tr>
<td><button id="record">Start Record</button></td>
<td><button id="recplay" disabled>Play</button></td>
<td><button id="download" disabled>Down load</button></td>
</tr>
</table>
</section>
<!-- <audio autoplay controls id="audioplayer"></audio> -->
<!-- 点击button 获取当时视频帧的图片显示 -->
<div>
<button id="snapshot">Take snapshot</button>
</div>
<div>
<canvas id="picture"></canvas>
</div>
<!-- 加载adapter.js -->
<script src="http://webrtc.github.io/adapter/adapter-latest.js"></script>
<!-- 加载JavaScript源码 -->
<script src="./js/client.js"></script>
</body>
</html>
-----------------------------js
//使用严格的检查语法
'use strict'
//获取html标签
var audioinput = document.querySelector("select#audioinput");//select中的ID为daudioinput的元素
var audiooutput = document.querySelector("select#audiooutput");
var videoinput = document.querySelector("select#videoinput");
var videoplay = document.querySelector('video#player');
//var audioplay = document.querySelector('audio#audioplayer');
var filtersSelect = document.querySelector('select#filter');
var snapshot = document.querySelector('button#snapshot');
var picture = document.querySelector('canvas#picture');
var divConstraints = document.querySelector('div#constraints');
var recvideo = document.querySelector('video#recplayer');
var btnRecord = document.querySelector('button#record');
var btnPlay = document.querySelector('button#recplay');
var btnDownload = document.querySelector('button#download');
var buffer;//保存录像有效数据
var mediaRecorder;//因为在不同函数都要访问,需定位为全局
//需要给canvas设置具体的宽高,就是图片显示的大小
picture.width = 320;
picture.height = 240;
function gotDevices(deviceInfos){
//forEach 里面执行的函数 并且还有一个变量
deviceInfos.forEach(function(deviceInfo){
console.log(deviceInfo.kind + ": label = "
+ deviceInfo.label + ": id = "
+ deviceInfo.deviceId + ": groupId= "
+ deviceInfo.groupId);
//在遍历每个设备的时候根据kind做判断 select中的每一项都是option
var option = document.createElement('option');//创建一个html的单元项
option.text = deviceInfo.label;
option.value = deviceInfo.deviceId;
if(deviceInfo.kind === 'audioinput'){
audioinput.appendChild(option);//上面获取的元素添加子元素
}else if(deviceInfo.kind === 'audiooutput'){
audiooutput.appendChild(option);
}else if(deviceInfo.kind === 'videoinput'){
videoinput.appendChild(option);
}
});
}
//实现getUserMedia执行成功then绑定的回调函数 gotMediaStream
//会返回一个stream流其中包括了音频轨 视频轨 等多个轨,因为下面constraints设置采集音频 视频 则有两路轨
function gotMediaStream(stream){
videoplay.srcObject = stream;//将流赋值给video标签
//audioplay.srcObject = stream;
//获取当前媒体流的所有视频轨的第一个
var videoTrack = stream.getVideoTracks()[0];
//获取到video的所有约束
var videoConstraints = videoTrack.getSettings();
//他是一个Constraints对象类型 需要转换为json格式 2表示缩进的宽度 2个空格
//并赋值到div标签内容里面
divConstraints.textContent = JSON.stringify(videoConstraints, null, 2);
//在这里将获取到的流赋值给全局变量window里面
window.stream = stream;
return navigator.mediaDevices.enumerateDevices(); //执行成功后又会返回一个promise,promis是可以串联的
}
function handleErroe(err){
console.log('getUserMedia error', err);
}
function start(){
//getUserMedia getDisplayMedia
if(!navigator.mediaDevices ||
!navigator.mediaDevices.getUserMedia){
console.log('getUserMedia is not supported!');
}else{
//constraints 这个函数需要传参 then函数表示成功就执行gotMediaStream catch函数表示失败就自动执行handleErroe
// js格式的
var deviceId = videoinput.value;
var constraints = {
video : {
width:320,
height:240,
frameRate:30,
facingMode:'user',
deviceId : deviceId ? deviceId : undefined
},
/*video : false,*/
audio : {
noiseSuppression:true,
echoCanccellation:true
}
}
//getUserMedia getDisplayMedia
navigator.mediaDevices.getUserMedia(constraints)
.then(gotMediaStream)
.then(gotDevices) //上个promis的成功返回的promisze promise是可以串联的
.catch(handleErroe)
}
}
//以执行js文件就是从这里开始 没有main函数的那种入口
start();
//指定 html的select选择变化 事件
videoinput.onchange = start();
//filter select事件处理
filtersSelect.onchange = function(){
//播放视频的标签使用的CSS类 使用filtersSelect选择的值
//videoplay.className = filtersSelect.value;
}
//实现button的触发事件,去截取事件
snapshot.onclick = function(){
//调用canvas中的drawImage方法 因为获取图片是2d的则上下文获取传参2d
//drawImage 传参 视频源 图片的起始点xy,图片大小宽高
picture.className = filtersSelect.value; //也可以设置图片的特效CSS为选择的特效
picture.getContext('2d').drawImage(videoplay, 0, 0, picture.width, picture.height);
}
//实现录像有效数据的触发事件并保存数据
function handleDataAvailable(e){
if(e && e.data && e.data.size > 0){
buffer.push(e.data);//将录像的有效数据放到buffer里面
}
}
function startRecord(){
buffer = [];//保存录像有效数据
//因为在gotMediaStream的时候将获取到的stream添加到全局的window里面了,现在就可以直接调用
var options = {
//音视频都有的时候叫video,只有音频叫avideo
mimeType: 'video/webm;codecs=vp8'
}
//判断options传入值浏览器是否支持
if(!MediaRecorder.isTypeSupported(options.mimeType)){
console.error('${options.mimeType} is not supported!');
return ;
}
try{
mediaRecorder = new MediaRecorder(window.stream, options);
}catch(e){
console.error('Failed to creat MediaRecorder!', e);
return ;
}
//有效数据的触发事件
mediaRecorder.ondataavailable = handleDataAvailable;
//每隔10个时间片存储一次数据
mediaRecorder.start(10);
}
function stopRecord(){
//mediaRecorder需定义为全局
mediaRecorder.stop();
}
//点击开始录制,再次点击实现停止录制 并且设置播放和下载按钮状态
btnRecord.onclick = ()=> {
if(btnRecord.textContent == 'Start Record'){
startRecord();
btnRecord.textContent = 'Stop Record';
btnPlay.disabled = true;
btnDownload.disabled = true;
}else{
stopRecord();
btnRecord.textContent = 'Start Record';
btnPlay.disabled = false;
btnDownload.disabled = false;
}
}
btnPlay.onclick = ()=> {
//创建一个Blob对象 第一个参数就是buffer 第二个就是一个类型指定buffer里面存储的类型
var blob = new Blob(buffer, {type: 'video/webm'});
//video标签播放就是给src设置一个url就可以播放了
recvideo.src = window.URL.createObjectURL(blob);//拿到播放视频的位置
//实时获取数据的时候才需要把stream赋值给srcObject,此时不需要则赋值为null
recvideo.srcObject = null;
//播放时控制标签 控制是否播放
recvideo.controls = true;//就是显示播放的箭头标识
recvideo.play();
}
btnDownload.onclick = ()=>{
var blob = new Blob(buffer, {type: 'video/webm'});
var url = window.URL.createObjectURL(blob);//创建一个url
var a = document.createElement('a');//创建一个a,就是html中的a 用于下载用的
a.href = url;//设置a的url下载地址
a.style.display = 'node';//是否显示
a.download = 'aaa.webm';//下载名称
a.click();
}
4.11、getDisplayMedia采集桌面屏幕数据
与音视频流的getUserMedia采集基本一致的
相关API的基本格式
var promise = navigator.mediaDevices. getDisplayMedia (constraints);详情可以查看4.2
但是注意在chrome谷歌里面该功能是实验性的需要设置chrome://flags里面的Experimental Web Platform features设置打开。
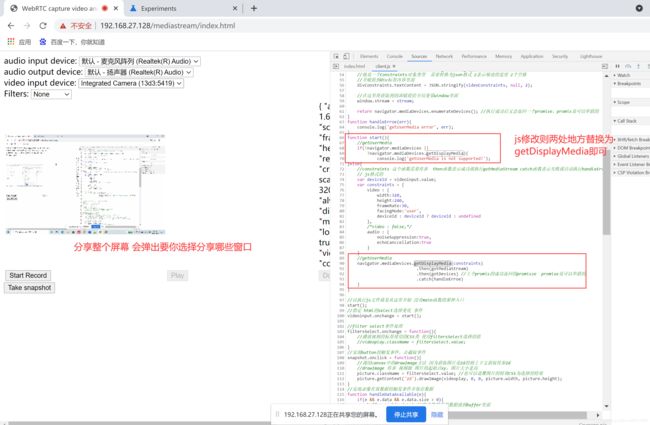
图34
5、webRtc相关内容-socket相关
5.1、使用socket.io发送消息
1)给本次连接发送消息;socket.emit();就是客户端给服务端发送消息,当服务端收到消息之后,会返回回复一个callback。如客户端发送消息给服务端要创建房间,服务端创建好了之后返回消息给客户端,这样客户端收到消息后就可以知道房间已经创建好了可以下一步逻辑操作了,从而达到异步操作的效果。这就是面对本次连接发送消息,告诉这个客户端房间创建好了。
2)给某个房间内的所有人发信息;类似与广播,所有人也包括自己;io.in(room).emit();【io表示一个整个的节点就是部署socket服务上层所有的人的一个节点,in表示某一个具体的房间;也可以使用io. socket.in(room).emit();】如房间为例,有的业务逻辑是每个端都需要维护一个客户列表,就是房间每次人进入或退出房间里面的每个端都应该收到这个退出加入的消息,从而加入删除自己维护的客户列表里面去。
3)除了本连接外,给某房间的所有人发消息;就是在这个房间内,我发送的这个消息就我自己不收到,但是房间其他人都收到,socket.to(room).emit(),如发送全体静音,不让别人说话但是自己可以说话。
4)除本连接外,给所有人发消息;socket.broadcast.emit(),、注意这里是所有的人也就是所有房间的所有人,上面是具体某个房间内的所有人,因为在一个socket服务节点里可能存在多个房间的情况。例如发送消息让所有用户都断开连接去连接另外的socket,这个时候就可以用到broadcast,并且用超级管理员权限执行断开操作。
5.2、使用socket.io客户端收到处理消息
1)发送action命令
S:socket.emit(‘action’);
C: socket.on(‘action’,function(){….});
2)发送一个action命令,还有data数据
S:socket.emit(‘action’,data);
C: socket.on(‘action’,function(data){….});
3)发送一个action命令,还有带2个data数据
S:socket.emit(‘action’,arg1, arg2);
C: socket.on(‘action’,function(arg1, arg2){….});
4)发送一个action命令,在emit方法中包含回调函数,就是在服务端已经写好了一个函数,在客户端直接调用即可。
S:socket.emit(‘action’,data, function(arg1, arg2));
C: socket.on(‘action’,function(data, fn){……fn(a,b)……});//在函数里面就可以调用传过来的回调函数fn并传参。
5.3、webRTC信令服务器
webRTC的规范是没有包含信令服务器这一块的,主要是规范客户端这块,因为每个公司业务模型都是不一样,就很难把各个公司的信令服务器都定义成一套规范,所以干脆服务器那块就由各个公司自己去定义,只要保证webRTC中一些必须信息的交换就可以了,其他具体业务都可以自己去定义,这样就比较灵活了,更利于webRTC在各个公司的使用推广。
首先要清楚,如果没有信令服务器那么webRTC之间是肯定不能通信的。
信令服务器在整个webRTC的通信过程中起到的作用
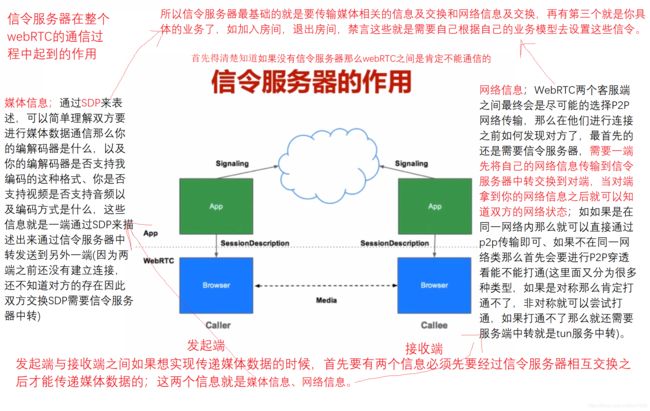
图35
媒体信息;通过SDP来表述,可以简单理解双方要进行媒体数据通信那么你的编解码器是什么,以及你的编解码器是否支持我编码的这种格式、你是否支持视频是否支持音频以及编码方式是什么,这些信息就是一端通过SDP来描述出来通过信令服务器中转发送到另外一端(因为两端之前还没有建立连接,还不知道对方的存在因此双方交换SDP需要信令服务器中转)
网络信息;WebRTC两个客服端之间最终会是尽可能的选择P2P网络传输,那么在他们进行连接之前如何发现对方了,最首先的还是需要信令服务器,需要一端先将自己的网络信息传输到信令服务器中转交换到对端,当对端拿到你的网络信息之后就可以知道双方的网络状态;如如果是在同一网络内那么就可以直接通过p2p传输即可、如果不在同一网络类那么首先会要进行P2P穿透看能不能打通(这里面又分为很多种类型,如果是对称那么肯定打通不了,非对称就可以尝试打通,如果打通不了那么就还需要服务端中转就是tun服务中转)。
总结
所以信令服务器最基础的就是要传输媒体相关的信息及交换和网络信息及交换,再有第三个就是你具体的业务了,如加入房间,退出房间,禁言这些就是需要自己根据自己的业务模型去设置这些信令。
5.4、这些信令服务器为什么要使用socket.io
1) 首先socket.io是webSocket的一个超集,本身就是有webSocket的功能,
我们知道在整个音视频传输的时候一般有两种协议udp和tcp,在底层协议里使用udp主要用于流媒体的传输如音频视频文字信息等,udp的问题就是在于不可靠的传输是可以丢包的,因此用于音视频来说丢包是没有问题的,不太影响实践运行。而对于信令来说就必须是可靠性的连接,如果丢包了就会导致流程运行问题了直接断开结束了,如我们的媒体信息或网络信息不能正常达到交换的话那么整个通信肯定是不能工作的,因此对于信令来说就是使用TCP。所以webSocket底层使用的是tcp,从而socket.io底层也是用的tcp协议,
2) socket.io本身就有房间的概念;
可以知道如果是两个人或三个人,多个人进行通讯的时候,那么首先就是要进入一个房间里面,这是一个很正常的逻辑,如开会,聚会,多个人聚集在一起通话视频那么就很自然的引申出来房间的概念。进入到一个房间里面那么大家就可以互相通信了,网络上也就有了房间这个虚拟的词。socket.io本身就带了房间的概率那么在实践通信的时候就不需要再自己搭建room服务器了,webRTC官方的案例就是有三个服务器(房间服务器;提供房间的用户的进与出,信令服务;最起码的交换媒体网络信息和业务信令,中转服务器;流媒体的中转服务),而我们使用socket.io库那么就可以不用再单独实现房间服务器了,这里房间服务器和信令服务器是集成到了一起的。
3) socket.io跨平台,跨终端,跨语言;
可以在各个平台上运行socket.io的库,并且跨语言可以在不同的语言上都可以使用socket.io库,从而便于我们在各个终端实现我们信令的客户端然后与我们的服务端进行连接,十分方便。

图36
5.5、实践 引入socket.io构建信令服务器部分基本流程
1) 安装socket.io
注意在/root/.npm-global/lib/node_modules这个下面进行npm安装(最之前的安装目录,运行程序也在则这里运行,否则找不到库),否则会报npm ERR! code ENOENT错误
解决Ubuntu下npm install socket.io失败 nodejs库版本与socket.io版本不一致问题,更新到最新的库。
aptitude install curl
curl -sL https://deb.nodesource.com/setup_14.x | sudo -E bash -
https://blog.csdn.net/Crisf/article/details/113618976
具体安装;npm install socket.io log4js
编译时遇到socketIO.listen方法报错,因为新3.xx版本不支持,可以修改为新版本支持的代码也可以将socket.io版本卸载安装低版本的。npm uninstall socket.io、npm install [email protected]
2) 引入socket.io
3) 处理connections消息(就是客户端连接服务器之后,在socket底层会触发一个connections消息,在上层我们监听这个消息就可以了)
4) 其余的消息处理就可以根据自己的业务来了。
5.6、使用socket.IO构建简单聊天室
服务器端;需要引入socket.io,并且与https服务绑定,并且实现有客户端连入时相关的消息转发处理逻辑。
客户端;前端的html文件布局设置,后端的client.js实现,同样也是实现与服务器那段相关消息的处理逻辑。注意两边消息定义是共同决定的,保持一致即可进行on,emit对应
图37
代码
服务器代码demoWeb_nodejs.js
// use strict 表示使用strict最严格的语法 防止语法漏洞
'use strict'
// 引入http模块 因为nodejs本身支持的可以直接引入
var http = require('http');
var https = require('https');
var fs = require('fs');
//因为express、serve-index不是nodejs自带的,因此需要npm安装一下
//npm install express serve-index 下载依赖模块
//用于web服务的专门模块
var express = require('express');
//用于导出目录文件的模块
var serveIndex = require('serve-index');
//引入socket.io库
var socketIO = require('socket.io');
//加入日志服务
var log4js = require('log4js');
//配置一下log4js的配置
log4js.configure({
appenders:{
file:{
type: 'file',
filename: 'app.log',
layout:{
type:'pattern',
pattern:'%r %p - %m',
}
}
},
categories:{
default:{
appenders: ['file'],
level: 'debug'
}
}
});
//获取一个log实例 服务器就不能用consle打印了而是要使用日志了
var logger = log4js.getLogger();
//创建http服务
//都传入express实例,之后回调的时候所有的请求都会传给express,让他帮我们处理
var app = express();
app.use(serveIndex('./public'))//到出这个目录
app.use(express.static('./public'))//使用发布的静态目录
var http_server = http.createServer(app);
http_server.listen(80, '0.0.0.0');
//创建https服务
var options = {
key : fs.readFileSync('./privatekey.pem'),
cert : fs.readFileSync('./certificate.pem')
}
//将https服务与socket.io进行绑定,之后再一起绑定监听443端口复用端口
var http_servers = https.createServer(options, app);
//绑定的socket叫做io,就是一个总节点一样,来进行管理。
var io = socketIO.listen(http_servers);//socketIO与https服务进行绑定
//var io = socketIO(http_servers);//listen方法新版本3.xx已不支持
//处理消息 sockets就是表示每个客户端,就相当于IO节点里面的一个连接
//处理连接,说明有客户端连接来了 并处理两个消息 加入房间 离开房间
io.sockets.on('connection', (socket)=>{
//处理join加入房间消息 join是自己定义的,并带一个参数:房间名字或ID唯一标识一个房间就可以了,别两个房间相同ID
socket.on('join',(room)=>{
socket.join(room);//这是调用socketIO里面自带的房间服务器里面的join功能
//创建加入房间,从而可以知道房间有多少人,每创建一个房间就会在rooms里添加一个
var myroom = io.sockets.adapter.rooms[room];//获取房间对象
var users = Object.keys(myroom.sockets).length;//获取房间里面人数
//socket.emit('joined', room, socket.id);//给客户端本人回
//socket.to(room).emit('joined', room, socket.id);//给房间里面的除了自己的所有人发送
io.in(room).emit('joined', room, socket.id);//给房间里面所有人发送
//socket.broadcast.emit('joined', room, socket.id);//给整个站点的所有人发除了自己
logger.log('the number of user in room is: ' + users);
});
//处理用户离开
socket.on('leave',(room)=>{
socket.leave(room);//这是调用socketIO里面自带的房间服务器里面的join功能
//创建加入房间,从而可以知道房间有多少人,每创建一个房间就会在rooms里添加一个
var myroom = io.sockets.adapter.rooms[room];//获取房间对象
var users = Object.keys(myroom.sockets).length;//获取房间里面人数
//socket.emit('joined', room, socket.id);//给客户端本人回
//socket.to(room).emit('joined', room, socket.id);//给房间里面的除了自己的所有人发送
io.in(room).emit('joined', room, socket.id);//给房间里面所有人发送
//socket.broadcast.emit('joined', room, socket.id);//给整个站点的所有人发除了自己
logger.log('the number of user in room is: ' + users);
});
socket.on('message',(room, data)=>{
io.in(room).emit('message',room, data);
logger.log('message is: ' + data);
});
});
http_servers.listen(443, '0.0.0.0');//从而443端口是一个复用端口即可响应web服务又可以响应socket信令消息服务
客户端代码
html
<html>
<head>
<title>Chat Room</title>
</head>
<body>
<table align="center">
<!-- 输入用户名的行 -->
<tr>
<td>
<label>UserNmae: </label>
<input type=text id="username"></input>
</td>
</tr>
<!-- 输入房间号和连接按钮行 -->
<tr>
<td>
<label>room: </label>
<input type=text id="room"></input>
<button id="connect">connect</button>
</td>
</tr>
<!-- 显示聊天内容框框行 不让编辑的 -->
<tr>
<td>
<!-- br表示换行 -->
<label>Context: </label><br>
<!-- 文本框设置一个默认行数 -->
<textarea disabled id="output" rows="10" cols="50"></textarea>
</td>
</tr>
<!-- 编辑输入框 -->
<tr>
<td>
<label>Input: </label><br>
<!-- 文本框设置一个默认行数 -->
<textarea disabled id="Input" rows="3" cols="50"></textarea>
</td>
</tr>
<tr>
<td>
<button id="Send">Send</button>
</td>
</tr>
</table>
<!-- 添加socket.io的client lib库 -->
<script src='https://cdnjs.cloudflare.com/ajax/libs/socket.io/2.0.3/socket.io.js'></script>
<script src='./js/client.js'></script>
</body>
</html>
后端client.js
'use strict'
var username = document.querySelector("input#username");
var Inputroom = document.querySelector("input#room");
var btnconnect = document.querySelector("button#connect");
var outputArea = document.querySelector("textarea#output");
var InputArea = document.querySelector("textarea#Input");
var btnSend = document.querySelector("button#Send");
//因为在不同函数中都有使用要定义为全局的
var socket;
var room;
btnconnect.onclick = ()=>{
//连接服务器
socket = io.connect();
//本次连接 需要接收处理的消息 并处理相应逻辑
//加入房间成功之后服务端会返回joined 并传回room所在的房间和用户ID
socket.on('joined', (room) =>{
btnconnect.disabled = true;//连接成功之后连接按钮就不让点击了
InputArea.disabled = false;//连接成功之后输入消息框就可以编辑了
btnSend.disabled = false;//连接成功之后发送按钮也可以点击了
});
//离开房间成功后服务器会返回leaved 这边就可以继续做响应处理
socket.on('leaved', (room) =>{
btnconnect.disabled = false;//逻辑与连接相反
InputArea.disabled = true;
btnSend.disabled = true;
});
//消息的转发 当收到消息
socket.on('message', (room, data) =>{
//收到消息之后就只需要将消息放到outputArea显示即可
outputArea.value = outputArea.value + data + '\r';
});
//需发送出去的消息
//连接需要发送的消息 获取房间号,emit发送join加入房间
room = Inputroom.value;
socket.emit('join', room);
}
//将消息发送到服务端,服务端再给其他客户端转发消息,其他客户端收到消息之后就放到outputArea显示
btnSend.onclick = ()=>{
var data = InputArea.value;
data = username.value + ':' + data;//改造一下数据 因为要对消息添加标志 不然不知道谁发送的消息
socket.emit('message', room, data);
InputArea.value = '';//发送完成之后情况输入框
}
6、WebRtc传输基本知识
6.1、常见的传输协议介绍
要清楚webRTC首先要解决的问题是两个浏览器之间如何进行音视频的实时互动,对于底层来说,就是两个端点之间如何进行高效的网络传输。
为了解决这个问题,WebRTC引入了很多网络的传输协议。
NAT(Network Address Translator) ;完成内网地址映射为公网地址
以传统的邮件寄送为例,A、B两个人要发信,B告诉A自己在某层某室,这个时候A能够给B发送消息吗?答案是不能,因为A并不知道一个具体的地址是什么,需要告诉他一个公告具体大家都知道的地址,如某省某市什么小区的哪号楼某层某室这样公告大家都知道的地址才能成功发送消息,如果只说某层某室那么也只有自己小区的人才知道了。这就跟我们网络是相关的了,对于网络上的一个主机,必须要有一个网络上的公网的地址双方之间才能通信,如果是一个私网内网的地址,那么对方根本找不到自己的。而对于我们生活中大部分的主机都是在网关之后的,他们之间都是有自己的内网地址并且不知道自己的外网地址是多少,因此需要实现通信那么就有一个映射,在网关上有一个映射就是NAT功能,它就可以完成将你内网的地址映射为一个外网的地址,就是一个四元组,将内网的IP端口映射为外网的IP端口,有了外网IP端口之后其他的主机就可以公网的IP地址和你进行通讯了。
STUN(Simple Traversal of UDP Through NAT);进行中介,完成两个公网信息的交换
在NAT之后那么主机内网地址都变成了公网的地址,但是两个公网地址之间还并不知道对方的存在,并不能直接通信,还需要一个第三方的服务给他们做一个介绍,这就是STUN服务,就是完成一个中介,将他们各自的公网信息进行一下交互,让他们互相认识,经过了网络信息交互之后那么AB两台主机就可以通过socket建立连接了,连接一旦建立就可以进行传输通信了。
TURN(Traversal Using Replays around NAT) ;同一房间进行转发
但是光有STUN,他们之间也不一定一定能够创建成功。如在国外有研究P2P穿越也只有百分之70能够穿越成功的,如果在国内可能百分之50都达不到,那么在现实生活中我们又要进行浏览器之间的数据传输,当P2P连接不成功的情况下,如何保证音视频还能够互通呢,那么就引入了TURN服务。TURN服务的原理就是在云端创建一个服务器,就负责双方之间流媒体数据的转发,当他们进入到同一个房间之后,A发送到TURN服务的数据在这个房间里,TURN服务就会给房间的所有人进行转发,从而对端就可以收到数据。这样就完成了当P2P连接不成功的情况下,他又有了一条路线可以进行音视频的传输。
ICE(Interactive Connectivity Establishment);选择最优方式的进行传输过去
ICE就是将上面的穿越NAT,TURN服务打包成一起,做一个最优的选择。首先尝试P2P进行,但是可能在你的主机上是双网卡,多端口之间进行最高效最优选择,当P2P不通的时候又会去选择TURN服务进行中转,但是TURN服务也不一定一定能够通的,因此也可能进行多个中间端点的最优选择。
6.2、NAT详细介绍
NAT引入

图38
NAT的种类
完全锥型NAT;内网的某台主机NAT映射成公网地址和端口后,外网所有的主机只要知道这个地址端口后都能向他发送数据,基本上没有上面限制,安全性较低的一种NAT,就是谁都可以访问的一种。
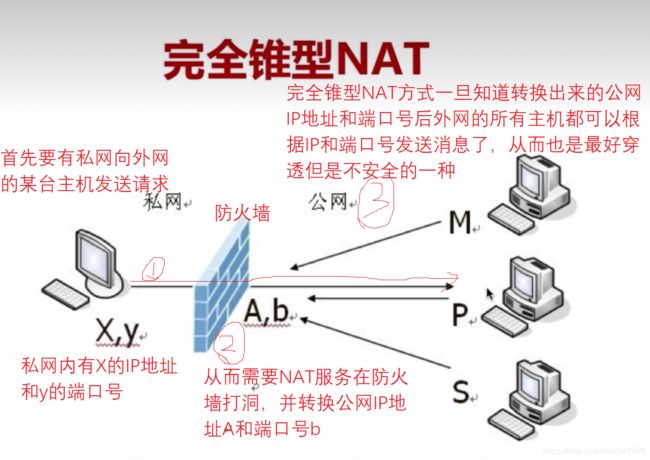
图39
地址限制锥型NAT;我对你出去请求的时候记录一下出去的IP地址,当你消息回来的时候就有这个IP地址,这台主机才给你回消息对于公网的其他主机来说,我已检查你的IP地址不对就之间PASS丢掉了,这种NAT类型就是对你的IP地址做一下判断,不是谁都可以访问,只要不是我向你发送过请求,其他人发送来的数据都不接收
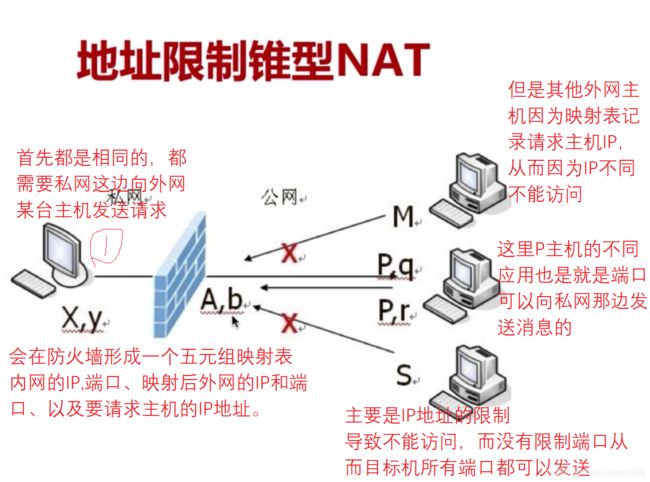
图40
端口限制锥型NAT;就是在IP地址限制型的基础上增加了对端口的限制,就是我发送请求的时候就会给某台主机的某个应用端口发送数据,从而就是只有这台主机的这个应用带你看返回的数据我才认可,否则就之间过滤掉,那么对这台主机的其他端口发来的数据我也不接收的。

图41
对称性NAT;当我进行NAT转换的时候,那么我内网的主机出外网的时候形成的映射,并不只形成一个IP地址和端口,他会形成多个,就是对访问不同的主机他会形成一个自己的IP地址和端口,这样就更加严格了,想知道我的IP的地址都很困难。如出去的是A,A告诉B有个内网的外网IP和端口是这个,但是B通过这个外网IP和端口也是不能访问的,因为内网的主机当与第三个主机进行连接的时候会新建映射一个IP地址和端口,所以这个更复杂,对NAT穿越提了更高的要求,甚至对于完全对称型的NAT是不能穿越的。
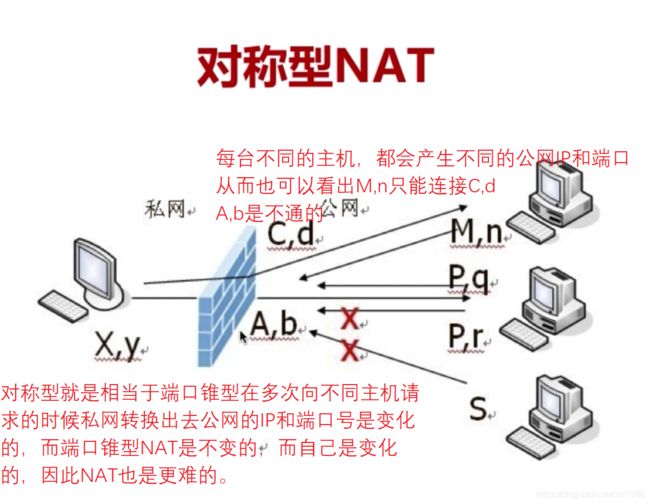
图42
NAT穿越原理
对于每一种类型的NAT穿越都是不一样的。
NAT穿越最终的目的就是两个主机之间要进行通信,那么首先就是C1,C2之间要知道互相的网络消息(从而就是C1,C2向STUN服务发送消息,STUN将各自的网络消息进行交换,就是将C1的公网端口交给C2,将C2的公网IP端口交给C1),交换之后就再根据NAT类型进行打通了,
如果是完全锥型的话那么就可以之间通信了(完全锥型就是只要我在防火墙上建立了一个映射关系,那么任何一台主机,将STUN当作一台主机,那么C2就可以利用C1根STUN之间的公网的映射通道去发送消息),
如果是IP限制型,C2就是不能利用C1与STUN的IP地址发送消息了,因为C1是知道C2的公网IP和端口,那么首先就得C1向C2发送请求,C2再利用C1请求时形参的映射关系从而可以返回数据了。
如果时端口限制型也是跟IP限制型类似的。
而对称型NAT就比较麻烦了,由于端口和IP地址的变化,那么端口猜测的方式,通过几次探测找到变化的规律从而打通。
不同NAT类型是否可以打通的关系图;只有端口型与对称型和对称型与对称型不能打通,其余的组合都可以打通的。
NAT类型判断
要完成自己对自己NAT类型的检测,是否可以打洞成功,首先要在云端一定要部署一个STUN服务并一定要有两个IP地址和端口。
图43
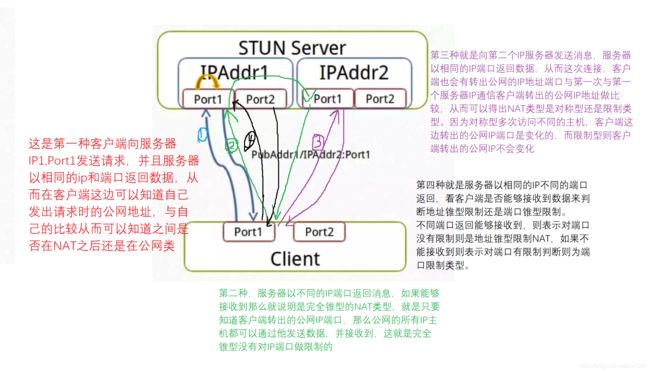
图44
6.3、STUN协议介绍
概述
STUN存在的目的就是进行NAT穿越,之前说了NAT服务有哪几类如何进行穿越其原理是说明都是属于STUN协议里面的一部分。另外STUN服务是典型的客户端/服务器模式,首先是客户端发起请求到服务端,服务端进行相应处理之后给客户端以响应。
在RFC STUN规范中其实有两套STUN规范:
第一套是RFC3489/STUN;就是Simple Traversal of UDP Through NAT通过UDP的简单传输完成NAT穿越,就是告诉你如何通过UDP协议完成一步步的NAT穿越,但是这种模式还是在实际中存在很多问题,因为很多路由对UDP协议有很多限制,甚至有的路由都不支持UDP协议,因此这套协议NAT穿透通过率比较的,从而引出第二套规范。
第二套是RFC5389/STUN;是在上一套的基础上增加了一些功能,但是定义却完全不一样了。他描述STUN为Session Traversal Utilities for NAT 简述为是穿越NAT的一系列传输工具。
因此STUN是存在两套规范的,因此在使用和查阅文档的时候要注意对应是哪套规范。
协议具体字节
包括消息头和消息体的,是20个字节的STUN header,而Body中是可以有0个或多个Atrribute属性的。
RFC3489/STUN header{
2个字节 (16Bit) 是表示类型、
2个字节纯消息体的长度,这个长度是不包括消息头的长度的、
16个字节(128bit)表示事务ID,请求和响应事务是相同的ID,用于请求和响应的的匹配的(如客户端发送很多个请求,服务端对每个请求都要返回一个响应,那么如何将哪个响应对应哪个请求呢,就是需要通过事务ID,就跟ID的相同来确定这个响应是对应哪个请求的,从而一一匹配)
}
RFC5389/STUN header{

图45
}
消息类型的具体表示

图46
大小端模式
{
大端模式;数据高字节保存在内存的低地址中
小端模式;数据高字节保存在内存的高地址中;在主机inter电脑都是小端的
}
网络字节顺序;往往采用大端排序方式如123就是先传1再传2再传3,而接收的时候就是1放到低地址里,2在中间地址,3在高地址里面。
STUN Message Body 消息体
注意消息头后的消息体是可以有0个或者多个属性的,并且每个属性都是进行TLV动态编码的;都有Type,Length, Value。Value是值,而Length标识Value的长度,最终的消息是32位对齐的消息,如果不是则通过补0对齐。具体格式是16位的Type,16位的lenth,其余都是Value。
图47
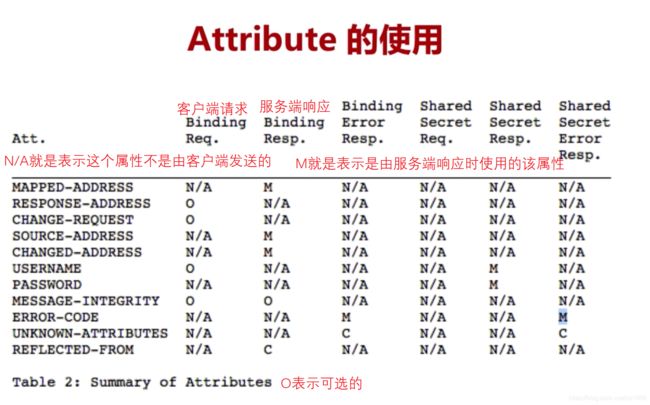
图48
6.4、TURN协议介绍
其目的是解决对称NAT无法穿越的问题。之前就有说当端口限制型与对称型、对称型与对称型这两种情况是无法NAT穿越的,那么在NAT无法穿越的时候我们要怎样保证整个业务的运行呢?这个时候就需要因为TURN服务,其实Turn服务实际上就是在服务端架设一个TURN服务,当客户端在发送数据无法穿越的时候,将媒体流数据首先传给TURN服务,通过TURN服务中介转给其他接收者,或者其他接收者发送消息给TURN服务,然后由TURN服务转给客户端。
TURN服务是建立在STUN服务之上的,他的消息头和BODY是一样的,外头形式大小都是一样的,只是解释的意思不一样,因此消息格式是可以使用STUN格式消息的。因此很多服务器都是将STUN协议和TURN协议两个放到一起的形成的一个服务器,从而又提供STUN功能又提供TURN功能。
实际上TURN服务应该要分为两类;一个是TURN Cilent、一个是TURN Server。
如何实现中转服务呢?首先是要求TURN Cilent发送一个请求,在服务端根据这个请求建立一个公共的IP和port用于接收或发送数据、然后TURN Cilent的对端(就是与TURN Cilent通信的那端)只需要发送正常的UDP包即可。
TURN如何进行穿越的数据实际流向转发图

图49
如何开启中继服务和保活流程

图50
TURN的两种发送机制
Send和Data模式;
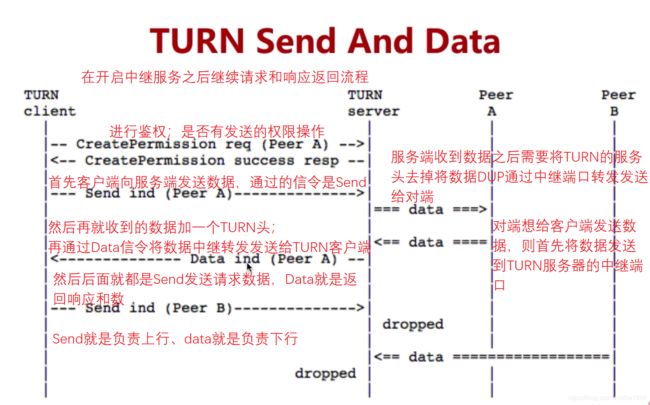
图51
Channel模式;
观察可以知道Send和Data模式有一个坏处就是每次发送数据之前都会带一个30字节的TURN头,这对于一般的情况下影响不大,但是对于流媒体的音视频数据而言数据量非常大,如果每个数据都带一个30字节的头,那么对整个网络带宽是非常有影响的,从而为了解决这个消息头的问题引入了Channel的发送方式。
原理就是大家规定一个ChannelID,我们都加入到这个管道中,我们就不用每次都带头消息告诉我们是什么什么的一些基本信息在里面。就是之前创建好了都在这个管道里,这个管道传输的数据都是符合这些消息头数据的,基本消息都是相同的,只需要发送数据就行了。

图52
注意Send和Data模式与Channel模式两种模式是可以同时存在的,两种模式可以混着发送这个没有关系的。
TURN的使用
1、 首先是绑定STUN binding,拿到客户端的映射IP地址
2、 发起端就调用Caller TURN allocation,就是让TURNserver开启中继服务,接收数据并转发。这里就是打通了连接的。
3、 发起端再将一些媒体信息网络信息通过SDP的offer信令发送给被调用者。这是WEBRTC必须的信息要发送给被调用者。
4、 被调用者收到消息之后也要发送TURN allocation就是被调用者也要去创建中继服务,从而接收对方的数据。
5、 被调用者还需要answersOK响应客户端的请求,这样就他们的整个交互数据就交换完了。
6、 Exchange candidate IP address,交换备选的IP地址,信息交换
7、 通过ICE框架检查P2P是否连接(因为最优先高效传输效率还是端对端的之间,因为不需要第三方接入以及第三方的带宽限制,只需要双方带宽)
8、 如果P2P不通的话,那么就需要端口中继服务了,来进行通信,就要向对方的中继端口去发送数据,对方就可以收到了。
6.5、ICE介绍
ICE主要的功能
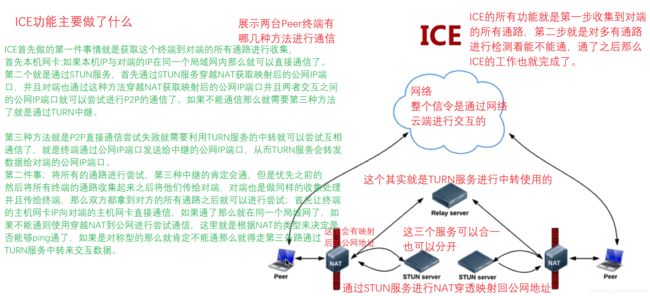
图53
ICE的几个基本概念
1、 ICE Candidate ICE的候选者;就是一个通路就代表一个候选者
就是每个Candidate就是一个地址,包括IP地址和端口(地址对)
拿到这些通路Candidate之后怎么进行两端的交互呢?就是通过SDP(他是对于媒体信息和网络信息的一个描述规范)这个规范是通过一个信令SDP发送给对方,对方拿到各自对方的所有通路信息,就知道对方支持哪些通路,以及自己有哪些通路。
格式;a=candidate;…UDP…IP…port…type host
a表示属性,是candidate表示一个通路
这个通路必须包括一些基本信息;类型(UOD还是TCP),IP地址,端口,类型(是主机类型还是Nat映射后的地址还是中继地址)
这个Candidate类型有三种;
主机候选者;就是获取本机所有IP和指定端口
反射候选者;STUN/TURN映射后的公网IP端口的候选者
中继候选者;TURN服务,通过发送Allocate请求申请的
2、 ICE主要做什么事情
收集Candidate、对Candidate Pair排序(哪条路与哪条路形参候选者队之后经过算法进行排序来节约时间不是每条尝试的,优先级最高的优先做测试也最有可能先通的)、连通性测试就是进行尝试了也就是发送消息看是否能够接收到还是超时
形成Candidate Pair
一方收集到所有的候选者后通过信令传给对方,同样另一方收到候选者后也做收集工作,
当双方都拿到全部候选者列表值就将候选者在逻辑上形成匹配对一对一对的,这就是Candidate Pair
连通性检测
首先对候选者进行优先级排序(以节约时间),对每个候选对进行发送检查,以及进行接收检查;如果能够发送出去之后还能够接收回信息那么就说明这对候选对是通的了。
什么是SDP
SDP(Session Description Protocol)它只是一种信息格式的描述标准,本身不属于传输协议,但是可以被其他传输协议用来交换必要的信息。这里包含的信息最主要的是包括媒体信息和网络信息。

图54
6.6、网络协议分析;tcpdump与wireshark
之前也讲过很多网络相关的的基本知识如NAT,NAT穿越的原理,NAT类型,STUN服务以及STUN的协议头协议体,TURN协议,ICE框架,这些都是网络传输的理论层次的,那么真实的网络是不是按照我们这些协议一步步走的我们并不知道就需要通过工具抓取网络包,分析数据看网络包是不是根据我们的网络协议一步步来的就可以进行验证了。
常用工具
Linux服务端用tcpdump;很强大但是对使用者的要求也比较高需要知道各种网络协议很熟悉。
其它端就可以使用WireShark;该工具有界面,可以看到网络的各个层次。比较方便简单因此可以在linux服务器使用tcpdump抓取数据到终端这边使用wireshark解析数据便于分析。
Tcpdump使用
如tcpdump -i eth0 src port 80 -xx -Xs 0 -w test.cap
-i指定网卡;eth0网卡名字、
src指明包的来源(可以指定IP也可以指定port)、
-xx表示指抓到的包以16进制显示、
-X指以ASICII码来显示便于观看、
-s 0表示指明抓整个包、
-w写到文件当中。
整个意思就是抓取网卡为eth0的数据并且进行端口过滤只保留80端口的的整包数据并且使用16进制和ascii码显示并且写到文件中。
.cap后缀是wireshark是可以读取出来的。
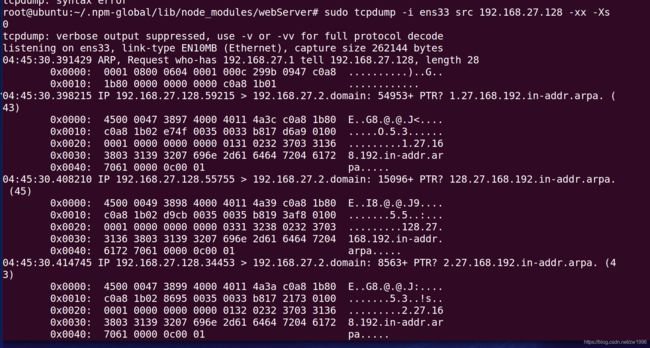
图56
Wireshark打开cap文件
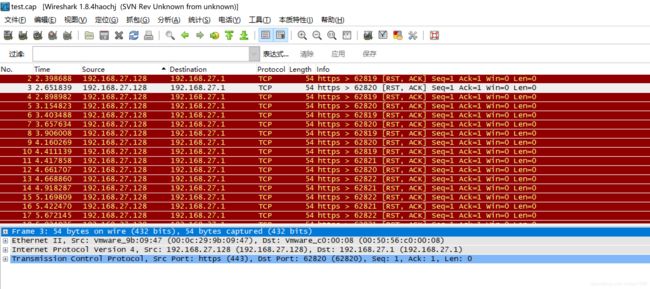
图57
Wireshark中的语法
与;and或&&、或;or或||、非;not或!、
等于;eq或==、小于;lt或<;大于;gt或>、小于等于;le或<=、大于等于;ge或>=、不等于;ne或!=。
可以按协议过滤;支持stun,scp,udp
可以按IP过滤;ip.dstxxxxx过滤只剩源IP、ip.srcxxxx过滤只剩目的IP、ip.addrxxx过滤只剩该IP
可以按照端口过滤;tcp.port == 8080、tcp.srcprot8080等等这样过滤
可以根据长度过滤;udp.length<30、http.content_length<30等等这样过滤
这些还可以进行组合;如udp.srcport3478 and ip.srcipxxxx这样利用逻辑运算组合
7、媒体能力协商之端对端连接
7.1、RTCPeerConnection概述
这个类是RTCPeerConnection是整个WebRTC的一个最核心的类,他是上层的一个同一接口,但是在底层却是做了很多复杂的逻辑,包括整个媒体的协商,整个流与轨道的处理接收与发送和统计与数据都是在这个类来处理的。所以对于上层而言就是简单的调用这个类使用几个简单的API,但是对于底层而言是做了大量的工作。
基本格式;创建对象pc = new RTCPeerConnection([configuration]);配置参数是可选的。
将这个类的方法可以进行分类;
1、 媒体协商相关的;大概就是四个方法,但是通过这四个方法就可以拿到整个双方的媒体信息然后他们会进行交换然后协商如你用的编码器是什么,我用的编码器是什么,各自的音频格式协商同一之后才真正的进行数据的传输与编解码。
2、 Stream/Track媒体流与轨道;在整个WebRTC当中每一路(每一组对端通信)都是一条流,每条流里面包括音频轨和视频轨或者多路音频轨多路视频轨。在整个传输中就是Steam/Track,在轨道中就包括音频数据和视频数据。
3、 传输相关方法;我们使用的是什么协议去传输,数据传输通过RTP协议,链路的好坏通过RTCP协议来反馈,通过数据的统计分析来查看整个链路的质量(是发送拥塞来还是本来的链路就是不太好的)
4、 统计相关方法;包括你的编解码器,音视频格式传输相关的数据都可以通过统计相关的方法获取到。
7.2、媒体协商
7.2.1、媒体协商的过程
在使用这个方法之前我们要先知道他的协议是什么,媒体是怎么样协商出来的。知道这个过程之后我们再去调用学习API就是非常简单的了。
图58
1、A首先是创建一个Offer
创建一个offer实际就形成了一个SDP;SDP就是包含了一些媒体信息(编解码信息)传输相关的信息。Offerr就是SDP的一种描述格式去描述的。
2、创建offer完成之后就通过云端的信令channel传递给B;并且传递之前还会调用setLocalDesription方法会触发一个非常重要的动作就是去收集A端的本地的candidate候选者(之前就讲述过在创建连接之前就要去拿到所有的候选者怎么收集的呢就是靠向STUN/TURN服务发送请求在请求过程中可以去拿到本地IP,NAT之后IP,中继服务IP这些)什么时候去请求获取候选者的呢就是靠这个setLocalDesription方法。这个方法一调用就会异步的触发这件事情(发送请求收集候选者)
3、通过信令服务传给B端之后B端首先会调用SetRemoteDesciription方法就是将offer所形成的SDP的数据放到自己远端的描述信息的槽里。当这步做完之后就会返回一个Answer
4、通过RTCPeerConnection这个连接类调用一个创建Answer的方法,就是创建一个自己本身的媒体信息传输信息;(也就是说offer是整个A端的媒体信息[音视频编解码器,编解码相关参数]和网络信息的SDP描述信息的封装,B收到offer之后将他放到自己远端的描述槽里面)之后再回复一个Answer,Answer就是自己本机B端整个的媒体信息和网络信息[这里面也包括了B端自己所支持的音频格式视频格式及相关编解码器和音频的单双通道采样率这些参数]B也会形成这些,并且B也会调用一个setLocalDesription方法,也会做同样的事情去触发收集B端自己的所有候选者[自己整个网络有多少个候选者都要收集起来形成一个列表]。
5、B端生成的Answer后通过信令服务channel传给了A端,A端收到之后也就同样把收到的Answer里面的SDP放到A端他自己的远端信息槽里面。
因此可以看出其实每一端都有两个SDP,一个是自己的媒体信息网络信息的,一个是对方的媒体信息网络信息,这两个都拿到之后就可以在内部进行协商,分析查看自己支持的格式有没有你支持的,取出他们的交集查看你支持最好的是哪个,我支持最好的格式是哪个去一个交集。取出整个所有信息的交集之后这个媒体的协商过程也就建立好了。只有媒体协商建立好了才能进行下一步编解码传输了,当编码传输到了对方之后因为已经协商好了就会之后这是它能支持的格式并使用对应的媒体器进行界面播放渲染了。
每一端都有四个步骤;
调用方;
创建offer,
设置setLocalDesription触发收集候选者,
接收Answer、
设置SetRemoteDesciription存储对端传来的对端他所支持的SDP。被调用方;
接收offer,
设置SetRemoteDesciription,
创建Answer,
创建setLocalDesription触发收集候选者
7.2.2、协商状态的变化
总结;反正总而言之只有当整个协商完成之后才能完成后面真正的音视频的处理传输和编解码
图59
调用者状态的变化
对于调用者而言需要发生哪些状态上的改变,首先创建Connection之后就要创建offer、设置offer进入have-local-offer状态并且一直在这个状态直到远端返回Answer,只有当收到远方的Answer并设置进行之后也就是协商之后才会改变状态并且又回到stable稳定状态,但是第二次回到稳定状态的时候这个时候就可以进行编解码传输了因为他已经是协商过之后第二次返回。
被调用者状态的变化
对于被调用者就是首先从信令服务器收到一个远端offer并且设置进去就从stable状态转变到hava_remotr-offer状态,同样在这个状态不会改变直到自己创建好了answer并设置进进去之后才会发生状态改变从而第二次进入stable状态,这样被调用者他也就完成了自己的协商工作就可以完成下面的逻辑工作了。
提前应答操作PRAnswer;这个操作就是在双方通讯的时候,其中被调用者还没有调用好数据的时候就可以先创建一个临时的Answer(这个临时的数据是没有媒体数据的就是没有音频流视频流并且会将发送的方向设置为sendOnly);就是对于被调用者而言就是还没有准备好媒体流只是网络链路通了(就是候选者都准备好了)因此可以提前发送一个PRAwser,这时候他是只能发送不能接收的状态,当调用者收到被调用者传来的PRAwser也就会知道对方现在还不能接收数据,这个时候两方的通讯虽然做了协商但是还不能进行通信(因为对方没有媒体流还有就是对方还没有媒体数据)因此就是进行状态改变被调用者就进入have_remote_pranswer状态,这样处理进入这个状态的好处就是可以提前建立链路的连接,也就是说包括ICE、DTLS加密握手这些与链路相关的协商其实都已经创建好了的,因为这些网络信息都是提前准备好了的就没有等媒体流先作为Answer发过来也就是PRAswer。从而干扰也就是说在被调用者在准备好自己的流之前是已经将与调用者的链路是准备好了的,那一旦被调用者向使用者申请开启音视频传输当用户授权之后这个时候就只需要将数据拿到传入进去就可以直接进行通信了。
对于调用者PRAswer简而言之就是在被调用者没有准备好之前可以发送一个PRAswer给调用者发送过去,发送过去之后调用者就会进入have_remote_pranswer状态,在这个状态双方的链路是已经协商好了的,只等当被调用者媒体数据准备好了之后再返回一个最终的Answer那么就会真正的进入stable状态,此时就是可以真正进行编解码传输了,这样最后数据好了之后传输就减少了网络流的链路连接(网络加密握手这些耗时操作)节省了时间、
同样对于被调用者PRAswer而言就是差不多的;再回复真正的Answer之前呢也是先创建一个只有网络信息的Answer并进入have-local-pranswer状态的,当真正的Answer准备好了之后呢再真正的设置一下,从而进入stable状态。
7.2.3、媒体协商方法
creatOffer;
作用;创建一个本地的媒体信息和编解码信息,网络信息。
基本格式;aPromise = myPeerConnection.creatOffer([options]);
creatAnswer;
作用;就是对于对端而言收到offeer之后就会创建一个Answer的方法,就是对端本地的信息最终是要传递给调用端的。
基本格式;aPromise = myPeerConnection.creatOffer([options]);
setLocalDescription;
作用;就是把自己本地的媒体网络信息设置好了之后就可以触发采集候选者了。
基本格式;aPromise = myPc. setLocalDescription(sessionDescription);
sessionDescription是将creatOffer或creatAnswer的结果当作参数设置
setRemoteDescription;
作用;就是收到对端的SDP信息之后将他设置到RemoteDescription的槽里面去,并且在内部真正去做媒体协商的方法。
基本格式;aPromise = myPc. setLocalDescription(sessionDescription);
sessionDescription是将creatOffer或creatAnswer的结果当作参数设置
7.2.4、Track方法
在RTCPeerConnection里面有两个重要的track方法;一个添加一个移除
addTrack;
基本格式;rtpSender = myPc.addTrack(track, stream…);
Track;你要添加的track就是你要添加的音频的轨还是视频轨
Stream;从getUserMedia里面拿到一个流,
流里面就可以有音频轨,视频轨,字幕轨,
这个时候就需要遍历所有的轨将他们加入到peerconnection(myPc实参)里面。
这样peerconnection就可以控制每一路轨了,并且从他们里面获取数据进行发送。
removeTrack;
基本格式myPc.remoteTrack(rtpSender);
rtpSender;;就是addTrack里面返回的Sender作为参数放进去,
就可以把peerconnection(myPc实参)里面这条轨移除掉。
7.2.5、peerconnection重要事件
Onnegotiationneeded;协商事件;当我们进行媒体协商的时候就会触发该事件。
Onicecandidate;当我们收到一个ICE的候选者的时候也会从底层触发该事件告诉我们有一个候选者来了,那么我们需要拿到这个候选者并且将他们添加到ICE里面去,这样我们就可以进行ICE的通信了。
7.3、端对端连接的基本流程
整个A与B两个端首先进行媒体协商、候选者的连接交换与链路检测部分、媒体数据传输三个部分的流程。
图60
A端媒体协商流程
首先获取RTCPeerConnection连接对象实例,
调用RTCPeerConnection的creatOffer方法创建一个offer的SDP,
再调用setLocalDescription设置到本地的槽里面去,
调用完这个方法之后其实会在底层发起一个bind请求,
发给STURN/TURN服务从而就开始收集所有能够与对方连接的候选者了
之后还需要将之前拿到的Offer的SDP发送给信令服务器,
通过信令服务器的中转这样B才拿到了A的offer
B端媒体协商流程
B端收到媒体offer的SDP之后,
首先要创建一个RTCPeerConnection连接对象,
再调用RTCPeerConnection的setRemoteDescription将收到的SDP设置到远端描述的槽里面去,
设置完成之后需要给一个应答则需要产生自己本机相关的媒体信息就是AnswerSDP,
创建完成之后也需要调用setLocalDescription将本机相关的SDP设置到本地描述的槽里面去,这个时候B端就有远端和自己端的SDP了,这样就可以在底层进行协商了,
同时在setLocalDescription的时候也会触发一个bind请求向turn服务去收集他B能够与A通信的所有候选者。
再之后就会将自己的AnswerSDP发送给信令服务器进行转发给A,
这个给时候A收到B端的AnswerSDP信息就会调用setRemoteDescription将收到的SDP设置到远端描述的槽里面去,这个时候A也是有自己和对端的两个SDP那么A在底层也可以进行媒体协商了。
候选者的连接交换与链路检测部分
因为之前有bind请求这个时候就触发Onicecandidate将候选者发送给A,A收到候选者之后就将候选者发送给信令服务器,通过信令服务器转发给对端,就是让对端也知道自己有哪些通路候选者,对端收到candidate之后就会调用AddIceCandidate添加到与对端的连接通路的候选者里面去。同样B收到候选者信息之后他也是通过信令转发给对端A,然后对端A也同样调用AddIceCandidate添加到与对端的连接通路的候选者里面去,这样A也就知道B的候选者了。这个时候双方就都拿到了对方所有可以互通的候选者这个时候他底层也就会做链接检测首先是做一个个的candidatePair候选者对然后进行排序再进行连接检测等一系列操作当找到一个最优的选择通路之后那么A与B就能够通信了。
媒体数据传输部分
能够通讯了那么首先是A将数据流发送给B,B收到数据流之后,因为之前已经做过绑定了,就是谁来的说句给我了那么就与对应的RTCPeerConnection对连,那收到数据之后但是还是不能直接显示的,需要将数据onaddStream里面的数据添加进来,才能将音视频数据向上抛,才能走向上一层,最后才能进行视频的渲染,音频的播放。
总结;端对端连接的整体流程大概分为三大块分别是;
媒体协商部分;看看A端有什么媒体能力,B端有什么媒体能力,他们之间的媒体能力取一个交集,就是取一个大家双方都能够识别支持的能力,包括音视频编解码,音频采样率帧率这些以及网络的一些信息。
通过ICE对整个可联通的链路进行收集之后的排序和连接检测找出双方可以连接的最优的线路。
最后拿到最优线路之后就可以进行数据传输了,当数据从一端传到另一端之后那么另一端会接收到一个事件onaddstream之后就可以将媒体流添加到自己的音视频标签中最终来完成显示播放。
7.4、实际本机内1:1音视频互通
简单回顾一下端对端的流程,大概可以分为三大块;整个媒体的协商(看看A端有哪些媒体能力,B端有哪些媒体能力,最后他们媒体之间的能力去一个交集,取大家都能够支持的能力,媒体能力也就是音频编解码视频编解码支持封装格式采样率帧率的控制以及网络的相关信息)。通过ICE对整个可联通的链路进行链路地址的收集排序连接检测,找出双方可以连接的最优线路。最后拿到最优通讯线路之后就可以开始进行媒体数据的传输了,当媒体数据从一端传输到另一端会传输回一个事件onaddstream,收到这个事件之后就可以把媒体流数据添加到video/audio标签中进行渲染播放。这就是端到端之前整个的媒体流程。
实际;该案例是一台电脑的一个页面里面去展示本地采集的音频视频,之后创建两个peerconnection最后将媒体流放到其中一个peerconnection中,之后让他们进行连接,最后通过本机底层的网络连接传输到另外一端的peerconnection。当另一端的连接收到音视频数据之后就会回调事件onaddstream就会将数据进行渲染播放。
图70
实际获取offer/Answer的SDP;
SDP(Session Description Protocol)它是一种信息格式的描述标准,本身不属于传输协议,但是可以被其他传输协议用来交换必要信息。
它最主要用的地方就是进行媒体的协商,在通讯之前首先进行媒体的协商,对于呼叫者首先要创建自己的offer将自己的媒体信息拿到然后通过信令服务器转给被呼叫者,然后被呼叫者拿到这个信令之后就要创建则这个Answer也就是将他自己的信令信息也拿到并通过信令服务器传给呼叫者,这样就完成了双方之间的媒体信息的交换,而这些媒体信息就是用SDP这些来描述的,拿到双方的SDP之后就可以取一个交集大家都支持的编解码器带宽等等信息,之后就可以进行媒体数据的传输。

图71
7.5、SDP学习
7.5.1、SDP规范
SDP规范将SDP分为两层;
第一层是会话层,就是相当于写程序时的全局变量,全局有效的。
第二层就是媒体层,就是相当于自己的一个个函数,按照SDP的理解就是一个个媒体,如每一路音频,每一路视频都是一个媒体层。
会话层是全局的一旦设置就是全局有效,当媒体层没有设置自己的属性之前那么就会使用全局的也就是会话层的属性,当媒体层自己特殊描述设置那么就会优先自己设置的。
会话层包括;会话的名称和目的、会话的存活时间(对于音视频而言一般会设置0表示无限期)、会话中包括多个媒体信息。
媒体信息主要包括;媒体格式(音频还是视频还是应用数据(就是自定义格式))、传输协议(IPV4还是IPV6,TCP还是UDP)、传输IP和端口(这里的作用不大因为WEBRTC音视频传输中一般都是以ICE收集来的)、媒体负载类型(MEPG4,H264,H265)。并且媒体信息可以定制自己的更多的属性并且对每个属性做更细的规范从而变得比较复杂。
SDP格式;都是由多个 类型和值组成的对组成的、一个会话级描述、多个媒体级描述。
SDP结构;会话描述(位于会话层)、时间描述(位于会话层)、多个媒体描述(具体描述某个媒体)
会话描述(位于会话层)
V=(protocol version) 一般是0,是我们SDP使用的版本 (必选)
O=(owner/create and session identifier)一个ID标识 (必选)
S=(session name),如果不想则可以写一个- (必选)
C=(连接相关的信息,会话使用的IP地址端口,地址类型网络类型等等)
但是这个在具体的每个媒体层都会设置因此意义也不大 (可选的)
A=(设置一些全局的属性)意义也不大
时间描述(位于会话层)
T=(time the session is active)存活时间 如果都为0 那么就表示不结束 实时通话
R=(重复次数)
多个媒体描述(具体描述某个媒体);
M=(media name and transport address)媒体名字和传输地址
C=(传输相关信息)。
B=(带宽设置);传输的限制就通过它。
A=(一堆属性,对m的描述属性),并且a的属性特别多。
A=<type>或者a=<type>:<values>
例如
a=framerate:<帧率>、
a=rtpmap:<fmt/payload type><encoding name>/<clock rate>[<encodingparameters>]、rtpmap是修饰payload type的具体细节的如编码器名字,时间频率,或者编码参数等。如a=rtpmap:103 ISAC/16000 可以知道103是ISAC 编解码器是ISAC,时间频率是16000.
A=fmtp:< fmt/payload type > parameters这个属性就是对payload type属性做进一步解释。如a=fmtp:103 apt=106 还是103但是他是额外需要关联到103的。
总结;SDP的规范来看就是将整个描述分为两层,会话层全局唯一描述一些基本信息意义不大,重要的是媒体层描述了一些媒体的类型音频还是视频,传输相关的IPV4还是IPV6,IP地址和端口、以及payload类型音频 视频都支持哪些编解码器以及相关编解码器的参数,并且还可以通过属性来进一步对payload进行指定。属性里面有两个重要的是rtpmap指定编解码器的ID和名称对应以及采样率和一些基本信息,还有一个是fmtp就可以进行一步说明。
7.5.2、WebRTC中的SDP
为了使SDP更能适应WebRTC里面的一些设置和会话的描述增加了一些属性特征。
WebRTC中的SDP总共是包括5个部分;会话元、网络描述、流描述、安全描述、服务质量描述,并且在每一个描述的下面都有一套自己的小的规范和自己的属性。
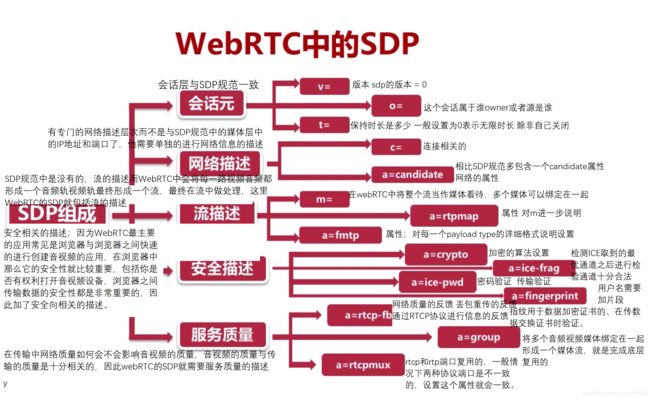
图72
7.5.3、WebRTC中SDP实际解析
以上面那个为实例将offerSDP拿出来进行分析
会话层----------------------
版本号
v=0
original源
第一个是名字 可以不写用-表示,
第二个session ID当前整个会话的ID唯一的标识,
第三个就是版本(后来每次新成一个sdp版本号就加一,代表是不同的session),
第四个就是我们所使用的网络类型,IN表示互联网internet
第五个是我们使用的网络地址协议是 IPV4
第六个是我们具体的IP地址
o=- 4377416165836296019 2 IN IP4 127.0.0.1
session表示会话的名称 可以不写用-表示,
s=-
时间 开始时间 结束时间 如果两个都是0的话表示一直不结束 对于webrtc而言因为是实时通话则需设置为 0 0 不牵扯时间问题
t=0 0
//接下来的就是属性设置的
第一个属性是group,后面是BUNDLE 0 代表的意思是有一个流与它进行绑定(后面就是1,2,3) BUNDLE的意思就是这一组媒体流绑定到一起,底层使用一个传输。
也就是说我们媒体流可能有很多 但是在我们传输层却只有一个链路这就是BUNDLE的作用
a=group:BUNDLE 0
属性msid表示meidia stream id 媒体流的一个标识,WMS表示WebRTC Media Stream 后面就是接那个ID串
a=msid-semantic: WMS NED6L9jodYCKBVHg0nUvkoqtq1DAQ7k0YDZF
----------------------------------媒体层----------------------
m表示我们的媒体信息 可以有多个m
第一个是媒体的类型 video
第二个是 端口号 9 可以知道1024以下的端口都是系统分配好的 不能轻易使用的,9就表示端口是9 表示不接收数据 就是不要往这个端口发送数据,它所有传输不使用SDP的传输,而使用FEC的网络
第三个是传输协议 底层是UDP 上层是RTP(是经过TLS交换证书的) SAVPF表示加密后的数据
第四是playloadtype 他们具体的含义会在下面做解释
m=video 9 UDP/TLS/RTP/SAVPF 96 97 98 99 100 101 102 122 127 121 125 107 108 109 124 120 123 119 114 115 116
连接 但是这个连接实际webrtc没有使用,
internet网络 IPV4 实际IP地址0.0.0.0表示任意地址,如果有多个网卡的话那么意思就是任何一个网卡都可以
c=IN IP4 0.0.0.0
下面的a属性都是对媒体的再次说明
rtcp 也使用9端口 意义与之前一样 拒绝无效的意思
a=rtcp:9 IN IP4 0.0.0.0
ice 用于ICE进行链路进行检查的时候对链路的有效性进行一个验证的
先将自己的ICT用户名密码传给对方 当与对方建立连接之后就会发过去,当发过来的和自己告诉它的是一致的那么说明这个链路就可以建立成功,否则链路就会切断
a=ice-ufrag:uzBD
a=ice-pwd:cEgiCpwaE7l1ux4OkQwHP6Wf
trickle 的意思就是在进行SDP交换的时候先不收集,在后面逐渐收集 将SDP发送走在setLocalDescription设置之后在逐渐收集,没收集一个做一次检查并效率比较进行替换,这样速度就快
a=ice-options:trickle
fingerprint 是一个哈希值 256位的 作用就是当通过dtls时要交换证书 在交换之后需要将证书的fingerprint指纹传给对方,交换的时候通过指纹进行匹配 判断双方是否是信任的
a=fingerprint:sha-256 8A:13:6E:AD:4B:96:0F:86:77:99:70:83:20:B4:E4:85:98:12:4A:74:D2:D9:6B:1E:45:24:B1:13:F7:EB:6A:AA
setup 媒体协商过程中谁做服务端谁在客户端的协商方法确定
actpass 表示我进行媒体协商的时候我可以作为服务器端也可以客户端,是可以选的。是通过Answer端进行选择的,它选择你做客户端那么他就是服务端,反之相同。
a=setup:actpass
mid表示媒体的ID 就是group:BUNDLE的那个值
a=mid:0
下面的参数是对这个媒体的参数扩展
扩展头的意思 ID及意思 之后ID就行了 urn http表示出处是哪里便于查找
a=extmap:14 urn:ietf:params:rtp-hdrext:toffset
a=extmap:2 http://www.webrtc.org/experiments/rtp-hdrext/abs-send-time
a=extmap:13 urn:3gpp:video-orientation
a=extmap:3 http://www.ietf.org/id/draft-holmer-rmcat-transport-wide-cc-extensions-01
a=extmap:12 http://www.webrtc.org/experiments/rtp-hdrext/playout-delay
a=extmap:11 http://www.webrtc.org/experiments/rtp-hdrext/video-content-type
a=extmap:7 http://www.webrtc.org/experiments/rtp-hdrext/video-timing
a=extmap:8 http://tools.ietf.org/html/draft-ietf-avtext-framemarking-07
a=extmap:9 http://www.webrtc.org/experiments/rtp-hdrext/color-space
a=extmap:4 urn:ietf:params:rtp-hdrext:sdes:mid
a=extmap:5 urn:ietf:params:rtp-hdrext:sdes:rtp-stream-id
a=extmap:6 urn:ietf:params:rtp-hdrext:sdes:repaired-rtp-stream-id
sendrecv表示在接收流的时候既可以接收也可以发送,他也有很多种类型的
a=sendrecv
msid与之前的msid-semantic是一致的
a=msid:NED6L9jodYCKBVHg0nUvkoqtq1DAQ7k0YDZF dca409c1-90f8-4d97-9905-a0c787b2b326
rtcp 传输中用于控制网络传输反馈的 如丢包 对方带宽发送数据
mux 复用表示rtcp和rtp复用同一个端口
a=rtcp-mux
rsize 表示回复rtcp消息能够减少 有标准的不准减少 有远端带宽评估之后进行rtcp消息减少
a=rtcp-rsize
对上面的playloadtype进行说明
// 96对于的编码器是VP8 时间参数是9万
// goog-remb 接收端带宽评估 goog表示是谷歌的非标准的
// transport-cc 传输端的带宽评估是通过transport-cc
// ccm表示编码控制 回馈消息 可以发送完成在内部帧请求 fir表示完成帧的 意思是当丢包之后需要发送一个完整的I帧过来
// nack 隔一段时间返回没有应答的包 然后再决策没有应答的要怎样做
// pli 也是完整帧类型请求
a=rtpmap:96 VP8/90000
a=rtcp-fb:96 goog-remb
a=rtcp-fb:96 transport-cc
a=rtcp-fb:96 ccm fir
a=rtcp-fb:96 nack
a=rtcp-fb:96 nack pli
//97可以表示重传 与96关联的通道 当96有丢包要重传的时候就可以用97
a=rtpmap:97 rtx/90000
a=fmtp:97 apt=96
.
.
.
.
.
.
.
ssrc 表示一路流
a=ssrc-group:FID 2693898019 4285589298
a=ssrc:2693898019 cname:un0+K/TgtZ/afzXS 名字
a=ssrc:2693898019 msid:NED6L9jodYCKBVHg0nUvkoqtq1DAQ7k0YDZF dca409c1-90f8-4d97-9905-a0c787b2b326
a=ssrc:2693898019 mslabel:NED6L9jodYCKBVHg0nUvkoqtq1DAQ7k0YDZF
a=ssrc:2693898019 label:dca409c1-90f8-4d97-9905-a0c787b2b326
a=ssrc:4285589298 cname:un0+K/TgtZ/afzXS 名字 对应不同的ssrc
a=ssrc:4285589298 msid:NED6L9jodYCKBVHg0nUvkoqtq1DAQ7k0YDZF dca409c1-90f8-4d97-9905-a0c787b2b326
a=ssrc:4285589298 mslabel:NED6L9jodYCKBVHg0nUvkoqtq1DAQ7k0YDZF
a=ssrc:4285589298 label:dca409c1-90f8-4d97-9905-a0c787b2b326s
实践代码在CSDN资源文件中有
笔记来源于学习李超老师的webrtc讲解视频;目前笔记记录到11节结束,后续才是1V1实时视频传输,现在的还是基础知识。