Flink 一站式计算平台 StreamPark 2.0.0 重磅发布,首个 Apache 版本终于来了

Apache StreamPark(Incubating) 社区的小伙伴们大家好:今天我们很高兴地宣布 StreamPark 2.0.0 正式发布!欢迎下载使用。
这是 StreamPark 加入 Apache 孵化器以来发布的第一个版本,也是一个重大功能更新的版本。距离上个版本发布已有半年之久,在这半年多的时间里,我们开发了很多非常实用的新功能,也经历了社区小伙伴们的数次催更和发版合规的数次整改。现在,它终于和大家见面了。这是一个诚意满满的、值得期待的版本。有超过 100 位 Contributor 贡献了超过 700 个 Pull Request,带来了诸多的新特性和改进修复,感谢每一位贡献者的努力。
在 2.0.0 版本中,我们完成了 Apache 项目的合规要求。此次发版投票前后周期跨越 3 个月,经过社区和 ASF 孵化器导师们数轮的检查和投票,在此非常感谢参与项目检查和投票的导师和社区小伙伴,由衷感受到 ASF 对项目的严苛要求,对 License(一种具有法律性质的合同或指导,目的在于规范受著作权保护的软件的使用或散布行为)合规的高度重视。终于,在第 7 轮投票中通过了本次发布。这意味着 2.0.0 版本的 License 合规最大程度的得到保证,可以被更多企业更广泛的使用。
本次重写了整个前端模块,UI显示更加美观和专业。前端构建和启动速度同历史版本比提升了 5~10 倍。对 Apache Flink 做了更好的支持,支持最新的 Flink 1.16。部署 Flink 作业 on Kubernetes 达到生产可用级别,另外在实用性和易用性上做了大量改进,修复了诸多历史 Bug 和安全漏洞,建议所有人升级使用。
尝鲜体验
- GitHub:https://github.com/apache/streampark
- 下载:https://streampark.apache.org/download
欢迎使用、关注、star、fork,四连成功~
安装使用
Apache StreamPark(Incubating) 提供了两个安装包,在 Scala 版本上有所不同。如下:
- apache-streampark_2.11-2.0.0-incubating-bin.tar.gz
- apache-streampark_2.12-2.0.0-incubating-bin.tar.gz
2.11 和 2.12 即为 Scala 的版本,这里 Scala 版本与 Flink 的 Scala 版本要保持一致。如果 Flink 版本是 1.15 及以上,那么只能使用 Scala 2.12 版本的 StreamPark。因为 Flink 1.15+ 只支持 Scala 2.12,1.15 以下的版本则 Scala 2.11 和 2.12 都支持。
总之需要下载与目标 Flink 的 Scala 版本对应的 StreamPark 安装包。
除了下载提供好的安装包之外,你也可以选择下载源码进行编译安装。StreamPark 2.0 提供了非常简单的一键编译脚本,执行脚本编译出目标安装包即可安装。
视频演示:
Apache StreamPark 从源码编译到启动部署
新特性解读
全新的前端
StreamPark 历史版本的前端模块是基于 Vue2 框架开发的,不少页面代码量过多、页面和组件复用率低,在可读性和维护性上都带来了不小的挑战。本次基于 Vue3 重写了整个前端部分,组件划分更清晰、可复用性更高,很好地解决了以上问题。升级 Vue3 之后模块按需编译按需导入的,体积比之前更小,编译、启动和渲染等速度更快。
本次支持了 i18n,支持中/英切换。此外反馈较多的关于异常信息的提示也做了改进: 之前作业失败等相关信息只记录到了后台日志,并未在前端显示给用户,这会给排查问题带来不便。本次改进了这部分,相关信息直观地呈现给用户,方便用户快速分析和定位问题。
在美观度上,进一步改进了暗黑模式,优化了非常多的细节,普遍反馈本次页面更加美观和专业。
上图为 StreamPark 2.0.0 界面预览
K8s 能力更稳定
本次在部署 Flink on Kubernetes 上,修复了诸多历史 Bug,支持了查看 Kubernetes 部署模式下的实时日志,重构了作业运行状态这部分的实现。
在状态获取这部分引入了基于读取 HistoryServer[1] 归档文件来获取作业状态的保底策略,需要特别指出的是 StreamPark 中关于 Flink on Kubernetes 的实现并非基于 flink-kubernetes-operator[2]。
在作业部署提交、运行状态等各个方面都做了大量的测试,整体稳定性和可用性经过企业大量作业的验证,达到生产可用级别。
更好的 Flink 支持
在 StreamPark 2.0.0 版本中,支持了最新的 Flink 1.16,到此 Flink 1.12.x 至 1.16 都已经做了完整的支持,并且本次对适配 Flink 做了改进,使得适配一个新版本的 Flink 更加简单。
视频演示:
StreamPark 支持 Flink多版本
此外,对 Flink 开发框架这部分也进行了改进,统一了 StreamPark 中的开发 Flink 作业的参数配置,重新规范了参数名,使 StreamPark 的 Flink 开发框架部分的参数与 Apache Flink 参数名保持一致,大大提升了用户配置 Flink 参数的易用性,从而减轻开发者的心智负担和使用学习成本。
最新的 Flink 作业配置文件结构如下:
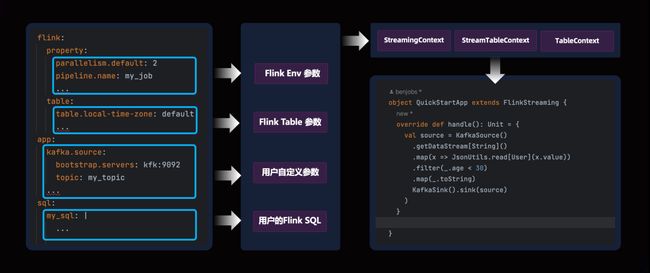
上图为 Flink 作业参数配置
易用性改进
历史版本中 StreamPark 平台强依赖 MySQL,本次扩展支持了三种数据库供用户选择: 分别是 H2、MySQL、PostgreSQL。StreamPark 默认使用H2。对于想要快速体验的用户来说,下载安装包、执行启动脚本启动服务即可,无需其他额外配置和操作就可以体验 StreamPark 了,进一步降低了用户的体验门槛和使用成本。
本次新增了变量管理功能,在没有变量之前在 StreamPark 里编写 Flink SQL 作业时会将连接器的相关信息,如: 数据库的连接字符串、用户名、 密码等明文地写在 SQL 中。这样不但容易出错,作业多了混乱不方便管理,而且还不安全。有了变量管理和填充功能之后: 在创建作业时可以使用定义好的变量进行填充,同时可以方便查看某个变量被哪些作业使用,避免手动输入带来的错误。
视频演示:
Apache StreamPark 变量管理 & 填充
除此之外,本次还优化了很多其他方面关于易用性上的细节,如:提供了 Docker 方式一键部署启动 StreamPark [3],支持了通过 copy 已有的作业来快速创建一个新的作业等等,这些功能都不同程度地提升了 StreamPark 的易用性,给用户带来更好的使用体验。
企业级支持
本次新增了团队管理,在没有团队管理之前,所有的作业都展示在一个页面,非常不便于作业的分类和管理,同时作业的权限也得不到保证。新增团队管理后,不同的团队之间资源隔离,团队成员只能看到本团队的作业,这样作业的管理和权限问题都得到了解决。
为了更好地同企业现有账号体系打通,本次新增了 LDAP 登录功能,只需要在系统的配置中进行 LDAP 相关的配置,然后在登录时选择通过 LDAP 登录即可。这样就可以快捷的一键登录 StreamPark 平台。
对于企业用户生产环境使用来讲,作业的稳定性至关重要,与之相关的预警机制也是一个必须要考量的一个重要指标。本次告警通知方式新增支持了钉钉、企业微信、飞书、邮件等方式。用户只需要配置一个告警组,在作业里指定告警组即可,做到了灵活配置和复用。
其他更新和改进
- 改进项目构建体验,记录上一次构建日志
- 支持了 Flink SQL 所有语法
- 开发框架部分支持 HOCON 配置文件
- run-mode 支持 streaming 和 batch
- 修复
env.java.opts参数不生效的 bug - 修复支持 Yarn 队列不生效的 bug
- 修复 on Yarn 下 Kerberos 认证相关的 bug
Release Note
本次 StreamPark 2.0.0 版本的 完整 Release Note 请访问:https://streampark.apache.org/download/release-note/2.0.0
感谢贡献者
THANK YOU ALL
StreamPark 开源社区的发展,离不开广大用户群体的积极反馈和宣传布道,更离不开贡献者们的无私贡献,感谢对此版本做出贡献的每一位贡献者。致谢名单 (排名不分先后):
1996fanrui、Aimiyoo、Assert、BIN、Cheng Pan、ChenlingXie、ChunFu Wu、Daixinyu、Daniel Gruno、Gerry、Gilliam Su、GuoGuo、HaiYang Chen、Kerwin、Kick156、Kunni、KyleZhang0536、Leping Huang、Liebing、LiuHao、Monster、PJ Fanning、Rinka、Roc Marshal、Rui Fan、Ruibin Xing、Shaokang Lv、Shlpeng、Steam、Tamer、Tobe、Tyrantlucifer、VampireAchao、WHJian、WangSizhu0504、YuTing、Yuepeng.Pan、Yw Zhang、atovk、avatarTaier、benjobs、bitstring、boliza、boojack、bulolo、chuanchuan、dian、didiaode18、fanchp0、fantasticKe、gongzhongqiang、hellowrold2022、huangzhuojun、jakevin、legendtkl、liuzhuang2017、lvlin241、lvshaokang、macksonmu、maruko、monrg、monster、mucj7、rafaelxie、sky-creater、sober、teeyog、tison、wangqingrong、wangrui、weijinglun、wellCh4n、wql、wzq246810、xujiangfeng001、xxyykkxx、yiwei、zhangxiangyang、zhu-mingye、zhuojun-huang、zhuzhihao94、ziqiang-wang、秋天、阿洋、小狐狸、木鱼和尚、第一片心意、芝麻仗剑走天涯
什么是StreamPark
StreamPark 是一个流处理应用程序开发管理框架。初衷是让流处理更简单,旨在轻松构建和管理流处理应用程序,提供使用 Apache Flink 和 Apache Spark 编写流处理应用程序的开发框架,未来将支持更多其他引擎。同时,StreamPark 提供了一个流处理应用管理平台,核心能力包括但不限于应用开发、调试、交互查询、部署、运维、实时数仓等,最初开源时项目名称叫 StreamX ,于 2022 年 8 月更名[4]为 StreamPark,随后通过投票正式成为 Apache 开源软件基金会的孵化项目。
加入我们
进入 Apache 孵化器意味着 StreamPark 距离成为顶级的开源社区产品更近一步,也是万里长征的第一步。我们时刻保持开发者谦逊朴素的本质,认真学习和遵循「The Apache Way」,秉承更加兼容并包的心态,迎接更多的机遇与挑战。诚挚欢迎更多的贡献者参与到社区建设中来,和我们一道携手共建。
项目地址:https://github.com/apache/incubator-streampark
提交问题和建议:https://github.com/apache/incubator-streampark/issues
贡献代码:https://github.com/apache/incubator-streampark/pulls
Proposal:https://cwiki.apache.org/confluence/display/INCUBATOR/StreamPark+Proposal
订阅社区开发邮件列表:[email protected]
社区沟通:点击链接

参考资料
[1] https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/deployment/advanced/historyserver
[2] https://github.com/apache/flink-kubernetes-operator
[3] https://streampark.apache.org/docs/user-guide/docker-deployment
[4] https://github.com/apache/incubator-streampark/issues/1335
祝大家安装、升级顺利~~