【Python3】POP3协议收邮件
初学Python3,做一个email的例子,虽然知道做的很渣渣,还是分享一下吧
POP3协议
POP3全称Post Official Protocol3,即邮局协议的第三个版本,它规定了怎样将个人计算机连接到Internet的邮件服务器和下载电子邮件的电子协议,它是因特网电子协议的第一个离线标准,POP3允许用户从服务器上将邮件存储到本地主机(个人计算机),同时删除保存在邮件服务器上的邮件,而POP3服务器则是遵循POP3协议的邮件服务器,用来接收电子邮件。
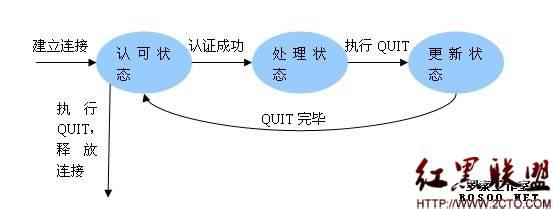
Python3支持POP3的模块是poplib:建立连接(初始化POP3时进行)、用户名/密码认证、获取邮件信息/下载邮件/删除邮件等处理、退出并更新处理。
POP3的协议模型及处理是非常直观的,获取到邮件以后的解析消息才是major problem!
代码如下
import poplib
import sys
from importlib import reload
from email.parser import Parser
from email.parser import BytesParser
from email.header import decode_header
from email.utils import parseaddr
import email.iterators
# 解析消息头中的字符串
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
# 将邮件附件或内容保存至文件
# 即邮件中的附件数据写入附件文件
def savefile(filename, data, path):
try:
filepath = path + filename
print( ' Save as: ' + filepath)
f = open(filepath, ' wb ')
except:
print(filepath + ' open failed ')
# f.close()
else:
f.write(data)
f.close()
# 获取邮件的字符编码,首先在message中寻找编码,如果没有,就在header的Content-Type中寻找
def guess_charset(msg):
charset = msg.get_charset()
if charset is None:
content_type = msg.get( ' Content-Type ', '').lower()
pos = content_type.find( ' charset= ')
if pos >= 0:
charset = content_type[pos+8:].strip()
return charset
# 解析邮件的函数,首先打印收件人、发件人、标题
# 然后调用message的walk循环处理邮件中的每一个子对象(包括文本、html、附件一次或多次)
# 邮件头属性中的filename存在则该子对象是附件,对附件名称进行编码并将附件下载到指定目录
# 由于网络上传输的邮件都是编码以后的格式,需要在get_payload的时候指定decode=True来转换成可输出的编码
# 如果邮件是text或者html格式,打印格式并输出转码以后的子对象内容
def print_info(msg):
for header in [ ' From ', ' To ', ' Subject ']:
value = msg.get(header, '')
if value:
if header == ' Subject ':
value = decode_str(value)
else:
hdr, addr = parseaddr(value)
name = decode_str(addr)
value = name + ' < ' + addr + ' > '
print(header + ' : ' + value)
for part in msg.walk():
filename = part.get_filename()
content_type = part.get_content_type()
charset = guess_charset(part)
if filename:
filename = decode_str(filename)
data = part.get_payload(decode = True)
if filename != None or filename != '':
print( ' Accessory: ' + filename)
savefile(filename, data, mypath)
else:
email_content_type = ''
content = ''
if content_type == ' text/plain ':
email_content_type = ' text '
elif content_type == ' text/html ':
email_content_type = ' html '
if charset:
content = part.get_payload(decode=True).decode(charset)
print(email_content_type + ' ' + content)
email = ' [email protected] '
password = ' email_passwd '
pop3_server = ' pop.163.com '
mypath = ' D://email/ '
server = poplib.POP3(pop3_server, 110)
# print(server.getwelcome())
server.user(email)
server.pass_(password)
print( ' Message: %s. Size: %s ' % server.stat())
resp, mails, objects = server.list()
# print(mails)
index = len(mails)
# 取出某一个邮件的全部信息
resp, lines, octets = server.retr(index)
# 邮件取出的信息是bytes,转换成Parser支持的str
lists = []
for e in lines:
lists.append(e.decode())
msg_content = ' \r\n '.join(lists)
msg = Parser().parsestr(msg_content)
print_info(msg)
# server.dele(index)
# 提交操作信息并退出
server.quit()
import sys
from importlib import reload
from email.parser import Parser
from email.parser import BytesParser
from email.header import decode_header
from email.utils import parseaddr
import email.iterators
# 解析消息头中的字符串
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
value = value.decode(charset)
return value
# 将邮件附件或内容保存至文件
# 即邮件中的附件数据写入附件文件
def savefile(filename, data, path):
try:
filepath = path + filename
print( ' Save as: ' + filepath)
f = open(filepath, ' wb ')
except:
print(filepath + ' open failed ')
# f.close()
else:
f.write(data)
f.close()
# 获取邮件的字符编码,首先在message中寻找编码,如果没有,就在header的Content-Type中寻找
def guess_charset(msg):
charset = msg.get_charset()
if charset is None:
content_type = msg.get( ' Content-Type ', '').lower()
pos = content_type.find( ' charset= ')
if pos >= 0:
charset = content_type[pos+8:].strip()
return charset
# 解析邮件的函数,首先打印收件人、发件人、标题
# 然后调用message的walk循环处理邮件中的每一个子对象(包括文本、html、附件一次或多次)
# 邮件头属性中的filename存在则该子对象是附件,对附件名称进行编码并将附件下载到指定目录
# 由于网络上传输的邮件都是编码以后的格式,需要在get_payload的时候指定decode=True来转换成可输出的编码
# 如果邮件是text或者html格式,打印格式并输出转码以后的子对象内容
def print_info(msg):
for header in [ ' From ', ' To ', ' Subject ']:
value = msg.get(header, '')
if value:
if header == ' Subject ':
value = decode_str(value)
else:
hdr, addr = parseaddr(value)
name = decode_str(addr)
value = name + ' < ' + addr + ' > '
print(header + ' : ' + value)
for part in msg.walk():
filename = part.get_filename()
content_type = part.get_content_type()
charset = guess_charset(part)
if filename:
filename = decode_str(filename)
data = part.get_payload(decode = True)
if filename != None or filename != '':
print( ' Accessory: ' + filename)
savefile(filename, data, mypath)
else:
email_content_type = ''
content = ''
if content_type == ' text/plain ':
email_content_type = ' text '
elif content_type == ' text/html ':
email_content_type = ' html '
if charset:
content = part.get_payload(decode=True).decode(charset)
print(email_content_type + ' ' + content)
email = ' [email protected] '
password = ' email_passwd '
pop3_server = ' pop.163.com '
mypath = ' D://email/ '
server = poplib.POP3(pop3_server, 110)
# print(server.getwelcome())
server.user(email)
server.pass_(password)
print( ' Message: %s. Size: %s ' % server.stat())
resp, mails, objects = server.list()
# print(mails)
index = len(mails)
# 取出某一个邮件的全部信息
resp, lines, octets = server.retr(index)
# 邮件取出的信息是bytes,转换成Parser支持的str
lists = []
for e in lines:
lists.append(e.decode())
msg_content = ' \r\n '.join(lists)
msg = Parser().parsestr(msg_content)
print_info(msg)
# server.dele(index)
# 提交操作信息并退出
server.quit()