CRF++使用小结
1. 简述
近期要应用CRF模型,进行序列识别。选用了CRF++工具包,详细来说是在VS2008的C#环境下,使用CRF++的windows版本号。本文总结一下了解到的和CRF++工具包相关的信息。
參考资料是CRF++的官方站点:CRF++: Yet Another CRF toolkit,网上的非常多关于CRF++的博文就是这篇文章的所有或者部分的翻译,本文也翻译了一些。
2. 工具包下载
第一,版本号选择,当前最新版本号是2010-05-16日更新的CRF++ 0.54版本号,只是这个版本号曾经我用过一次好像执行的时候存在一些问题,网上一些人也说有问题,所以这里用的是2009-05-06: CRF++ 0.53版本号。关于执行出错的信息有http://ir.hit.edu.cn/bbs/viewthread.php?action=printable&tid=7945为证。
第二,文件下载,这个主页上面仅仅有最新的0.54版本号的文件,网上能够搜索,只是不是资源不是非常多,我在CSDN上面下载了一个CRF++0.53版本号的,包括linux和windows版本号,其要花掉10个积分。由于,我没有找到比較稳定、长期、免费的链接,这里上传一份这个文件:CRF++ 0.53 Linux和Windows版本号。
3. 工具包文件

doc目录:就是官方主页的内容。
example目录:有四个任务的训练数据、測试数据和模板文件。
sdk目录:CRF++的头文件和静态链接库。
crf_learn.exe:CRF++的训练程序。
crf_test.exe:CRF++的预測程序
libcrfpp.dll:训练程序和预測程序须要使用的静态链接库。
实际上,须要使用的就是crf_learn.exe,crf_test.exe和libcrfpp.dll,这三个文件。
4. 命令行格式
4.1 训练程序
命令行:
% crf_learn template_file train_file model_file
这个训练过程的时间、迭代次数等信息会输出到控制台上(感觉上是crf_learn程序的输出信息到标准输出流上了),假设想保存这些信息,我们能够将这些标准输出流到文件上,命令格式例如以下:
% crf_learn template_file train_file model_file >> train_info_file
有四个基本的參数能够调整:
-a CRF-L2 or CRF-L1
规范化算法选择。默认是CRF-L2。一般来说L2算法效果要比L1算法略微好一点,尽管L1算法中非零特征的数值要比L2中大幅度的小。
-c float
这个參数设置CRF的hyper-parameter。c的数值越大,CRF拟合训练数据的程度越高。这个參数能够调整过度拟合和不拟合之间的平衡度。这个參数能够通过交叉验证等方法寻找较优的參数。
-f NUM
这个參数设置特征的cut-off threshold。CRF++使用训练数据中至少NUM次出现的特征。默认值为1。当使用CRF++到大规模数据时,仅仅出现一次的特征可能会有几百万,这个选项就会在这种情况下起到作用。
-p NUM
假设电脑有多个CPU,那么那么能够通过多线程提升训练速度。NUM是线程数量。
带两个參数的命令行样例:
% crf_learn -f 3 -c 1.5 template_file train_file model_file
4.2 測试程序
命令行:
% crf_test -m model_file test_files
有两个參数-v和-n都是显示一些信息的,-v能够显示预測标签的概率值,-n能够显示不同可能序列的概率值,对于准确率,召回率,执行效率,没有影响,这里不说明了。
与crf_learn类似,输出的结果放到了标准输出流上,而这个输出结果是最重要的预測结果信息(測试文件的内容+预測标注),相同能够使用重定向,将结果保存下来,命令行例如以下。
% crf_test -m model_file test_files >> result_file
5. 文件格式
5.1 训练文件
以下是一个训练文件的样例:

训练文件由若干个句子组成(能够理解为若干个训练例子),不同句子之间通过换行符分隔,上图中显示出的有两个句子。每一个句子能够有若干组标签,最后一组标签是标注,上图中有三列,即第一列和第二列都是已知的数据,第三列是要预測的标注,以上面例子为例是,依据第一列的词语和和第二列的词性,预測第三列的标注。
当然这里有涉及到标注的问题,这个就是非常多paper要研究的了,比方命名实体识别就有非常多不同的标注集。这个超出本文范围。
5.2 測试文件
測试文件与训练文件格式自然是一样的,用过机器学习工具包的这个一般都理解吧。
与SVM不同,CRF++没有单独的结果文件,预測结果通过标准输出流输出了,因此前面4.2节的命令行中,将结果重定向到文件里了。结果文件比測试文件多了一列,即为预測的标签,我们能够计算最后两列,一列的标注的标签,一列的预測的标签,来得到标签预測的准确率。
5.3 模板文件
5.3.1 模板基础
模板文件里的每一行是一个模板。每一个模板都是由%x[row,col]来指定输入数据中的一个token。row指定到当前token的行偏移,col指定列位置。
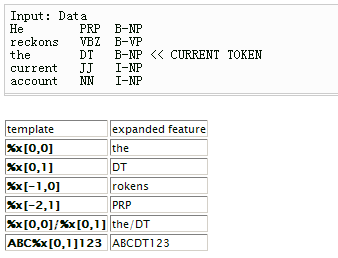
由上图可见,当前token是the这个单词。%x[-2,1]就就是the的前两行,1号列的元素(注意,列是从0号列開始的),即为PRP。
5.3.2 模板类型
有两种类型的模板,模板类型通过第一个字符指定。
Unigram template: first character, 'U'
当给出一个"U01:%x[0,1]"的模板时,CRF++会产生例如以下的一些特征函数集合(func1 ... funcN) 。

这几个函数我说明一下,%x[0,1]这个特征到前面的例子就是说,依据词语(第1列)的词性(第2列)来预測其标注(第3列),这些函数就是反应了训练例子的情况,func1反映了“训练例子中,词性是DT且标注是B-NP的情况”,func2反映了“训练例子中,词性是DT且标注是I-NP的情况”。
模板函数的数量是L*N,当中L是标注集中类别数量,N是从模板中扩展处理的字符串种类。
Bigram template: first character, 'B'
这个模板用来描写叙述二元特征。这个模板会自己主动产生当前output token和前一个output token的合并。注意,这样的类型的模板会产生L * L * N种不同的特征。
Unigram feature 和 Bigram feature有什么差别呢?
unigram/bigram非常easy混淆,由于通过unigram-features也能够写出类似%x[-1,0]%x[0,0]这种单词级别的bigram(二元特征)。而这里的unigram和bigram features指定是uni/bigrams的输出标签。
unigram: |output tag| x |all possible strings expanded with a macro|
bigram: |output tag| x |output tag| x |all possible strings expanded with a macro|
这里的一元/二元指的就是输出标签的情况,这个详细的样例我还没看到,example目录中四个样例,也都是仅仅用了Unigram,没实用Bigarm,因此感觉一般Unigram feature就够了。
5.3.3 模板样例
这是CoNLL 2000的Base-NP chunking任务的模板样例。仅仅使用了一个bigram template ('B')。这意味着仅仅有前一个output token和当前token被当作bigram features。“#”開始的行是凝视,空行没有意义。

6. 例子数据
example目录中有四个任务,basenp,chunking,JapaneseNE,seg。前两个是英文数据,后两个是日文数据。第一个应该是命名实体识别,第二个应该是分词,第三个应该是日文命名实体识别,第四个不清楚。这里主要跑了一下前两个任务,后两个是日文的搞不懂。
依据任务以下的linux的脚步文件,我写了个简单的windows批处理(当中用重定向保存了信息),比方命名为exec.bat,跑了一下。批处理文件放在要跑的任务的路径下即可,批处理文件内容例如以下:
..\..\crf_learn -c 10.0 template train.data model >> train-info.txt
..\..\crf_test -m model test.data >> test-info.txt
这里简单解释一下批处理,批处理文件执行后的当前文件夹就是该批处理文件所在的文件夹(至少我的是这样,假设不是,能够使用cd %~dp0这句命令,~dp0表示了“当前盘符和路径”),crf_learn和crf_test程序在当前文件夹的前两级文件夹上,所以用了..\..\。
7. 总结
命令行(命令行格式,參数,重定向)
调參数(一般也就调训练过程的c值)
标注集(这个非常重要,研究相关)
模板文件(这个也非常重要,研究相关)
模板文件的Unigram feature 和 Bigram feature,前面也说了,这里指的是output的一元/二元,这个应用的情况临时还不是特别了解,还须要看一些paper可能才干知道。
转自:http://www.cnblogs.com/pangxiaodong/archive/2011/11/21/2256264.html