如何扛住100亿次请求?请尝试一下?
点击“开发者技术前线”,选择“星标????”
让一部分开发者看到未来

作者 | xiaojiaqi
来源 | github.com/xiaojiaqi/10billionhongbaos前几天,偶然看到了 《扛住100亿次请求——如何做一个“有把握”的春晚红包系统”》(http://www.infoq.com/cn/presentations/how-to-build-a-spring-festival-bonus-system)一文,看完以后,感慨良多,收益很多。正所谓他山之石,可以攻玉,虽然此文发表于2015年,我看到时已经是2016年末,但是其中的思想仍然是可以为很多后端设计借鉴,。同时作为一个工程师,看完以后又会思考,学习了这样的文章以后,是否能给自己的工作带来一些实际的经验呢?所谓纸上得来终觉浅,绝知此事要躬行,能否自己实践一下100亿次红包请求呢?否则读完以后脑子里能剩下的东西 不过就是100亿 1400万QPS整流 这样的字眼,剩下的文章将展示作者是如何以此过程为目标,在本地环境的模拟了此过程。
实现的目标: 单机支持100万连接,模拟了摇红包和发红包过程,单机峰值QPS 6万,平稳支持了业务。
注:本文以及作者所有内容,仅代表个人理解和实践,过程和微信团队没有任何关系,真正的线上系统也不同,只是从一些技术点进行了实践,请读者进行区分。因作者水平有限,有任何问题都是作者的责任,有问题请联系 ppmsn2005#gmail.com. 全文内容 扛住100亿次请求?我们来试一试
2. 背景知识
QPS: Queries per second 每秒的请求数目
PPS:Packets per second 每秒数据包数目
摇红包:客户端发出一个摇红包的请求,如果系统有红包就会返回,用户获得红包
发红包:产生一个红包里面含有一定金额,红包指定数个用户,每个用户会收到红包信息,用户可以发送拆红包的请求,获取其中的部分金额。
3. 确定目标
在一切系统开始以前,我们应该搞清楚我们的系统在完成以后,应该有一个什么样的负载能力。
3.1 用户总数:
通过文章我们可以了解到接入服务器638台, 服务上限大概是14.3亿用户, 所以单机负载的用户上限大概是14.3亿/638台=228万用户/台。但是目前中国肯定不会有14亿用户同时在线,参考 http://qiye.qianzhan.com/show/detail/160818-b8d1c700.html 的说法,2016年Q2 微信用户大概是8亿,月活在5.4 亿左右。所以在2015年春节期间,虽然使用的用户会很多,但是同时在线肯定不到5.4亿。
3.2. 服务器数量:
一共有638台服务器,按照正常运维设计,我相信所有服务器不会完全上线,会有一定的硬件冗余,来防止突发硬件故障。假设一共有600台接入服务器。
3.3 单机需要支持的负载数:
每台服务器支持的用户数:5.4亿/600 = 90万。也就是平均单机支持90万用户。如果真实情况比90万更多,则模拟的情况可能会有偏差,但是我认为QPS在这个实验中更重要。
3.4. 单机峰值QPS:
文章中明确表示为1400万QPS.这个数值是非常高的,但是因为有600台服务器存在,所以单机的QPS为 1400万/600= 约为2.3万QPS, 文章曾经提及系统可以支持4000万QPS,那么系统的QPS 至少要到4000万/600 = 约为 6.6万, 这个数值大约是目前的3倍,短期来看并不会被触及。但是我相信应该做过相应的压力测试。
3.5. 发放红包:
文中提到系统以5万个每秒的下发速度,那么单机每秒下发速度50000/600 =83个/秒,也就是单机系统应该保证每秒以83个的速度下发即可。
最后考虑到系统的真实性,还至少有用户登录的动作,拿红包这样的业务。真实的系统还会包括聊天这样的服务业务。
最后整体的看一下 100亿次摇红包这个需求,假设它是均匀地发生在春节联欢晚会的4个小时里,那么服务器的QPS 应该是10000000000/600/3600/4.0=1157. 也就是单机每秒1000多次,这个数值其实并不高。如果完全由峰值速度1400万消化 10000000000/(1400*10000) = 714秒,也就是说只需要峰值坚持11分钟,就可以完成所有的请求。可见互联网产品的一个特点就是峰值非常高,持续时间并不会很长。
总结
从单台服务器看.它需要满足下面一些条件:
支持至少100万连接用户
每秒至少能处理2.3万的QPS,这里我们把目标定得更高一些 分别设定到了3万和6万。
摇红包:支持每秒83个的速度下发放红包,也就是说每秒有2.3万次摇红包的请求,其中83个请求能摇到红包,其余的2.29万次请求会知道自己没摇到。当然客户端在收到红包以后,也需要确保客户端和服务器两边的红包数目和红包内的金额要一致。因为没有支付模块,所以我们也把要求提高一倍,达到200个红包每秒的分发速度
支持用户之间发红包业务,确保收发两边的红包数目和红包内金额要一致。同样也设定200个红包每秒的分发速度为我们的目标。
想完整模拟整个系统实在太难了,首先需要海量的服务器,其次需要上亿的模拟客户端。这对我来说是办不到,但是有一点可以确定,整个系统是可以水平扩展的,所以我们可以模拟100万客户端,在模拟一台服务器 那么就完成了1/600的模拟。
和现有系统区别:
和大部分高QPS测试的不同,本系统的侧重点有所不同。我对2者做了一些对比。
| 常见高QPS系统压力测试 | 本系统压力测试 | |
|---|---|---|
| 连接数 | 一般<1000 (几百以内) | 1000000 (1百万) |
| 单连接吞吐量 | 非常大 每个连接几十M字节吞吐 | 非常小 每个连接每次几十个字节 |
| 需要的IO次数 | 不多 | 非常多 |
4. 基础软件和硬件
4.1软件:
Golang 1.8r3 , shell, python (开发没有使用c++ 而是使用了golang, 是因为使用golang 的最初原型达到了系统要求。虽然golang 还存在一定的问题,但是和开发效率比,这点损失可以接受)
服务器操作系统: Ubuntu 12.04
客户端操作系统: debian 5.0
4.2 硬件环境
服务端:dell R2950。8核物理机,非独占有其他业务在工作,16G内存。
这台硬件大概是7年前的产品,性能应该不是很高要求。
服务器硬件版本: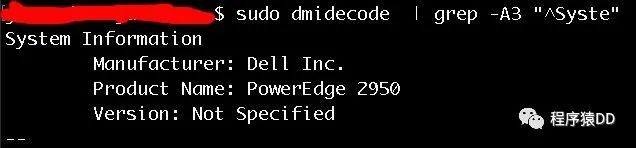
服务器CPU信息:
客户端:esxi 5.0 虚拟机,配置为4核 5G内存。一共17台,每台和服务器建立6万个连接。完成100万客户端模拟
5. 技术分析和实现
5.1 单机实现100万用户连接
这一点来说相对简单,笔者在几年前就早完成了单机百万用户的开发以及操作。现代的服务器都可以支持百万用户。
相关内容可以查看:
github代码以及相关文档。https://github.com/xiaojiaqi/C1000kPracticeGuide
系统配置以及优化文档:https://github.com/xiaojiaqi/C1000kPracticeGuide/tree/master/docs/cn
5.2 3万QPS
这个问题需要分2个部分来看客户端方面和服务器方面。
客户端QPS
因为有100万连接连在服务器上,QPS为3万。这就意味着每个连接每33秒,就需要向服务器发一个摇红包的请求。因为单IP可以建立的连接数为6万左右, 有17台服务器同时模拟客户端行为。我们要做的就保证在每一秒都有这么多的请求发往服务器即可。
其中技术要点就是客户端协同。但是各个客户端的启动时间,建立连接的时间都不一致,还存在网络断开重连这样的情况,各个客户端如何判断何时自己需要发送请求,各自该发送多少请求呢?
我是这样解决的:利用NTP服务,同步所有的服务器时间,客户端利用时间戳来判断自己的此时需要发送多少请求。
算法很容易实现:
假设有100万用户,则用户id 为0-999999.要求的QPS为5万, 客户端得知QPS为5万,总用户数为100万,它计算 100万/5万=20,所有的用户应该分为20组,如果 time() % 20 == 用户id % 20,那么这个id的用户就该在这一秒发出请求,如此实现了多客户端协同工作。每个客户端只需要知道 总用户数和QPS 就能自行准确发出请求了。
(扩展思考:如果QPS是3万 这样不能被整除的数目,该如何办?如何保证每台客户端发出的请求数目尽量的均衡呢?)
服务器QPS
服务器端的QPS相对简单,它只需要处理客户端的请求即可。但是为了客观了解处理情况,我们还需要做2件事情。
第一: 需要记录每秒处理的请求数目,这需要在代码里埋入计数器。
第二: 我们需要监控网络,因为网络的吞吐情况,可以客观的反映出QPS的真实数据。为此,我利用python脚本 结合ethtool 工具编写了一个简单的工具,通过它我们可以直观的监视到网络的数据包通过情况如何。它可以客观的显示出我们的网络有如此多的数据传输在发生。
工具截图: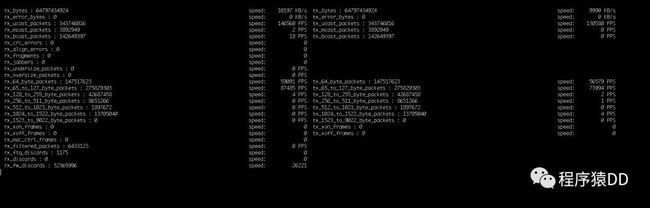
5.3 摇红包业务
摇红包的业务非常简单,首先服务器按照一定的速度生产红包。红包没有被取走的话,就堆积在里面。服务器接收一个客户端的请求,如果服务器里现在有红包就会告诉客户端有,否则就提示没有红包。
因为单机每秒有3万的请求,所以大部分的请求会失败。只需要处理好锁的问题即可。
我为了减少竞争,将所有的用户分在了不同的桶里。这样可以减少对锁的竞争。如果以后还有更高的性能要求,还可以使用 高性能队列——Disruptor来进一步提高性能。
注意,在我的测试环境里是缺少支付这个核心服务的,所以实现的难度是大大的减轻了。另外提供一组数字:2016年淘宝的双11的交易峰值仅仅为12万/秒,微信红包分发速度是5万/秒,要做到这点是非常困难的。(http://mt.sohu.com/20161111/n472951708.shtml)
5.4 发红包业务
发红包的业务很简单,系统随机产生一些红包,并且随机选择一些用户,系统向这些用户提示有红包。这些用户只需要发出拆红包的请求,系统就可以随机从红包中拆分出部分金额,分给用户,完成这个业务。同样这里也没有支付这个核心服务。
5.5 监控
最后 我们需要一套监控系统来了解系统的状况,我借用了我另一个项目(https://github.com/xiaojiaqi/fakewechat) 里的部分代码完成了这个监控模块,利用这个监控,服务器和客户端会把当前的计数器内容发往监控,监控需要把各个客户端的数据做一个整合和展示。同时还会把日志记录下来,给以后的分析提供原始数据。线上系统更多使用opentsdb这样的时序数据库,这里资源有限,所以用了一个原始的方案
监控显示日志大概这样
6. 代码实现及分析
在代码方面,使用到的技巧实在不多,主要是设计思想和golang本身的一些问题需要考虑。首先golang的goroutine 的数目控制,因为至少有100万以上的连接,所以按照普通的设计方案,至少需要200万或者300万的goroutine在工作。这会造成系统本身的负担很重。
其次就是100万个连接的管理,无论是连接还是业务都会造成一些心智的负担。
我的设计是这样的:
 架构图
架构图
首先将100万连接分成多个不同的SET,每个SET是一个独立,平行的对象。每个SET 只管理几千个连接,如果单个SET 工作正常,我只需要添加SET就能提高系统处理能力。按照SET分还有一个好处,可以将一个SET作为一个业务单元,在不同性能服务器上可以负载不同的压力,比如8核机器管理10个SET,4核机器管理5个SET 可以细粒度的分流压力,并容易迁移处理
其次谨慎的设计了每个SET里数据结构的大小,保证每个SET的压力不会太大,不会出现消息的堆积。
再次减少了gcroutine的数目,每个连接只使用一个goroutine,发送消息在一个SET里只有一个gcroutine负责,这样节省了100万个goroutine。这样整个系统只需要保留 100万零几百个gcroutine就能完成业务。大量的节省了cpu 和内存
系统的工作流程大概如下:
每个客户端连接成功后,系统会分配一个goroutine读取客户端的消息,当消息读取完成,将它转化为消息对象放至在SET的接收消息队列,然后返回获取下一个消息
在SET内部,有一个工作goroutine,它只做非常简单而高效的事情,它做的事情如下,检查SET的接受消息,它会收到3类消息
1, 客户端的摇红包请求消息 2, 客户端的其他消息 比如聊天 好友这一类 3, 服务器端对客户端消息的回应
对于 第1种消息 客户端的摇红包请求消息 是这样处理的,从客户端拿到摇红包请求消息,试图从SET的红包队列里 获取一个红包,如果拿到了就把红包信息 返回给客户端,否则构造一个没有摇到的消息,返回给对应的客户端。
对于第2种消息 客户端的其他消息 比如聊天 好友这一类,只需简单地从队列里拿走消息,转发给后端的聊天服务队列即可,其他服务会把消息转发出去。
对于第3种消息 服务器端对客户端消息的回应。SET 只需要根据消息里的用户id,找到SET里保留的用户连接对象,发回去就可以了。
对于红包产生服务,它的工作很简单,只需要按照顺序在轮流在每个SET的红包产生对列里放至红包对象就可以了。这样可以保证每个SET里都是公平的,其次它的工作强度很低,可以保证业务稳定。
见代码 https://github.com/xiaojiaqi/10billionhongbaos
7. 实践
实践的过程分为3个阶段
阶段1:分别启动服务器端和监控端,然后逐一启动17台客户端,让它们建立起100万的链接。在服务器端,利用ss 命令 统计出每个客户端和服务器建立了多少连接。
命令如下:
Alias ss2=Ss –ant | grep 1025 | grep EST | awk –F: “{print $8}” | sort | uniq –c’
结果如下:
阶段2:利用客户端的http接口,将所有的客户端QPS 调整到3万,让客户端发出3W QPS强度的请求。
运行如下命令:
观察网络监控和监控端反馈,发现QPS 达到预期数据 网络监控截图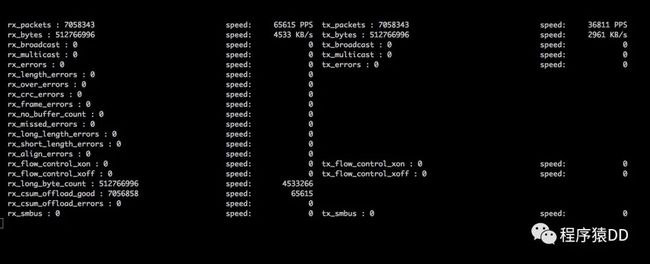
在服务器端启动一个产生红包的服务,这个服务会以200个每秒的速度下发红包,总共4万个。此时观察客户端在监控上的日志,会发现基本上以200个每秒的速度获取到红包。
![摇红包] (https://raw.githubusercontent.com/xiaojiaqi/10billionhongbaos/master/images/yao.png)
等到所有红包下发完成后,再启动一个发红包的服务,这个服务系统会生成2万个红包,每秒也是200个,每个红包随机指定3位用户,并向这3个用户发出消息,客户端会自动来拿红包,最后所有的红包都被拿走。
阶段3:利用客户端的http接口,将所有的客户端QPS 调整到6万,让客户端发出6W QPS强度的请求。
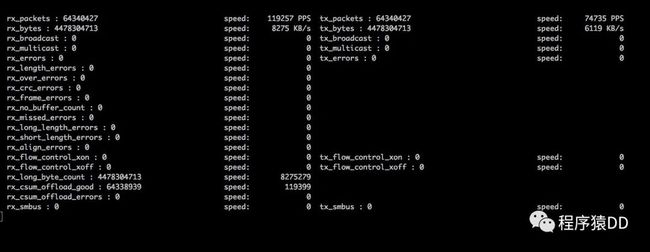 6wqps
6wqps
如法炮制,在服务器端,启动一个产生红包的服务,这个服务会以200个每秒的速度下发红包。总共4万个。此时观察客户端在监控上的日志,会发现基本上以200个每秒的速度获取到红包。等到所有红包下发完成后,再启动一个发红包的服务,这个服务系统会生成2万个红包,每秒也是200个,每个红包随机指定3位用户,并向这3个用户发出消息,客户端会自动来拿红包,最后所有的红包都被拿走。
最后,实践完成。
8. 分析数据
在实践过程中,服务器和客户端都将自己内部的计数器记录发往监控端,成为了日志。我们利用简单python 脚本和gnuplt 绘图工具,将实践的过程可视化,由此来验证运行过程。
第一张是 客户端的QPS发送数据
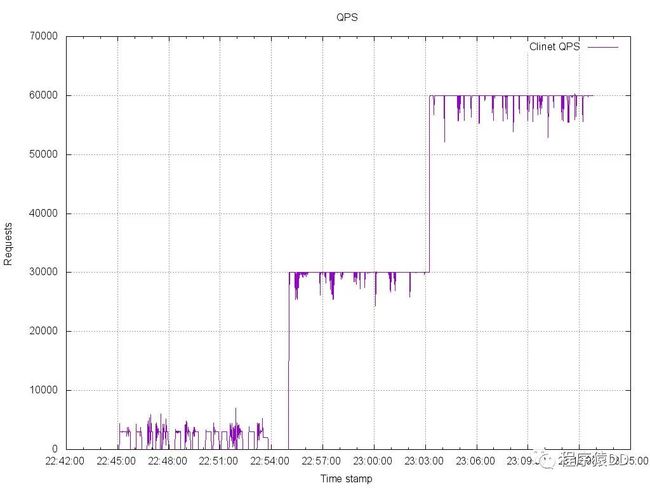 客户端qps
客户端qps
这张图的横坐标是时间,单位是秒,纵坐标是QPS,表示这时刻所有客户端发送的请求的QPS。图的第一区间,几个小的峰值,是100万客户端建立连接的, 图的第二区间是3万QPS 区间,我们可以看到数据 比较稳定的保持在3万这个区间。最后是6万QPS区间。但是从整张图可以看到QPS不是完美地保持在我们希望的直线上。这主要是以下几个原因造成的
当非常多goroutine 同时运行的时候,依靠sleep 定时并不准确,发生了偏移。我觉得这是golang本身调度导致的。当然如果cpu比较强劲,这个现象会消失。
因为网络的影响,客户端在发起连接时,可能发生延迟,导致在前1秒没有完成连接。
服务器负载较大时,1000M网络已经出现了丢包现象,可以通过ifconfig 命令观察到这个现象,所以会有QPS的波动。
第二张是 服务器处理的QPS图
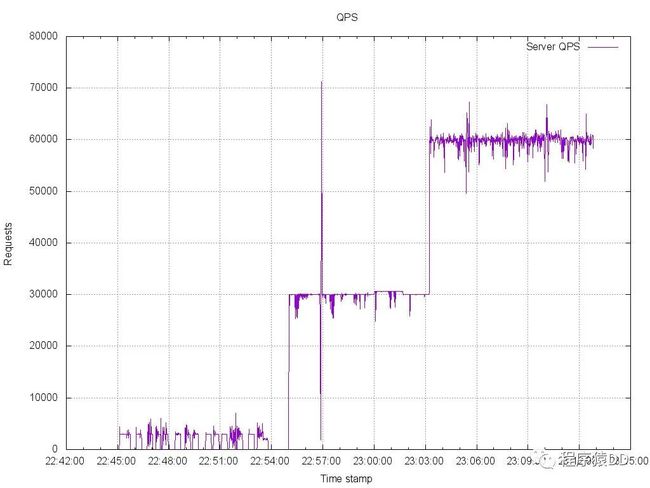 服务器qps
服务器qps
和客户端的向对应的,服务器也存在3个区间,和客户端的情况很接近。但是我们看到了在大概22:57分,系统的处理能力就有一个明显的下降,随后又提高的尖状。这说明代码还需要优化。
整体观察在3万QPS区间,服务器的QPS比较稳定,在6万QSP时候,服务器的处理就不稳定了。我相信这和我的代码有关,如果继续优化的话,还应该能有更好的效果。
将2张图合并起来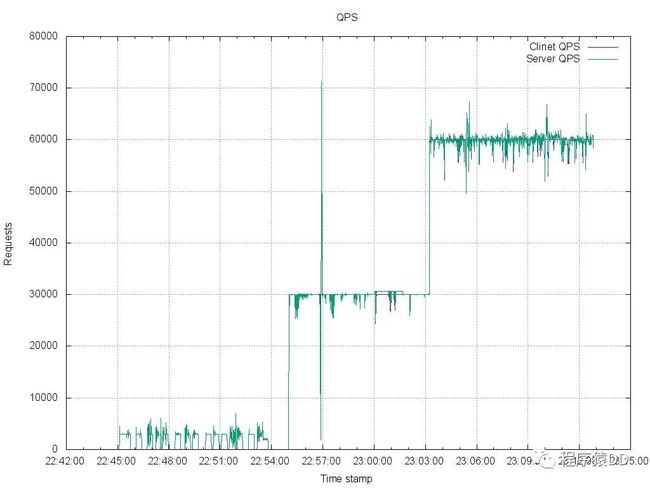
基本是吻合的,这也证明系统是符合预期设计的。
这是红包生成数量的状态变化图
非常的稳定。
这是客户端每秒获取的摇红包状态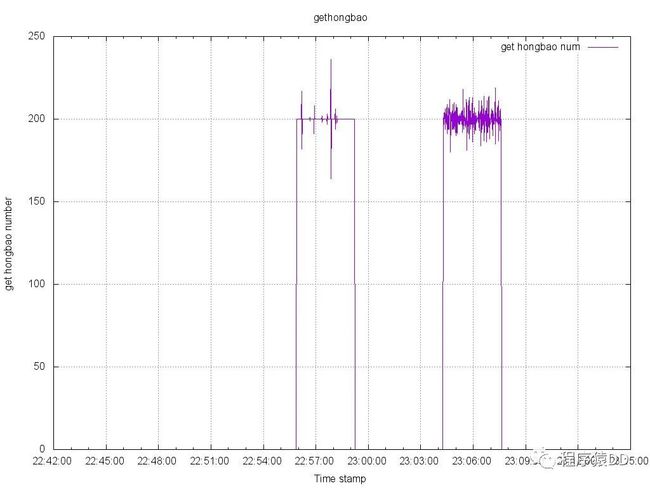
可以发现3万QPS区间,客户端每秒获取的红包数基本在200左右,在6万QPS的时候,以及出现剧烈的抖动,不能保证在200这个数值了。我觉得主要是6万QPS时候,网络的抖动加剧了,造成了红包数目也在抖动。
最后是golang 自带的pprof 信息,其中有gc 时间超过了10ms, 考虑到这是一个7年前的硬件,而且非独占模式,所以还是可以接受。
总结:
按照设计目标,我们模拟和设计了一个支持100万用户,并且每秒至少可以支持3万QPS,最多6万QPS的系统,简单模拟了微信的摇红包和发红包的过程。可以说达到了预期的目的。如果600台主机每台主机可以支持6万QPS,只需要7分钟就可以完成 100亿次摇红包请求。
虽然这个原型简单地完成了预设的业务,但是它和真正的服务会有哪些差别呢?我罗列了一下
| 区别 | 真正服务 | 本次模拟 |
|---|---|---|
| 业务复杂 | 更复杂 | 非常简单 |
| 协议 | Protobuf 以及加密 | 简单的协议 |
| 支付 | 复杂 | 无 |
| 日志 | 复杂 | 无 |
| 性能 | 更高 | 无 |
| 用户分布 | 用户id分散在不同服务器,需要hash以后统一, 复杂。 | 用户id 连续,很多优化使代码简单 非常高效 |
| 安全控制 | 复杂 | 无 |
| 热更新及版本控制 | 复杂 | 无 |
| 监控 | 细致 | 简单 |
Refers:
单机百万的实践
https://github.com/xiaojiaqi/C1000kPracticeGuide
如何在AWS上进行100万用户压力测试
https://github.com/xiaojiaqi/fakewechat/wiki/Stress-Testing-in-the-Cloud
构建一个你自己的类微信系统
https://github.com/xiaojiaqi/fakewechat/wiki/Design
http://djt.qq.com/article/view/1356
http://techblog.cloudperf.net/2016/05/2-million-packets-per-second-on-public.html
http://datacratic.com/site/blog/1m-qps-nginx-and-ubuntu-1204-ec2
@火丁笔记
http://huoding.com/2013/10/30/296
https://gobyexample.com/non-blocking-channel-operations
END
前线推出学习交流一定要备注:研究/工作方向+地点+学校/公司+昵称(如AI+上海+上师大+卡卡),根据格式备注,可更快被通过且邀请进群
扫码助手小姐姐微信,进群大厂内推&大佬技术交流
END
开发者技术前线 ,汇集技术前线快讯和关注行业趋势,大厂干货,是开发者经历和成长的优秀指南。ps:后台回复 “面试“&”资料” 数百面试手册,即可领取程序员大礼包等你历史推荐
2020年必学的 10 大算法
为什么程序员都不喜欢使用switch,而是大量的 if……else if ?
面试官:POST 比 GET 安全吗?你理解就是错的
技术总监:你个P7 连 CopyOnWriteArrayList 都没听过!我:确实没听过
好文点个在看吧!